


| Présentation | La bibliothèque logicielle Apache Hadoop est un framework qui permet le traitement distribué de grands ensembles de données sur un cluster d'ordinateurs à l'aide d'un modèle de programmation simple. Apache™ Hadoop® est un logiciel open source pour une informatique distribuée fiable, évolutive. |
Le projet comprend les modules suivants :
Cet article vous aidera à installer hadoop sur CentOS étape par étape et à configurer un cluster hadoop à nœud unique.
Installer JavaAvant d'installer hadoop, assurez-vous que Java est installé sur votre système. Utilisez cette commande pour vérifier la version installée de Java.
java -version java version "1.7.0_75" Java(TM) SE Runtime Environment (build 1.7.0_75-b13) Java HotSpot(TM) 64-Bit Server VM (build 24.75-b04, mixed mode)
Pour installer ou mettre à jour Java, veuillez suivre les instructions étape par étape ci-dessous.
La première étape consiste à télécharger la dernière version de Java depuis le site officiel d'Oracle.
cd /opt/ wget --no-cookies --no-check-certificate --header "Cookie: gpw_e24=http%3A%2F%2Fwww.oracle.com%2F; oraclelicense=accept-securebackup-cookie" "http://download.oracle.com/otn-pub/java/jdk/7u79-b15/jdk-7u79-linux-x64.tar.gz" tar xzf jdk-7u79-linux-x64.tar.gz
Nécessite une configuration pour utiliser une version plus récente de Java comme alternative. Utilisez la commande suivante pour ce faire.
cd /opt/jdk1.7.0_79/ alternatives --install /usr/bin/java java /opt/jdk1.7.0_79/bin/java 2 alternatives --config java There are 3 programs which provide 'java'. Selection Command ----------------------------------------------- * 1 /opt/jdk1.7.0_60/bin/java + 2 /opt/jdk1.7.0_72/bin/java 3 /opt/jdk1.7.0_79/bin/java Enter to keep the current selection[+], or type selection number: 3 [Press Enter]
Maintenant, vous devrez peut-être également utiliser la commande alternatives pour définir les chemins des commandes javac et jar.
alternatives --install /usr/bin/jar jar /opt/jdk1.7.0_79/bin/jar 2 alternatives --install /usr/bin/javac javac /opt/jdk1.7.0_79/bin/javac 2 alternatives --set jar /opt/jdk1.7.0_79/bin/jar alternatives --set javac /opt/jdk1.7.0_79/bin/javac
L'étape suivante consiste à configurer les variables d'environnement. Utilisez les commandes suivantes pour définir correctement ces variables.
Définissez la variable JAVA_HOME :
export JAVA_HOME=/opt/jdk1.7.0_79
Définissez la variable JRE_HOME :
export JRE_HOME=/opt/jdk1.7.0_79/jre
Définir la variable PATH :
export PATH=$PATH:/opt/jdk1.7.0_79/bin:/opt/jdk1.7.0_79/jre/bin
Après avoir configuré l'environnement Java. Commencez à installer Apache Hadoop.
La première étape consiste à créer un compte utilisateur système pour l'installation de Hadoop.
useradd hadoop passwd hadoop
Vous devez maintenant configurer la clé ssh pour l'utilisateur hadoop. Utilisez la commande suivante pour activer la connexion SSH sans mot de passe.
su - hadoop ssh-keygen -t rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys exit
Téléchargez dès maintenant la dernière version disponible de hadoop sur le site officiel hadoop.apache.org.
cd ~ wget http://apache.claz.org/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz tar xzf hadoop-2.6.0.tar.gz mv hadoop-2.6.0 hadoop
L'étape suivante consiste à définir les variables d'environnement utilisées par hadoop.
Modifiez ~/.bashrc et ajoutez ces valeurs suivantes à la fin du fichier.
export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
Appliquer les modifications dans l'environnement d'exécution actuel.
source ~/.bashrc
Modifiez $HADOOP_HOME/etc/hadoop/hadoop-env.sh et définissez la variable d'environnement JAVA_HOME.
export JAVA_HOME=/opt/jdk1.7.0_79/
Maintenant, commençons par configurer un cluster hadoop de base à nœud unique.
Modifiez d'abord le fichier de configuration hadoop et apportez les modifications suivantes.
cd /home/hadoop/hadoop/etc/hadoop
Modifions core-site.xml.
fs.default.name hdfs://localhost:9000
Puis éditez hdfs-site.xml :
dfs.replication 1 dfs.name.dir file:///home/hadoop/hadoopdata/hdfs/namenode dfs.data.dir file:///home/hadoop/hadoopdata/hdfs/datanode
et éditez mapred-site.xml :
mapreduce.framework.name yarn
Dernière modification de fil-site.xml :
yarn.nodemanager.aux-services mapreduce_shuffle
Formatez maintenant le namenode à l'aide de la commande suivante :
hdfs namenode -format
Pour démarrer tous les services Hadoop, utilisez la commande suivante :
cd /home/hadoop/hadoop/sbin/ start-dfs.sh start-yarn.sh
Pour vérifier si tous les services démarrent normalement, utilisez la commande jps :
jps
Vous devriez voir un résultat comme celui-ci.
26049 SecondaryNameNode 25929 DataNode 26399 Jps 26129 JobTracker 26249 TaskTracker 25807 NameNode
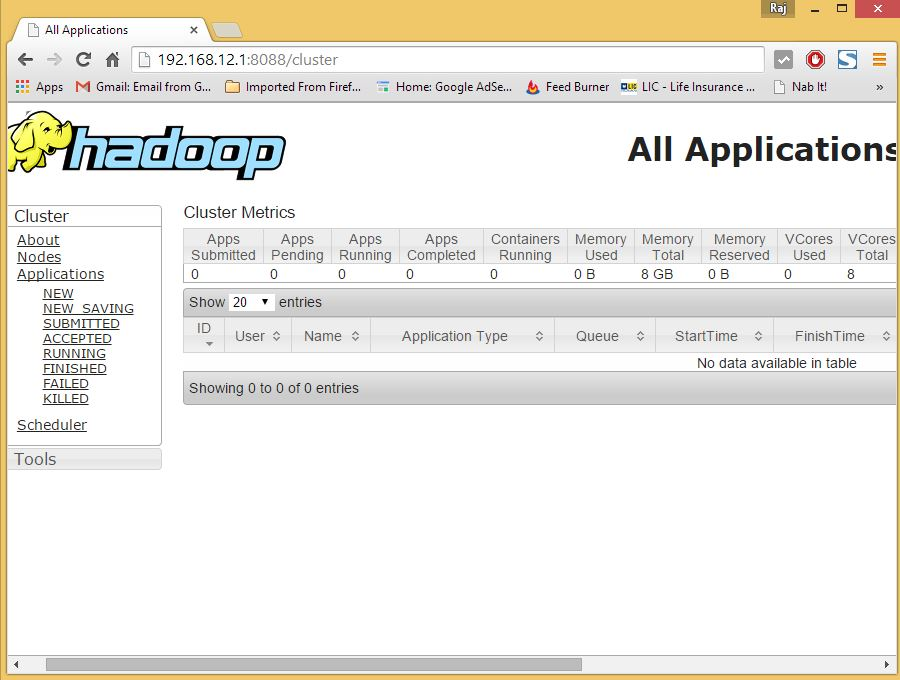
Vous pouvez désormais accéder au service Hadoop dans votre navigateur : http://votre-adresse-ip:8088/.
hadoop
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



