


Bonjour, je m'appelle Xiaozhuang !
Les débutants ne sont peut-être pas familiers avec la création de réseaux de neurones convolutifs (CNN). Illustrons-le avec un cas complet ci-dessous.
CNN est un modèle d'apprentissage profond largement utilisé dans la classification d'images, la détection de cibles, la génération d'images et d'autres tâches. Il extrait automatiquement les caractéristiques des images via des couches convolutives et des couches de pooling, et effectue une classification via des couches entièrement connectées. La clé de ce modèle est d'utiliser des opérations de convolution et de regroupement pour capturer efficacement les caractéristiques locales dans les images et les combiner via des réseaux multicouches pour obtenir une extraction avancée des caractéristiques et une classification des images.
La couche convolutive extrait les caractéristiques de l'image d'entrée via des opérations de convolution. Cette opération implique un noyau de convolution apprenable qui glisse sur l'image d'entrée et calcule le produit scalaire sous la fenêtre glissante. Ce processus permet d’extraire les caractéristiques locales, améliorant ainsi la perception du réseau de l’invariance de la traduction.
Formule :
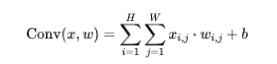
où x est l'entrée, w est le noyau de convolution et b est le biais.
La couche de pooling est une technologie de réduction de dimensionnalité couramment utilisée. Sa fonction est de réduire la dimension spatiale des données, réduisant ainsi la quantité de calcul et extrayant les caractéristiques les plus significatives. Parmi eux, le pooling maximum est une méthode de pooling courante, qui sélectionne la plus grande valeur dans chaque fenêtre en tant que représentative. Grâce à une mise en commun maximale, nous pouvons réduire la complexité des données et améliorer l'efficacité informatique du modèle tout en conservant les informations importantes.
Formule (Max Pooling) :
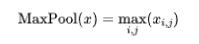
La couche entièrement connectée joue un rôle important dans le réseau neuronal. Elle extrait les couches convolutives et de pooling qui sont connectées aux catégories de sortie. . Chaque neurone de la couche entièrement connectée est connecté à tous les neurones de la couche précédente, afin que la synthèse et la classification des caractéristiques puissent être réalisées.
import torchimport torch.nn as nnimport torch.optim as optimfrom torchvision import datasets, transforms# 定义卷积神经网络类class SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()# 卷积层1self.conv1 = nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3, stride=1, padding=1)self.relu = nn.ReLU()self.pool = nn.MaxPool2d(kernel_size=2, stride=2)# 卷积层2self.conv2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=1)# 全连接层self.fc1 = nn.Linear(32 * 7 * 7, 10)# 输入大小根据数据调整def forward(self, x):x = self.conv1(x)x = self.relu(x)x = self.pool(x)x = self.conv2(x)x = self.relu(x)x = self.pool(x)x = x.view(-1, 32 * 7 * 7)x = self.fc1(x)return x# 定义损失函数和优化器net = SimpleCNN()criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(net.parameters(), lr=0.001)# 加载和预处理数据transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)# 训练网络num_epochs = 5for epoch in range(num_epochs):for i, (images, labels) in enumerate(train_loader):optimizer.zero_grad()outputs = net(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()if (i+1) % 100 == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], Loss: {loss.item()}')# 测试网络net.eval()with torch.no_grad():correct = 0total = 0for images, labels in test_loader:outputs = net(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()accuracy = correct / totalprint('Accuracy on the test set: {}%'.format(100 * accuracy))Cet exemple montre un modèle CNN simple, formé et testé à l'aide de l'ensemble de données MNIST.
Ensuite, nous ajoutons une étape de visualisation pour comprendre plus intuitivement les performances et le processus de formation du modèle.
import matplotlib.pyplot as plt
Pendant la boucle d'entraînement, enregistrez la perte et la précision de chaque époque.
# 在训练循环中添加以下代码train_loss_list = []accuracy_list = []for epoch in range(num_epochs):running_loss = 0.0correct = 0total = 0for i, (images, labels) in enumerate(train_loader):optimizer.zero_grad()outputs = net(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()if (i+1) % 100 == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], Loss: {loss.item()}')epoch_loss = running_loss / len(train_loader)accuracy = correct / totaltrain_loss_list.append(epoch_loss)accuracy_list.append(accuracy)# 在训练循环后,添加以下代码plt.figure(figsize=(12, 4))# 可视化损失plt.subplot(1, 2, 1)plt.plot(range(1, num_epochs + 1), train_loss_list, label='Training Loss')plt.title('Training Loss')plt.xlabel('Epochs')plt.ylabel('Loss')plt.legend()# 可视化准确率plt.subplot(1, 2, 2)plt.plot(range(1, num_epochs + 1), accuracy_list, label='Accuracy')plt.title('Accuracy')plt.xlabel('Epochs')plt.ylabel('Accuracy')plt.legend()plt.tight_layout()plt.show()De cette façon, nous pouvons voir les changements dans la perte et la précision de l'entraînement après le processus d'entraînement.
Après avoir importé le code, vous pouvez ajuster le contenu visuel et le format selon vos besoins.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 À quel point Snapdragon 8gen2 est-il équivalent à Apple ?
À quel point Snapdragon 8gen2 est-il équivalent à Apple ?
 Comment résoudre l'erreur d'application WerFault.exe
Comment résoudre l'erreur d'application WerFault.exe
 disposition absolue
disposition absolue
 Mongodb et MySQL sont faciles à utiliser et recommandés
Mongodb et MySQL sont faciles à utiliser et recommandés
 utilisation du format_numéro
utilisation du format_numéro
 conversion RVB en hexadécimal
conversion RVB en hexadécimal
 Comment créer des graphiques et des graphiques d'analyse de données en PPT
Comment créer des graphiques et des graphiques d'analyse de données en PPT
 Quelles sont les bibliothèques tierces couramment utilisées en PHP ?
Quelles sont les bibliothèques tierces couramment utilisées en PHP ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



