


Cette année, les grands modèles de langage (LLM) sont devenus le centre d'attention dans le domaine de l'intelligence artificielle. Le LLM a fait des progrès significatifs dans diverses tâches de traitement du langage naturel (NLP), notamment en raisonnement. Cependant, sur des tâches de raisonnement complexes, les performances de LLM doivent encore être améliorées
LLM peut-il déterminer qu'il y a des erreurs dans son propre raisonnement ? Récemment, une étude menée conjointement par l'Université de Cambridge et Google Research a révélé que LLM ne peut pas détecter les erreurs de raisonnement par lui-même, mais qu'il peut utiliser la méthode de retour en arrière proposée dans l'étude pour corriger les erreurs

Ce document a provoqué une certaine controverse, quelqu'un a soulevé des objections à ce sujet. Par exemple, sur Hacker News, quelqu'un a fait remarquer que le titre du journal était exagéré et un peu piège à clics. D'autres ont critiqué la méthode proposée dans l'article pour corriger les erreurs logiques comme étant basée sur la correspondance de modèles plutôt que sur l'utilisation de méthodes logiques. Cette méthode est sujette à l'échec. Huang et al dans l'article « Les grands modèles de langage ne peuvent pas auto-corriger le raisonnement. encore" Faites remarquer : l'autocorrection peut être efficace pour améliorer le style et la qualité des résultats du modèle, mais il existe peu de preuves que LLM ait la capacité d'identifier et de corriger son propre raisonnement et ses erreurs logiques sans retour externe. Par exemple, Reflexion et RCI utilisent tous deux le résultat de correction de la vérité terrain comme signal pour arrêter le cycle d'autocorrection.
L'équipe de recherche de l'Université de Cambridge et Google Research a proposé une nouvelle idée : diviser le processus d'autocorrection en deux étapes : la découverte des erreurs et la correction des résultats.
La découverte des erreurs est une compétence de raisonnement de base qui a été utilisé dans Il a été largement étudié et appliqué dans les domaines de la philosophie, de la psychologie et des mathématiques et a donné naissance à des concepts tels que la pensée critique, les erreurs logiques et mathématiques. Il est raisonnable de supposer que la capacité à détecter les erreurs devrait également être une exigence importante pour le LLM. Cependant, nos résultats montrent que les LLM de pointe sont actuellement incapables de détecter les erreurs de manière fiable.
En utilisant la méthode de conception d'invite de chaîne de réflexion, n'importe quelle tâche peut être transformée en tâche de découverte de bogues. À cette fin, les chercheurs ont collecté et publié un ensemble de données d’informations sur la trajectoire de type CoT, BIG-Bench Mistake, qui a été généré par PaLM et a marqué l’emplacement de la première erreur logique. Les chercheurs affirment que BIG-Bench Mistake est le premier ensemble de données de ce type qui ne se limite pas aux problèmes mathématiques.
Ces trajectoires proviennent de 5 tâches de l'ensemble de données BIG-Bench : tri de mots, suivi d'objets mélangés, déduction logique, arithmétique en plusieurs étapes et la langue Dyck. 
Afin de répondre aux questions de chaque tâche, ils ont utilisé la méthode de conception d'invite CoT pour appeler PaLM 2. Afin de diviser la trajectoire CoT en étapes claires, ils ont adopté la méthode proposée dans « React : Synergizing Reasoning and Acting in Language Models » pour générer chaque étape séparément et utiliser des nouvelles lignes comme marqueurs d'arrêt
Lors de la génération de toutes les trajectoires, dans ce ensemble de données, lorsque la température = 0, l'exactitude de la réponse est déterminée par une correspondance exacte
Sur le nouvel ensemble de données de découverte de bogues, GPT-4-Turbo, GPT-4 et La précision de GPT- 3.5-Turbo est présenté dans le tableau 4
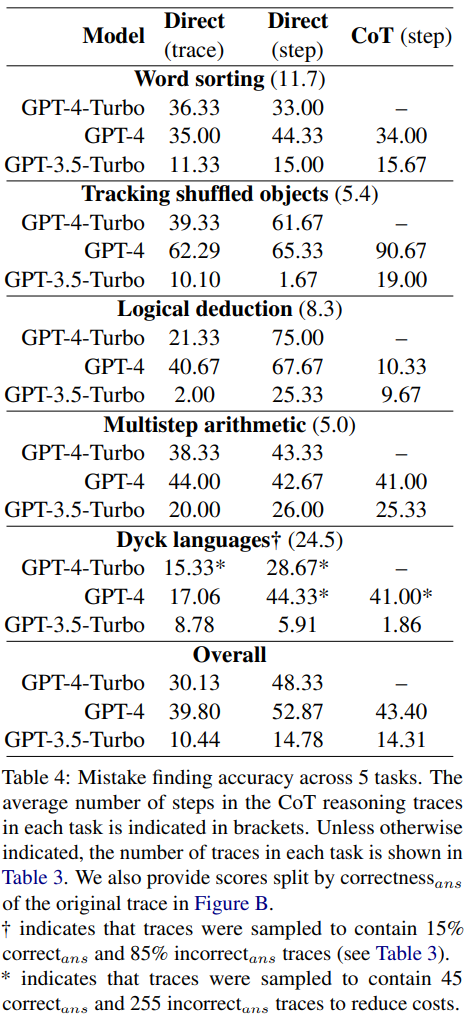
Chaque question a deux réponses possibles : soit correcte, soit fausse. S'il s'agit d'une erreur, la valeur N indiquera l'étape où la première erreur s'est produite
Tous les modèles ont été saisis avec les mêmes 3 invites. Ils ont utilisé trois méthodes de conception d'invites différentes :
Le contenu qui doit être réécrit est : Discussion connexe
Les résultats montrent que les trois modèles ont du mal à gérer ce nouvel ensemble de données de découverte d'erreurs. GPT fonctionne mieux, mais il ne peut atteindre qu'une précision globale de 52,87 dans la conception d'invites directes au niveau des étapes.
Cela montre que les LLM de pointe actuels ont du mal à trouver les erreurs, même dans les cas les plus simples et les plus clairs. En revanche, les humains peuvent détecter des erreurs sans expertise spécifique et avec une grande cohérence.
Les chercheurs pensent que l’incapacité de LLM à détecter les erreurs est la principale raison pour laquelle LLM ne peut pas auto-corriger les erreurs de raisonnement.
Comparaison rapide des méthodes de conception
Les chercheurs ont découvert que de la méthode au niveau de la trajectoire directe à la méthode au niveau des étapes en passant par la méthode CoT, la précision de la trajectoire diminuait considérablement sans erreurs. La figure 1 montre ce compromis
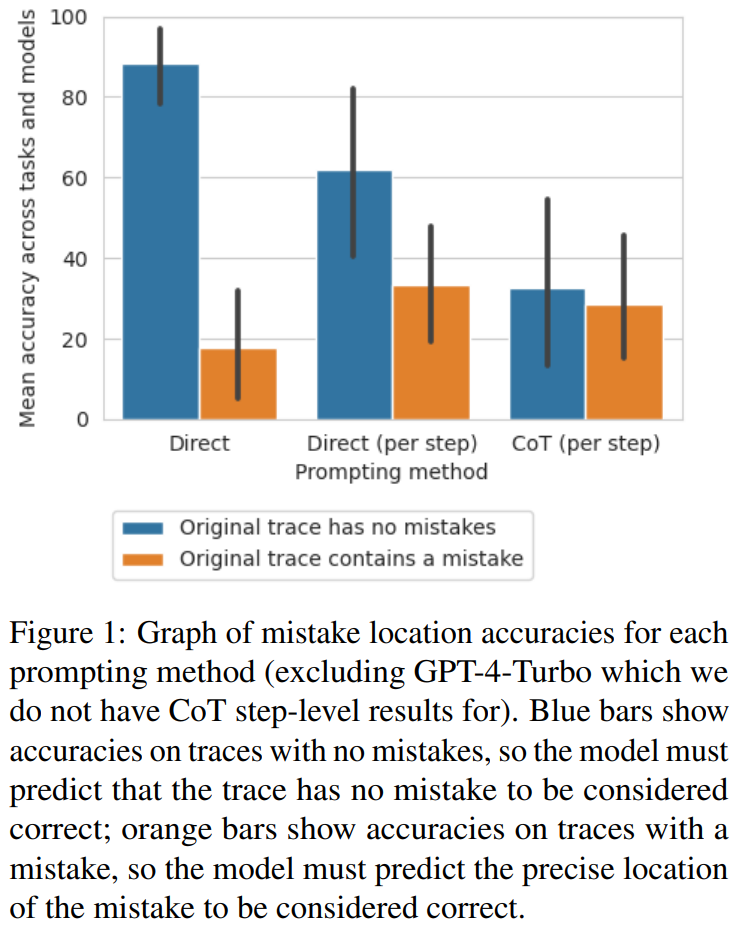
Les chercheurs pensent que la raison en est peut-être le nombre de sorties du modèle. Les trois méthodes nécessitent la génération de résultats de plus en plus complexes : les méthodes de conception rapide qui génèrent directement des trajectoires nécessitent un seul jeton, les méthodes de conception rapide qui génèrent directement des étapes nécessitent un jeton par étape, et les méthodes de conception rapide au niveau des étapes CoT nécessitent plusieurs phrases pour chaque étape. S'il existe une certaine probabilité d'un taux d'erreur par appel de build, plus il y a d'appels par trace, plus grandes sont les chances que le modèle identifie au moins une erreur
Peu d'échantillons avec l'emplacement de l'erreur comme proxy de l'exactitude de la conception rapide
Les chercheurs ont examiné si ces méthodes de conception rapides pouvaient déterminer de manière fiable l'exactitude d'une trajectoire plutôt que son emplacement incorrect.
Ils ont calculé le score moyen de F1 en fonction de la capacité du modèle à prédire correctement s'il y a des erreurs dans la trajectoire. En cas d'erreur, la trajectoire prédite par le modèle est considérée comme la « mauvaise réponse ». Sinon, la trajectoire prédite par le modèle est considérée comme la "bonne réponse"
En utilisant correct_ans et incorrect_ans comme étiquettes positives et pondérées en fonction du nombre d'occurrences de chaque étiquette, les chercheurs ont calculé le score F1 moyen, et les résultats sont indiqué dans le tableau 5.
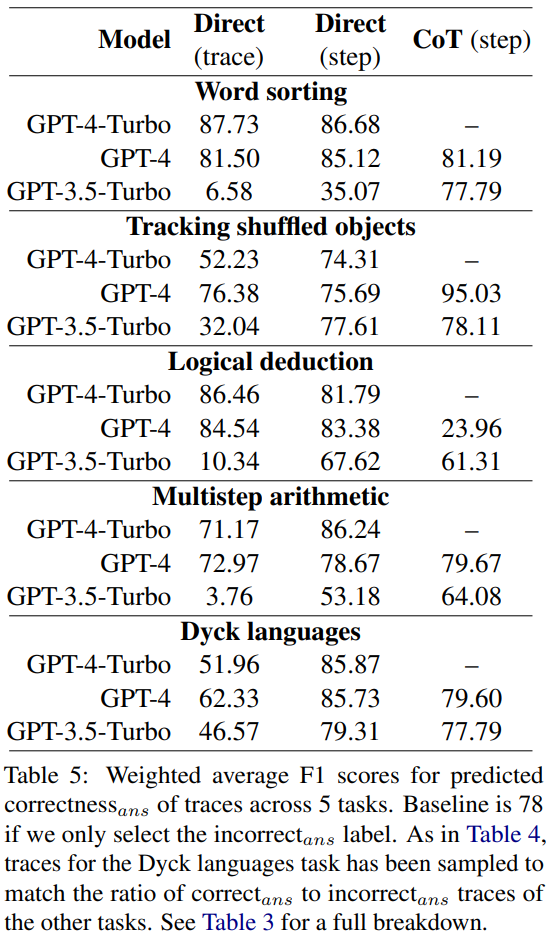
Ce score F1 pondéré montre que la recherche d'erreurs via l'invite est une mauvaise stratégie pour déterminer l'exactitude de la réponse finale.
Huang et al. ont souligné que LLM ne peut pas auto-corriger les erreurs logiques sans retour externe. Cependant, dans de nombreuses applications du monde réel, il n'y a souvent pas de retour externe disponible. Dans cette étude, les chercheurs ont adopté une alternative : un classificateur léger formé sur une petite quantité de données. Semblable aux modèles de récompense de l'apprentissage par renforcement traditionnel, ce classificateur peut détecter toute erreur logique dans les trajectoires CoT avant de les renvoyer au modèle générateur pour améliorer le résultat. Si vous souhaitez maximiser l'amélioration, vous pouvez effectuer plusieurs itérations.
Les chercheurs ont proposé une méthode simple pour améliorer les résultats du modèle en revenant sur l'emplacement des erreurs logiques
Par rapport à la méthode d'autocorrection précédente, cette méthode de backtracking présente de nombreux avantages :
Les chercheurs ont utilisé l'ensemble de données BIG-Bench Mistake pour mener des expériences afin de déterminer si la méthode de retour en arrière peut aider LLM à corriger les erreurs logiques. Veuillez consulter le tableau 6 pour les résultats expérimentaux.
Pour les résultats de trajectoires de réponses incorrectes, la précision doit être recalculée 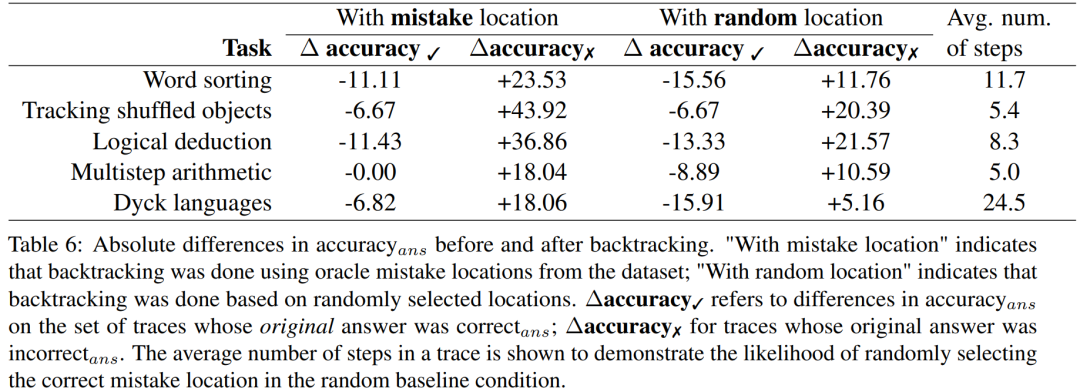
Ces résultats de score montrent que le gain de la correction des trajectoires de réponses incorrectes est supérieur à la perte causée par la modification de la bonne réponse d'origine. De plus, bien que les tests de référence aléatoires s’améliorent également, leurs gains sont nettement inférieurs à ceux obtenus avec l’utilisation de véritables emplacements d’erreur. Notez que dans les tests randomisés, les gains de performances sont plus susceptibles de se produire sur des tâches impliquant moins d'étapes, car il est plus probable de trouver l'emplacement de la véritable erreur.
Pour explorer quel modèle de récompense de niveau de précision est nécessaire lorsque de bonnes étiquettes ne sont pas disponibles, ils ont expérimenté l'utilisation du retour en arrière via un modèle de récompense simulé ; l'objectif de conception de ce modèle de récompense simulé est de produire des étiquettes de différents niveaux de précision. Ils utilisent l'exactitude_RM pour représenter la précision du modèle de récompense de simulation à un emplacement d'erreur spécifié.
Lorsque la précision_RM d'un modèle de récompense donné est de X%, utilisez le mauvais emplacement de BIG-Bench Erreur X% du temps. Pour les (100 − X) % restants, un emplacement d'erreur est échantillonné de manière aléatoire. Pour simuler le comportement d'un classificateur typique, les emplacements des erreurs sont échantillonnés de manière à correspondre à la distribution de l'ensemble de données. Les chercheurs ont également trouvé des moyens de garantir que le mauvais emplacement de l’échantillon ne correspondait pas au bon emplacement. Les résultats sont présentés dans la figure 2.
On peut observer que lorsque le taux de perte atteint 65%, la précision Δ commence à se stabiliser. En fait, pour la plupart des tâches, la Δprécision ✓ dépasse déjà la Δprécision ✗ lorsque la précision_RM est d'environ 60 à 70 %. Cela montre que même si une plus grande précision conduit à de meilleurs résultats, le retour en arrière fonctionne toujours même sans étiquettes de localisation d'erreur de référence
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



