


Dans les pratiques antérieures, la fusion de modèles a été largement utilisée, en particulier dans les modèles discriminants, où elle est considérée comme une méthode permettant d'améliorer régulièrement les performances. Cependant, pour les modèles de langage génératifs, leur fonctionnement n’est pas aussi simple que pour les modèles discriminants en raison du processus de décodage impliqué.
De plus, en raison de l'augmentation du nombre de paramètres des grands modèles, dans des scénarios avec des échelles de paramètres plus grandes, les méthodes qui peuvent être envisagées avec un apprentissage d'ensemble simple sont plus limitées que l'apprentissage automatique à faibles paramètres, comme l'empilement classique, boosting et autres méthodes, car Le problème des paramètres du modèle empilé ne peut pas être facilement étendu. Par conséquent, l’apprentissage d’ensemble pour les grands modèles nécessite un examen attentif.
Ci-dessous, nous expliquons cinq méthodes d'intégration de base, à savoir l'intégration de modèles, l'intégration probabiliste, l'apprentissage par greffage, le vote participatif et le MOE.
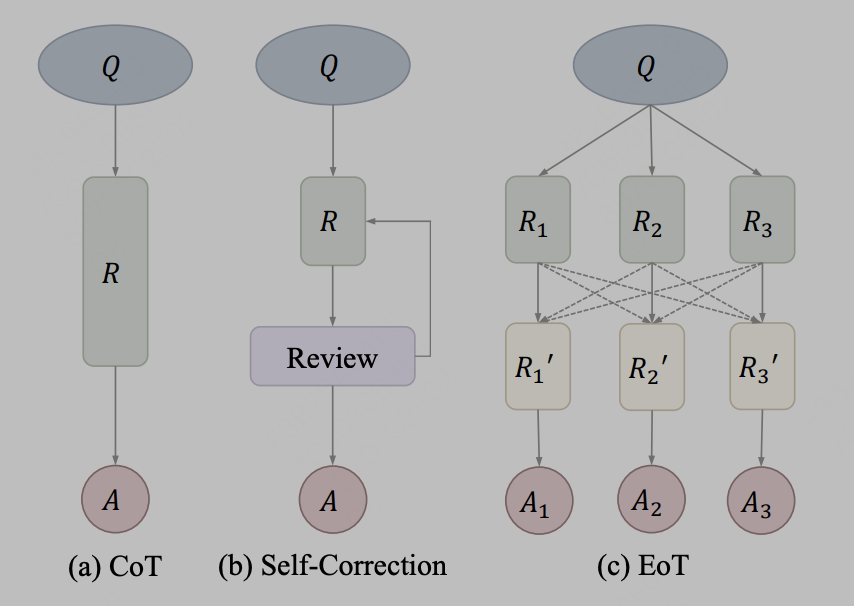
L'intégration du modèle est relativement simple, c'est-à-dire que les grands modèles sont intégrés au niveau du texte de sortie. Par exemple, utilisez simplement les résultats de sortie de trois modèles LLama différents et saisissez-les comme invites dans le quatrième modèle pour. référence. En pratique, la transmission d'informations par texte peut être utilisée comme méthode de communication. La méthode représentative est EoT, qui vient de l'article « Exchange-of-Thought : Enhancing Large Language Model Capabilities through Cross-Model Communication ». Le cadre d'échange de pensées de s, connu sous le nom d'échange de pensées, est conçu pour faciliter la communication croisée entre les modèles afin d'améliorer la compréhension collective dans le processus de résolution de problèmes. Grâce à ce cadre, les modèles peuvent absorber le raisonnement d’autres modèles pour mieux coordonner et améliorer leurs propres solutions. Représenté par le diagramme dans l'article :
 Picture
Picture
Après que l'auteur ait traité CoT et les méthodes d'autocorrection comme le même concept, EoT propose une nouvelle méthode qui permet la transmission hiérarchique de messages entre plusieurs modèles. En communiquant entre modèles, ceux-ci peuvent s'appuyer sur le raisonnement et les processus de pensée de chacun, contribuant ainsi à résoudre les problèmes plus efficacement. Cette approche devrait améliorer les performances et la précision du modèle.
L'ensemble probabiliste présente des similitudes avec les méthodes traditionnelles d'apprentissage automatique. Par exemple, une méthode d'ensemble peut être formée en faisant la moyenne des résultats logit prédits par le modèle. Dans les grands modèles, des ensembles probabilistes peuvent être fusionnés au niveau des probabilités de sortie du vocabulaire du modèle de transformateur. Il est important de noter que cette opération nécessite que les vocabulaires des multiples modèles originaux fusionnés soient cohérents. Une telle méthode d'intégration peut améliorer les performances et la robustesse du modèle, le rendant plus adapté aux scénarios d'application pratiques.
Ci-dessous, nous donnons une implémentation simple du pseudocode.
kv_cache = NoneWhile True:input_ids = torch.tensor([[new_token]], dtype=torch.long, device='cuda')kv_cache1, kv_cache2 = kv_cache output1 = models[0](input_ids=input_ids, past_key_values=kv_cache1, use_cache=True)output2 = models[1](input_ids=input_ids, past_key_values=kv_cache2, use_cache=True)kv_cache = [output1.past_key_values, output2.past_key_values]prob = (output1.logits + output2.logits) / 2new_token = torch.argmax(prob, 0).item()
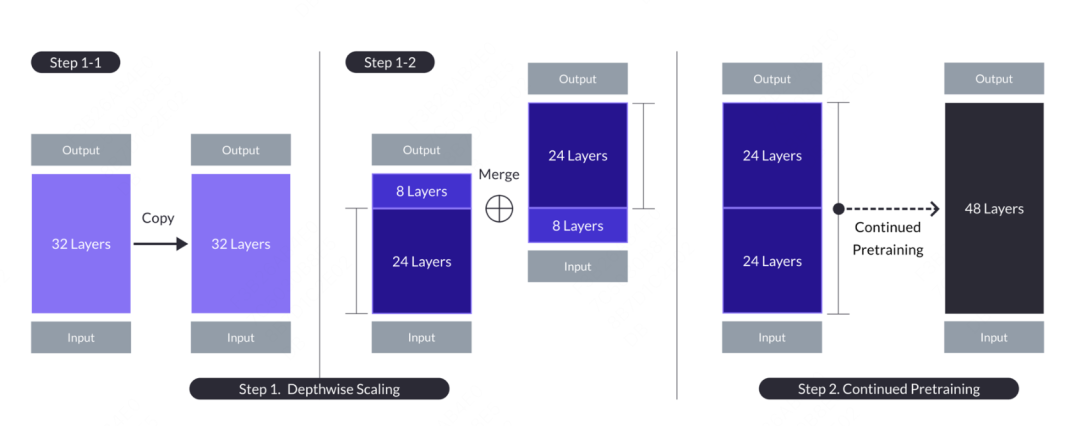
Le concept d'apprentissage par greffage vient du plantgo national de Kaggle Grandmaster, issu du concours d'exploration de données. Il s’agit essentiellement d’une sorte d’apprentissage par transfert, qui était à l’origine utilisée pour décrire la méthode consistant à utiliser la sortie d’un modèle d’arbre comme entrée d’un autre modèle d’arbre. Cette méthode s’apparente au greffage dans la reproduction des arbres, d’où son nom. Dans les grands modèles, il existe également l'application de l'apprentissage par greffage. Le nom du modèle est SOLAR. L'article vient de "SOLAR 10.7B: Scaling Large Language Models with Simple but Effective Depth Up-Scaling". Grafting de modèle. Différent du greffage de l'apprentissage dans l'apprentissage automatique, le grand modèle ne fusionne pas directement les résultats de probabilité d'un autre modèle, mais greffe une partie de la structure et des poids au modèle de fusion et subit un certain processus de pré-entraînement pour le réaliser. Les paramètres du modèle peuvent être adaptés aux nouveaux modèles. L'opération spécifique consiste à copier le modèle de base contenant n couches pour une modification ultérieure. Ensuite, les m dernières couches sont supprimées du modèle d'origine et les m premières couches sont supprimées de sa copie, ce qui donne lieu à deux modèles de couches n-m différents. Enfin, les deux modèles sont concaténés pour former un modèle à l'échelle avec 2*(nm) couches.
Lorsque vous avez besoin de créer un modèle cible à 48 couches, vous pouvez envisager de prendre les 24 premières couches et les 24 dernières couches de deux modèles de 32 couches et de les connecter pour former un nouveau modèle de 48 couches. Ensuite, le modèle combiné est ensuite pré-entraîné. En général, la pré-formation continue nécessite moins de volume de données et de ressources informatiques qu’une formation à partir de zéro.
 Photos
Photos
Après avoir poursuivi la pré-formation, une opération d'alignement doit être effectuée, qui comprend deux processus, à savoir la mise au point des instructions et le DPO. Le réglage fin de l'instruction utilise des données d'instruction open source et les transforme en données d'instruction spécifiques aux mathématiques pour améliorer les capacités mathématiques du modèle. DPO remplace le RLHF traditionnel, qui est finalement devenu la version SOLAR-chat.
Le vote par crowdsourcing a été utilisé dans le plan de première place de la WSDM CUP de cette année et a été pratiqué dans les compétitions de générations précédentes. L'idée centrale est la suivante : si la phrase générée par un modèle est la plus similaire aux résultats de tous les modèles, alors cette phrase peut être considérée comme la moyenne de tous les modèles. De cette façon, la moyenne au sens de probabilité devient la moyenne des résultats de génération de jetons. Supposons qu'à partir d'un échantillon de test, nous ayons une réponse de candidat qui doit être agrégée. Pour chaque candidat, nous calculons le score de corrélation entre ) et () et les additionnons pour obtenir le score de qualité de (). Les sources peuvent intégrer une similarité cosinus de couche (notée emb_a_s), un ROUGE-L au niveau du mot (noté word_a_f) et un ROUGE-L au niveau du caractère (noté char_a_f). Voici quelques indicateurs de similarité construits artificiellement, y compris des indicateurs littéraux. et sémantique.
Adresse du code : https://github.com/zhangzhao219/WSDM-Cup-2024/tree/main
Dernier et le plus important, le modèle expert mixte grand modèle (Mélange d'experts ( MoE en abrégé), il s'agit d'une méthode d'architecture de modèle qui combine plusieurs sous-modèles (c'est-à-dire des « experts »). Elle vise à améliorer l'effet de prédiction global grâce au travail collaboratif de plusieurs experts. La structure du MoE peut améliorer considérablement les capacités de traitement. Le modèle et l'efficacité opérationnelle. L'architecture typique du MoE à grand modèle comprend un mécanisme de contrôle et une série de réseaux d'experts. Le mécanisme de contrôle est chargé d'attribuer dynamiquement le poids de chaque expert en fonction des données d'entrée pour déterminer la contribution finale de chaque expert. . Le degré de contribution au résultat ; en même temps, le mécanisme de sélection des experts sélectionnera une partie des experts pour participer au calcul de prédiction réel selon les instructions du signal de déclenchement. Cette conception réduit non seulement les exigences informatiques globales. , mais permet également au modèle de sélectionner le meilleur en fonction de différentes entrées.
Le mélange d'experts (MoE) n'est pas un concept nouveau récemment. Le concept de mélange d'experts remonte à l'article « Mélange adaptatif de ». Experts locaux" publié en 1991. Semblable à l'apprentissage d'ensemble, son objectif principal est de créer un mécanisme de coordination et de fusion pour un ensemble de réseaux d'experts indépendants. Dans une telle architecture, chaque réseau indépendant (c'est-à-dire "expert") est responsable du traitement d'un partie spécifique de l'ensemble de données, et se concentre sur une zone de données d'entrée spécifique. Ce sous-ensemble peut être orienté vers un certain sujet, un certain domaine, une certaine classification de problème, etc., et n'est pas un concept explicite
Dans le Face à différentes données d'entrée, la question clé est de savoir comment le système décide quel expert les gérera. Le Gating Network est là pour résoudre ce problème. Il détermine les responsabilités de travail de chaque expert en attribuant des pondérations à ces réseaux d'experts et à ces portes au cours du processus. l'ensemble du processus de formation. Le réseau de contrôle sera formé simultanément et ne nécessitera pas de manipulation manuelle explicite.
Au cours de la période 2010 à 2015, deux directions de recherche ont eu un impact important sur le développement ultérieur du Modèle Expert Mixte (MoE) :
组件化专家:在传统的MoE框架中,系统由一个门控网络和若干个专家网络构成。在支持向量机(SVM)、高斯过程以及其他机器学习方法的背景下,MoE常常被当作模型中的一个单独部分。然而,Eigen、Ranzato和Ilya等研究者提出了将MoE作为深层网络中一个内部组件的想法。这种创新使得MoE可以被整合进多层网络的特定位置中,从而使模型在变得更大的同时,也能保持高效。
条件计算:传统神经网络会在每一层对所有输入数据进行处理。在这段时期,Yoshua Bengio等学者开始研究一种基于输入特征动态激活或者禁用网络部分的方法。
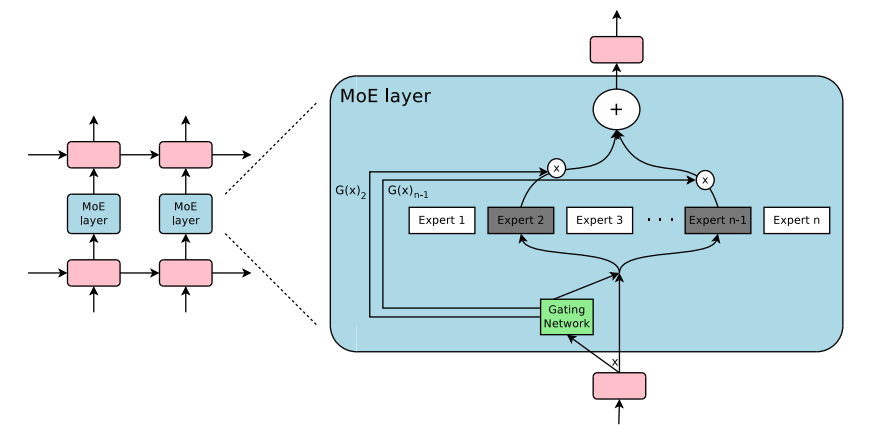
这两项研究的结合推动了混合专家模型在自然语言处理(NLP)领域的应用。尤其是在2017年,Shazeer和他的团队将这一理念应用于一个137亿参数的LSTM模型(这是当时在NLP领域广泛使用的一种模型架构,由Schmidhuber提出)。他们通过引入稀疏性来实现在保持模型规模巨大的同时,加快推理速度。这项工作主要应用于翻译任务,并且面对了包括高通信成本和训练稳定性问题在内的多个挑战。如图所示《Outrageously Large Neural Network》 中的MoE layer架构如下:
 图片
图片
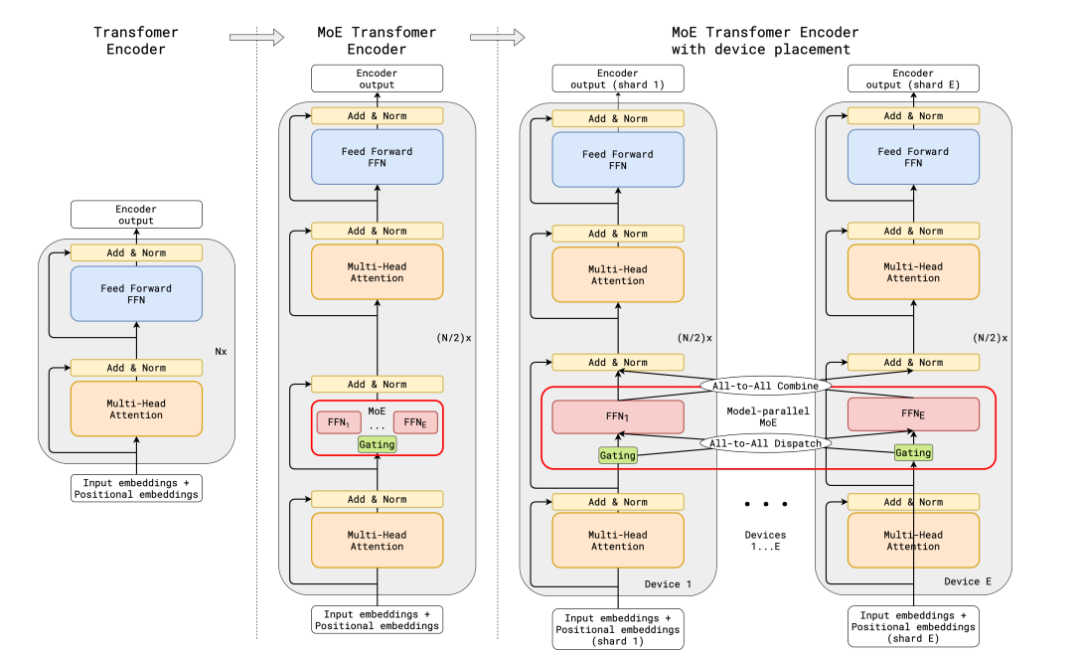
传统的MoE都集中在非transfomer的模型架构上,大模型时代的transfomer模型参数量达百亿级,如何在transformer上应用MoE并且把参数扩展到百亿级别,并且解决训练稳定性和推理效率的问题,成为MoE在大模型应用上的关键问题。谷歌提出了代表性的方法Gshard,成功将Transformer模型的参数量增加至超过六千亿,并以此提升模型水平。
在GShard框架下,编码器和解码器中的每个前馈网络(FFN)层被一种采用Top-2门控机制的混合专家模型(MoE)层所替代。下面的图示展现了编码器的结构设计。这样的设计对于执行大规模计算任务非常有利:当模型被分布到多个处理设备上时,MoE层在各个设备间进行共享,而其他层则在每个设备上独立复制。其架构如下图所示:
 图片
图片
为了确保训练过程中的负载均衡和效率,GShard提出了三种关键的技术,分别是损失函数,随机路由机制,专家容量限制。
辅助负载均衡损失函数:损失函数考量某个专家的buffer中已经存下的token数量,乘上某个专家的buffer中已经存下的token在该专家上的平均权重,构建这样的损失函数能让专家负载保持均衡。
随机路由机制:在Top-2的机制中,我们总是选择排名第一的专家,但是排名第二的专家则是通过其权重的比例来随机选择的。
专家容量限制:我们可以设置一个阈值来限定一个专家能够处理的token数量。如果两个专家的容量都已经达到了上限,那么令牌就会发生溢出,这时token会通过残差连接传递到下一层,或者在某些情况下被直接丢弃。专家容量是MoE架构中一个非常关键的概念,其存在的原因是所有的张量尺寸在编译时都已经静态确定,我们无法预知会有多少token分配给每个专家,因此需要预设一个固定的容量限制。
需要注意的是,在推理阶段,只有部分专家会被激活。同时,有些计算过程是被所有token共享的,比如自注意力(self-attention)机制。这就是我们能够用相当于12B参数的稠密模型计算资源来运行一个含有8个专家的47B参数模型的原因。如果我们使用Top-2门控机制,模型的参数量可以达到14B,但是由于自注意力操作是专家之间共享的,实际在模型运行时使用的参数量是12B。
整个MoeLayer的原理可以用如下伪代码表示:
M = input.shape[-1] # input维度为(seq_len, batch_size, M),M是注意力输出embedding的维度reshaped_input = input.reshape(-1, M)gates = softmax(einsum("SM, ME -> SE", reshaped_input, Wg)) #输入input,Wg是门控训练参数,维度为(M, E),E是MoE层中专家的数量,输出每个token被分配给每个专家的概率,维度为(S, E)combine_weights, dispatch_mask = Top2Gating(gates) #确定每个token最终分配给的前两位专家,返回相应的权重和掩码dispatched_expert_input = einsum("SEC, SM -> ECM", dispatch_mask, reshaped_input) # 对输入数据进行排序,按照专家的顺序排列,为分发到专家计算做矩阵形状整合h = enisum("ECM, EMH -> ECH", dispatched_expert_input, Wi) #各个专家计算分发过来的input,本质上是几个独立的全链接层h = relu(h)expert_outputs = enisum("ECH, EHM -> ECM", h, Wo) #各个专家的输出outputs = enisum("SEC, ECM -> SM", combine_weights, expert_outputs) #最后,进行加权计算,得到最终MoE-layer层的输出outputs_reshape = outputs.reshape(input.shape) # 从(S, M)变成(seq_len, batch_size, M)
Concernant l'amélioration architecturale de MoE, Switch Transformers a conçu une couche Switch Transformer spéciale qui peut traiter deux entrées indépendantes (c'est-à-dire deux jetons différents) et est équipée de quatre experts pour le traitement. Contrairement à l’idée originale des experts top2, Switch Transformers adopte une stratégie simplifiée des experts top1. Comme le montre la figure ci-dessous :
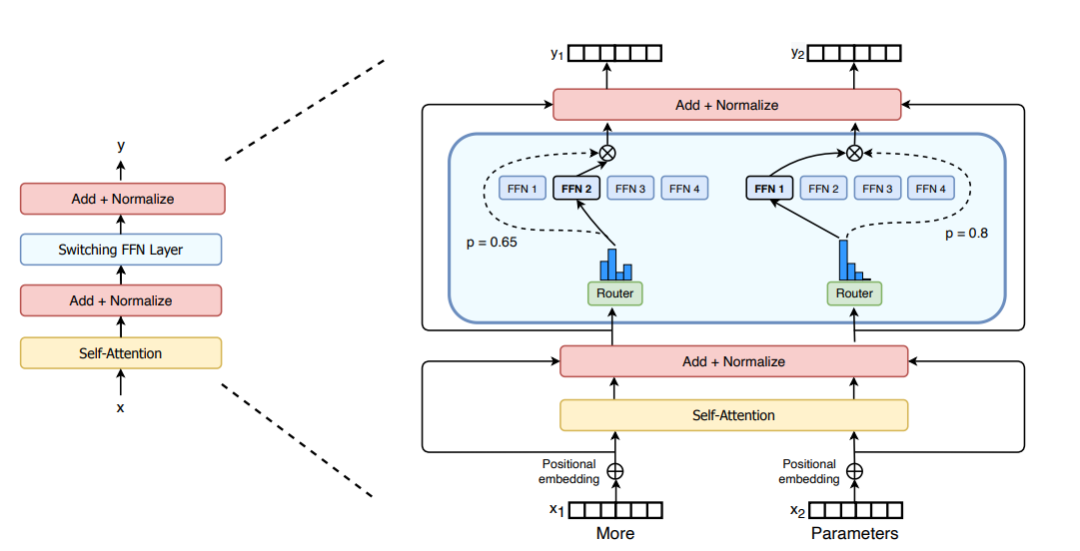 picture
picture
Différence, l'architecture de DeepSeek MoE, un grand modèle national bien connu, conçoit un expert partagé qui participe à l'activation à chaque fois. Sa conception est basée sur le principe que. un expert spécifique peut maîtriser un domaine de connaissances spécifique. Grâce à une segmentation fine des domaines de connaissances des experts, il est possible d'éviter qu'un seul expert ait besoin de maîtriser trop de connaissances, évitant ainsi la confusion des connaissances. Dans le même temps, la mise en place d’experts communs garantit que certaines connaissances universellement applicables sont utilisées dans chaque calcul.
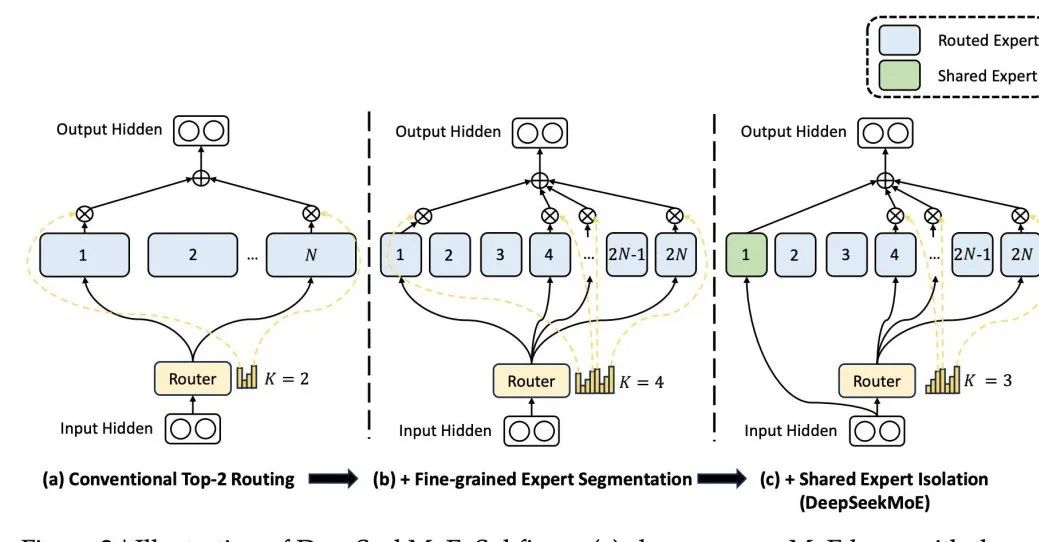 Photos
Photos
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Formules de permutation et de combinaison couramment utilisées
Formules de permutation et de combinaison couramment utilisées Adresse du portefeuille Yiooke
Adresse du portefeuille Yiooke Comment résoudre le délai d'attente
Comment résoudre le délai d'attente Quels sont les logiciels antivirus ?
Quels sont les logiciels antivirus ? Quels sont les attributs d'une balise ?
Quels sont les attributs d'une balise ? Paiement sans mot de passe Taobao
Paiement sans mot de passe Taobao Comment exécuter du code HTML dans vscode
Comment exécuter du code HTML dans vscode fil prix de la devise prix en temps réel
fil prix de la devise prix en temps réel




















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



