


Avec l'émergence des grands modèles de langage (LLM) et des modèles visuels de base (VFM), on s'attend à ce que les systèmes d'intelligence artificielle multimodaux avec de grands modèles puissent percevoir de manière globale le monde réel et prendre des décisions comme les humains. Ces derniers mois, le LLM a attiré une grande attention dans le domaine de la recherche sur la conduite autonome. Malgré le grand potentiel du LLM, il existe encore des défis, des opportunités et des orientations de recherche futures dans les systèmes de conduite, qui manquent actuellement d'élucidation détaillée.
Dans cet article, des recherches menées par Tencent Maps, Purdue University, UIUC et University of Virginia Personnel recherche systématique dans ce domaine. Cette étude présente d'abord le contexte des modèles multimodaux à grand langage (MLLM), les progrès du développement de modèles multimodaux utilisant LLM et un examen de l'histoire de la conduite autonome. L'étude fournit ensuite un aperçu des outils MLLM existants pour les systèmes de conduite, de trafic et de cartographie, ainsi que des ensembles de données existants. L'étude résume également les travaux connexes du 1er atelier WACV sur les grands modèles de langage et de vision pour la conduite autonome (LLVM-AD), le premier atelier sur l'application du LLM à la conduite autonome. Afin de promouvoir davantage le développement de ce domaine, cette étude discute également de la manière d'appliquer le MLLM aux systèmes de conduite autonome et de certaines questions importantes qui doivent être résolues par le monde universitaire et l'industrie.

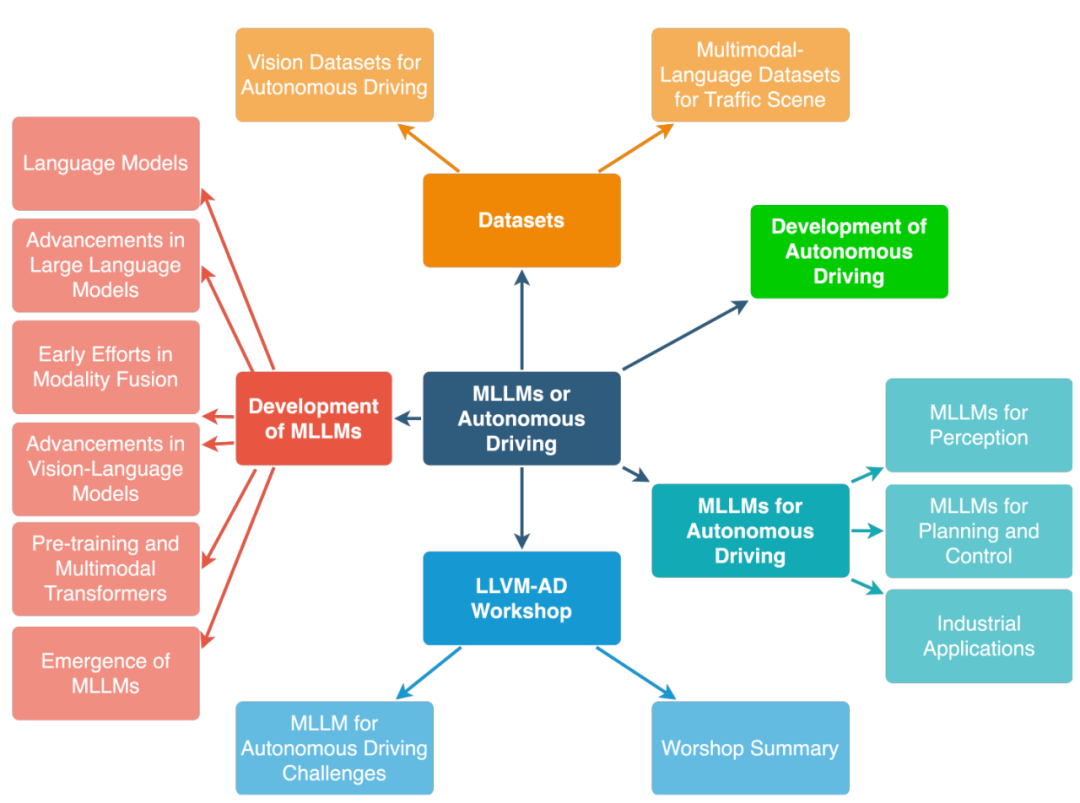
Multimodal Large Language Model (MLLM) a récemment attiré beaucoup d'attention, ce Le modèle combine les capacités d'inférence de LLM avec des données d'image, vidéo et audio, permettant à ces données d'effectuer plus efficacement diverses tâches grâce à un alignement multimodal, notamment la classification d'images, l'alignement de texte avec les vidéos correspondantes et la détection de la parole. De plus, certaines études ont montré que le LLM peut gérer des tâches simples dans le domaine de la robotique. Cependant, actuellement dans le domaine de la conduite autonome, l'intégration du MLLM progresse lentement. Existe-t-il un potentiel d'amélioration des systèmes de conduite autonome existants, tels que. GPT-4, PaLM-2 et les LLM comme LLaMA-2 nécessitent encore des recherches et une exploration plus approfondies
Dans cette revue, les chercheurs pensent que l'intégration des LLM dans le domaine de la conduite autonome peut entraîner un changement de paradigme significatif, améliorant ainsi la perception de la conduite. , la planification des mouvements, l'interaction homme-véhicule et le contrôle des mouvements pour offrir aux utilisateurs des solutions de transport futures plus adaptables et plus fiables. En termes de perception, LLM peut utiliser Tool Learning pour appeler des API externes afin d'accéder à des sources d'informations en temps réel, telles que des cartes de haute précision, des rapports de trafic et des informations météorologiques, afin que le véhicule puisse mieux comprendre l'environnement qui l'entoure. Les voitures autonomes peuvent raisonner sur les itinéraires encombrés via LLM et suggérer des chemins alternatifs pour améliorer l'efficacité et la sécurité de la conduite. En termes de planification de mouvement et d'interaction homme-véhicule, LLM peut promouvoir une communication centrée sur l'utilisateur, permettant aux passagers d'exprimer leurs besoins et leurs préférences dans un langage courant. En termes de contrôle de mouvement, LLM permet d'abord de personnaliser les paramètres de contrôle en fonction des préférences du conducteur, réalisant ainsi une expérience de conduite personnalisée. De plus, LLM peut offrir de la transparence à l'utilisateur en expliquant chaque étape du processus de contrôle de mouvement. L'examen prédit que dans les futurs véhicules autonomes de niveau SAE L4-L5, les passagers pourront utiliser le langage, les gestes et même les yeux pour communiquer leurs demandes, le MLLM fournissant des commentaires en temps réel dans la voiture et sur la conduite via des affichages visuels intégrés ou des réponses vocales. processus de développement de la conduite autonome et des modèles multi-modes à grand langage
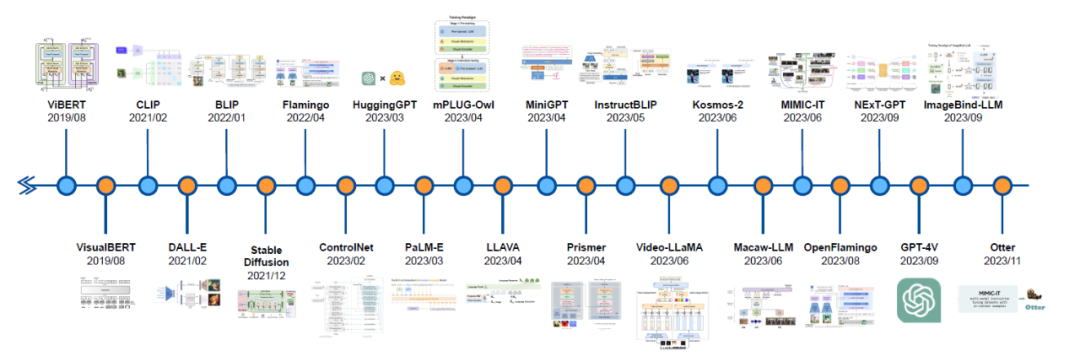 Résumé de la recherche sur la conduite autonome MLLM : Le cadre LLM du modèle actuel comprend principalement LAMA et LAMA 2. GPT-3.5, GPT-4 , Flan5XXL, Vicuna-13b. FT, ICL et PT font référence au réglage fin, à l'apprentissage contextuel et à la pré-formation dans ce tableau. Pour les liens vers la littérature, veuillez vous référer au dépôt github : https://github.com/IrohXu/Awesome-Multimodal-LLM-Autonomous-Driving
Résumé de la recherche sur la conduite autonome MLLM : Le cadre LLM du modèle actuel comprend principalement LAMA et LAMA 2. GPT-3.5, GPT-4 , Flan5XXL, Vicuna-13b. FT, ICL et PT font référence au réglage fin, à l'apprentissage contextuel et à la pré-formation dans ce tableau. Pour les liens vers la littérature, veuillez vous référer au dépôt github : https://github.com/IrohXu/Awesome-Multimodal-LLM-Autonomous-Driving
Afin de construire un pont entre la conduite autonome et le LLVM, les chercheurs concernés ont organisé le premier atelier de conduite autonome avec un grand modèle de langage et de vision (LLVM-AD) lors de la conférence d'hiver 2024 IEEE/CVF sur les applications de vision par ordinateur (WACV). Cet atelier vise à renforcer la collaboration entre les chercheurs universitaires et les professionnels de l'industrie pour explorer les possibilités et les défis de la mise en œuvre de modèles linguistiques multimodaux à grande échelle dans le domaine de la conduite autonome. LLVM-AD promouvra davantage le développement d'ensembles de données open source ultérieurs sur la compréhension du langage du trafic réel
Le premier atelier de conduite autonome de modèle de langage et de vision à grande échelle WACV (LLVM-AD) a accepté un total de neuf articles. Certains de ces articles portent sur de grands modèles de langage multimodaux dans la conduite autonome, en se concentrant sur l'intégration du LLM dans l'interaction utilisateur-véhicule, la planification des mouvements et le contrôle du véhicule. Plusieurs articles explorent également de nouvelles applications du LLM pour l’interaction et la prise de décision de type humain dans les véhicules autonomes. Par exemple, « Imitating Human Driving » et « Driving by Language » explorent l'interprétation et le raisonnement de LLM dans des scénarios de conduite complexes, ainsi que les cadres permettant d'imiter le comportement humain. De plus, « Systèmes autonomes centrés sur l'humain et LLM » met l'accent sur le placement des utilisateurs au centre de la conception du LLM et sur l'utilisation du LLM pour interpréter les instructions de l'utilisateur. Cette approche représente un changement important vers des systèmes autonomes centrés sur l’humain. En plus du LLM fusionné, l'atelier a également couvert certaines méthodes pures basées sur la vision et le traitement des données. De plus, l'atelier a présenté des méthodes innovantes de traitement et d'évaluation des données. Par exemple, NuScenes-MQA introduit un nouveau schéma d'annotation pour les ensembles de données de conduite autonome. Collectivement, ces articles démontrent les progrès réalisés dans l'intégration de modèles de langage et de techniques avancées dans la conduite autonome, ouvrant la voie à des véhicules autonomes plus intuitifs, efficaces et centrés sur l'humain.
Pour les développements futurs, cette étude propose les orientations de recherche suivantes :
Le contenu qui doit être réécrit est le suivant : 1. De nouveaux ensembles de données pour les grands modèles de langage multimodaux dans la conduite autonome
Bien que de grands modèles de langage soient utilisés dans le langage Il y a eu des succès dans la compréhension de cela, mais des défis reste à l’appliquer à la conduite autonome. En effet, ces modèles doivent intégrer et comprendre les entrées provenant de différentes modalités, telles que les images panoramiques, les nuages de points 3D et les cartes de haute précision. Les limitations actuelles en termes de taille et de qualité des données signifient que les ensembles de données existants ne peuvent pas répondre pleinement à ces défis. De plus, les ensembles de données de langage visuel annotés à partir des premiers ensembles de données open source tels que NuScenes peuvent ne pas fournir une base de référence solide pour la compréhension du langage visuel dans les scénarios de conduite. Par conséquent, il existe un besoin urgent de nouveaux ensembles de données à grande échelle couvrant un large éventail de scénarios de circulation et de conduite pour compenser le problème de longue traîne (déséquilibre) des distributions d'ensembles de données précédentes afin de tester et d'améliorer efficacement les performances de ces modèles dans applications de conduite autonome.
2. Prise en charge matérielle requise pour les modèles à grand langage en conduite autonome
Différentes fonctions dans les véhicules autonomes ont des exigences matérielles différentes. L'utilisation de LLM à l'intérieur d'un véhicule pour planifier la conduite ou participer au contrôle du véhicule nécessite un traitement en temps réel et une faible latence pour garantir la sécurité, ce qui augmente les exigences de calcul et affecte la consommation d'énergie. Si LLM est déployé dans le cloud, la bande passante pour l'échange de données devient un autre facteur de sécurité critique. En revanche, l'utilisation de LLM pour la planification de la navigation ou l'analyse de commandes non liées à la conduite (telles que la lecture de musique dans la voiture) ne nécessite pas un volume de requêtes élevé ni des performances en temps réel, ce qui fait des services à distance une option viable. À l'avenir, le LLM en conduite autonome pourra être compressé grâce à la distillation des connaissances afin de réduire les besoins de calcul et la latence. Il reste encore beaucoup de place pour le développement dans ce domaine.
3. Utilisez de grands modèles linguistiques pour comprendre des cartes de haute précision
Les cartes de haute précision jouent un rôle essentiel dans la technologie des véhicules autonomes car elles fournissent des informations de base sur l'environnement physique dans lequel le véhicule évolue. La couche de carte sémantique dans les cartes HD est importante car elle capture la signification et les informations contextuelles de l'environnement physique. Afin d'encoder efficacement ces informations dans la prochaine génération de conduite autonome pilotée par le système d'annotation automatique d'IA cartographique de haute précision de Tencent, de nouveaux modèles sont nécessaires pour mapper ces fonctionnalités multimodales dans l'espace linguistique. Tencent a développé le système d'étiquetage automatique de cartes AI de haute précision THMA, basé sur l'apprentissage actif, qui peut produire et étiqueter des cartes de haute précision à une échelle de centaines de milliers de kilomètres. Afin de promouvoir le développement de ce domaine, Tencent a proposé l'ensemble de données MAPLM basé sur THMA, qui contient des images panoramiques, des nuages de points lidar 3D et des annotations cartographiques de haute précision basées sur le contexte, ainsi qu'un nouveau test de questions et réponses MAPLM-QA.
4. Grand modèle de langage dans l'interaction homme-véhicule
L'interaction homme-véhicule et la compréhension du comportement de conduite humaine constituent également un défi majeur dans la conduite autonome. Les conducteurs humains s'appuient souvent sur des signaux non verbaux, comme ralentir pour céder ou utiliser les mouvements du corps pour communiquer avec d'autres conducteurs ou piétons. Ces signaux non verbaux jouent un rôle essentiel dans la communication sur la route. Il y a eu de nombreux accidents impliquant des systèmes de conduite autonome dans le passé, car les voitures autonomes se comportaient souvent d'une manière à laquelle les autres conducteurs ne s'attendaient pas. À l'avenir, MLLM sera en mesure d'intégrer de riches informations contextuelles provenant de diverses sources et d'analyser le regard, les gestes et le style de conduite du conducteur pour mieux comprendre ces signaux sociaux et permettre une planification efficace. En estimant les signaux sociaux des autres conducteurs, LLM peut améliorer les capacités de prise de décision et la sécurité globale des véhicules autonomes.
Conduite autonome personnalisée
À mesure que les véhicules autonomes se développent, un aspect important est de considérer comment ils s'adaptent aux préférences de conduite individuelles de l'utilisateur. Il existe un consensus croissant selon lequel les voitures autonomes devraient imiter le style de conduite de leurs utilisateurs. Pour y parvenir, les systèmes de conduite autonome doivent apprendre et intégrer les préférences des utilisateurs dans divers aspects, tels que la navigation, la maintenance des véhicules et le divertissement. Les capacités de réglage des instructions et les capacités d’apprentissage contextuel de LLM le rendent idéal pour intégrer les préférences des utilisateurs et les informations sur l’historique de conduite dans les véhicules autonomes afin d’offrir une expérience de conduite personnalisée.
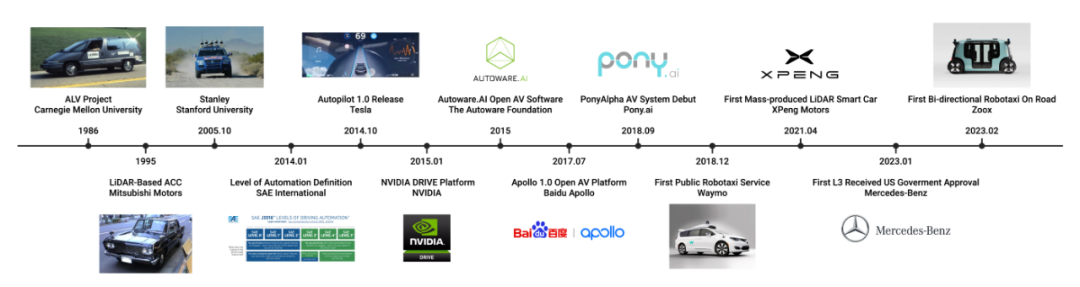
Depuis de nombreuses années, la conduite autonome est au centre de l'attention et a attiré de nombreux investisseurs en capital-risque. L'intégration du LLM dans les véhicules autonomes présente des défis uniques, mais les surmonter améliorera considérablement les systèmes autonomes existants. Il est prévisible que les cockpits intelligents pris en charge par LLM aient la capacité de comprendre les scénarios de conduite et les préférences des utilisateurs, et d'établir une confiance plus profonde entre le véhicule et ses occupants. De plus, les systèmes de conduite autonome déployant le LLM seront mieux à même de faire face aux dilemmes éthiques impliquant la mise en balance de la sécurité des piétons et de la sécurité des occupants du véhicule, favorisant ainsi un processus décisionnel plus susceptible d'être éthique dans des scénarios de conduite complexes. Cet article intègre les idées des membres du comité de l’atelier WACV 2024 LLVM-AD et vise à inciter les chercheurs à contribuer au développement de véhicules autonomes de nouvelle génération alimentés par la technologie LLM.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



