


Au fur et à mesure que l'analyse technique de Sora se déroule, l'importance de l'infrastructure IA devient de plus en plus importante.
Un nouvel article de Byte et de l'Université de Pékin a attiré l'attention à ce moment-là :
L'article a révélé que le cluster Wanka construit par Byte peut compléter le modèle réduit GPT-3 (175B) en 1,75 jours ) formation .
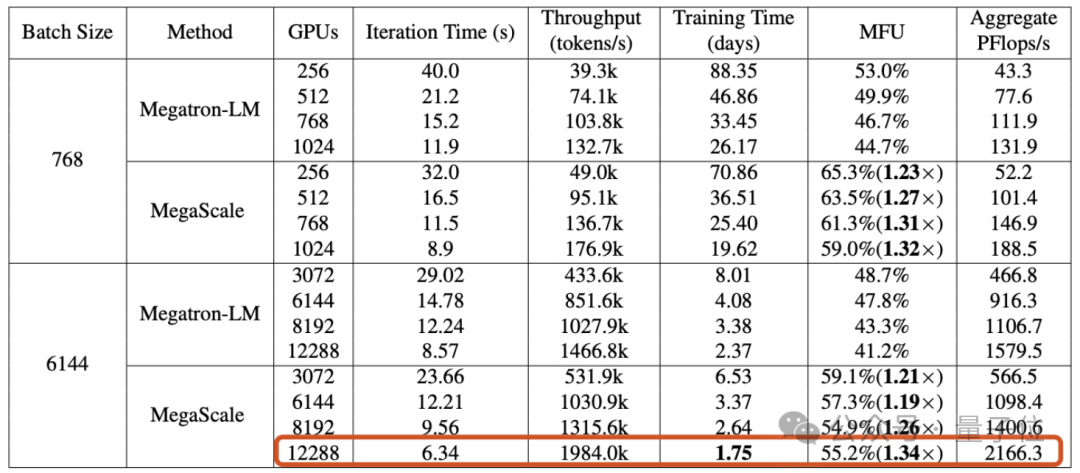
Plus précisément, Byte a proposé un système de production appelé MegaScale, qui vise à résoudre les problèmes d'efficacité et de stabilité rencontrés lors de la formation de grands modèles sur le cluster Wanka.
Lors de la formation d'un grand modèle de langage de 175 milliards de paramètres sur 12 288 GPU, MegaScale a atteint une utilisation de la puissance de calcul de 55,2 % (MFU) , soit 1,34 fois celle de NVIDIA Megatron-LM.
Le document a également révélé qu'en septembre 2023, Byte a établi un GPU à architecture Ampere (A100/A800) cluster avec plus de 10 000 cartes et construit actuellement une architecture Hopper à grande échelle (H100/H800) grappe. .
À l'ère des grands modèles, l'importance du GPU n'a plus besoin d'être développée.
Mais la formation des grands modèles ne peut pas être démarrée directement lorsque le nombre de cartes est plein - lorsque l'échelle du cluster GPU atteint le niveau "10 000", comment parvenir à une formation efficace et stable est un défi en soi. problèmes d'ingénierie.

Le premier défi : l'efficacité.
La formation d'un grand modèle de langage n'est pas une simple tâche parallèle. Elle nécessite de distribuer le modèle entre plusieurs GPU, et ces GPU nécessitent une communication fréquente pour faire avancer conjointement le processus de formation. Outre la communication, des facteurs tels que l'optimisation des opérateurs, le prétraitement des données et la consommation de mémoire GPU ont tous un impact sur l'utilisation de la puissance de calcul (MFU) , un indicateur qui mesure l'efficacité de la formation.
MFU est le rapport entre le débit réel et le débit maximum théorique.
Le deuxième défi : la stabilité.
Nous savons que la formation de grands modèles de langage prend souvent beaucoup de temps, ce qui signifie également que les échecs et les retards pendant le processus de formation ne sont pas rares.
Le coût d'une panne est élevé, il est donc particulièrement important de savoir comment raccourcir le temps de récupération après panne.
Afin de relever ces défis, les chercheurs de ByteDance ont construit MegaScale et l'ont déployé dans le centre de données de Byte pour prendre en charge la formation de divers grands modèles.
MegaScale est amélioré sur la base de NVIDIA Megatron-LM.
Les améliorations spécifiques incluent la co-conception d'algorithmes et de composants système, l'optimisation du chevauchement de communication et de calcul, l'optimisation des opérateurs, l'optimisation du pipeline de données et le réglage des performances du réseau, etc. :
Le document mentionne que MegaScale peut détecter et réparer automatiquement plus de 90 % des pannes logicielles et matérielles.
Les résultats expérimentaux montrent que MegaScale a atteint 55,2 % de MFU lors de la formation d'un grand modèle de langage de 175 B sur 12 288 GPU, soit 1,34 fois l'utilisation de la puissance de calcul de Megatrion-LM.
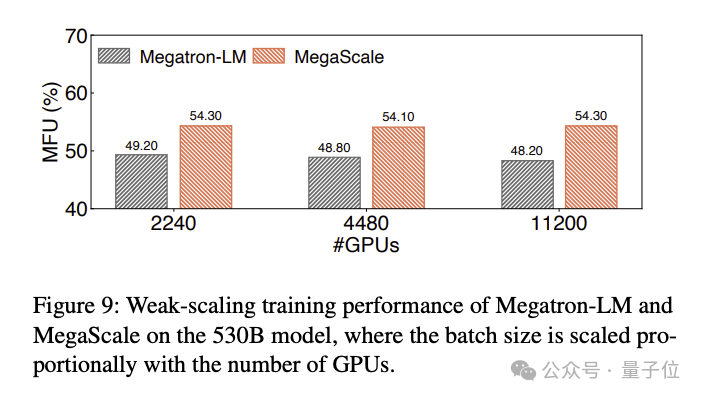
Les résultats de la comparaison MFU de la formation d'un grand modèle de langage 530B sont les suivants :
Au moment même où ce document technique déclenchait la discussion, de nouvelles nouvelles sont apparues concernant le produit Sora basé sur les octets :
Capture d'écran Son outil vidéo d'IA similaire à Sora a lancé un test bêta sur invitation uniquement.

Il semble que les bases soient posées, alors attendez-vous avec impatience les produits grand modèle de Byte ?
Adresse papier : https://arxiv.org/abs/2402.15627
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



