


Les informaticiens jouent actuellement le rôle de support opérationnel dans les entreprises. En ce qui concerne la gestion de l'exploitation et de la maintenance, je pense que tout le monde traverse une période difficile. Ils sont chaque jour responsables de travaux d'exploitation et de maintenance fastidieux, à forte charge et à haut risque, mais ils sont devenus « transparents » en matière d'affaires. planification et développement de carrière. Il y a un dicton plaisantant dans l'industrie : "Ceux qui ne dépensent que de l'argent ne méritent pas d'avoir leur mot à dire".
Avec la popularisation des applications d'IA à grands modèles, les données sont devenues un atout clé et un élément de compétitivité essentiel des entreprises. Ces dernières années, la taille des données d’entreprise a augmenté rapidement, augmentant de façon exponentielle, passant du niveau du pétaoctet à celui des centaines de pétaoctets. Les types de données ont également progressivement évolué de données structurées basées sur des bases de données à des données semi-structurées et non structurées basées sur des fichiers, des journaux, des vidéos, etc. Afin de répondre aux besoins des services métiers, le stockage des données doit être classifié et accessible comme une bibliothèque, et une méthode de stockage plus sécurisée et fiable est également nécessaire.
Les informaticiens ne sont plus de simples acteurs passifs chargés de construire et de gérer les ressources informatiques et d'assurer la stabilité des équipements.
La nouvelle mission des informaticiens a évolué vers la fourniture de services de données de haute qualité, rendre les données faciles à utiliser et aider les départements métiers à faire bon usage des données !

Pour la gestion des infrastructures, la pratique courante dans l'industrie est d'utiliser Technologie AIOps, transformant les opérations et la maintenance quotidiennes manuelles fastidieuses en exécution automatisée à l'aide d'outils et utilisant des capacités intelligentes telles que des systèmes experts et des graphiques de connaissances pour découvrir de manière proactive les dangers du système et réparer automatiquement les pannes, etc. Après la popularisation de la technologie de l'IA générative, de nouvelles applications telles que le service client intelligent et l'exploitation et la maintenance interactives ont récemment vu le jour.
Pour la gestion des données, l'industrie dispose de fournisseurs professionnels de logiciels DataOps représentés par Informatica, IBM, etc., qui prennent en charge l'intégration des données, l'étiquetage des données, l'analyse des données, l'optimisation des données, le marché des données, etc. Capacité à fournir des services aux équipes commerciales telles que les analystes de données, les analystes BI et les data scientists.
Les recherches de l'auteur ont révélé que la gestion de l'exploitation et de la maintenance des infrastructures et la gestion des données dans la plupart des entreprises sont actuellement séparées, avec des équipes responsables différentes, et qu'il n'y a pas de collaboration efficace entre les plates-formes d'outils. Les données commerciales sont stockées dans une infrastructure informatique telle que le stockage et doivent être intégrées. Cependant, la gestion réelle des deux est très éloignée, et même les langues entre les deux équipes ne sont pas alignées. Cela entraîne généralement plusieurs inconvénients : .
1) Données provenant de différentes sources : Parce qu'elles appartiennent à différentes équipes et utilisent des outils différents, les équipes commerciales copient généralement les données originales sur la plateforme de gestion des données pour analyse et traitement via ETL et d'autres méthodes. Cela entraîne non seulement un gaspillage d'espace de stockage, mais entraîne également des problèmes tels qu'une incohérence des données et des mises à jour intempestives des données, ce qui affecte la précision de l'analyse des données.
2) Difficulté de collaboration interrégionale : De nos jours, les centres de données d'entreprise sont déployés dans plusieurs villes. Lorsque les données sont transmises entre les régions, elles sont actuellement principalement répliquées au niveau de la couche hôte via le logiciel DataOps. Cette méthode de transmission de données est non seulement faible, mais le processus de transmission comporte également de sérieux risques tels que la sécurité, la conformité et la confidentialité.
3) Optimisation insuffisante du système : Actuellement, l'optimisation repose généralement sur l'utilisation des ressources de l'infrastructure. Parce que la disposition des données ne peut pas être perçue comme permettant une optimisation globale, le coût du stockage des données reste élevé et en croissance. est limitée.La contradiction entre le budget et la croissance exponentielle de l'échelle des données est devenue la contradiction clé qui limite l'accumulation des actifs de données de l'entreprise.
L'auteur estime que l'équipe informatique devrait considérer « l'infrastructure » et les « données » car il gère et optimise un tout organique pour atteindre l'homologie des données, l'optimisation globale et la circulation sécurisée, jouant un rôle important en tant que gestionnaire d'actifs de données.
Tout d'abord, obtenez une vue unifiée des fichiers globaux. Utilisez un système de fichiers global, une gestion unifiée des métadonnées et d'autres technologies pour former une vue globale unifiée des données dans différentes régions, différents centres de données et différents types d'équipements. Sur cette base, des stratégies d'optimisation globales peuvent être formulées en fonction de dimensions telles que chaud, chaud, froid, répétition, expiration, etc., et envoyées au dispositif de stockage pour exécution. Cette approche peut réaliser une optimisation globale. Les technologies telles que la compression et le chiffrement basées sur la réplication de la couche de stockage peuvent généralement permettre un mouvement des données des dizaines de fois plus rapide, et l'efficacité et la sécurité peuvent être garanties.
Deuxièmement, générez automatiquement un répertoire de données à partir de données massives non structurées. Générez automatiquement des services de catalogue de données via des métadonnées, des métadonnées améliorées, etc., et gérez efficacement les données par catégories. Sur la base de l'annuaire, l'équipe commerciale peut extraire automatiquement les données qui répondent aux conditions d'analyse et de traitement, au lieu de rechercher manuellement les données comme une aiguille dans une botte de foin. Les recherches de l'auteur ont révélé que la technologie d'annotation des données via les algorithmes de reconnaissance de l'IA est relativement mature. Par conséquent, des cadres ouverts peuvent être utilisés pour intégrer des algorithmes d'IA pour différents scénarios et analyser automatiquement le contenu des fichiers pour former des balises diversifiées, qui peuvent être utilisées comme métadonnées améliorées. améliorer les capacités de gestion des données.
Dans le même temps, lorsque les données circulent entre les appareils, des considérations particulières doivent être accordées à la souveraineté des données, à la confidentialité et à d'autres problèmes. Les données contenues dans les périphériques de stockage doivent être automatiquement classées, classées en termes de confidentialité, décentralisées et divisées en domaines, etc. Le logiciel de gestion doit gérer uniformément l'accès, l'utilisation, le flux et d'autres politiques pour éviter les fuites d'informations sensibles et de données privées, ainsi que les données futures. Scénarios d'échange d'éléments Ceux-ci deviendront des exigences de base. Par exemple, lorsque des données sortent d'un périphérique de stockage, la conformité, la confidentialité personnelle, etc. doivent d'abord être déterminées pour déterminer si elles répondent aux exigences politiques, sinon l'entreprise sera confrontée à de graves risques juridiques et réglementaires.
L'architecture de référence est la suivante :
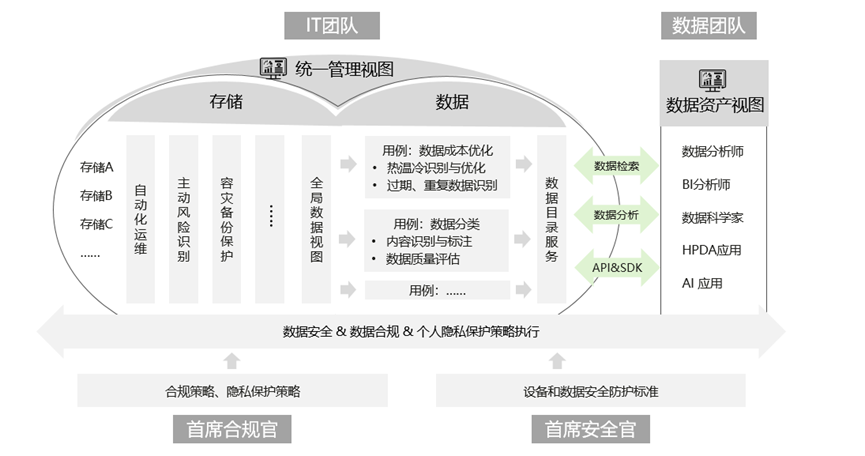
Selon les recherches de l'auteur et la consultation de pairs experts, j'ai découvert que les principaux fournisseurs de stockage du secteur, tels que Huawei Storage et NetApp, ont publié produits pour une solution intégrée de stockage et de gestion des données, je pense que davantage de fabricants le prendront en charge à l'avenir.
L'équipement et les données doivent être saisis à deux mains, et les deux mains doivent être fortes. Les informaticiens peuvent jouer un rôle plus important à l’ère de l’IA.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment lier des données dans une liste déroulante
Comment lier des données dans une liste déroulante
 Touches de raccourci de l'écran de verrouillage Windows
Touches de raccourci de l'écran de verrouillage Windows
 Outils Flash recommandés
Outils Flash recommandés
 Comment résoudre l'erreur 443
Comment résoudre l'erreur 443
 webstorm ajuster la taille de la police
webstorm ajuster la taille de la police
 SQL dans l'utilisation de l'opérateur
SQL dans l'utilisation de l'opérateur
 commande utilisateur du commutateur Linux
commande utilisateur du commutateur Linux
 Comment définir le chinois dans vscode
Comment définir le chinois dans vscode








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



