


À l'ère des maquettes à grande échelle, Transformer soutient à lui seul l'ensemble du domaine de la recherche scientifique. Depuis sa sortie, les modèles de langage basés sur Transformer ont démontré d'excellentes performances sur une variété de tâches. L'architecture sous-jacente de Transformer est devenue à la pointe de la technologie en matière de modélisation et d'inférence du langage naturel, et s'est également révélée prometteuse dans des domaines tels que la vision par ordinateur. et l'apprentissage par renforcement. Cela montre de fortes perspectives
L'architecture actuelle du Transformer est très vaste et nécessite généralement beaucoup de ressources informatiques pour la formation et l'inférence
C'est intentionnel, car un Transformer formé avec plus de paramètres ou de données l'est évidemment. plus grand que les autres modèles sont plus performants. Néanmoins, un nombre croissant de travaux montrent que les modèles basés sur Transformer ainsi que les réseaux de neurones ne nécessitent pas tous les paramètres ajustés pour préserver leurs hypothèses apprises.
En général, une surparamétrage massif semble être utile lors de la formation de modèles, mais ces modèles peuvent être fortement élagués avant l'inférence ; des études montrent que les réseaux de neurones peuvent souvent supprimer plus de 90 % des poids sans obtenir de bonnes performances. déclin. Ce phénomène a incité les chercheurs à se tourner vers des stratégies d'élagage qui facilitent l'inférence de modèles
Des chercheurs du MIT et de Microsoft ont rapporté dans un article intitulé "La vérité est là : améliorer l'amélioration grâce à la réduction du classement sélectif des couches". l'article "La capacité de raisonnement des modèles linguistiques". Ils ont constaté qu'un élagage fin sur des couches spécifiques du modèle Transformer peut améliorer considérablement les performances du modèle sur certaines tâches

Cette intervention simple est appelée LASER (LAyer SElective Rank réduction) dans l'étude. Il améliore considérablement les performances de LLM en réduisant sélectivement les composants d'ordre supérieur de la matrice de poids d'apprentissage d'une couche spécifique du modèle Transformer via une décomposition en valeurs singulières. Cette opération peut être effectuée une fois la formation du modèle terminée et ne nécessite aucun paramètre ou donnée supplémentaire
Pendant l'opération, la réduction des poids est effectuée en appliquant des matrices et des couches de poids spécifiques au modèle. L'étude a également révélé que de nombreuses matrices similaires étaient capables de réduire considérablement les poids et qu'en général, aucune dégradation des performances n'était observée jusqu'à ce que plus de 90 % des composants soient supprimés.
L'étude a également révélé que la réduction de ces facteurs peut améliorer considérablement la précision. Il est intéressant de noter que cette découverte s'applique non seulement au langage naturel, mais améliore également les performances de l'apprentissage par renforcement
De plus, cette étude tente de déduire ce qui est stocké dans les composants d'ordre supérieur afin d'améliorer les performances par suppression. L'étude a révélé qu'après avoir utilisé LASER pour répondre aux questions, le modèle original répondait principalement en utilisant des mots à haute fréquence (tels que « le », « de », etc.). Ces mots ne correspondent même pas au type sémantique de la bonne réponse, ce qui signifie que sans intervention, ces composants amèneront le modèle à générer des mots à haute fréquence non pertinents
Cependant, après avoir effectué un certain degré de réduction de rang, Le les réponses du modèle peuvent être transformées en réponses correctes.
Pour comprendre cela, l'étude a également exploré ce que les composants restants codaient individuellement, et ils ont approximé la matrice de poids en utilisant uniquement leurs vecteurs singuliers d'ordre supérieur. Il a été constaté que ces composants décrivaient des réponses différentes ou des mots courants à haute fréquence dans la même catégorie sémantique que la réponse correcte.
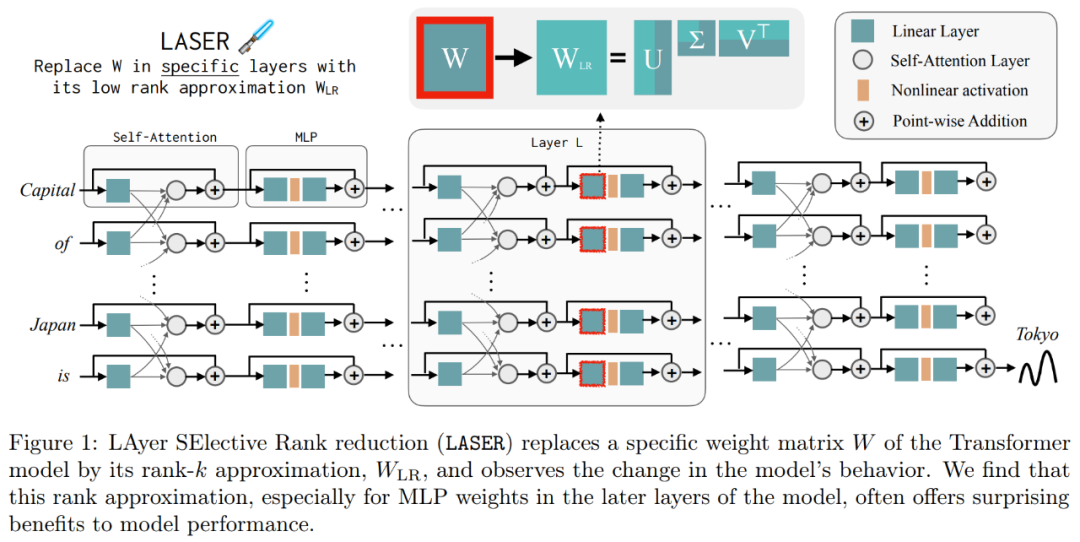
Ces résultats suggèrent que lorsque des composants bruyants d'ordre supérieur sont combinés avec des composants d'ordre inférieur, leurs réponses contradictoires produisent une réponse moyenne, qui peut être incorrecte. La figure 1 fournit une représentation visuelle de l'architecture du Transformer et de la procédure suivie par LASER. Ici, la matrice de poids d'une couche spécifique de perceptron multicouche (MLP) est remplacée par son approximation de bas rang.
Le chercheur a présenté l'intervention LASER en détail. L'intervention LASER en une seule étape est définie par trois paramètres (τ, ℓ et ρ). Ensemble, ces paramètres décrivent la matrice à remplacer par l'approximation de bas rang et le degré d'approximation. Le chercheur classe la matrice à intervenir selon le type de paramètre
Le chercheur se concentre sur la matrice W = {W_q, W_k, W_v, W_o, U_in, U_out}, qui est composée de perceptron multicouche (MLP) et d'attention Composition matricielle dans la couche de force. Le nombre de couches représente le niveau d’intervention du chercheur, où l’indice de la première couche est 0. Par exemple, Llama-2 a 32 niveaux, il est donc exprimé sous la forme ℓ ∈ {0, 1, 2,・・・31}
En fin de compte, ρ ∈ [0, 1) décrit quelle partie du rang maximum doit être préservée lors des approximations de bas rang. Par exemple, en supposant 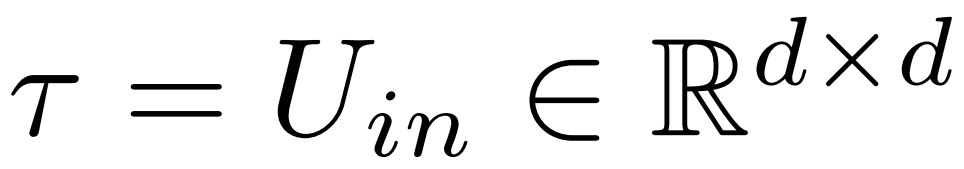 , le rang maximum de la matrice est d. Les chercheurs l'ont remplacé par l'approximation ⌊ρ・d⌋-.
, le rang maximum de la matrice est d. Les chercheurs l'ont remplacé par l'approximation ⌊ρ・d⌋-.
Les éléments suivants sont requis Dans la figure 1 ci-dessous, un exemple de LASER est présenté. Les symboles τ = U_in et ℓ = L sur la figure indiquent que la matrice de poids de première couche du MLP est mise à jour dans le bloc Transformer de la Lème couche. Il existe également un paramètre permettant de contrôler la valeur k dans l'approximation du rang k
LASER peut limiter le flux de certaines informations dans le réseau et produire de manière inattendue des avantages significatifs en termes de performances. Ces interventions peuvent également être facilement combinées, comme par exemple appliquer un ensemble d'interventions dans n'importe quel ordre 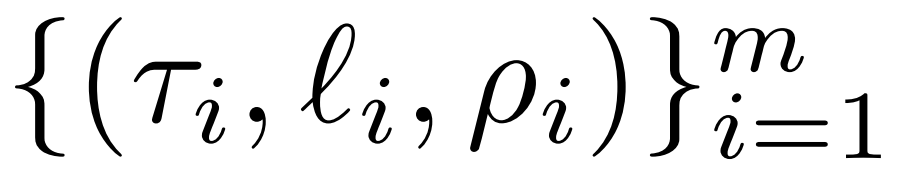 .
.
La méthode LASER n'est qu'une simple recherche de ce type d'intervention, modifiée pour apporter un bénéfice maximum. Il existe cependant de nombreuses autres manières de combiner ces interventions, ce qui constitue une orientation pour les travaux futurs.
Dans la partie expérimentale, le chercheur a utilisé le modèle GPT-J pré-entraîné sur l'ensemble de données PILE, qui comporte 27 couches et 6 milliards de paramètres. Le comportement du modèle est ensuite évalué sur l'ensemble de données CounterFact, qui contient des échantillons de triplets (sujet, relation et réponse), avec trois invites de paraphrase fournies pour chaque question.
Tout d'abord, nous avons analysé le modèle GPT-J sur l'ensemble de données CounterFact. La figure 2 montre l'impact sur la perte de classification d'un ensemble de données après avoir appliqué différents niveaux de réduction de rang à chaque matrice de l'architecture Transformer. Chaque couche de transformateur se compose d'un petit MLP à deux couches, avec des matrices d'entrée et de sortie affichées séparément. Différentes couleurs représentent différents pourcentages de composants supprimés
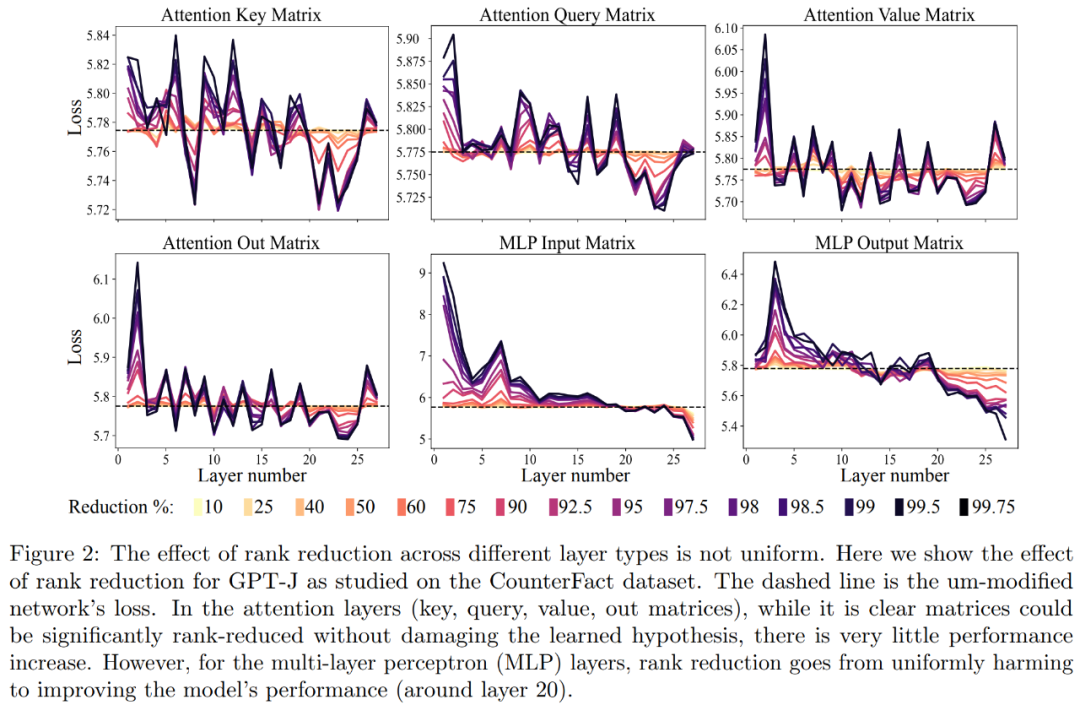
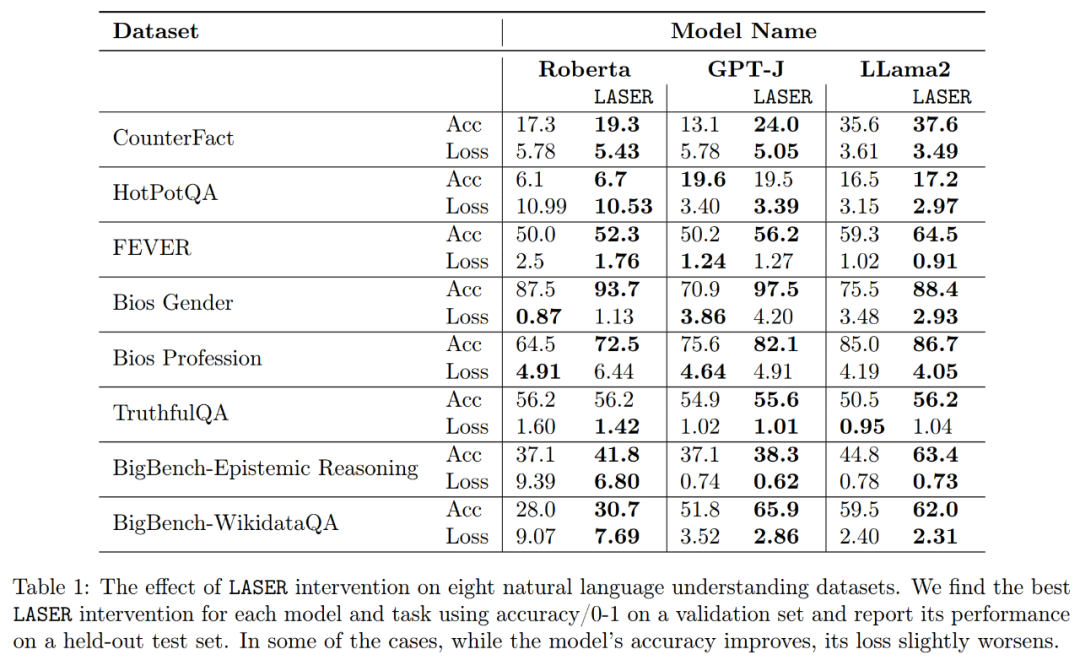
Concernant la précision et la robustesse de l'interprétation améliorée, comme le montrent la figure 2 ci-dessus et le tableau 1 ci-dessous, les chercheurs ont constaté que lors de la réduction de rang sur une seule couche, le factuel la précision du modèle GPT-J sur l'ensemble de données CounterFact est passée de 13,1 % à 24,0 %. Il est important de noter que ces améliorations sont uniquement le résultat d’une réduction de rang et n’impliquent aucune formation supplémentaire ni ajustement du modèle.
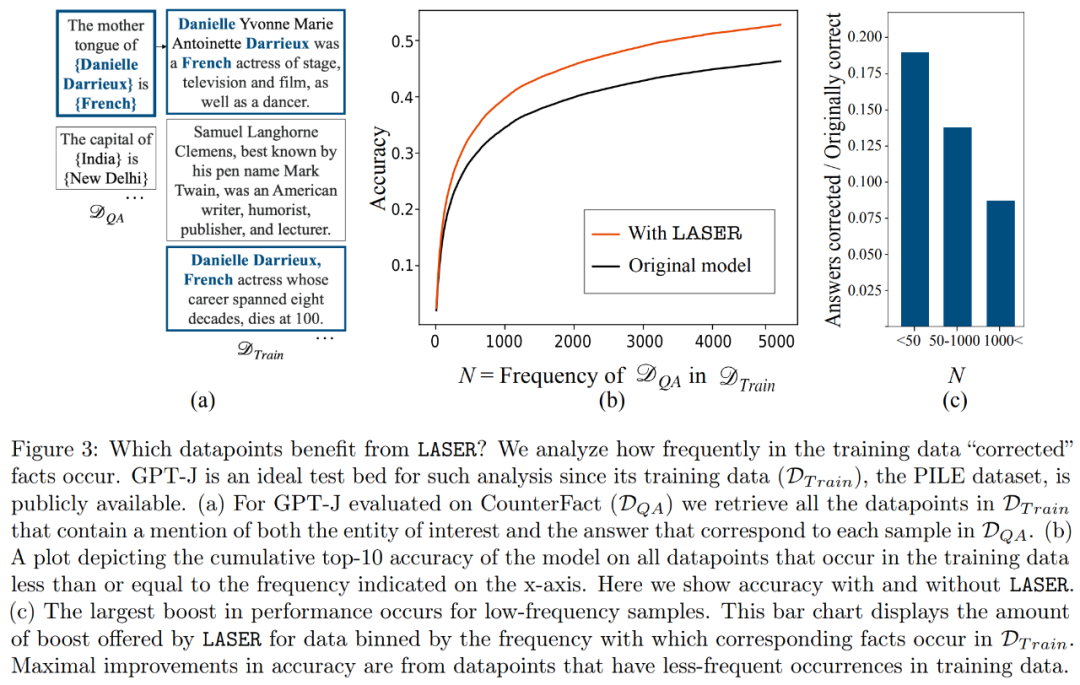
Quels faits seront restaurés lors de la restauration de rang inférieur ? Les chercheurs ont découvert que les faits obtenus grâce à la récupération par réduction de rang sont susceptibles d'apparaître très rarement dans l'ensemble de données, comme le montre la figure 3
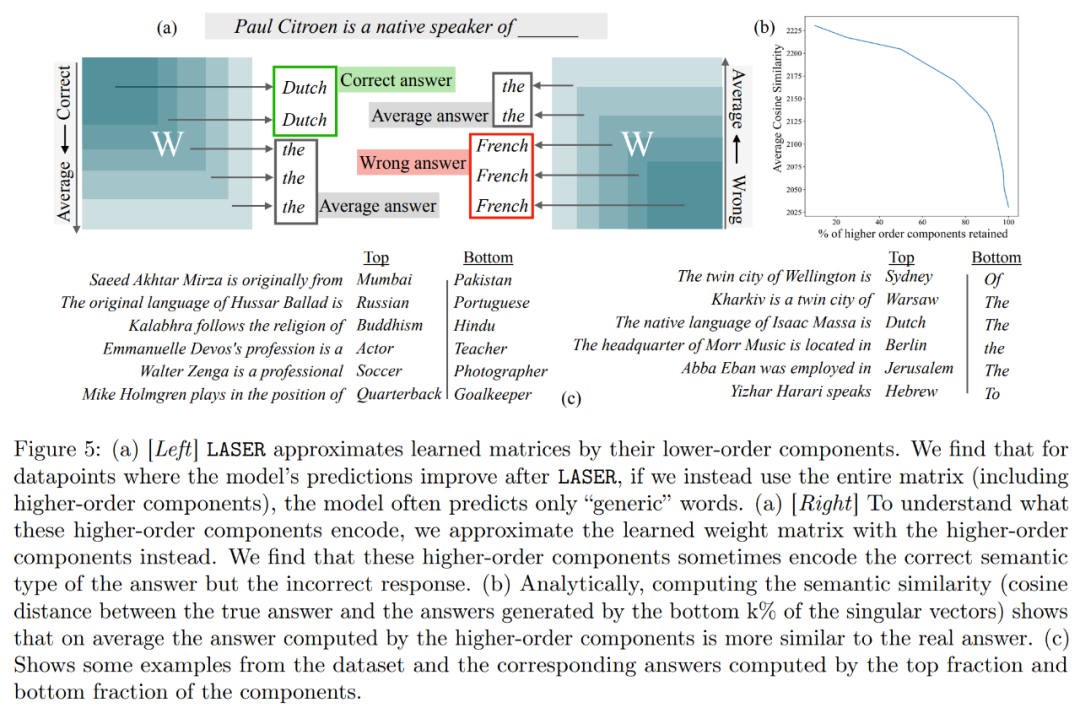
Que stockent les composants d'ordre supérieur ? Les chercheurs utilisent des composants d'ordre élevé pour se rapprocher de la matrice de poids finale (au lieu d'utiliser des composants d'ordre inférieur comme LASER), comme le montre la figure 5 (a) ci-dessous. Ils ont mesuré la similarité cosinusoïdale moyenne des vraies réponses par rapport aux réponses prédites lors de l'approximation de la matrice en utilisant différents nombres de composants d'ordre supérieur, comme le montre la figure 5 (b) ci-dessous.
Les chercheurs ont finalement évalué la généralisabilité des trois LLM différents qu'ils ont trouvés sur plusieurs tâches de compréhension du langage. Pour chaque tâche, ils ont évalué les performances du modèle à l’aide de trois mesures : la précision de la génération, la précision de la classification et la perte. D'après les résultats du tableau 1, même si le rang de la matrice est considérablement réduit, cela n'entraînera pas une diminution de la précision du modèle, mais peut au contraire améliorer les performances du modèle
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Utilisation de la fonction sqrt en Java
Utilisation de la fonction sqrt en Java
 Comment mesurer la vitesse du réseau sur un ordinateur
Comment mesurer la vitesse du réseau sur un ordinateur
 Solution au problème selon lequel l'entrée n'est pas prise en charge au démarrage de l'ordinateur
Solution au problème selon lequel l'entrée n'est pas prise en charge au démarrage de l'ordinateur
 éditeur HTML en ligne
éditeur HTML en ligne
 Que signifie ajouter en Java ?
Que signifie ajouter en Java ?
 Erreur de connexion au serveur d'identifiant Apple
Erreur de connexion au serveur d'identifiant Apple
 Quelle plateforme est Fengxiangjia ?
Quelle plateforme est Fengxiangjia ?
 Que dois-je faire si eDonkey Search ne parvient pas à se connecter au serveur ?
Que dois-je faire si eDonkey Search ne parvient pas à se connecter au serveur ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



