


Meta FAIR Le projet de recherche auquel Tian Yuandong a participé a reçu de nombreux éloges le mois dernier. Dans leur article « MobileLLM : Optimizing Sub-billion Parameter Language Models for On-Device Use Cases », ils ont commencé à explorer comment optimiser les petits modèles avec moins d'un milliard de paramètres, dans le but d'atteindre l'objectif d'exécuter de grands modèles de langage sur les appareils mobiles. .
Le 6 mars, l'équipe de Tian Yuandong a publié les derniers résultats de recherche, axés cette fois sur l'amélioration de l'efficacité de la mémoire LLM. Outre Tian Yuandong lui-même, l'équipe de recherche comprend également des chercheurs du California Institute of Technology, de l'Université du Texas à Austin et de la CMU. Cette recherche vise à optimiser davantage les performances de la mémoire LLM et à fournir un soutien et des conseils pour le développement technologique futur.
Ils ont proposé conjointement une stratégie d'entraînement appelée GaLore (Gradient Low-Rank Projection), qui permet un apprentissage complet des paramètres. Par rapport aux méthodes adaptatives courantes de bas rang telles que LoRA, GaLore a une efficacité de mémoire plus élevée.
Cette étude montre pour la première fois que les modèles 7B peuvent être pré-entraînés avec succès sur un GPU grand public doté de 24 Go de mémoire (par exemple, NVIDIA RTX 4090) sans utiliser de parallélisme de modèle, de points de contrôle ou de stratégies de déchargement.

Adresse de l'article : https://arxiv.org/abs/2403.03507
Titre de l'article : GaLore : Formation LLM à mémoire efficace par projection de gradient de bas rang
Jetons un coup d'œil ensuite Le contenu principal de l'article.
Actuellement, les grands modèles de langage (LLM) ont montré un potentiel exceptionnel dans de nombreux domaines, mais nous devons également faire face à un problème réel, à savoir que la pré-formation et la mise au point du LLM nécessitent non seulement une grande quantité de ressources informatiques, mais nécessitent également une grande quantité de mémoire.
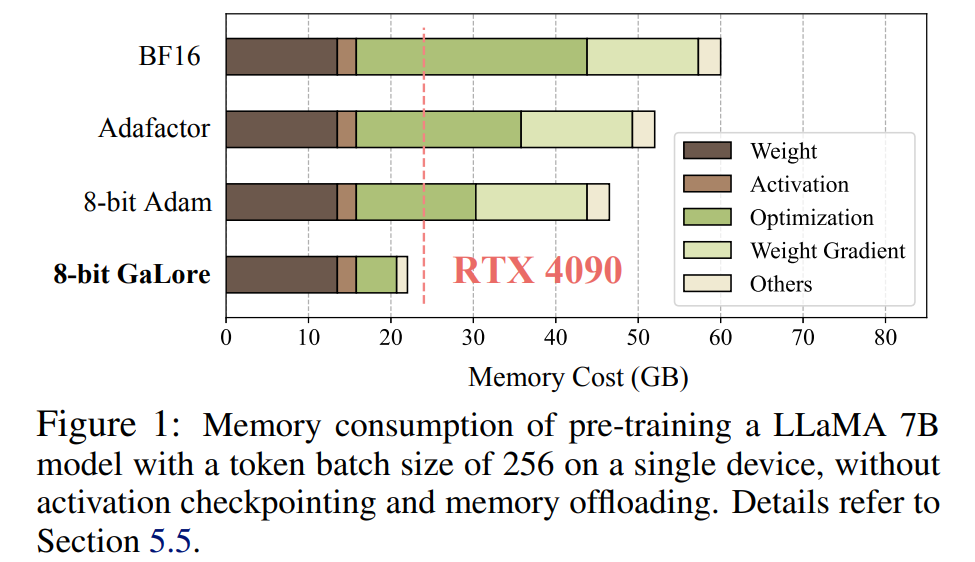
Les besoins en mémoire de LLM incluent non seulement des paramètres se chiffrant en milliards, mais également des gradients et des états d'optimisation (tels que l'impulsion du gradient et la variance d'Adam), qui peuvent être plus grands que le stockage lui-même. Par exemple, LLaMA 7B, pré-entraîné à partir de zéro en utilisant une seule taille de lot, nécessite au moins 58 Go de mémoire (14 Go pour les paramètres pouvant être entraînés, 42 Go pour les états d'optimisation Adam et les gradients de poids, et 2 Go pour les activations). Cela rend la formation LLM irréalisable sur les GPU grand public tels que le NVIDIA RTX 4090 avec 24 Go de mémoire.
Pour résoudre les problèmes ci-dessus, les chercheurs continuent de développer diverses techniques d'optimisation pour réduire l'utilisation de la mémoire pendant le pré-entraînement et le réglage fin.
Cette méthode réduit l'utilisation de la mémoire de 65,5 % dans les états d'optimisation, tout en maintenant l'efficacité et les performances de la pré-formation sur les architectures LLaMA 1B et 7B en utilisant l'ensemble de données C4 avec jusqu'à 19,7 B de jetons, et dans GLUE. l'efficacité et la performance de RoBERTa sur la tâche. Par rapport à la référence BF16, GaLore 8 bits réduit encore la mémoire de l'optimiseur de 82,5 % et la mémoire totale d'entraînement de 63,3 %.
Après avoir vu cette recherche, les internautes ont déclaré : « Il est temps d'oublier le cloud et le HPC. Avec GaLore, toute l'AI4Science sera réalisée sur un GPU grand public à 2 000 $. »
Tian Yuandong a déclaré : "Avec GaLore, il est désormais possible de pré-entraîner le modèle 7B sur des NVidia RTX 4090 avec 24 Go de mémoire.
Nous n'avons pas supposé une structure de poids de bas rang comme LoRA, mais avons prouvé que le gradient de poids est naturellement faible- Rank , et peut ainsi être projeté dans un espace (variable) de faible dimension. Par conséquent, nous économisons simultanément la mémoire pour les gradients, l'élan d'Adam et la variance
Ainsi, contrairement à LoRA, GaLore ne modifie pas la dynamique d'entraînement et peut être projeté dans un espace (variable) de faible dimension. utilisé à partir de zéro. Commencez le pré-entraînement du modèle 7B sans aucun échauffement gourmand en mémoire. GaLore peut également être utilisé pour un réglage fin, produisant des résultats comparables à LoRA.
Comme mentionné précédemment, GaLore est une stratégie d'entraînement qui permet un apprentissage complet des paramètres, mais qui est plus efficace en termes de mémoire que les méthodes adaptatives courantes de bas rang (telles que LoRA). L'idée clé de GaLore est d'utiliser la structure de bas rang qui évolue lentement du gradient 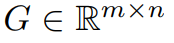 de la matrice de poids W, plutôt que d'essayer de se rapprocher directement de la matrice de poids sous une forme de bas rang.
de la matrice de poids W, plutôt que d'essayer de se rapprocher directement de la matrice de poids sous une forme de bas rang.
Cet article prouve d'abord théoriquement que la matrice de gradient G deviendra de bas rang au cours du processus de formation. Sur la base de la théorie, cet article utilise GaLore pour calculer deux matrices de projection 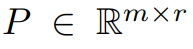 et
et 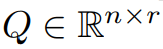 pour projeter la matrice de gradient G dans. Forme de bas rang P^⊤GQ. Dans ce cas, le coût en mémoire des états d'optimisation qui s'appuient sur des statistiques de gradient de composants peut être considérablement réduit. Comme le montre le tableau 1, GaLore est plus efficace en termes de mémoire que LoRA. En fait, cela peut réduire la mémoire jusqu'à 30 % pendant le pré-entraînement par rapport à LoRA.
pour projeter la matrice de gradient G dans. Forme de bas rang P^⊤GQ. Dans ce cas, le coût en mémoire des états d'optimisation qui s'appuient sur des statistiques de gradient de composants peut être considérablement réduit. Comme le montre le tableau 1, GaLore est plus efficace en termes de mémoire que LoRA. En fait, cela peut réduire la mémoire jusqu'à 30 % pendant le pré-entraînement par rapport à LoRA.

Cet article prouve que GaLore fonctionne bien en pré-entraînement et en mise au point. Lors de la pré-entraînement de LLaMA 7B sur l'ensemble de données C4, GaLore 8 bits combine un optimiseur 8 bits et une technologie de mise à jour du poids couche par couche pour atteindre des performances comparables au classement complet, avec un coût de mémoire inférieur à 10 % pour l'état d'optimisation.
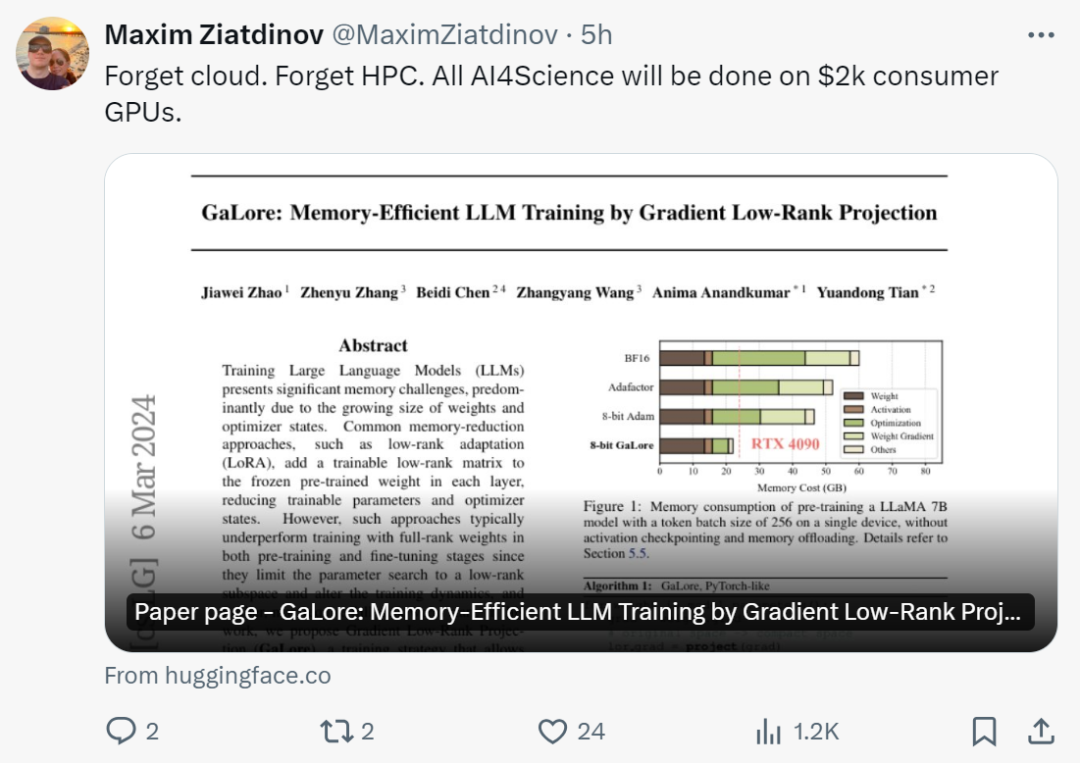
Il convient de noter que pour la pré-entraînement, GaLore maintient une mémoire faible tout au long du processus d'entraînement sans nécessiter une formation complète comme ReLoRA. Grâce à l'efficacité de la mémoire de GaLore, pour la première fois, LLaMA 7B peut être entraîné à partir de zéro sur un seul GPU avec 24 Go de mémoire (par exemple, sur un NVIDIA RTX 4090) sans aucune technique coûteuse de déchargement de mémoire (Figure 1).
En tant que méthode de projection de gradient, GaLore est indépendant du choix de l'optimiseur et peut être facilement connecté à un optimiseur existant avec seulement deux lignes de code, comme le montre l'algorithme 1.

La figure suivante montre l'algorithme pour appliquer GaLore à Adam :

Les chercheurs ont évalué la pré-formation de GaLore et le réglage fin du LLM. Toutes les expériences ont été réalisées sur le GPU NVIDIA A100.
Pour évaluer ses performances, les chercheurs ont appliqué GaLore pour former un grand modèle de langage basé sur LLaMA sur l'ensemble de données C4. L'ensemble de données C4 est une version énorme et aseptisée du corpus d'exploration Web Common Crawl, utilisé principalement pour pré-entraîner des modèles de langage et des représentations de mots. Afin de simuler au mieux le scénario de pré-formation réel, les chercheurs se sont entraînés sur une quantité suffisamment importante de données sans les dupliquer, avec des tailles de modèles allant jusqu'à 7 milliards de paramètres.
Cet article suit la configuration expérimentale de Lialin et al., utilisant une architecture basée sur LLaMA3 avec activation RMSNorm et SwiGLU. Pour chaque taille de modèle, à l'exception du taux d'apprentissage, ils ont utilisé le même ensemble d'hyperparamètres et ont exécuté toutes les expériences au format BF16 afin de réduire l'utilisation de la mémoire tout en ajustant le taux d'apprentissage pour chaque méthode avec le même budget de calcul et en signalant des performances optimales.
De plus, les chercheurs ont utilisé la tâche GLUE comme référence pour le réglage fin de GaLore et LoRA en termes d'efficacité mémoire. GLUE est une référence pour évaluer les performances des modèles PNL dans diverses tâches, notamment l'analyse des sentiments, la réponse aux questions et la corrélation de textes.
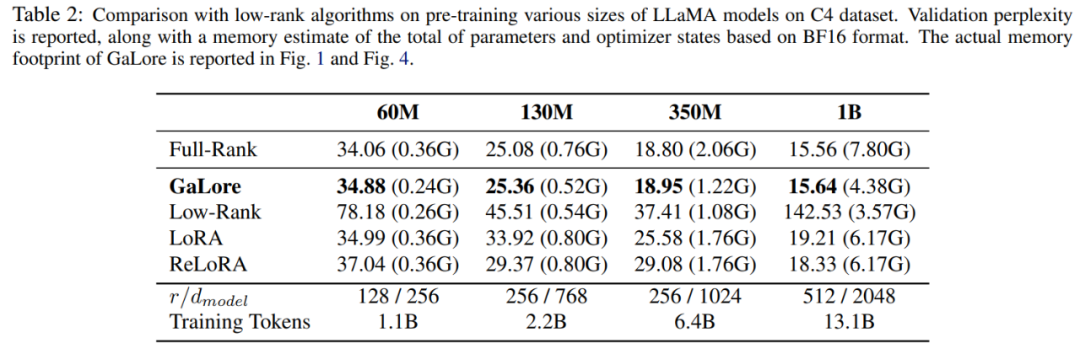
Cet article utilise d'abord l'optimiseur Adam pour comparer GaLore avec les méthodes de bas rang existantes, et les résultats sont présentés dans le tableau 2.
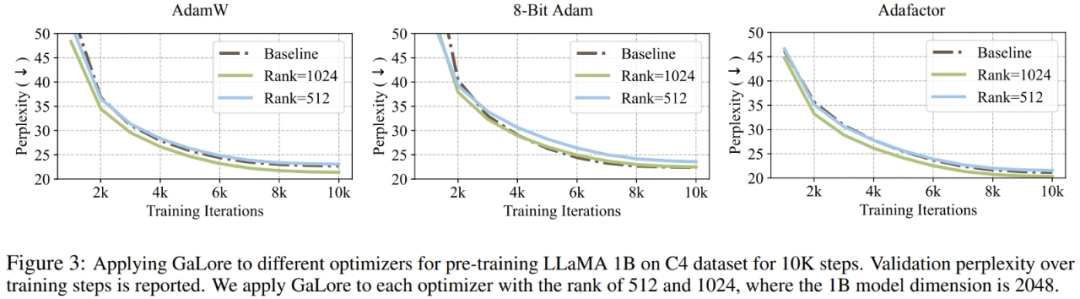
Les chercheurs ont prouvé que GaLore peut être appliqué à divers algorithmes d'apprentissage, en particulier des optimiseurs économes en mémoire, pour réduire davantage l'utilisation de la mémoire. Les chercheurs ont appliqué GaLore aux optimiseurs AdamW, Adam 8 bits et Adafactor. Ils utilisent l'Adafactor statistique de premier ordre pour éviter la dégradation des performances.
Les expériences les ont évalués sur l'architecture LLaMA 1B avec 10 000 étapes de formation, ont ajusté le taux d'apprentissage pour chaque paramètre et ont signalé les meilleures performances. Comme le montre la figure 3, le graphique ci-dessous démontre que GaLore fonctionne avec des optimiseurs populaires tels que AdamW, Adam 8 bits et Adafactor. De plus, l’introduction de très peu d’hyperparamètres n’affecte pas les performances de GaLore.
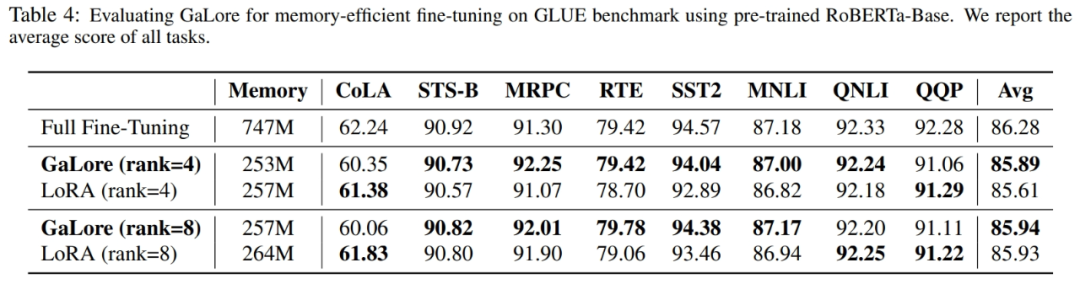
Comme le montre le tableau 4, GaLore peut atteindre des performances supérieures à LoRA avec moins d'utilisation de la mémoire dans la plupart des tâches. Cela démontre que GaLore peut être utilisé comme stratégie de formation full-stack économe en mémoire pour la pré-formation et le réglage fin du LLM.
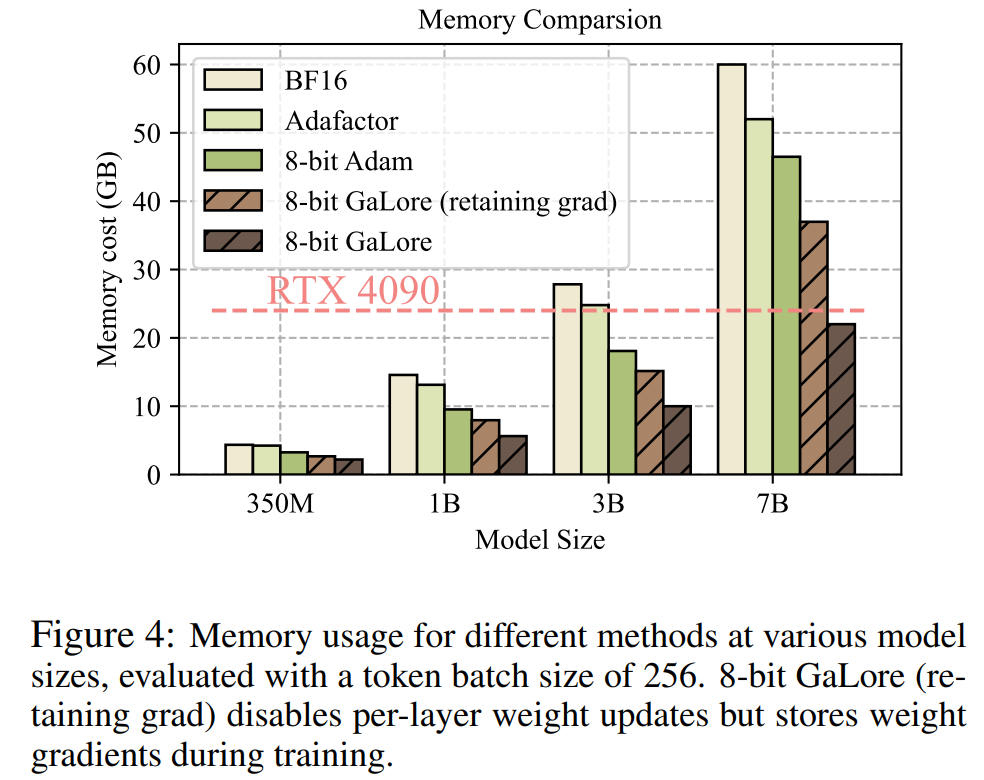
Comme le montre la figure 4, par rapport au benchmark BF16 et à Adam 8 bits, GaLore 8 bits nécessite beaucoup moins de mémoire, ne nécessitant que 22,0 Go de mémoire lors du pré-entraînement de LLaMA 7B, et la taille du lot de jetons de chaque GPU est plus petit (jusqu'à 500 jetons).
Pour plus de détails techniques, veuillez lire l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment lier des données dans une liste déroulante
Comment lier des données dans une liste déroulante
 qu'est-ce que le serveur
qu'est-ce que le serveur
 Tutoriel de saisie de symboles pleine largeur
Tutoriel de saisie de symboles pleine largeur
 Plateforme de change virtuelle
Plateforme de change virtuelle
 Que sont les boîtes mail internationales ?
Que sont les boîtes mail internationales ?
 ^quxjg$c
^quxjg$c
 Quels serveurs y a-t-il sur le Web ?
Quels serveurs y a-t-il sur le Web ?
 La différence entre le système Hongmeng et le système Android
La différence entre le système Hongmeng et le système Android








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



