


La tâche de génération d'image en vidéo (I2V) est un défi dans le domaine de la vision par ordinateur qui vise à convertir des images statiques en vidéos dynamiques. La difficulté de cette tâche est d'extraire et de générer des informations dynamiques dans la dimension temporelle à partir d'une seule image tout en conservant l'authenticité et la cohérence visuelle du contenu de l'image. Les méthodes I2V existantes nécessitent souvent des architectures de modèles complexes et de grandes quantités de données de formation pour atteindre cet objectif.
Récemment, un nouveau résultat de recherche « I2V-Adapter : A General Image-to-Video Adapter for Video Diffusion Models » dirigé par Kuaishou a été publié. Cette recherche introduit une méthode innovante de conversion image-vidéo et propose un module adaptateur léger, l'I2V-Adapter. Ce module adaptateur est capable de convertir des images statiques en vidéos dynamiques sans modifier la structure d'origine et les paramètres pré-entraînés des modèles de génération texte-vidéo (T2V) existants. Cette méthode a de larges perspectives d'application dans le domaine de la conversion d'image en vidéo et peut apporter davantage de possibilités à la création vidéo, à la communication médiatique et à d'autres domaines. La publication des résultats de la recherche revêt une grande importance pour promouvoir le développement de la technologie de l'image et de la vidéo et constitue un outil et une méthode efficaces pour les chercheurs dans des domaines connexes.

Par rapport aux méthodes existantes, I2V-Adapter a davantage de paramètres entraînables. D'énormes améliorations ont été réalisé, et le nombre de paramètres peut atteindre aussi bas que 22M, ce qui ne représente que 1% de la solution grand public Stable Video Diffusion. Dans le même temps, l'adaptateur est également compatible avec les modèles T2I personnalisés (tels que DreamBooth, Lora) et les outils de contrôle (tels que ControlNet) développés par la communauté Stable Diffusion. Grâce à des expériences, les chercheurs ont prouvé l'efficacité de l'I2V-Adapter pour générer du contenu vidéo de haute qualité, ouvrant ainsi de nouvelles possibilités d'applications créatives dans le domaine I2V.

Modélisation temporelle avec diffusion stable
Par rapport à la génération d'images, la génération vidéo est confrontée à un défi unique, à savoir modéliser la cohérence temporelle entre les images vidéo et le sexe. La plupart des méthodes actuelles sont basées sur des modèles T2I pré-entraînés, tels que Stable Diffusion et SDXL, en introduisant des modules de synchronisation pour modéliser les informations de synchronisation dans les vidéos. Inspiré d'AnimateDiff, un modèle initialement conçu pour les tâches T2V personnalisées, il modélise les informations de synchronisation en introduisant un module de synchronisation découplé du modèle T2I, et conserve la capacité du modèle T2I d'origine à générer des vidéos fluides. Par conséquent, les chercheurs pensent que le module temporel pré-entraîné peut être considéré comme une représentation temporelle universelle et peut être appliqué à d’autres scénarios de génération vidéo, tels que la génération I2V, sans aucun réglage précis. Par conséquent, les chercheurs ont directement utilisé le module de synchronisation AnimateDiff pré-entraîné et ont maintenu ses paramètres fixes.
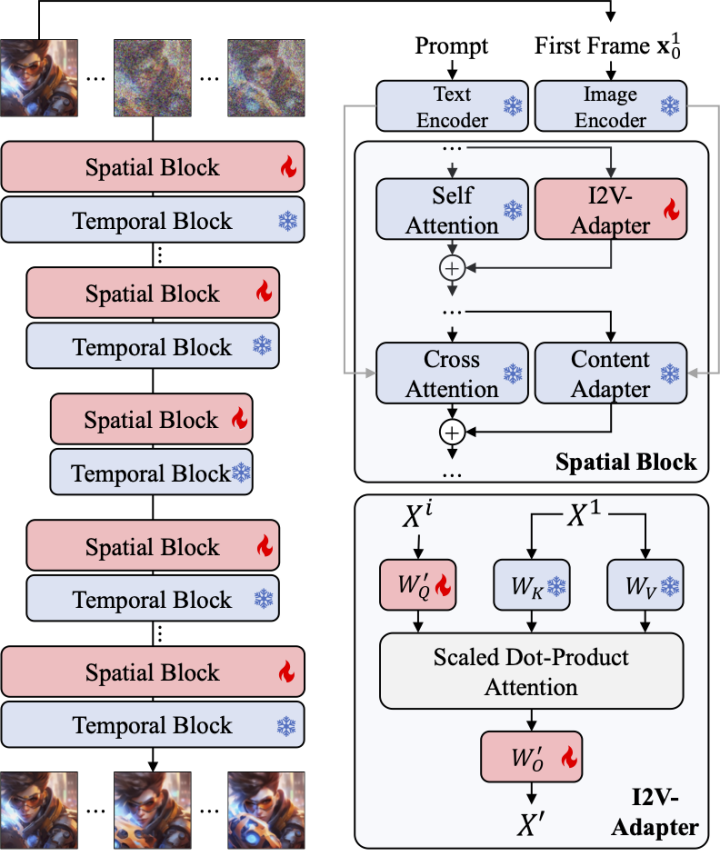
Adaptateur pour les couches d'attention
Un autre défi de la tâche I2V est de conserver les informations d'identification de l'image d'entrée. Il existe actuellement deux solutions principales : l'une consiste à utiliser un encodeur d'image pré-entraîné pour coder l'image d'entrée et à injecter les caractéristiques codées dans le modèle via un mécanisme d'attention croisée pour guider le processus de débruitage ; concaténés avec l'entrée bruyante dans la dimension du canal, puis introduits ensemble dans le réseau suivant. Cependant, la première méthode peut entraîner une modification de l'ID vidéo généré car il est difficile pour l'encodeur d'image de capturer les informations sous-jacentes, tandis que la seconde méthode nécessite souvent de modifier la structure et les paramètres du modèle T2I, ce qui entraîne des coûts de formation élevés et médiocres ; compatibilité.
Afin de résoudre les problèmes ci-dessus, les chercheurs ont proposé l'adaptateur I2V. Plus précisément, le chercheur entre l'image d'entrée et l'entrée bruitée dans le réseau en parallèle. Dans le bloc spatial du modèle, toutes les trames interrogeront en outre les informations de la première trame, c'est-à-dire que les caractéristiques clés et de valeur proviennent de la première trame sans bruit. , et la sortie Le résultat est ajouté à l'auto-attention du modèle d'origine. La matrice de mappage de sortie de ce module est initialisée avec des zéros et seules la matrice de mappage de sortie et la matrice de mappage de requêtes sont entraînées. Afin d'améliorer encore la compréhension du modèle des informations sémantiques de l'image d'entrée, les chercheurs ont introduit un adaptateur de contenu pré-entraîné (cet article utilise IP-Adapter [8]) pour injecter les caractéristiques sémantiques de l'image.
Frame Similarity Prior
Afin d'améliorer encore la stabilité des résultats générés, les chercheurs ont proposé une similarité inter-images avant de trouver un équilibre entre la stabilité et l'intensité du mouvement de la vidéo générée. L'hypothèse clé est qu'à un niveau de bruit gaussien relativement faible, la première image bruyante et les images suivantes bruyantes sont suffisamment proches, comme le montre la figure ci-dessous :
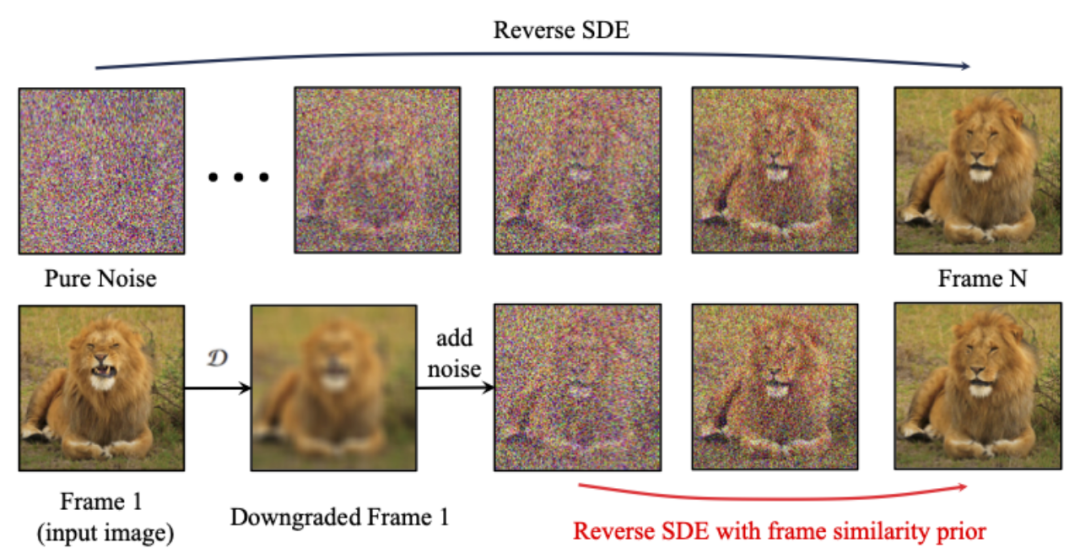
Ainsi, les chercheurs ont supposé que toutes les structures de trame étaient similaires. , et deviennent indiscernables après l'ajout d'une certaine quantité de bruit gaussien, de sorte que l'image d'entrée bruitée peut être utilisée comme entrée a priori pour les images suivantes. Afin d'éliminer le caractère trompeur des informations haute fréquence, les chercheurs ont également utilisé un opérateur de flou gaussien et un mélange de masques aléatoire. Plus précisément, l'opération est donnée par la formule suivante :

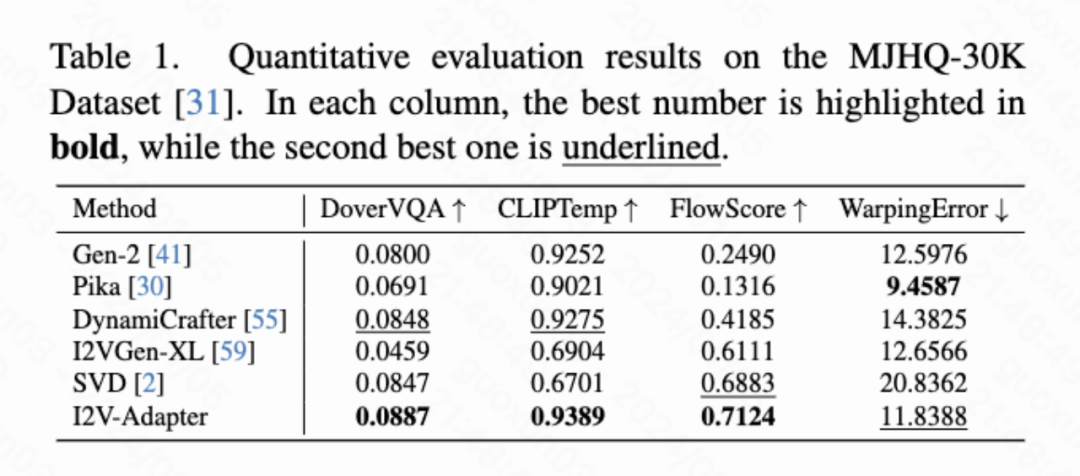
Résultats quantitatifs
Cet article calcule quatre indicateurs quantitatifs, à savoir DoverVQA (score esthétique), CLIPTemp (premier Frame cohérence), FlowScore (amplitude de mouvement) et WarppingError (erreur de mouvement) sont utilisés pour évaluer la qualité de la vidéo générée. Le tableau 1 montre que l'adaptateur I2V a reçu le score esthétique le plus élevé et a également dépassé tous les schémas de comparaison en termes de cohérence de la première image. De plus, la vidéo générée par I2V-Adapter présente la plus grande amplitude de mouvement et une erreur de mouvement relativement faible, ce qui indique que ce modèle est capable de générer des vidéos plus dynamiques tout en conservant la précision du mouvement temporel.
Résultats qualitatifs
Animation d'image (gauche est l'entrée, droite est la sortie) :



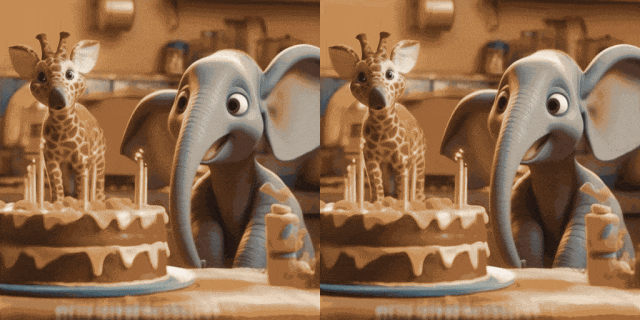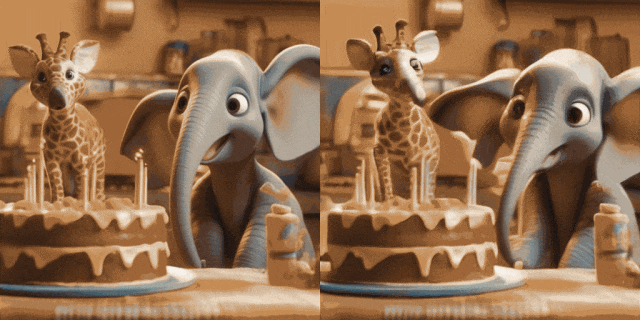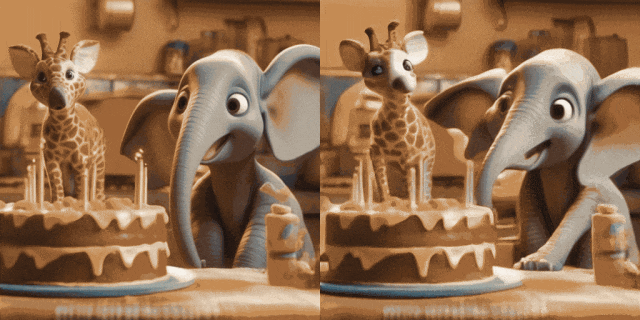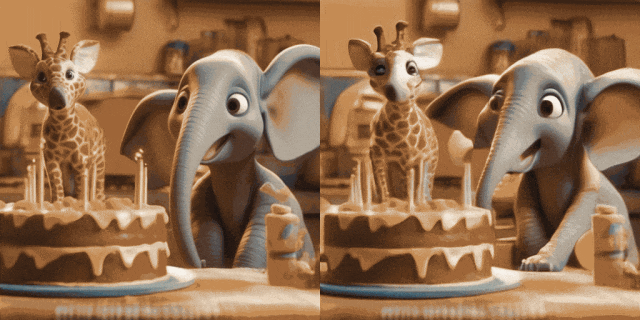
avec T2I personnalisés (sur le Entrée gauche, droite est la sortie) :




w/ ControlNet (gauche est l'entrée, droite est la sortie) :



Cet article propose I2V-Adapter, un module léger plug-and-play pour les tâches de génération d'image en vidéo. Cette méthode maintient fixes les structures et les paramètres des blocs spatiaux et des blocs de mouvement du modèle T2V d'origine, entre la première image sans bruit et les images suivantes avec du bruit en parallèle, et permet à toutes les images d'interagir avec la première image sans bruit via le mécanisme d'attention. , produisez ainsi une vidéo temporellement cohérente et cohérente avec la première image. Les chercheurs ont démontré l’efficacité de cette méthode sur des tâches I2V à travers des expérimentations quantitatives et qualitatives. De plus, sa conception découplée permet à la solution d'être directement combinée avec des modules tels que DreamBooth, Lora et ControlNet, prouvant la compatibilité de la solution et favorisant la recherche sur la génération d'image en vidéo personnalisée et contrôlable.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Que faire avec la carte vidéo
Que faire avec la carte vidéo
 Comment télécharger des vidéos de Douyin
Comment télécharger des vidéos de Douyin
 ppt en mot
ppt en mot
 Comment gérer les téléchargements de fichiers bloqués dans Windows 10
Comment gérer les téléchargements de fichiers bloqués dans Windows 10
 Quelles sont les utilisations de MySQL
Quelles sont les utilisations de MySQL
 Prix du Litecoin aujourd'hui
Prix du Litecoin aujourd'hui
 utilisation de la commande net use
utilisation de la commande net use
 La différence entre la région actuelle et la plage utilisée
La différence entre la région actuelle et la plage utilisée








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



