


Imaginez que lorsque vous êtes debout dans la pièce et que vous vous préparez à marcher vers la porte, planifiez-vous progressivement le chemin de l'autorégression ? En effet, votre chemin est généré dans son ensemble en une seule fois.
Les dernières recherches soulignent que le module de planification utilisant le modèle de diffusion peut générer en même temps une planification de trajectoire à longue séquence, ce qui est plus conforme à la prise de décision humaine. En outre, le modèle de diffusion peut également fournir des solutions plus optimisées pour les algorithmes d’intelligence décisionnelle existants en termes de représentation politique et de synthèse de données.
L'article de synthèse "Modèles de diffusion pour l'apprentissage par renforcement : une enquête" rédigé par une équipe de l'Université Jiao Tong de Shanghai résume l'application des modèles de diffusion dans les domaines liés à l'apprentissage par renforcement. L'analyse souligne que les algorithmes d'apprentissage par renforcement existants sont confrontés à des défis tels que l'accumulation d'erreurs de planification de longues séquences, des capacités limitées d'expression de politiques et des données interactives insuffisantes. Le modèle de diffusion a montré des avantages dans la résolution des problèmes d'apprentissage par renforcement et a été utilisé pour résoudre les problèmes ci-dessus. Les défis de longue date apportent de nouvelles idées. Lien papier : https://arxiv.org/abs/2311.01223

Cette revue vise à renforcer la diffusion modèle Les rôles dans l'apprentissage sont classés et les cas réussis de modèles de diffusion dans différents scénarios d'apprentissage par renforcement sont résumés. Enfin, la revue attend avec impatience l’orientation future du développement de l’utilisation de modèles de diffusion pour résoudre les problèmes d’apprentissage par renforcement.
La figure montre le rôle du modèle de diffusion dans le cycle classique de pool de relecture agent-environnement-expérience. Par rapport aux solutions traditionnelles, le modèle de diffusion introduit de nouveaux éléments dans le système et offre des opportunités d'interaction et d'apprentissage d'informations plus complètes. De cette manière, l'agent peut mieux s'adapter aux changements environnementaux et optimiser sa prise de décision
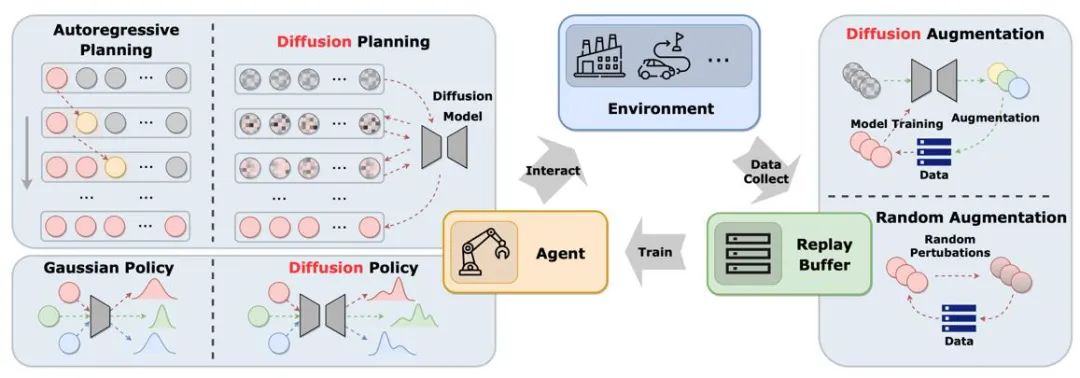
L'article est classé selon le rôle du modèle de diffusion dans l'apprentissage par renforcement. les méthodes d'application et les caractéristiques des modèles de diffusion sont comparées.
Figure 2 : Les différents rôles que jouent les modèles de diffusion dans l'apprentissage par renforcement.
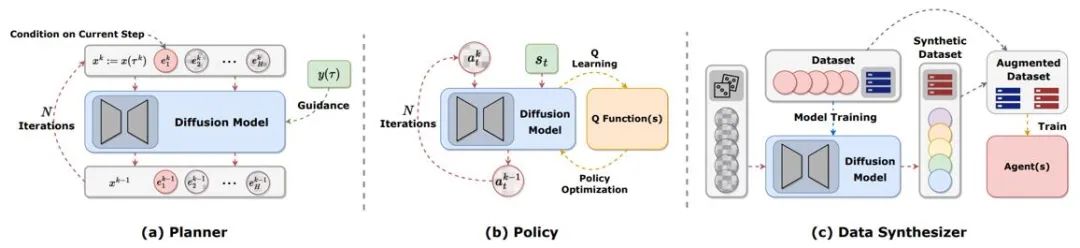
Planification de trajectoire
La planification dans l'apprentissage par renforcement fait référence à la prise de décisions en imagination en utilisant des modèles dynamiques, puis en sélectionnant les actions appropriées pour maximiser les récompenses cumulatives. Le processus de planification explore souvent des séquences d'actions et d'états pour améliorer l'efficacité à long terme des décisions. Dans les cadres d'apprentissage par renforcement basé sur modèle (MBRL), les séquences de planification sont souvent simulées de manière autorégressive, ce qui entraîne une accumulation d'erreurs. Les modèles de diffusion peuvent générer simultanément des séquences de planification en plusieurs étapes. Les cibles générées par les articles existants utilisant des modèles de diffusion sont très diverses, incluant (s,a,r), (s,a), uniquement s, uniquement a, etc. Pour générer des trajectoires très rémunératrices lors de l’évaluation en ligne, de nombreux travaux utilisent des techniques d’échantillonnage guidé avec ou sans classificateurs.
Représentation de la politique
Le planificateur de diffusion est plus similaire au MBRL dans l'apprentissage par renforcement traditionnel. En revanche, l'utilisation d'un modèle de diffusion comme politique est plus similaire à l'apprentissage par renforcement sans modèle. Diffusion-QL combine d'abord la stratégie de diffusion avec le framework Q-learning. Étant donné que les modèles de diffusion sont bien plus capables d'ajuster les distributions multimodales que les modèles traditionnels, les stratégies de diffusion fonctionnent bien dans les ensembles de données multimodales échantillonnées par plusieurs stratégies comportementales. La stratégie de diffusion est la même que la stratégie ordinaire, utilisant généralement l'état comme condition pour générer des actions tout en envisageant de maximiser la fonction Q (s, a). Des méthodes telles que Diffusion-QL ajoutent un terme de fonction de valeur pondérée lors de la formation du modèle de diffusion, tandis que CEP construit une cible de régression pondérée d'un point de vue énergétique et utilise la fonction de valeur comme facteur pour ajuster la distribution d'action apprise par le modèle de diffusion.
Synthèse de données
Le modèle de diffusion peut être utilisé comme synthétiseur de données pour atténuer le problème des données clairsemées dans l'apprentissage par renforcement hors ligne ou en ligne. Les méthodes traditionnelles d'amélioration des données d'apprentissage par renforcement ne peuvent généralement perturber que légèrement les données d'origine, tandis que la puissante capacité d'ajustement de distribution du modèle de diffusion lui permet d'apprendre directement la distribution de l'ensemble des données, puis d'échantillonner de nouvelles données de haute qualité.
Autres types
En plus des catégories ci-dessus, il existe également des œuvres éparses utilisant des modèles de diffusion par d'autres moyens. Par exemple, DVF estime une fonction de valeur à l'aide d'un modèle de diffusion. LDCQ code d'abord la trajectoire dans l'espace latent, puis applique le modèle de diffusion sur l'espace latent. PolyGRAD utilise un modèle de diffusion pour transférer dynamiquement l'environnement d'apprentissage, permettant une interaction entre les politiques et les modèles pour améliorer l'efficacité de l'apprentissage des politiques.
Apprentissage par renforcement hors ligne
L'introduction du modèle de diffusion aide la stratégie d'apprentissage par renforcement hors ligne à s'adapter à la distribution de données multimodale et étend la caractérisation de la stratégie capacité. Diffuser a d'abord proposé un algorithme de génération de trajectoire à haute récompense basé sur le guidage d'un classificateur et a inspiré de nombreux travaux ultérieurs. Dans le même temps, le modèle de diffusion peut également être appliqué dans des scénarios d’apprentissage par renforcement multitâches et multi-agents.
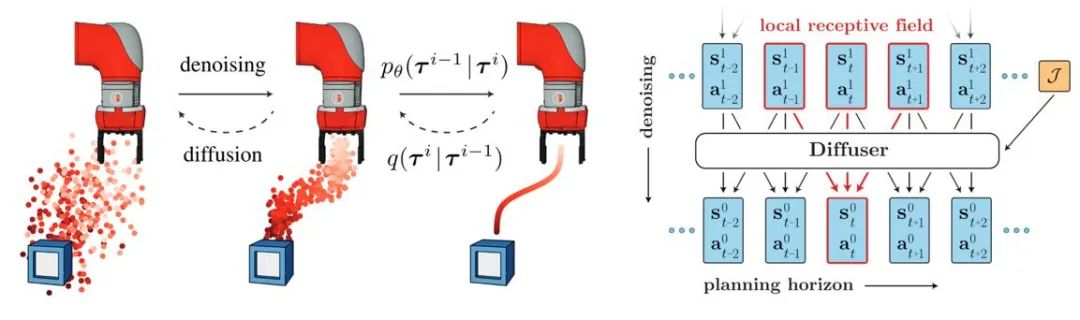
Figure 3 : Diagramme schématique du processus et du modèle de génération de trajectoire de diffuseur
Apprentissage par renforcement en ligne
Les chercheurs ont prouvé que le modèle de diffusion a également la capacité d'optimiser les fonctions et les stratégies de valeur dans apprentissage par renforcement en ligne. Par exemple, le DIPO ré-étiquete les données d'action et utilise la formation sur modèle de diffusion pour éviter l'instabilité de la formation guidée par les valeurs. Le CPQL a vérifié que le modèle de diffusion par échantillonnage en une seule étape en tant que stratégie peut équilibrer l'exploration et l'utilisation pendant l'interaction ;
Apprentissage par imitation
L'apprentissage par imitation reconstruit le comportement d'un expert en apprenant à partir de données de démonstration d'experts. L'application du modèle de diffusion permet d'améliorer les capacités de représentation politique et d'acquérir diverses compétences liées aux tâches. Dans le domaine du contrôle des robots, des recherches ont montré que les modèles de diffusion peuvent prédire des séquences d'action en boucle fermée tout en maintenant la stabilité temporelle. La politique de diffusion utilise un modèle de diffusion d'entrée d'image pour générer des séquences d'action de robot. Les expériences montrent que le modèle de diffusion peut générer des séquences d'action efficaces en boucle fermée tout en garantissant la cohérence temporelle.
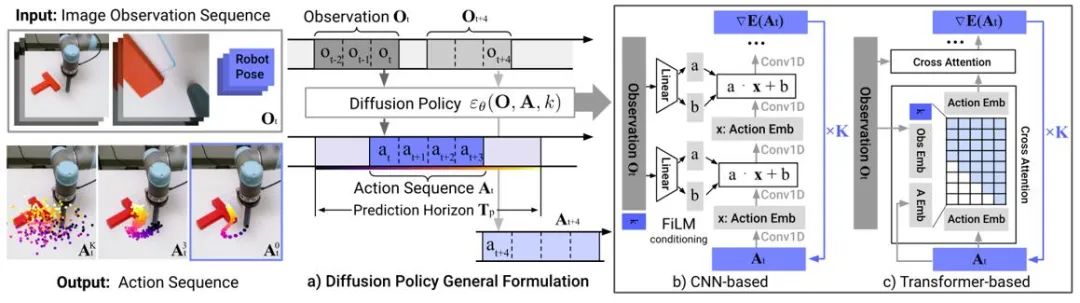
Figure 4 : Schéma du modèle de politique de diffusion
Génération de trajectoire
La génération de trajectoire du modèle de diffusion dans l'apprentissage par renforcement se concentre principalement sur deux types de tâches : la génération d'actions humaines et le contrôle de robots . Les données d'action ou les données vidéo générées par les modèles de diffusion sont utilisées pour construire des simulateurs de simulation ou former des modèles décisionnels en aval. UniPi entraîne un modèle de diffusion de génération vidéo en tant que stratégie générale et réalise un contrôle de robot transversal en accédant à différents modèles de dynamique inverse pour obtenir des commandes de contrôle sous-jacentes.
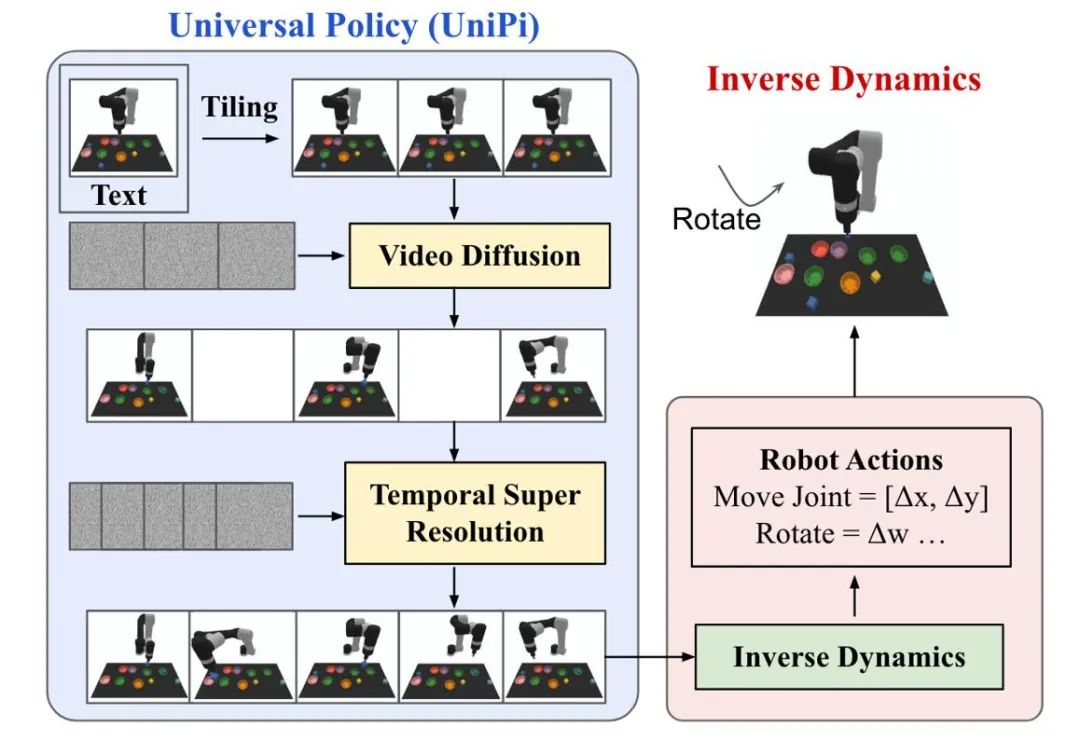
Figure 5 : Diagramme schématique du processus décisionnel d'UniPi.
Amélioration des données
Le modèle de diffusion peut également s'adapter directement à la distribution des données d'origine, fournissant une variété de données étendues dynamiquement tout en conservant l'authenticité. Par exemple, SynthER et MTDiff-s génèrent des informations complètes sur le transfert d'environnement de la tâche de formation via le modèle de diffusion et les appliquent à l'amélioration des politiques, et les résultats montrent que la diversité et la précision des données générées sont meilleures que les méthodes historiques.
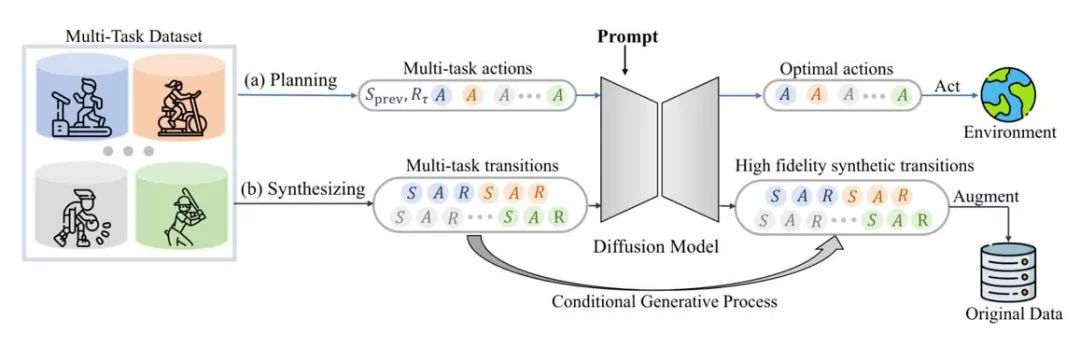
Figure 6 : Diagramme schématique de MTDiff pour la planification multitâche et l'amélioration des données
Environnement de simulation générative
Comme le montre la figure 1, recherche existante principalement Les modèles de diffusion sont utilisés pour surmonter les limites des agents et des pools de relecture d'expériences, et il existe relativement peu d'études sur l'utilisation de modèles de diffusion pour améliorer les environnements de simulation. Gen2Sim utilise le modèle de diffusion de graphes vincentiens pour générer divers objets manipulables dans l'environnement de simulation afin d'améliorer la capacité de généralisation des opérations de précision du robot. Les modèles de diffusion ont également le potentiel de générer des fonctions de transition d'état, des fonctions de récompense ou des comportements d'adversaires dans des interactions multi-agents dans un environnement de simulation.
Ajouter des contraintes de sécurité
En utilisant les contraintes de sécurité comme conditions d'échantillonnage du modèle, les agents basés sur le modèle de diffusion peuvent prendre des décisions qui satisfont à des contraintes spécifiques. L'échantillonnage guidé du modèle de diffusion permet d'ajouter continuellement de nouvelles contraintes de sécurité en apprenant des classificateurs supplémentaires, tandis que les paramètres du modèle d'origine restent inchangés, économisant ainsi une surcharge de formation supplémentaire.
Génération améliorée par récupération
La technologie de génération améliorée par récupération peut améliorer les capacités du modèle en accédant à des ensembles de données externes et est largement utilisée dans les grands modèles de langage. Les performances des modèles de décision basés sur la diffusion dans ces états peuvent également être améliorées en récupérant les trajectoires liées à l'état actuel de l'agent et en les introduisant dans le modèle. Si l'ensemble de données de récupération est constamment mis à jour, il est possible pour l'agent d'afficher de nouveaux comportements sans être recyclé.
Combiner plusieurs compétences
Combiné avec ou sans guidage de classificateur, le modèle de diffusion peut combiner plusieurs compétences simples pour accomplir des tâches complexes. Les premiers résultats de l’apprentissage par renforcement hors ligne indiquent également que les modèles de diffusion peuvent partager des connaissances entre différentes compétences, permettant ainsi de réaliser un transfert zéro ou un apprentissage continu en combinant différentes compétences.
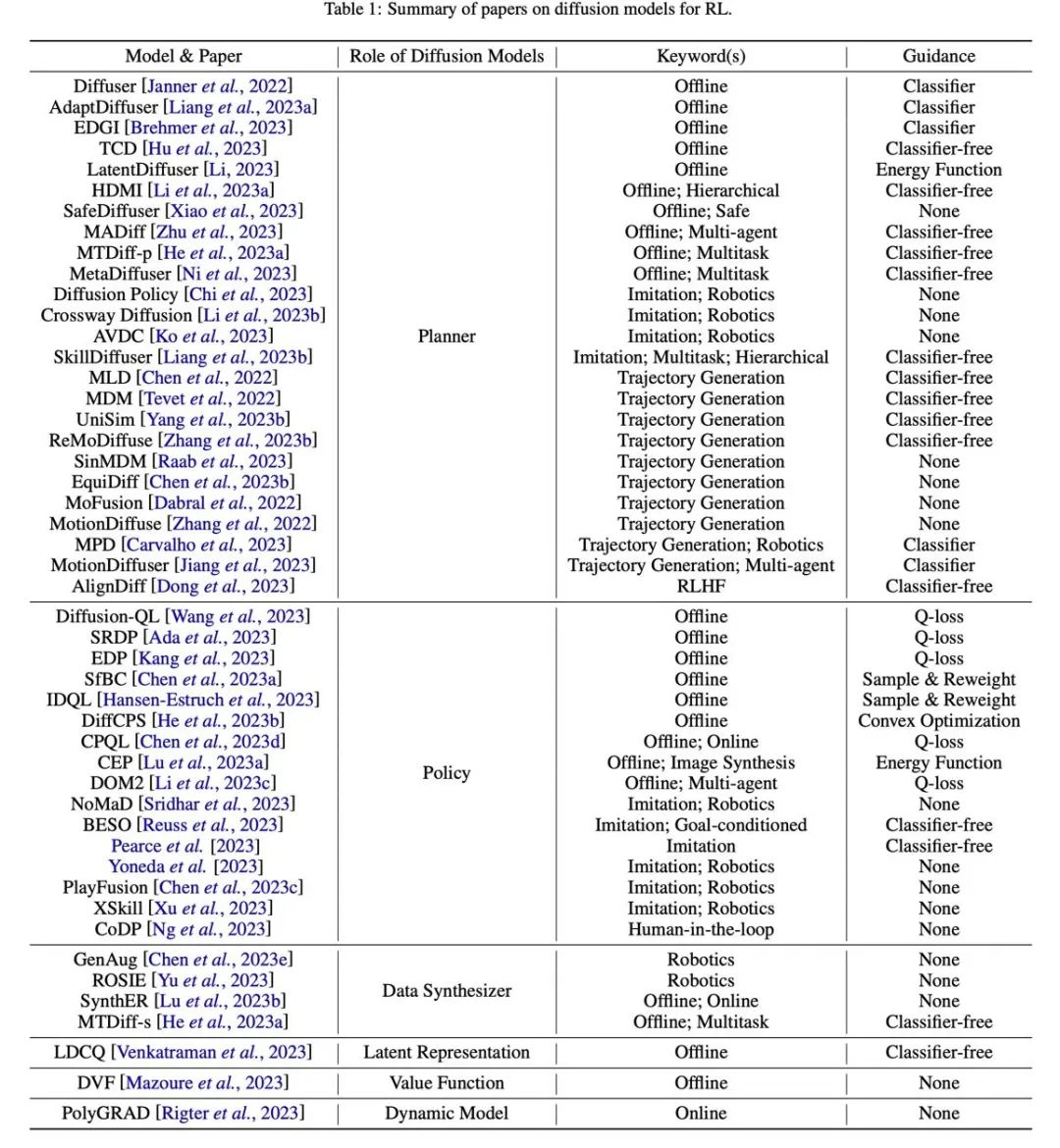
Figure 7 : Tableau récapitulatif et de classification des articles connexes.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



