


L'évaluation du modèle est une partie très importante du deep learning et du machine learning, utilisée pour mesurer les performances et l'efficacité du modèle. Cet article décomposera étape par étape la matrice de confusion, l'exactitude, la précision, le rappel et le score F1

La matrice de confusion est utilisée pour évaluer les performances du modèle dans les problèmes de classification , il s'agit d'un modèle de démonstration sur l'exemple de table de classification. Les lignes représentent les catégories réelles et les colonnes représentent les catégories prédites. Pour un problème de classification binaire, la structure de la matrice de confusion est la suivante :
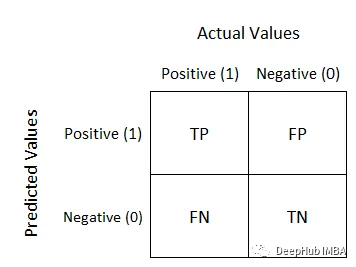
Cela semble compliqué pour les débutants, mais c'est en fait assez simple. Le négatif/positif à l’arrière est la valeur de prédiction du modèle, et le vrai/faux à l’avant est la précision de la prédiction du modèle. Par exemple, True Negative signifie que la prédiction du modèle est négative et cohérente avec la valeur réelle, c'est-à-dire que la prédiction est correcte. Cela facilite la compréhension. Voici une matrice de confusion simple :
from sklearn.metrics import confusion_matrix import seaborn as sns import matplotlib.pyplot as plt # Example predictions and true labels y_true = [1, 0, 1, 1, 0, 1, 0, 0, 1, 0] y_pred = [1, 0, 1, 0, 0, 1, 0, 1, 1, 1] # Create a confusion matrix cm = confusion_matrix(y_true, y_pred) # Visualize the blueprint sns.heatmap(cm, annot=True, fmt="d", cmap="Blues", xticklabels=["Predicted 0", "Predicted 1"], yticklabels=["Actual 0", "Actual 1"]) plt.xlabel("Predicted") plt.ylabel("Actual") plt.show()Utilisez TP et TN lorsque vous souhaitez mettre l'accent sur les prédictions correctes et la précision globale. Utilisez FP et FN lorsque vous souhaitez comprendre les types d'erreurs commises par votre modèle. Par exemple, dans les applications où le coût des faux positifs est élevé, il peut être essentiel de minimiser les faux positifs.
À titre d’exemple, parlons des classificateurs de spam. La matrice de confusion nous aide à comprendre combien d'e-mails de spam le classificateur a correctement identifiés et combien d'e-mails non spam il a incorrectement marqués comme spam.
Sur la base de la matrice de confusion, de nombreuses autres mesures d'évaluation peuvent être calculées telles que l'exactitude, le degré de précision, rappel et score F1.
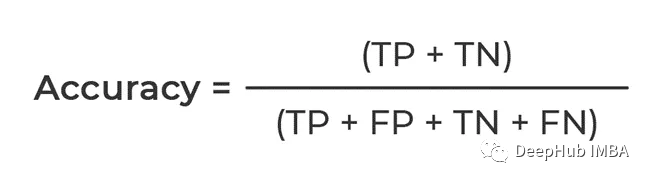
Selon notre résumé ci-dessus, ce qui est calculé est la proportion qui peut être prédite correctement. Le numérateur est que TP et TN sont tous deux vrais, ce qui correspond au nombre total de prédictions correctes par. le modèle

Vous pouvez voir la formule Il calcule la proportion de Positif, c'est-à-dire combien de positifs dans les données sont correctement prédits, donc la précision est aussi appelée taux de précision.
Cela devient très important dans les situations où les fausses alarmes ont des conséquences ou des coûts importants. En prenant le modèle de diagnostic médical comme exemple, l'exactitude est garantie pour garantir que seuls ceux qui ont réellement besoin d'un traitement reçoivent un traitement. Le rappel, également appelé sensibilité ou taux de vrais positifs, fait référence au modèle capturant toutes les classes positives.
Score F1
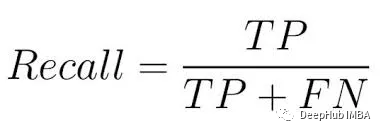
La formule de calcul du score F1 est : F1 = 2 * (Précision * Rappel) / (Précision + Rappel) Parmi eux, la précision fait référence à la proportion d'échantillons prédits comme exemples positifs par le modèle qui sont en réalité des exemples positifs ; le taux de rappel fait référence à la proportion du nombre d'échantillons correctement prédits comme exemples positifs par le modèle par rapport au nombre d'échantillons qui sont réellement des exemples positifs. exemples positifs. Le score F1 est la moyenne harmonique de précision et de rappel, qui peut prendre en compte de manière globale l'exactitude et l'exhaustivité du modèle pour évaluer les performances du modèle
Dans cet article, nous avons présenté en détail la matrice de confusion, l'exactitude, la précision, le rappel et le score F1, et avons souligné que ces indicateurs peuvent évaluer et améliorer efficacement les performances du modèleRésumé
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



