


Le modèle open source du MoE accueille enfin son premier acteur national !
Ses performances ne sont pas inférieures au modèle dense Llama 2-7B, mais le montant de calcul n'est que de 40 %.
Ce modèle peut être qualifié de guerrier à 19 faces, écrasant particulièrement Llama en termes de capacités mathématiques et de codage.
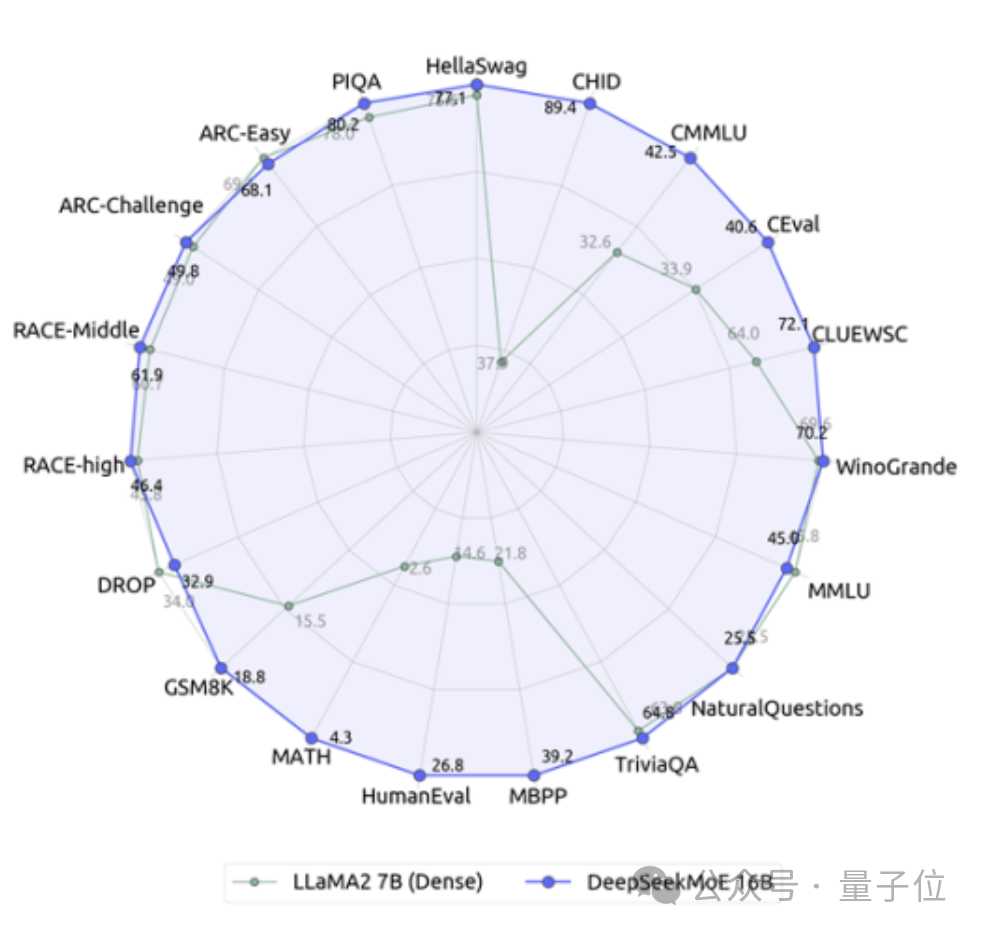
Il s'agit du dernier modèle expert open source à 16 milliards de paramètres DeepSeek MoE de l'équipe Deep Search.
En plus de ses excellentes performances, l’objectif principal de DeepSeek MoE est d’économiser de la puissance de calcul.
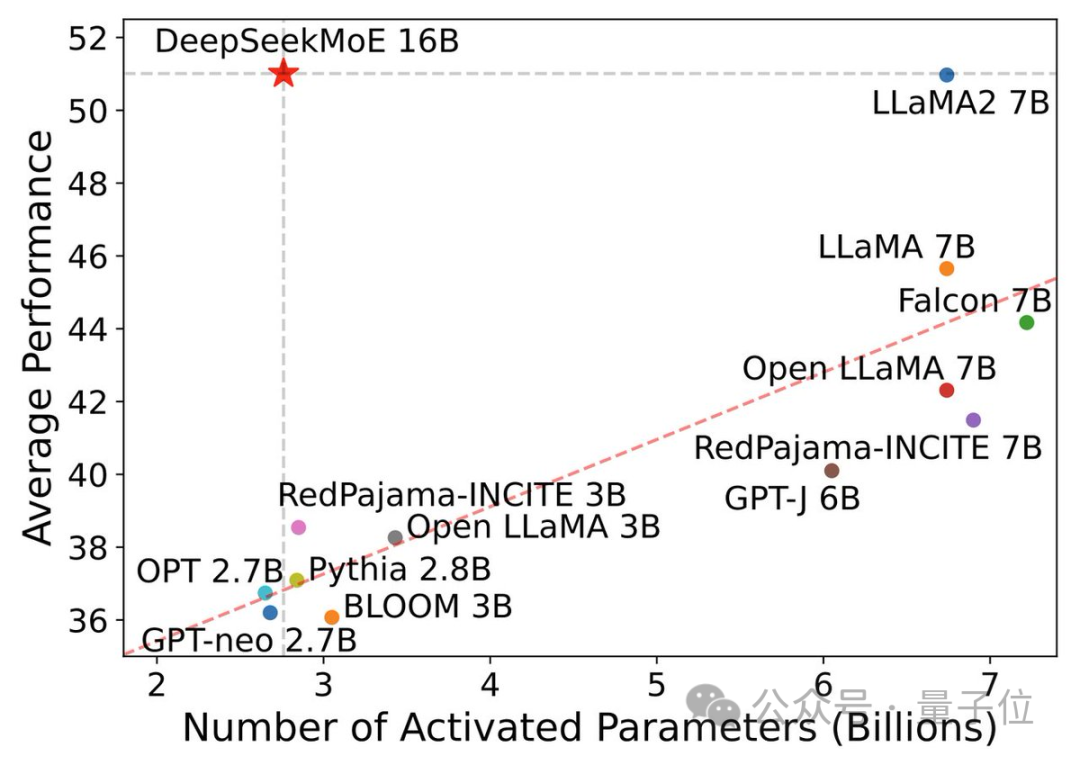
Dans ce diagramme de paramètres d'activation de performance, il « se démarque » et occupe une grande zone vide dans le coin supérieur gauche.
Un jour seulement après sa publication, le tweet de l'équipe DeepSeek sur X a reçu un grand nombre de retweets et d'attention.
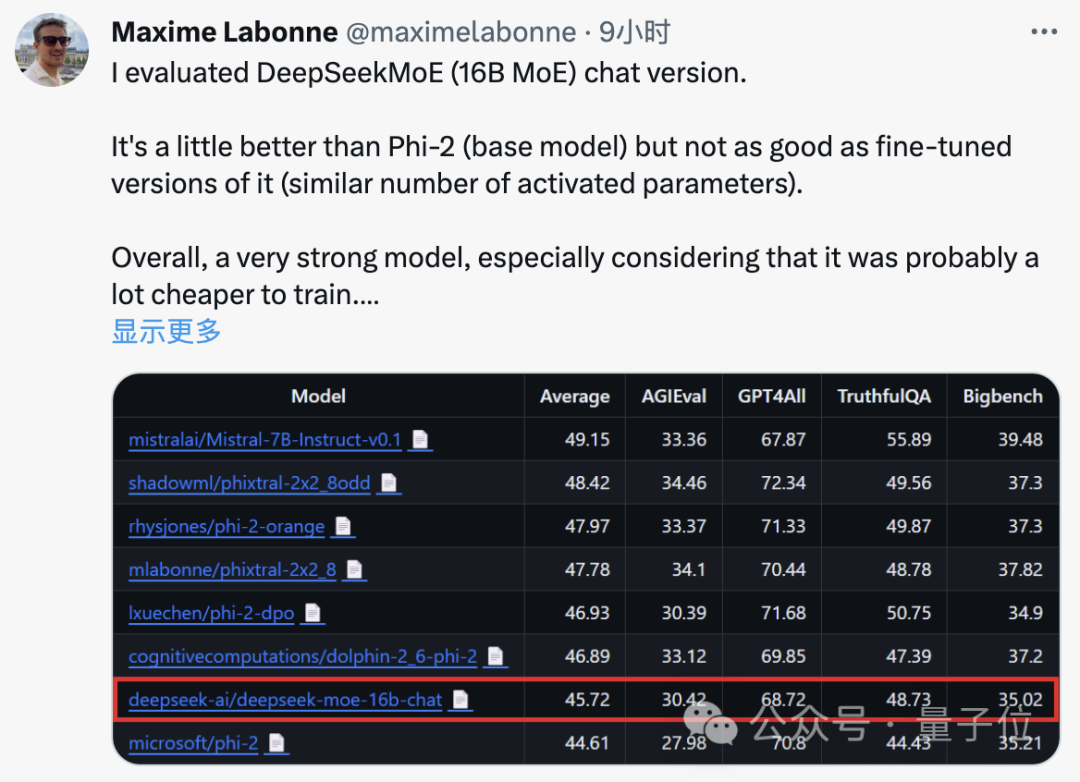
Maxime Labonne, ingénieur en machine learning chez JP Morgan, a également déclaré après des tests que la version chat de DeepSeek MoE était légèrement plus performante que le « petit modèle » Phi-2 de Microsoft.
Dans le même temps, DeepSeek MoE a également reçu plus de 300 étoiles sur GitHub et est apparu sur la page d'accueil du classement des modèles de génération de texte Hugging Face.
Alors, quelles sont les performances spécifiques de DeepSeek MoE ?
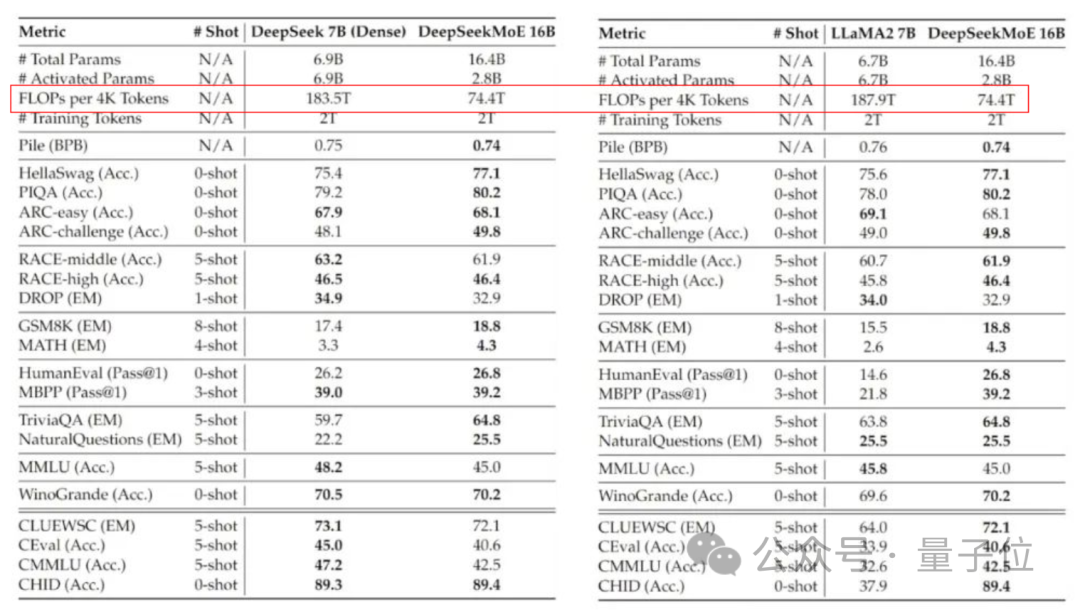
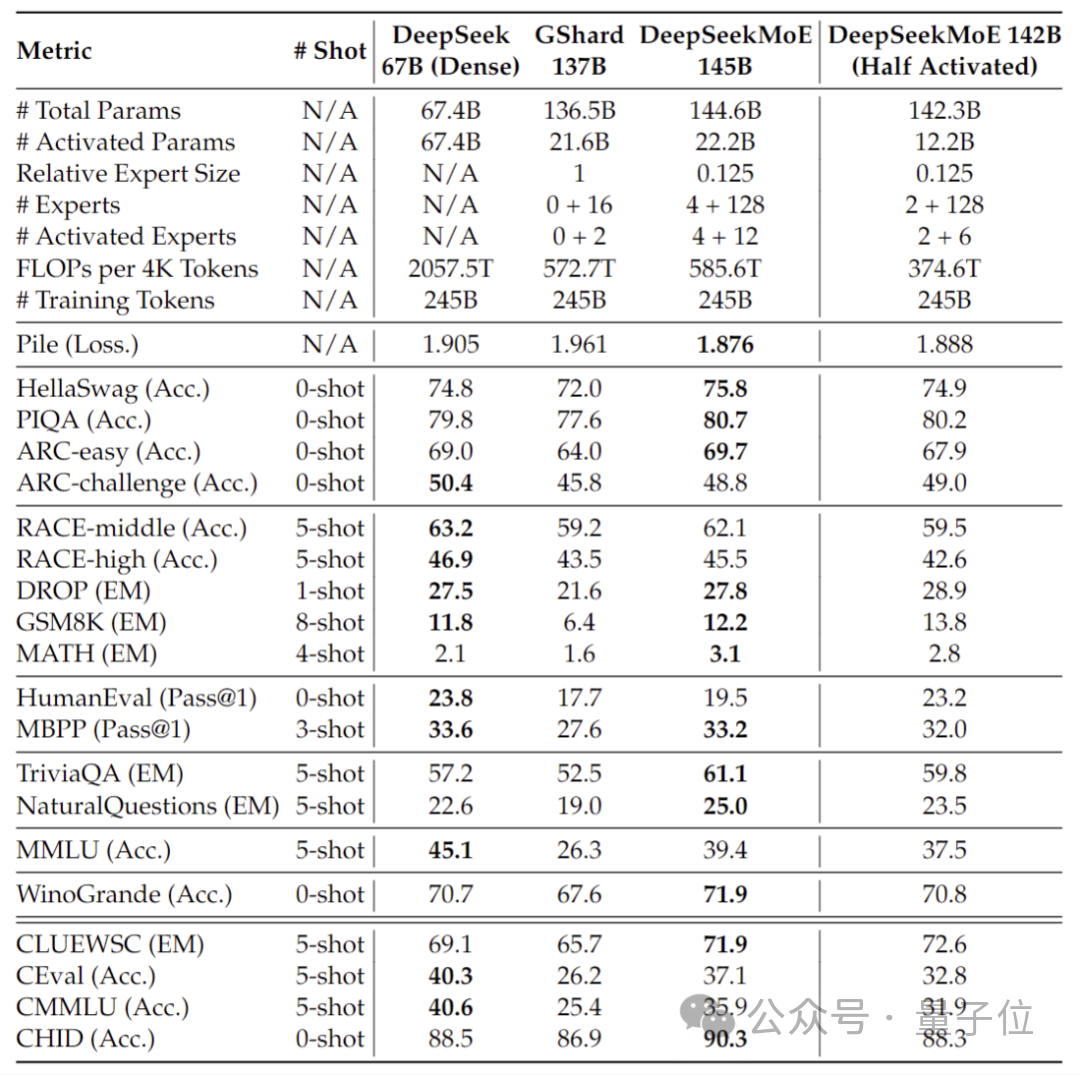
La version actuellement lancée de DeepSeek MoE compte 16 milliards de paramètres, et le nombre réel de paramètres activés est d'environ 2,8 milliards.
Par rapport à notre propre modèle dense 7B, les performances des deux sur 19 ensembles de données diffèrent, mais les performances globales sont relativement proches.
Par rapport à Llama 2-7B, qui est également un modèle dense, DeepSeek MoE présente également des avantages évidents en mathématiques, en code, etc.
Mais la charge de calcul des deux modèles denses dépasse 180TFLOP pour 4 000 jetons, tandis que DeepSeek MoE n'a que 74,4TFLOP, soit seulement 40 % des deux.
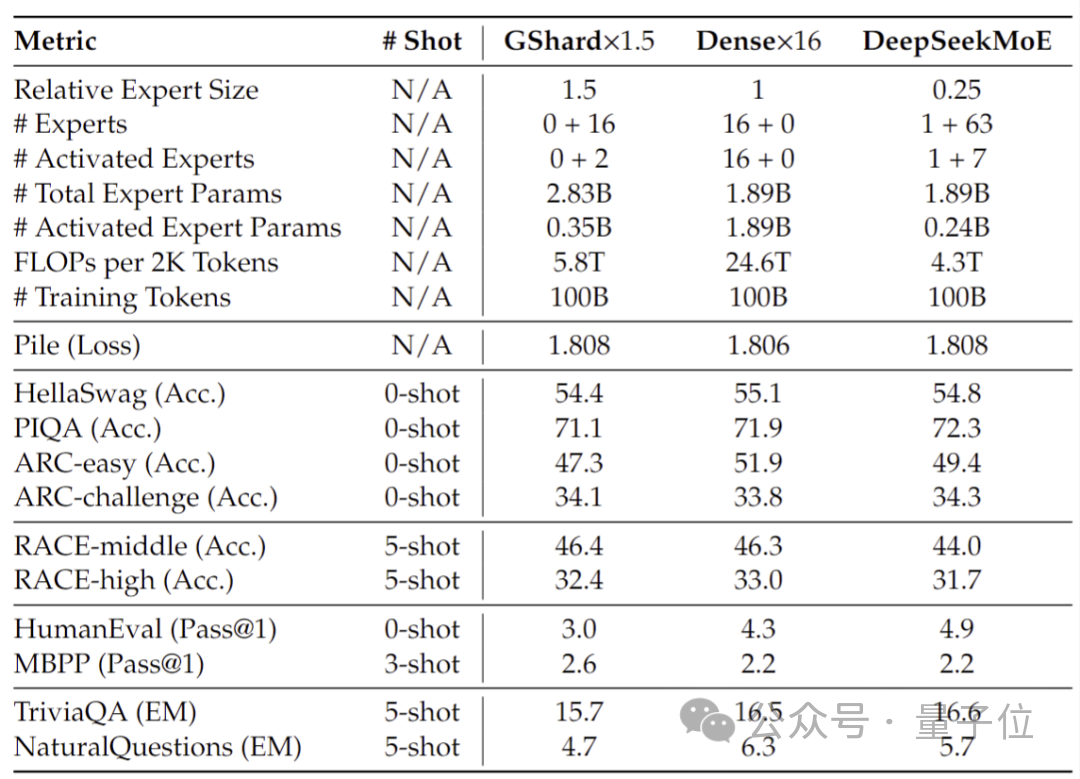
Les tests de performances effectués sur 2 milliards de paramètres montrent que DeepSeek MoE peut également obtenir des résultats équivalents, voire meilleurs, que GShard 2.8B, qui est également un modèle MoE avec 1,5 fois plus de paramètres et utilise moins de calculs.
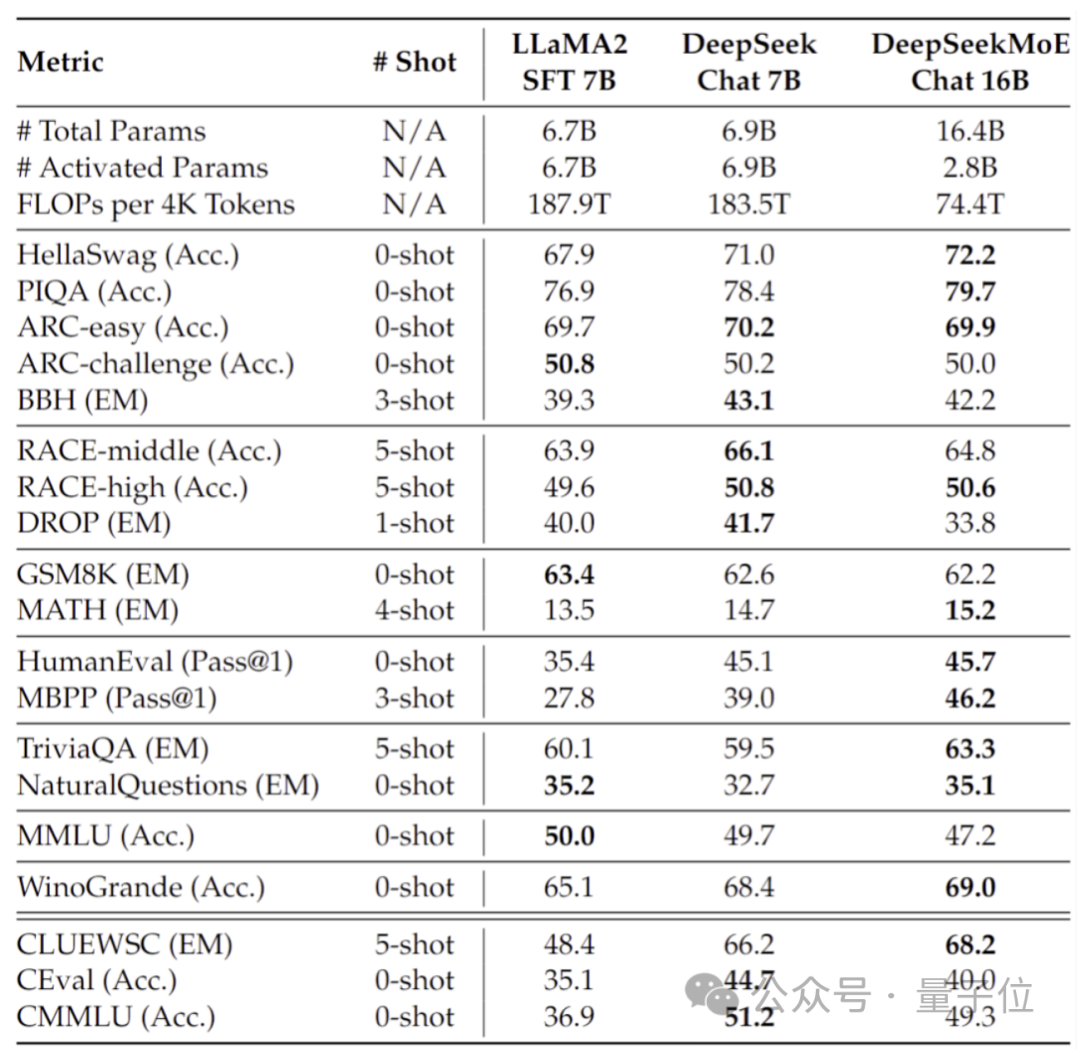
De plus, l'équipe Deep Seek a également affiné la version Chat de DeepSeek MoE basée sur SFT, et ses performances sont également proches de sa propre version dense et de Llama 2-7B.
De plus, l'équipe DeepSeek a également révélé qu'il existe également une version 145B du modèle DeepSeek MoE en cours de développement.
Des tests préliminaires progressifs montrent que le 145B DeepSeek MoE a une énorme avance sur le GShard 137B et peut atteindre des performances équivalentes à la version dense du modèle DeepSeek 67B avec 28,5 % du montant de calcul.
Une fois la recherche et le développement terminé, l'équipe ouvrira également la version 145B.
Derrière les performances de ces modèles se cache la nouvelle architecture MoE auto-développée par DeepSeek.
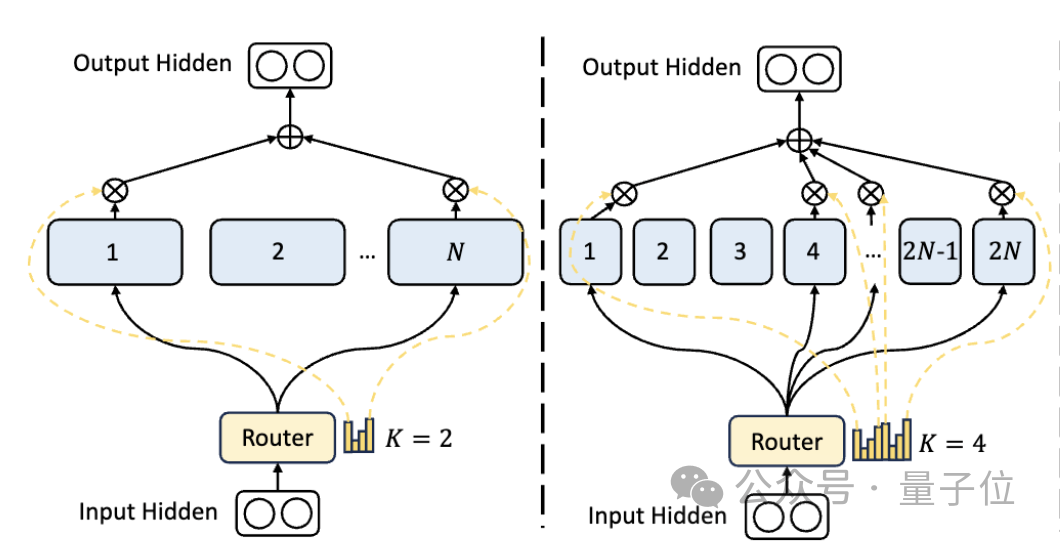
Tout d'abord, par rapport à l'architecture MoE traditionnelle, DeepSeek dispose d'une division d'experts plus fine.
Lorsque le nombre total de paramètres est fixé, le modèle traditionnel peut classer N experts, tandis que DeepSeek peut classer 2N experts.
Dans le même temps, le nombre d'experts sélectionnés à chaque fois qu'une tâche est effectuée est deux fois supérieur à celui du modèle traditionnel, donc le nombre global de paramètres utilisés reste le même, mais le degré de liberté de sélection augmente.
Cette stratégie de segmentation permet une combinaison plus flexible et adaptative d'experts en activation, améliorant ainsi la précision du modèle sur différentes tâches et la pertinence de l'acquisition de connaissances.
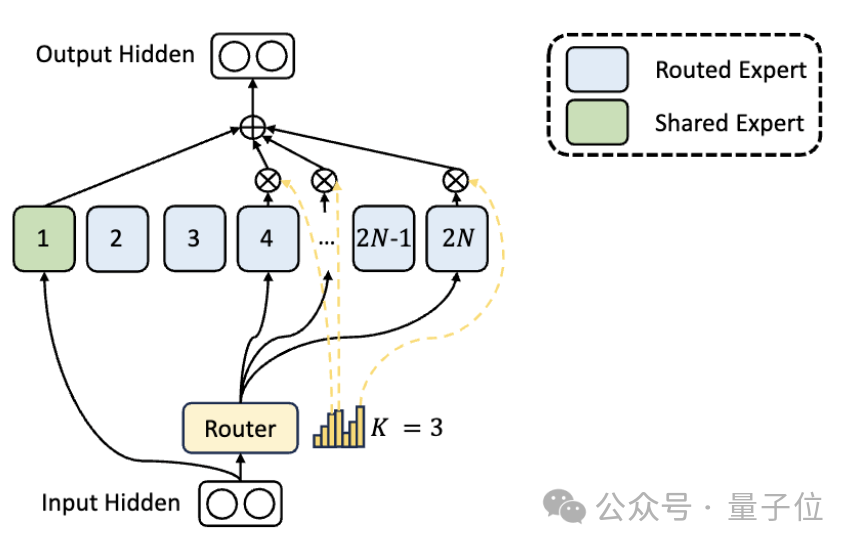
En plus des différences dans la division des experts, DeepSeek introduit également de manière innovante le paramètre « expert partagé ».
Ces experts partagés activent des jetons pour toutes les entrées et ne sont pas affectés par le module de routage. Le but est de capturer et d'intégrer les connaissances communes nécessaires dans différents contextes.
En compressant ces connaissances partagées en experts partagés, la redondance des paramètres entre autres experts peut être réduite, améliorant ainsi l'efficacité des paramètres du modèle.
La configuration d'experts partagés aide d'autres experts à se concentrer davantage sur leurs domaines de connaissances uniques, augmentant ainsi le niveau global de spécialisation des experts.
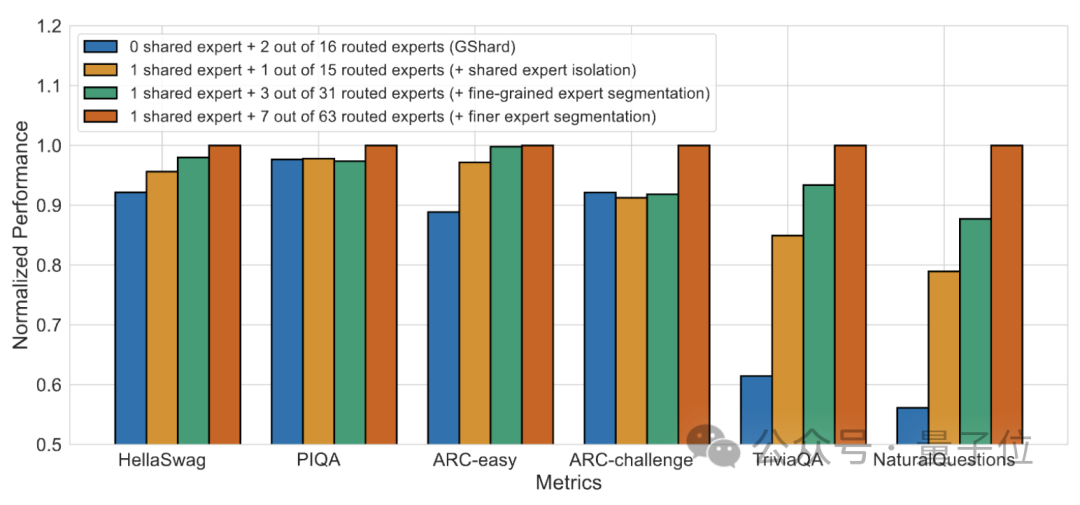
Les résultats de l'expérience d'ablation montrent que les deux solutions jouent un rôle important dans la « réduction des coûts et l'augmentation de l'efficacité » de DeepSeek MoE.
Adresse papier : https://arxiv.org/abs/2401.06066.
Lien de référence : https://mp.weixin.qq.com/s/T9-EGxYuHcGQgXArLXGbgg.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Application de l'intelligence artificielle dans la vie
Application de l'intelligence artificielle dans la vie
 Quel est le concept de base de l'intelligence artificielle
Quel est le concept de base de l'intelligence artificielle
 Quel logiciel est Dreamweaver ?
Quel logiciel est Dreamweaver ?
 Oracle effacer les données du tableau
Oracle effacer les données du tableau
 Tri des tableaux JS : méthode sort()
Tri des tableaux JS : méthode sort()
 Trois frameworks majeurs pour le développement Android
Trois frameworks majeurs pour le développement Android
 JAXB
JAXB
 Quelles sont les orientations d'emploi à Java ?
Quelles sont les orientations d'emploi à Java ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



