



Meta a récemment lancé deux puissants clusters GPU pour prendre en charge la formation de modèles d'IA générative de nouvelle génération, y compris le prochain Llama 3.
Les deux centres de données seraient équipés de jusqu'à 24 576 GPU, conçus pour prendre en charge des modèles d'IA générative plus grands et plus complexes que ceux publiés précédemment.
En tant que modèle d'algorithme open source populaire, Meta's Llama est comparable au GPT d'OpenAI et au Gemini de Google.
Selon Geek.com, ces deux clusters GPU sont équipés du GPU H100 le plus puissant de NVIDIA, qui est beaucoup plus grand que les grands clusters précédemment lancés par Meta. Auparavant, le cluster de Meta comptait environ 16 000 GPU Nvidia A100.
Il est rapporté que Meta a acheté des milliers des derniers GPU de Nvidia. La société d'études de marché Omdia a souligné dans son dernier rapport que Meta était devenu l'un des clients les plus importants de Nvidia.
Les ingénieurs Meta ont annoncé qu'ils prévoyaient d'utiliser de nouveaux clusters GPU pour affiner les systèmes d'IA existants afin de former des systèmes d'IA plus récents et plus puissants, notamment Llama 3.
L'ingénieur a souligné que le développement de Llama 3 est actuellement "en cours", mais n'a pas révélé quand il sortira.
L’objectif à long terme de Meta est de développer des systèmes généraux d’intelligence artificielle (AGI), car l’AGI est plus proche des humains en termes de créativité et est très différente des modèles d’IA générative existants.
Le nouveau cluster GPU aidera Meta à atteindre ces objectifs. De plus, la société améliore le framework PyTorch AI pour prendre en charge davantage de GPU.
Il convient de mentionner que bien que les deux clusters aient exactement le même nombre de GPU et puissent se connecter l'un à l'autre à des points de terminaison de 400 Go par seconde, ils utilisent des architectures différentes.
Parmi eux, un cluster GPU peut accéder à distance à la mémoire directe ou au RDMA via une structure de réseau Ethernet convergé construite à l'aide de l'Arista 7800 d'Arista Networks avec des commutateurs de rack Wedge400 et Minipack2 OCP. Un autre cluster GPU est construit à l'aide de la technologie de structure réseau Quantum2 InfiniBand de Nvidia.
Les deux clusters utilisent Grand Teton, la plate-forme matérielle GPU ouverte de Meta, conçue pour prendre en charge les charges de travail d'IA à grande échelle. Grand Teton offre quatre fois la bande passante hôte-GPU de son prédécesseur, la plate-forme Zion-EX, et deux fois la puissance de calcul, la bande passante et la puissance de Zion-EX.
Meta a déclaré que ces deux clusters adoptent la dernière infrastructure d'alimentation et de rack ouverte, dans le but d'offrir une plus grande flexibilité dans la conception des centres de données. Open Rack v3 permet aux racks d'alimentation d'être montés n'importe où à l'intérieur du rack plutôt que d'être fixés aux jeux de barres, ce qui permet des configurations plus flexibles.
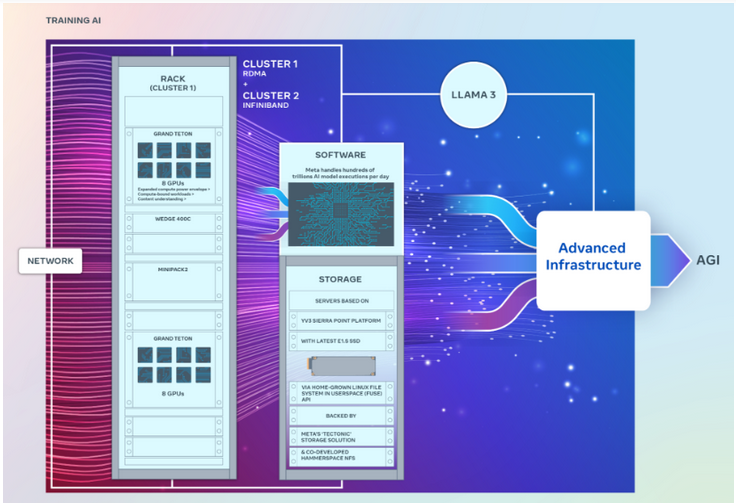
De plus, le nombre de serveurs par rack est également personnalisable, permettant un équilibre plus efficace en termes de capacité de débit de chaque serveur.
En termes de stockage, ces deux clusters GPU sont basés sur la plateforme serveur YV3 Sierra Point et utilisent les disques SSD E1.S les plus avancés.
Les ingénieurs Meta ont souligné dans l'article que l'entreprise s'engage en faveur de l'innovation ouverte de la pile matérielle d'IA. "Alors que nous regardons vers l'avenir, nous reconnaissons que ce qui a fonctionné avant ou actuellement ne suffira peut-être pas à répondre aux besoins futurs. C'est pourquoi nous évaluons et améliorons constamment notre infrastructure.
Meta est membre de l'AI Alliance one récemment créée. " . L'alliance vise à créer un écosystème ouvert qui augmente la transparence et la confiance dans le développement de l'IA et garantit que chacun bénéficie de ses innovations.
Meta a également révélé qu'elle continuerait à acheter davantage de GPU Nvidia H100 et prévoyait d'avoir plus de 350 000 GPU d'ici la fin de cette année. Ces GPU seront utilisés pour continuer à construire une infrastructure d’IA, ce qui signifie que des clusters GPU de plus en plus puissants seront disponibles à l’avenir.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Application de l'intelligence artificielle dans la vie
Application de l'intelligence artificielle dans la vie
 Quel est le concept de base de l'intelligence artificielle
Quel est le concept de base de l'intelligence artificielle
 Tutoriel sur la fabrication de pièces inscrites
Tutoriel sur la fabrication de pièces inscrites
 Que signifie le HD du téléphone portable ?
Que signifie le HD du téléphone portable ?
 La différence entre le compte de service WeChat et le compte officiel
La différence entre le compte de service WeChat et le compte officiel
 Comment référencer CSS en HTML
Comment référencer CSS en HTML
 Trois méthodes d'encodage couramment utilisées
Trois méthodes d'encodage couramment utilisées
 Est-ce que plus la fréquence du processeur de l'ordinateur est élevée, mieux c'est ?
Est-ce que plus la fréquence du processeur de l'ordinateur est élevée, mieux c'est ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



