


"Ce n'est en aucun cas une simple découpe."
Auteur de ControlNet Les dernières recherches ont reçu une vague d'attention -
Donnez-moi une invite, vous pouvez utiliser Stable Diffusion pour générer directement un ou plusieurs Calques transparents (PNG) !
Par exemple :
Une femme aux cheveux en bataille dans la chambre.
Femme aux cheveux en désordre, dans la chambre.

Vous pouvez voir que l'IA a non seulement généré une image complète conforme à l'invite, mais que même le arrière-plan et les personnages peuvent être séparés.
Et lorsque vous zoomez sur l'image PNG du personnage et regardez de plus près, vous pouvez voir que les mèches de cheveux sont clairement définies.

Regardez un autre exemple :
Brûler du bois de chauffage, sur une table, à la campagne.
Brûler du bois de chauffage, sur une table, à la campagne.

De même, en agrandissant le PNG de "l'allumette allumée", même la fumée noire autour de la flamme peut être séparée :

C'est le auteur de ControlNet La nouvelle méthode proposée, LayerDiffusion, permet à des modèles de diffusion latente pré-entraînés à grande échelle de générer des images transparentes.

Il convient de souligner à nouveau que LayerDiffusion n'est en aucun cas aussi simple que de découper des images, l'accent est mis sur la génération.
Comme l'ont dit les internautes :
C'est actuellement l'un des processus essentiels de la production d'animation et de vidéo. Si cette étape peut être franchie, on peut dire que la cohérence SD n’est plus un problème.
Certains internautes pensaient qu'un tel travail n'était pas difficile, il suffisait simplement de "ajouter un canal alpha d'ailleurs", mais ce qui l'a surpris, c'est :
Les résultats ont mis si longtemps à sortir.
Alors, comment LayerDiffusion est-il implémenté ?
Le cœur de LayerDiffusion est une méthode appelée transparence latente(transparence latente).
En termes simples, cela permet d'ajouter de la transparence au modèle sans détruire la distribution latente du modèle de diffusion latente pré-entraîné (tel que Stable Diffusion) .
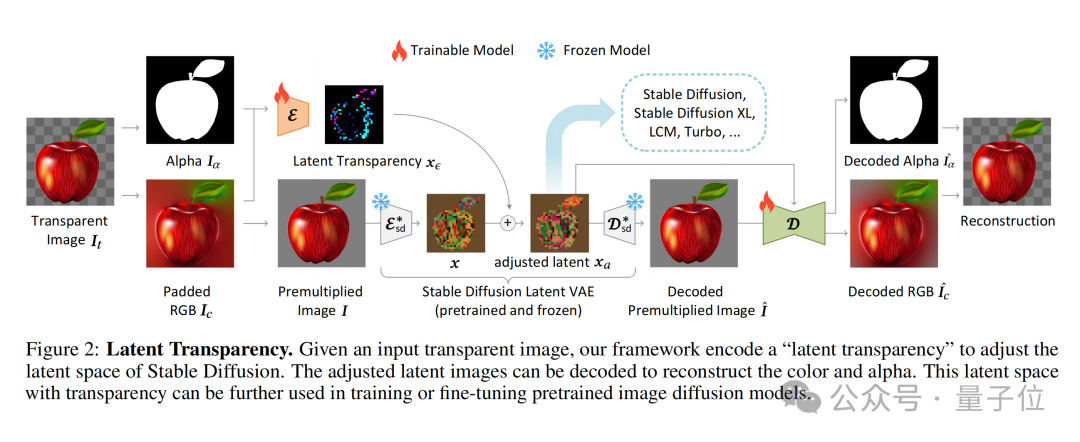
En termes de mise en œuvre spécifique, cela peut être compris comme l'ajout d'une petite perturbation (décalage) soigneusement conçue à l'image latente. Cette perturbation est codée comme un canal supplémentaire, qui, avec le canal RVB, constitue une image latente complète.
Afin de réaliser l'encodage et le décodage de la transparence, l'auteur a formé deux modèles de réseaux neuronaux indépendants : l'un est le encodeur de transparence latente(encodeur de transparence latente), et l'autre est le décodeur de transparence latente(latent décodeur de transparence).
L'encodeur reçoit le canal RVB et le canal alpha de l'image originale en entrée, convertissant les informations de transparence en un décalage dans l'espace latent.
Le décodeur reçoit l'image latente ajustée et l'image RVB reconstruite, et extrait les informations de transparence de l'espace latent pour reconstruire l'image transparente d'origine.
Pour garantir que la transparence potentielle ajoutée ne détruit pas la distribution sous-jacente du modèle pré-entraîné, les auteurs proposent une métrique « d'innocuité » (innocuité).
Cette métrique évalue l'impact de la transparence latente en comparant les résultats de décodage de l'image latente ajustée par le décodeur du modèle pré-entraîné d'origine à l'image d'origine.
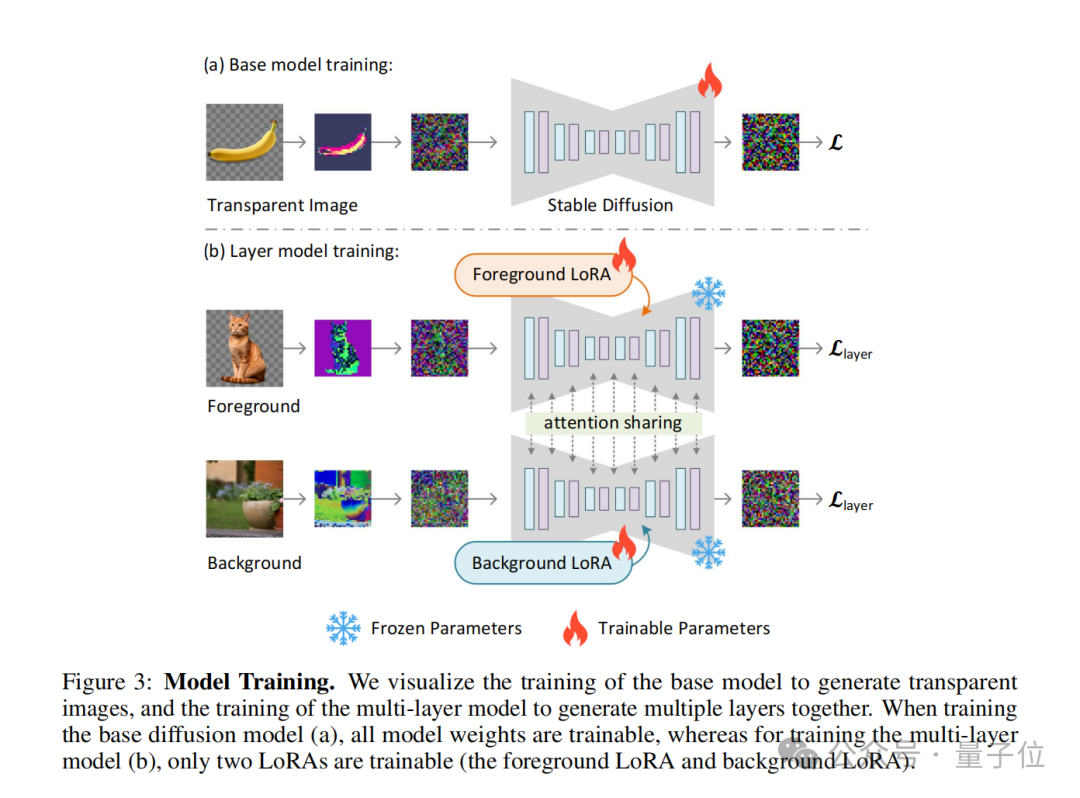
Au cours du processus de formation, l'auteur utilise également une fonction de perte articulaire (fonction de perte articulaire) , qui combine la perte de reconstruction (perte de reconstruction) , la perte d'identité (perte d'identité) et la perte de discriminateur (perte de discriminateur ).
Leurs fonctions sont :
Avec cette approche, n'importe quel modèle de diffusion latente peut être converti en un générateur d'images transparentes en l'ajustant simplement pour l'adapter à l'espace latent ajusté.

Le concept de transparence latente peut également être étendu pour générer plusieurs couches transparentes et combiné avec d'autres systèmes de contrôle conditionnel pour réaliser des tâches de génération d'images plus complexes, telles que la génération de conditions de premier plan/arrière-plan, la génération de couches conjointes, la structure du contenu des couches. contrôle, etc



Il est à noter que l'auteur montre également comment introduire ControlNet pour enrichir les fonctions de LayerDiffusion :

Quant à LayerDiffusion et le tapis traditionnel Les différences peuvent être résumée dans les points suivants.
Génération native vs post-traitement
LayerDiffusion est une méthode native de génération d'images transparentes qui prend en compte et encode les informations de transparence directement pendant le processus de génération. Cela signifie que le modèle crée un canal alpha lors de la génération de l'image, produisant ainsi une image avec transparence.
Les méthodes de découpe traditionnelles impliquent généralement d'abord de générer ou d'obtenir une image, puis de séparer le premier plan et l'arrière-plan grâce à des techniques d'édition d'image(telles que l'incrustation chroma, la détection des contours, les masques spécifiés par l'utilisateur, etc.) . Cette approche nécessite souvent des étapes supplémentaires pour gérer la transparence et peut produire des transitions peu naturelles sur des arrière-plans ou des bords complexes.
Opérations spatiales latentes vs opérations spatiales de pixels
LayerDiffusion fonctionne dans l'espace latent (espace latent), qui est une représentation intermédiaire qui permet au modèle d'apprendre et de générer des caractéristiques d'image plus complexes. En codant la transparence dans l'espace latent, le modèle peut gérer la transparence naturellement lors de la génération sans avoir besoin de calculs complexes au niveau des pixels.
Les techniques de découpe traditionnelles sont généralement effectuées dans l'espace des pixels, ce qui peut impliquer une édition directe de l'image originale, comme le remplacement des couleurs, le lissage des bords, etc. Ces méthodes peuvent avoir des difficultés à gérer les effets translucides (comme le feu, la fumée) ou les bords complexes.
Ensemble de données et formation
LayerDiffusion utilise un ensemble de données à grande échelle pour la formation, qui contient des paires d'images transparentes, permettant au modèle d'apprendre la distribution complexe requise pour générer des images transparentes de haute qualité.
Les méthodes de matage traditionnelles peuvent s'appuyer sur des ensembles de données plus petits ou des ensembles d'entraînement spécifiques, ce qui peut limiter leur capacité à gérer divers scénarios.
Flexibilité et contrôle
LayerDiffusion offre une plus grande flexibilité et un plus grand contrôle car il permet à l'utilisateur de guider la génération d'images via des invites de texte et peut générer plusieurs calques, lesquels calques peuvent être mélangés et combinés pour créer des scènes complexes.
Les méthodes de découpe traditionnelles peuvent être plus limitées en termes de contrôle, en particulier lorsqu'il s'agit de contenu d'image complexe et de transparence.Comparaison de la qualité
La recherche auprès des utilisateurs montre que les images transparentes générées par LayerDiffusion sont préférées par les utilisateurs dans la plupart des cas(97%) , ce qui indique que le contenu transparent qu'elles génèrent est visuellement comparable aux actifs transparents commerciaux, et peut même être possible mieux.
Les méthodes de découpe traditionnelles peuvent ne pas atteindre la même qualité dans certains cas, en particulier lorsqu'il s'agit de transparence et de bords difficiles. Dans l'ensemble, LayerDiffusion fournit une méthode plus avancée et plus flexible pour générer et traiter des images transparentes. Il code la transparence directement pendant le processus de génération et est capable de produire des résultats de haute qualité difficiles à obtenir avec les méthodes de découpe traditionnelles. À propos de l'auteurComme nous venons de le mentionner, l'un des auteurs de cette étude est l'inventeur du célèbre ControlNet -Zhang Lumin.
Il est diplômé de l'Université de Suzhou avec un diplôme de premier cycle. Il a publié un article sur la peinture par l'IA lorsqu'il était étudiant en première année. Au cours de sa période de premier cycle, il a publié 10 ouvrages de haut niveau. Zhang Lumin étudie actuellement pour un doctorat à l'Université de Stanford, mais on peut dire qu'il est très discret et ne s'est même pas inscrit à Google Scholar.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Les derniers prix des dix principales monnaies virtuelles
Les derniers prix des dix principales monnaies virtuelles
 Que signifie vram ?
Que signifie vram ?
 Comment ouvrir le fichier bak
Comment ouvrir le fichier bak
 Quelle est la priorité de l'interruption ?
Quelle est la priorité de l'interruption ?
 html définir la taille de la couleur de la police
html définir la taille de la couleur de la police
 La valeur d'entrée Excel est illégale
La valeur d'entrée Excel est illégale
 Fonctions de la commande tracert
Fonctions de la commande tracert
 Utilisation de typedef en langage C
Utilisation de typedef en langage C








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



