


À mesure que les grands modèles de langage tels que GPT-4 sont de plus en plus intégrés à la robotique, l'intelligence artificielle s'installe progressivement dans le monde réel. Par conséquent, les recherches liées à l’intelligence incarnée attirent également de plus en plus d’attention. Parmi de nombreux projets de recherche, la série de robots « RT » de Google a toujours été à l'avant-garde, et cette tendance a commencé à s'accélérer récemment (voir « Les grands modèles reconstruisent des robots, Comment Google Deepmind définit l'intelligence incorporée dans le futur » pour plus de détails).

En juillet de l'année dernière, Google DeepMind a lancé RT-2, le premier modèle au monde capable de contrôler des robots pour une interaction visuel-langage-action (VLA). En donnant simplement des instructions de manière conversationnelle, RT-2 peut identifier Swift sur un grand nombre de photos et lui livrer une canette de Coca.
Maintenant, ce robot a encore évolué. La dernière version du robot RT s'appelle « RT-H ». Elle peut améliorer la précision de l'exécution des tâches et l'efficacité de l'apprentissage en décomposant des tâches complexes en instructions linguistiques simples, puis en convertissant ces instructions en actions du robot. Par exemple, étant donné une tâche telle que "mettre le couvercle sur le pot de pistaches" et une image de scène, RT-H utilisera un modèle de langage visuel (VLM) pour prédire les actions du langage (mouvement), telles que "bouger le bras vers l'avant". " et " Faites pivoter le bras vers la droite ", puis prédisez l'action du robot en fonction de ces actions verbales.

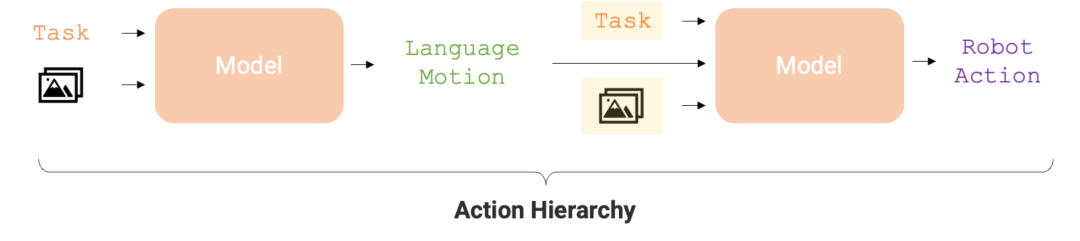
Le niveau d'action est crucial pour optimiser la précision et l'efficacité d'apprentissage de l'exécution des tâches du robot. Cette structure hiérarchique permet au RT-H d'être nettement plus performant que le RT-2 dans diverses tâches du robot, offrant ainsi un chemin d'exécution plus efficace pour le robot.

Voici les détails du document.

Le langage est le moteur du raisonnement humain, qui nous permet de décomposer des concepts complexes en composants plus simples, correct nos malentendus et généraliser les concepts dans de nouveaux contextes. Ces dernières années, les robots ont également commencé à utiliser la structure efficace et combinée du langage pour décomposer des concepts de haut niveau, fournir une correction linguistique ou réaliser une généralisation dans de nouveaux environnements.
Ces études suivent généralement un paradigme commun : confrontés à une tâche de haut niveau décrite dans le langage (comme "ramasser la canette de Coca"), ils apprennent des stratégies pour mapper les observations et les descriptions de tâches dans le langage à un robot de bas niveau. actions, qui doivent être réalisées grâce à des ensembles de données multitâches à grande échelle. L'avantage du langage dans ces scénarios est qu'il code une structure partagée entre des tâches similaires (par exemple, « ramasser la canette de Coca » contre « ramasser la pomme »), réduisant ainsi les données requises pour apprendre les mappages des tâches aux actions. Cependant, à mesure que les tâches deviennent plus diversifiées, le langage utilisé pour décrire chaque tâche devient également plus diversifié (par exemple, « prendre une canette de Coca » par rapport à « remplir un verre d'eau »), ce qui rend l'apprentissage entre différentes tâches uniquement par le biais d'un langage de haut niveau. Il devient plus difficile de partager les structures entre
Afin d'apprendre diverses tâches, les chercheurs visent à capturer plus précisément les similitudes entre ces tâches.
Ils ont découvert que le langage peut non seulement décrire des tâches de haut niveau, mais aussi expliquer en détail comment accomplir les tâches - ce type de représentation est plus délicat et plus proche d'actions spécifiques. Par exemple, la tâche consistant à « ramasser une canette de Coca » peut être décomposée en une série d'étapes plus détaillées, à savoir le « mouvement du langage » : d'abord « tendre le bras vers l'avant », puis « saisir la canette » et enfin « lever le bras ». le bras vers le haut"". L’idée centrale des chercheurs est qu’en utilisant les actions verbales comme couche intermédiaire entre les descriptions de tâches de haut niveau et les actions de bas niveau, elles peuvent être utilisées pour construire une hiérarchie d’actions formée par des actions verbales.
Il y a plusieurs avantages à établir ce niveau d'action :

Compte tenu des avantages ci-dessus des actions linguistiques, des chercheurs de Google DeepMind ont conçu un cadre de bout en bout - RT-H (Robot Transformer with Action Hierarchies, c'est-à-dire des robots transformateurs utilisant des niveaux d'action) , en se concentrant sur l'apprentissage de ce niveau d'action. RT-H comprend comment effectuer une tâche à un niveau détaillé en analysant les observations et les descriptions de tâches de haut niveau pour prédire les instructions d'action verbales actuelles. Ensuite, à l'aide de ces observations, tâches et actions verbales déduites, RT-H prédit les actions correspondantes pour chaque étape. Les actions verbales fournissent un contexte supplémentaire dans le processus pour aider à prédire plus précisément des actions spécifiques (zone violette sur la figure 1).
De plus, ils ont développé une méthode automatisée pour extraire des ensembles d'actions linguistiques simplifiées de la proprioception du robot, créant ainsi une riche base de données de plus de 2 500 actions linguistiques sans avoir besoin d'annotation manuelle. L'architecture du modèle de
RT-H s'appuie sur RT-2, qui est un modèle de langage visuel (VLM) à grande échelle formé conjointement sur des données visuelles et linguistiques à l'échelle Internet pour améliorer les effets d'apprentissage des politiques. RT-H utilise un modèle unique pour gérer à la fois les actions linguistiques et les requêtes d'action, en tirant parti de connaissances approfondies à l'échelle d'Internet pour alimenter chaque niveau de la hiérarchie des actions.
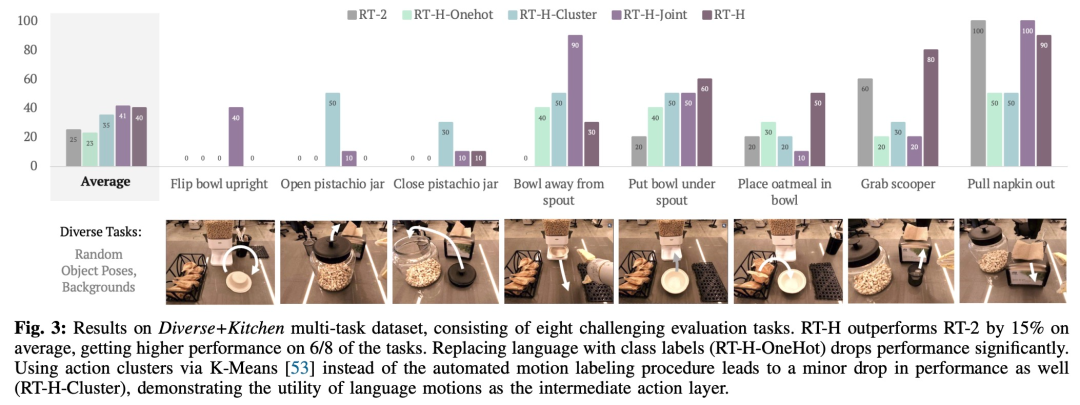
Lors d'expériences, les chercheurs ont découvert que l'utilisation de la hiérarchie d'actions du langage peut apporter des améliorations significatives lors du traitement de divers ensembles de données multitâches, améliorant les performances de 15 % sur une gamme de tâches par rapport au RT-2. Ils ont également constaté que les modifications apportées aux mouvements de parole entraînaient des taux de réussite presque parfaits sur la même tâche, démontrant la flexibilité et l'adaptabilité situationnelle des mouvements de parole appris. De plus, en affinant le modèle d'intervention par l'action linguistique, ses performances dépassent de 50 % les méthodes d'apprentissage par imitation interactive SOTA (telles que IWR). En fin de compte, ils ont prouvé que les actions linguistiques dans RT-H peuvent mieux s'adapter aux changements de scène et d'objet, montrant de meilleures performances de généralisation que RT-2.
Pour capturer efficacement la structure partagée dans des ensembles de données multitâches (non représentés par des descriptions de tâches de haut niveau), RT-H vise à apprendre à exploiter explicitement les politiques au niveau de l'action.
Plus précisément, l'équipe de recherche a introduit la couche intermédiaire de prédiction de l'action linguistique dans l'apprentissage des politiques. Les actions linguistiques qui décrivent le comportement précis des robots peuvent capturer des informations utiles à partir d'ensembles de données multitâches et générer des politiques hautes performances. Les actions linguistiques peuvent à nouveau entrer en jeu lorsque la politique apprise est difficile à exécuter : elles fournissent une interface intuitive pour une correction humaine en ligne pertinente à un scénario donné. Les politiques formées sur les actions vocales peuvent naturellement suivre des corrections humaines de bas niveau et mener à bien des tâches à partir des données de correction. De plus, la stratégie peut même être entraînée sur des données corrigées par la langue et améliorer encore ses performances.
Comme le montre la figure 2, RT-H comporte deux étapes clés : d'abord prédire les actions verbales sur la base des descriptions de tâches et des observations visuelles, puis déduire des actions précises sur la base des actions verbales prédites, des tâches spécifiques et des résultats d'observation.
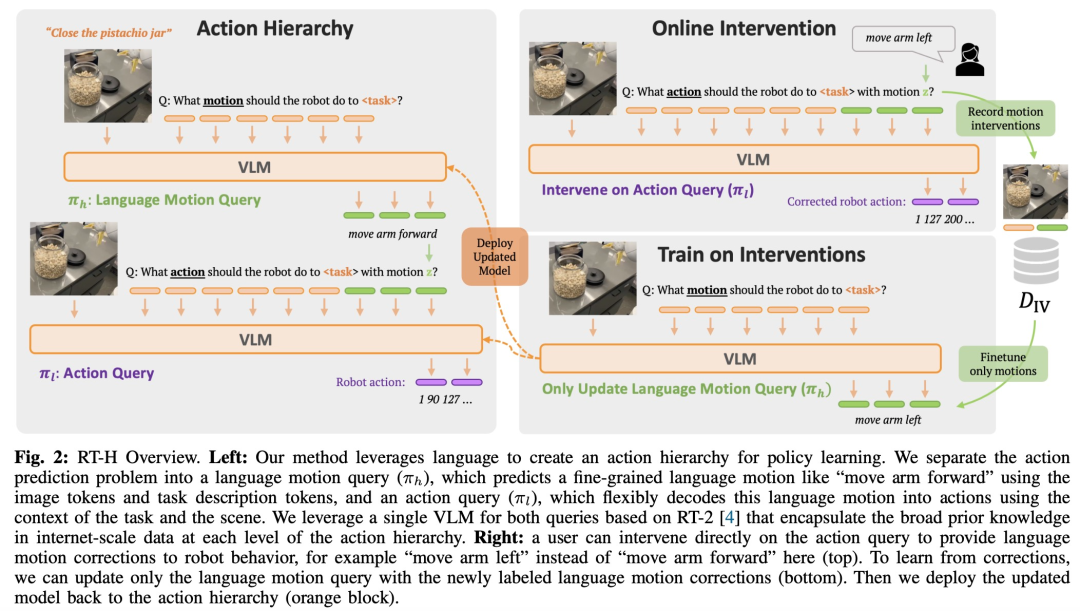
RT-H utilise le réseau fédérateur VLM et suit le processus de formation de RT-2 pour l'instanciation. Semblable au RT-2, RT-H exploite des connaissances approfondies en langage naturel et en traitement d'images à partir de données à l'échelle Internet grâce à une formation collaborative. Pour intégrer ces connaissances préalables à tous les niveaux de la hiérarchie des actions, un seul modèle apprend simultanément les actions verbales et les requêtes d'action.
Afin d'évaluer de manière exhaustive les performances du RT-H, l'équipe de recherche a posé quatre questions expérimentales clés :
En termes d'ensemble de données, cette étude utilise un vaste ensemble de données multitâches contenant 100 000 échantillons de démonstration avec des poses et des arrière-plans d'objets aléatoires. Cet ensemble de données combine les ensembles de données suivants :
L'étude appelle cet ensemble de données combiné l'ensemble de données Diverse+Kitchen (D+K) et utilise un programme automatisé pour l'étiqueter pour les actions verbales. Pour évaluer les performances des RT-H formés sur l'ensemble de données complet Diverse+Kitchen, l'étude a évalué huit tâches spécifiques, notamment :
1) Placer le bol à la verticale sur le comptoir
2) Ouvrir le pot de pistache
3) Fermez le pot à pistaches
4) Éloignez le bol du distributeur de céréales
5) Placez le bol sous le distributeur de céréales
6) Placez les flocons d'avoine Placer dans le bol
7) Récupérer la cuillère du panier
8) Tirer la serviette du distributeur
Ces huit tâches ont été choisies car elles nécessitent des séquences de mouvements complexes et une grande précision.
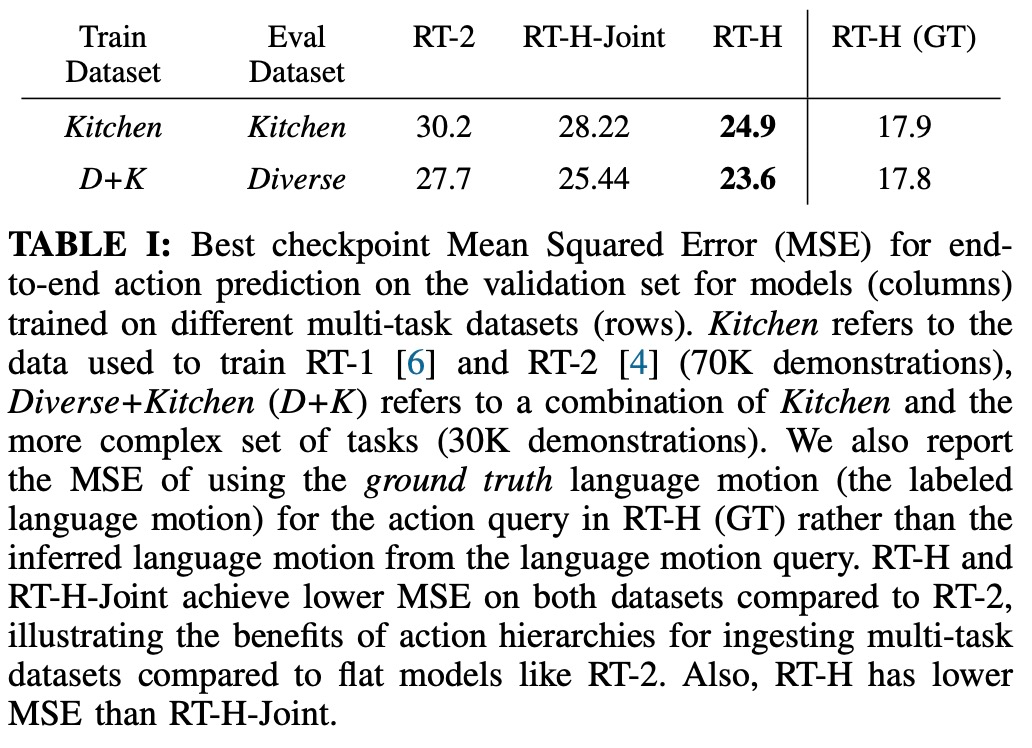
Le tableau ci-dessous donne le MSE minimum pour les points de contrôle de formation RT-H, RT-H-Joint et RT-2 lors de la formation sur l'ensemble de données Diverse+Kitchen ou l'ensemble de données Kitchen. Le MSE de RT-H est environ 20 % inférieur à celui de RT-2, et le MSE de RTH-Joint est inférieur de 5 à 10 % à celui de RT-2, ce qui indique que la hiérarchie des actions peut aider à améliorer la prédiction des actions hors ligne dans de grands projets multi- ensembles de données de tâches. RT-H (GT) utilise la métrique MSE de vérité terrain et atteint un écart de 40 % par rapport au MSE de bout en bout, indiquant que les actions linguistiques correctement étiquetées ont une valeur informationnelle élevée pour prédire les actions.
La figure 4 montre plusieurs exemples d'actions contextuelles tirées de l'évaluation en ligne RT-H. Comme on peut le constater, la même action verbale entraîne souvent des changements subtils dans les actions pour accomplir la tâche, tout en respectant l'action verbale de niveau supérieur.

Comme le montre la figure 5, l'équipe de recherche a démontré la flexibilité du RT-H en intervenant en ligne avec les mouvements linguistiques dans le RT-H.

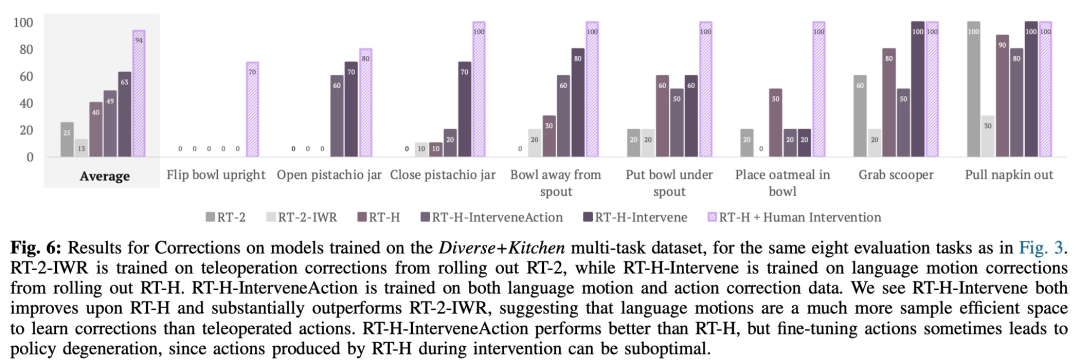
Cette étude a également utilisé des expériences comparatives pour analyser l'effet de la correction. Les résultats sont présentés dans la figure 6 ci-dessous :
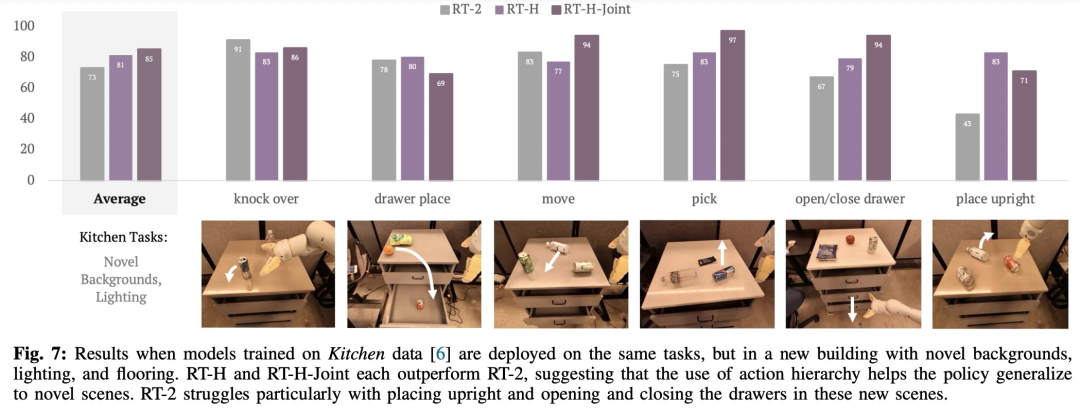
Comme le montre la figure 7, RT-H et RT-H-. Les articulations ont des effets différents sur la scène. Les changements sont sensiblement plus robustes :
En fait, il existe une structure partagée entre des tâches apparemment différentes. Par exemple, chacune de ces tâches nécessite certains comportements de sélection pour démarrer la tâche, et en apprenant la structure partagée des actions linguistiques entre différentes tâches, RT-H peut y parvenir. . Reprendre l'étape sans aucune correction.

Même lorsque RT-H n'est plus capable de généraliser ses prédictions d'actions verbales, les corrections d'actions verbales se généralisent souvent, donc seules quelques corrections sont nécessaires pour mener à bien la tâche. Cela démontre le potentiel des actions verbales pour élargir la collecte de données sur de nouvelles tâches.
Les lecteurs intéressés peuvent lire le texte original de l'article pour en savoir plus sur le contenu de la recherche.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Linux ajoute une méthode de source de mise à jour
Linux ajoute une méthode de source de mise à jour
 Connaissances nécessaires pour le front-end Web
Connaissances nécessaires pour le front-end Web
 Quel est le mot de passe du service mobile ?
Quel est le mot de passe du service mobile ?
 Comment résoudre l'écran bleu 0x0000006b
Comment résoudre l'écran bleu 0x0000006b
 Qu'est-ce qu'un ETF Bitcoin Futures ?
Qu'est-ce qu'un ETF Bitcoin Futures ?
 Applications logicielles de spéculation monétaire formelles et faciles à utiliser recommandées en 2024
Applications logicielles de spéculation monétaire formelles et faciles à utiliser recommandées en 2024
 Prévisions futures d'ondulation
Prévisions futures d'ondulation
 Que dois-je faire si mon ordinateur ne s'allume pas ?
Que dois-je faire si mon ordinateur ne s'allume pas ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



