


Ces dernières années, des progrès significatifs ont été réalisés dans la conversion automatique de texte en contenu 3D, grâce au développement de modèles de diffusion pré-entraînés [1, 2, 3]. Parmi eux, DreamFusion[4] introduit une méthode efficace qui utilise un modèle de diffusion 2D pré-entraîné[5] pour générer automatiquement des actifs 3D à partir de texte sans avoir besoin d'un ensemble de données d'actifs 3D dédié
Introduit par DreamFusion Une innovation clé est l'algorithme d'échantillonnage par distillation fractionnée (SDS). L'algorithme évalue une seule représentation 3D à l'aide d'un modèle de diffusion 2D pré-entraîné, tel que NeRF [6], l'optimisant ainsi pour garantir que l'image rendue depuis n'importe quelle perspective de caméra conserve une haute cohérence avec le texte donné. Inspirés par l'algorithme fondateur SDS, plusieurs travaux [7, 8, 9, 10, 11] ont vu le jour pour faire progresser les tâches de génération de texte en 3D en appliquant des modèles de diffusion 2D pré-entraînés.
Bien que des progrès significatifs aient été réalisés dans la génération de texte en 3D en tirant parti de modèles de diffusion de texte en 2D pré-entraînés, il existe encore un grand écart entre les images 2D et les ressources 3D. Cette distinction est clairement démontrée dans la figure 1.
Premièrement, les modèles texte-2D produisent des résultats de génération indépendants de la caméra, en se concentrant sur la génération d'images de haute qualité sous des angles spécifiques tout en ignorant les autres angles. En revanche, la création de contenu 3D est étroitement liée aux paramètres de la caméra tels que la position, l'angle de prise de vue et le champ de vision. Par conséquent, les modèles de conversion texte-3D doivent produire des résultats de haute qualité sur tous les paramètres possibles de la caméra.
De plus, les modèles génératifs texte-2D doivent générer simultanément des éléments de premier plan et d'arrière-plan pour maintenir la cohérence globale de l'image. En revanche, les modèles génératifs texte-3D doivent uniquement se concentrer sur la création d’objets de premier plan. Cette différence permet aux modèles texte-3D d'allouer plus de ressources et d'attention pour représenter et générer avec précision les objets de premier plan. Par conséquent, lors de l'utilisation de modèles de diffusion 2D pré-entraînés directement pour la création d'actifs 3D, la différence de domaine entre la génération texte en 2D et la génération texte en 3D devient un obstacle évident aux performances
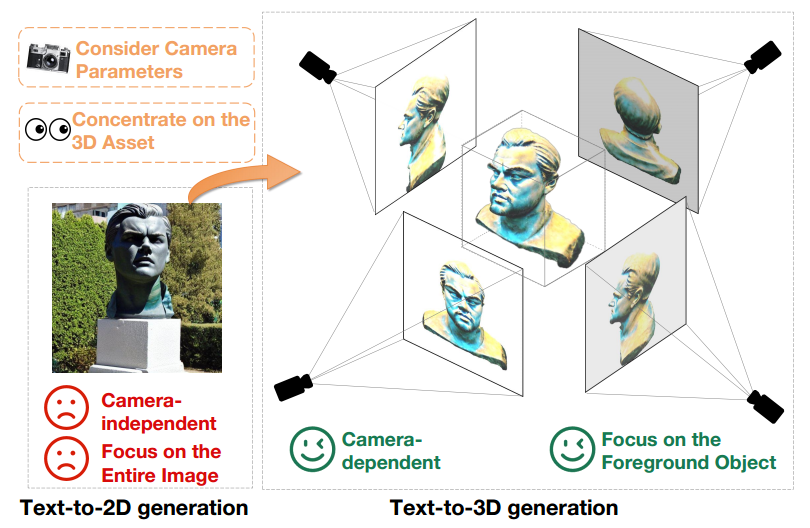
Figure 1 texte Sortie du Le modèle généré en 2D (à gauche) et le modèle généré en texte en 3D (à droite) sous la même invite de texte, à savoir "Une statue de la tête de Leonardo DiCaprio".
Pour résoudre ce problème, l'article propose X-Dreamer, une nouvelle méthode de création de contenu texte en 3D de haute qualité qui peut combler efficacement les écarts de domaine texte en 2D et texte en 3D entre les générations.
Les composants clés de X-Dreamer sont deux conceptions innovantes : l'adaptation de bas rang guidée par caméra (CG-LoRA) et la perte d'alignement du masque d'attention (AMA).
Premièrement, les méthodes existantes [7, 8, 9, 10] adoptent généralement des modèles de diffusion 2D pré-entraînés [5, 12] pour la génération de texte en 3D, qui n'ont pas de lien inhérent avec les paramètres de la caméra. Pour remédier à cette limitation et garantir que X-Dreamer produit des résultats directement affectés par les paramètres de la caméra, l'article présente CG-LoRA pour ajuster le modèle de diffusion 2D pré-entraîné. Notamment, les paramètres de CG-LoRA sont générés dynamiquement sur la base des informations de la caméra à chaque itération, établissant ainsi une relation robuste entre le modèle texte-3D et les paramètres de la caméra.
Deuxièmement, le modèle de diffusion de texte en 2D pré-entraîné accorde une attention à la génération de premier plan et d'arrière-plan, tandis que la création d'actifs 3D nécessite plus d'attention à la génération précise d'objets de premier plan. Pour résoudre ce problème, l'article propose la perte AMA, qui utilise un masque binaire d'objets 3D pour guider la carte d'attention d'un modèle de diffusion pré-entraîné afin de prioriser la création d'objets de premier plan. En intégrant ce module, X-Dreamer donne la priorité à la génération d'objets de premier plan, améliorant considérablement la qualité globale du contenu 3D généré.

Page d'accueil du projet :
https://xmu-xiaoma666.github.io/Projects/X-Dreamer/
Page d'accueil de Github : https://github.com/xmu-xiaoma666 /X-Dreamer
DiscussionArticleAdresse : https://arxiv.org/abs/2312.00085
X-Dreamer a apporté les contributions suivantes au domaine de la génération de texte en 3D :
X-Dreamer contient deux étapes principales : l'apprentissage de la géométrie et l'apprentissage de l'apparence. Pour l'apprentissage de la géométrie, cette étude utilise DMTET comme représentation 3D et utilise un ellipsoïde 3D pour l'initialiser. Une fois initialisée, la fonction de perte utilise la perte d'erreur quadratique moyenne (MSE). Ensuite, DMTET et CG-LoRA sont optimisés à l'aide de la perte d'échantillonnage par distillation fractionnée (SDS) et de la perte AMA proposée dans cette étude pour garantir l'alignement entre la représentation 3D et les signaux textuels d'entrée.
Pour l'apprentissage de l'apparence, l'article utilise le bidirectionnel. Modélisation de la fonction de distribution de réflexion (BRDF). Plus précisément, l'article utilise MLP avec des paramètres pouvant être entraînés pour prédire les matériaux de surface. Semblable à l'étape d'apprentissage de la géométrie, l'article utilise la perte SDS et la perte AMA pour optimiser les paramètres entraînables de MLP et CG-LoRA afin d'obtenir un alignement entre les représentations 3D et les signaux textuels. La figure 2 montre la composition détaillée de X-Dreamer.

Figure 2 Présentation de X-Dreamer, y compris l'apprentissage de la géométrie et l'apprentissage de l'apparence.
Geometry Learning(Geometry Learning)
Dans ce module, X-Dreamer utilise le réseau MLP pour paramétrer DMTET dans une représentation 3D. Afin d'améliorer la stabilité de la modélisation géométrique, cet article utilise un ellipsoïde 3D comme configuration initiale de DMTET
pour paramétrer DMTET dans une représentation 3D. Afin d'améliorer la stabilité de la modélisation géométrique, cet article utilise un ellipsoïde 3D comme configuration initiale de DMTET  . Pour chaque sommet
. Pour chaque sommet 
 appartenant à un maillage tétraédrique , nous nous entraînons
appartenant à un maillage tétraédrique , nous nous entraînons  à prédire deux grandeurs importantes : la valeur SDF
à prédire deux grandeurs importantes : la valeur SDF  et le décalage de déformation
et le décalage de déformation  . Afin d'initialiser
. Afin d'initialiser  en tant qu'ellipsoïde, cet article échantillonne N points uniformément répartis dans l'ellipsoïde et calcule la valeur SDF correspondante
en tant qu'ellipsoïde, cet article échantillonne N points uniformément répartis dans l'ellipsoïde et calcule la valeur SDF correspondante  . Par la suite, la perte d’erreur quadratique moyenne (MSE) est utilisée pour optimiser
. Par la suite, la perte d’erreur quadratique moyenne (MSE) est utilisée pour optimiser  . Ce processus d'optimisation garantit que le DMTET est efficacement initialisé pour ressembler à un ellipsoïde 3D. La formule de perte MSE est la suivante :
. Ce processus d'optimisation garantit que le DMTET est efficacement initialisé pour ressembler à un ellipsoïde 3D. La formule de perte MSE est la suivante : 

Après avoir initialisé la géométrie, alignez la géométrie du DMTET avec l'invite de texte de saisie. Cela se fait en utilisant une technique de rendu différentiel pour générer une carte normale n et un masque m de l'objet à partir d'un DMTET initialisé étant donné une pose de caméra c échantillonnée aléatoirement. Par la suite, la carte normale n est entrée dans un modèle de diffusion stable (SD) gelé avec une intégration CG-LoRA entraînable, et les paramètres dans
initialisé étant donné une pose de caméra c échantillonnée aléatoirement. Par la suite, la carte normale n est entrée dans un modèle de diffusion stable (SD) gelé avec une intégration CG-LoRA entraînable, et les paramètres dans  sont mis à jour en utilisant la perte SDS, définie comme suit :
sont mis à jour en utilisant la perte SDS, définie comme suit :

où,  représente les paramètres de SD, et
représente les paramètres de SD, et  est le bruit prédit de SD sous un niveau de bruit t et une intégration de texte y donnés. De plus,
est le bruit prédit de SD sous un niveau de bruit t et une intégration de texte y donnés. De plus,  , où
, où 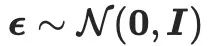 représente le bruit échantillonné à partir d'une distribution normale. L'implémentation de
représente le bruit échantillonné à partir d'une distribution normale. L'implémentation de  ,
,  et
et  est basée sur DreamFusion [4].
est basée sur DreamFusion [4].
De plus, afin de concentrer SD sur la génération d'objets au premier plan, X-Dreamer introduit une perte AMA supplémentaire pour aligner le masque d'objet avec la carte d'attention de SD comme suit :

Où  représente le nombre de couches d'attention,
représente le nombre de couches d'attention,  est la carte d'attention de la i-ième couche d'attention. La fonction
est la carte d'attention de la i-ième couche d'attention. La fonction  est utilisée pour ajuster la taille du masque d'objet 3D rendu afin de garantir que sa taille est alignée avec la taille de la carte d'attention.
est utilisée pour ajuster la taille du masque d'objet 3D rendu afin de garantir que sa taille est alignée avec la taille de la carte d'attention.
Apprentissage de l'apparence(Apprentissage de l'apparence)
Après avoir obtenu la géométrie d'un objet 3D, le but de cet article est de calculer l'apparence de l'objet 3D à l'aide d'un modèle matériel de Rendu Physique (PBR). Le modèle de matériau comprend un terme de diffusion  , un terme de rugosité et de métallicité
, un terme de rugosité et de métallicité  , et un terme de changement normal
, et un terme de changement normal  . Pour tout point
. Pour tout point 
de la surface de la géométrie, le perceptron multicouche (MLP) paramétré par  est utilisé pour obtenir trois termes matériaux, qui peuvent s'exprimer ainsi :
est utilisé pour obtenir trois termes matériaux, qui peuvent s'exprimer ainsi :

où,  Représente l'encodage de position à l'aide de la technologie de grille de hachage. Après cela, chaque pixel de l'image rendue peut être calculé à l'aide de la formule suivante :
Représente l'encodage de position à l'aide de la technologie de grille de hachage. Après cela, chaque pixel de l'image rendue peut être calculé à l'aide de la formule suivante :

Parmi eux, 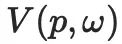 représente la valeur en pixel du point sur la surface de l'objet 3D rendu depuis la direction
représente la valeur en pixel du point sur la surface de l'objet 3D rendu depuis la direction 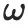
 .
.  représente l'hémisphère défini par l'ensemble des directions incidentes qui satisfont à la condition
représente l'hémisphère défini par l'ensemble des directions incidentes qui satisfont à la condition 
 , où
, où  représente la direction incidente et
représente la direction incidente et 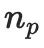 représente la normale à la surface au point
représente la normale à la surface au point  .
.  correspond à la lumière incidente de la carte d'environnement prête à l'emploi et
correspond à la lumière incidente de la carte d'environnement prête à l'emploi et  est la fonction de distribution de réflectance bidirectionnelle (BRDF) liée aux propriétés du matériau (c'est-à-dire
est la fonction de distribution de réflectance bidirectionnelle (BRDF) liée aux propriétés du matériau (c'est-à-dire  ). En agrégeant toutes les couleurs de pixels rendues, une image rendue
). En agrégeant toutes les couleurs de pixels rendues, une image rendue  est obtenue. Semblable à l'étape d'apprentissage de la géométrie, l'image rendue
est obtenue. Semblable à l'étape d'apprentissage de la géométrie, l'image rendue 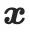 est introduite dans SD et optimisée
est introduite dans SD et optimisée  en utilisant la perte SDS et la perte AMA.
en utilisant la perte SDS et la perte AMA.
Adaptation de bas rang guidée par caméra (CG-LoRA)
Pour résoudre le problème de génération de résultats 3D sous-optimaux provoqués par l'écart de domaine entre la génération de texte en 2D et en 3D, X - Dreamer a proposé une méthode d'adaptation de bas rang guidée par caméra
comme le montre la figure 3, qui utilise des paramètres de caméra et un texte sensible à la direction pour guider la génération de paramètres dans CG-LoRA, permettant à X-Dreamer de percevoir efficacement le informations sur la position et la direction de la caméra.
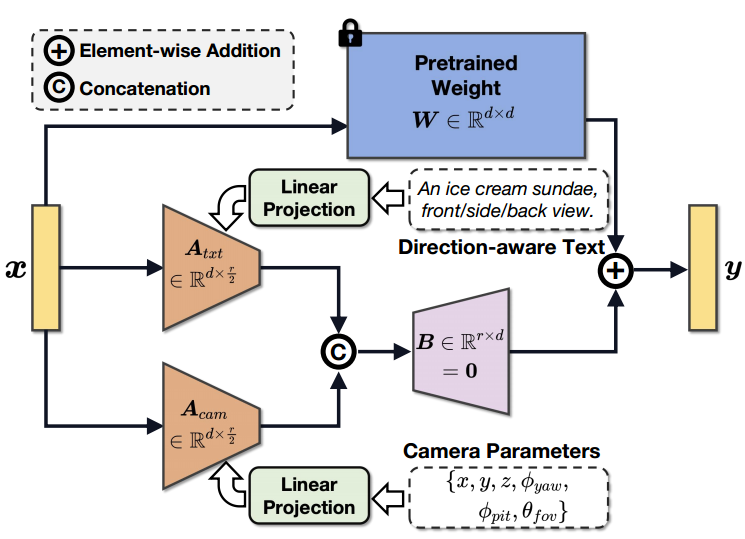
Figure 3 Illustration du CG-LoRA guidé par caméra.
Plus précisément, étant donné une invite de texte  et les paramètres de la caméra
et les paramètres de la caméra  , utilisez d'abord un encodeur CLIP de texte pré-entraîné
, utilisez d'abord un encodeur CLIP de texte pré-entraîné  et un MLP entraînable
et un MLP entraînable  pour projeter ces entrées dans l'espace des fonctionnalités :
pour projeter ces entrées dans l'espace des fonctionnalités :

Parmi eux,  et
et 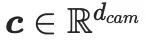 sont respectivement des fonctionnalités de texte et des fonctionnalités d'appareil photo. Après cela, deux matrices de bas rang sont utilisées pour projeter
sont respectivement des fonctionnalités de texte et des fonctionnalités d'appareil photo. Après cela, deux matrices de bas rang sont utilisées pour projeter  et
et  dans une matrice de réduction de dimensionnalité entraînable dans CG-LoRA :
dans une matrice de réduction de dimensionnalité entraînable dans CG-LoRA :

où,  et
et  sont CG-LoRA de matrices de réduction de dimensionnalité à deux dimensions. La fonction
sont CG-LoRA de matrices de réduction de dimensionnalité à deux dimensions. La fonction 
permet de transformer la forme du tenseur de  en
en  .
. 
 et
et  sont deux matrices de bas rang. Par conséquent, ils peuvent être décomposés en produit de deux matrices pour réduire les paramètres entraînables dans l'implémentation, c'est-à-dire
sont deux matrices de bas rang. Par conséquent, ils peuvent être décomposés en produit de deux matrices pour réduire les paramètres entraînables dans l'implémentation, c'est-à-dire  ,
,  ,
,  ,
,  ;
;  est un petit nombre (ex : 4). Selon la composition de LoRA, la matrice d'expansion des dimensions
est un petit nombre (ex : 4). Selon la composition de LoRA, la matrice d'expansion des dimensions 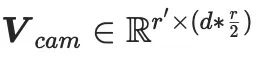 est initialisée à zéro pour garantir que le modèle commence l'entraînement avec les paramètres pré-entraînés de SD. Par conséquent, la formule du processus feedforward de CG-LoRA est la suivante :
est initialisée à zéro pour garantir que le modèle commence l'entraînement avec les paramètres pré-entraînés de SD. Par conséquent, la formule du processus feedforward de CG-LoRA est la suivante : 
 où, représente les paramètres figés du modèle SD pré-entraîné, et
où, représente les paramètres figés du modèle SD pré-entraîné, et
 est l'opération en cascade. Dans la mise en œuvre de cette méthode, CG-LoRA est intégré dans la couche d'intégration linéaire du module d'attention en SD pour capturer efficacement les informations d'orientation et de caméra.
est l'opération en cascade. Dans la mise en œuvre de cette méthode, CG-LoRA est intégré dans la couche d'intégration linéaire du module d'attention en SD pour capturer efficacement les informations d'orientation et de caméra.
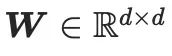 Ce qui doit être réexprimé est : la perte d'alignement du masque d'attention (perte AMA)
Ce qui doit être réexprimé est : la perte d'alignement du masque d'attention (perte AMA) 
SD est pré-entraîné pour générer des images 2D en tenant compte des éléments de premier plan et d'arrière-plan. Cependant, la génération de texte en 3D nécessite davantage d'attention à la génération d'objets de premier plan. Compte tenu de cette exigence, X-Dreamer propose la perte d'alignement du masque d'attention (perte AMA) pour aligner la carte d'attention de SD avec l'image de masque rendue de l'objet 3D. Plus précisément, pour chaque couche d'attention dans SD pré-entraîné, cette méthode utilise les caractéristiques de l'image de requête et les caractéristiques clés de l'étiquette CLS
pour calculer la carte d'attention. La formule de calcul est la suivante : 
Parmi eux,  représente le nombre de têtes dans le mécanisme d'attention multi-têtes,
représente le nombre de têtes dans le mécanisme d'attention multi-têtes,  représente la carte d'attention, puis la carte d'attention globale est calculée en faisant la moyenne des valeurs d'attentiondes cartes d'attention
représente la carte d'attention, puis la carte d'attention globale est calculée en faisant la moyenne des valeurs d'attentiondes cartes d'attention  dans toutes les têtes d'attention La valeur de
dans toutes les têtes d'attention La valeur de  .
.
Étant donné que la fonction softmax est utilisée pour normaliser les valeurs de la carte d'attention, les valeurs d'activation dans la carte d'attention peuvent devenir très petites lorsque la résolution des caractéristiques de l'image est élevée. Cependant, aligner directement la carte d'attention avec le masque de l'objet 3D rendu n'est pas optimal, étant donné que chaque élément du masque de l'objet 3D rendu est une valeur binaire de 0 ou 1. Pour résoudre ce problème, l'article propose une technique de normalisation qui mappe les valeurs de la carte d'attention entre (0, 1). La formule de ce processus de normalisation est la suivante :

où  représente une petite valeur constante (telle que
représente une petite valeur constante (telle que  ) pour empêcher 0 d'apparaître au dénominateur. Enfin, la perte AMA est utilisée pour aligner les cartes d'attention de toutes les couches d'attention sur le masque rendu de l'objet 3D.
) pour empêcher 0 d'apparaître au dénominateur. Enfin, la perte AMA est utilisée pour aligner les cartes d'attention de toutes les couches d'attention sur le masque rendu de l'objet 3D.
L'article utilise quatre GPU Nvidia RTX 3090 et la bibliothèque PyTorch pour mener des expériences. Pour calculer la perte de SDS, le modèle de diffusion stable mis en œuvre via des diffuseurs Hugging Face a été utilisé. Pour les codeurs DMTET et matériels, ils sont implémentés respectivement sous forme de MLP à deux couches et de MLP monocouche, avec une dimension de couche cachée de 32.
Partez de l'ellipsoïde pour générer du texte en 3D
Le document montre les résultats de la génération de texte en 3D de X-Dreamer en utilisant l'ellipsoïde comme forme géométrique initiale, comme indiqué dans Figure 4 illustrée. Les résultats démontrent la capacité de X-Dreamer à générer des objets 3D photoréalistes et de haute qualité qui correspondent avec précision aux invites de texte saisies.

Figure 4 Utilisation de l'ellipsoïde comme point de départ pour la génération de texte en 3D
À partir de la grille à gros grains pour la génération de texte en 3D
Bien que Un grand nombre de maillages à gros grains peuvent être téléchargés sur Internet, mais l'utilisation directe de ces maillages pour créer du contenu 3D entraîne souvent de mauvaises performances en raison d'un manque de détails géométriques. Cependant, ces maillages peuvent fournir à X-Dreamer de meilleures informations préalables sur la forme 3D que les ellipsoïdes 3D.
Par conséquent, il est également possible d'utiliser une grille de guidage à gros grains pour initialiser DMTET au lieu d'utiliser un ellipsoïde. Comme le montre la figure 5, X-Dreamer peut générer des ressources 3D avec des détails géométriques précis basés sur un texte donné, même si le maillage à gros grains fourni manque de détails.

Figure 5 Génération de texte en 3D à partir d'un maillage à gros grains.
Ce qui doit être réécrit est : Comparaison qualitative.
Pour évaluer l'efficacité de X-Dreamer, cet article le compare à quatre méthodes avancées : DreamFusion [4], Magic3D [8] , Fantasia3D [ 7] et ProlificDreamer [11], comme le montre la figure 6
Par rapport aux méthodes basées sur SDS [4, 7, 8], X-Dreamer les surpasse en générant des ressources 3D réalistes et de haute qualité. De plus, X-Dreamer produit du contenu 3D avec des effets visuels comparables, voire meilleurs, par rapport aux méthodes basées sur VSD [11] tout en nécessitant beaucoup moins de temps d'optimisation. Plus précisément, le processus d'apprentissage de la géométrie et de l'apparence ne prend qu'environ 27 minutes pour X-Dreamer, contre plus de 8 heures pour ProlificDreamer.

Figure 6 Comparaison avec les méthodes de l'état de l'art (SOTA).
Le contenu qui doit être réécrit est : Expérience d'ablation
Afin de comprendre en profondeur les capacités de la perte CG-LoRA et AMA, le journal a mené une étude d'ablation, dans laquelle chaque module a été ajouté individuellement pour évaluer son impact. Comme le montre la figure 7, les résultats de l'ablation montrent que lorsque CG-LoRA est exclu de X-Dreamer, la géométrie et la qualité d'apparence des objets 3D générés diminuent considérablement.
De plus, la perte AMA manquante de X-Dreamer a également un effet délétère sur la géométrie et la fidélité de l'apparence des actifs 3D générés. Ceux qui doivent être réécrits sont les suivants : Les expériences d'ablation fournissent une enquête précieuse sur les contributions individuelles des pertes CG-LoRA et AMA dans l'amélioration de la géométrie, de l'apparence et de la qualité globale des objets 3D générés.

Figure 7 Étude d'ablation du X-Dreamer.
Le but de l'introduction de la perte AMA est de concentrer l'attention sur les objets de premier plan pendant le processus de débruitage. Ceci est réalisé en alignant la carte d'attention de la SD avec le masque de rendu de l'objet 3D. Afin d'évaluer l'efficacité de la perte d'AMA pour atteindre cet objectif, cet article compare les cartes d'attention du SD avec et sans perte d'AMA respectivement dans les étapes d'apprentissage de la géométrie et d'apprentissage de l'apparence
Comme le montre la figure 8, on peut l'observer que l'ajout d'AMA La perte améliore non seulement la géométrie et l'apparence des actifs 3D générés, mais permet également à SD de concentrer son attention spécifiquement sur les zones d'objets de premier plan. Les résultats de visualisation confirment l'efficacité de la perte AMA pour guider l'attention SD, améliorant ainsi la qualité des étapes d'apprentissage de la géométrie et de l'apparence et la focalisation des objets de premier plan

Ce qui doit être réécrit est : La figure 8 démontre le attention Résultats de visualisation des tracés de force, des masques de rendu et des images rendues avec et sans perte AMA
Cette recherche introduit un cadre révolutionnaire appelé X-Dreamer, qui vise à résoudre les écarts texte-2D et texte-domaine entre la 3D génération pour améliorer la génération de texte en 3D. Pour atteindre cet objectif, l'article propose d'abord CG-LoRA, un module qui intègre des informations pertinentes en trois dimensions (y compris du texte sensible à la direction et des paramètres de caméra) dans un modèle de diffusion stable (SD) pré-entraîné. Ce faisant, cet article est capable de capturer efficacement les informations liées au domaine tridimensionnel. De plus, cet article conçoit une perte AMA pour aligner la carte d'attention générée par SD avec le masque de rendu de l'objet 3D. L'objectif principal de la perte AMA est de guider le texte vers des modèles 3D vers la génération d'objets de premier plan. Grâce à des expériences approfondies, cet article évalue de manière exhaustive l'efficacité de la méthode proposée et démontre que X-Dreamer est capable de générer un contenu 3D réaliste et de haute qualité basé sur des invites textuelles données
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Introduction au framework utilisé par vscode
Introduction au framework utilisé par vscode
 Commande cmd pour nettoyer les fichiers indésirables du lecteur C
Commande cmd pour nettoyer les fichiers indésirables du lecteur C
 Qu'est-ce que cela signifie lorsqu'un message a été envoyé mais rejeté par l'autre partie ?
Qu'est-ce que cela signifie lorsqu'un message a été envoyé mais rejeté par l'autre partie ?
 Programmation en langage de haut niveau
Programmation en langage de haut niveau
 Méthodes de cryptage du stockage des données
Méthodes de cryptage du stockage des données
 numéro de série Photoshop CS5
numéro de série Photoshop CS5
 Étapes pour supprimer l'un des systèmes doubles
Étapes pour supprimer l'un des systèmes doubles
 métamoteur de recherche
métamoteur de recherche







![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



