


Récemment, la vitesse à laquelle les nouveaux articles sont publiés est si rapide que j'ai l'impression de ne pas pouvoir les lire. On peut voir que la fusion de grands modèles multimodaux pour le langage et la vision est devenue un consensus dans l'industrie. Cet article sur UniPad est plus représentatif, avec une entrée multimodale et un modèle de base pré-entraîné de modèles de type mondial. étant facile à étendre à plusieurs applications de vision traditionnelles. Cela résout également le problème de l'application de la méthode de pré-entraînement des grands modèles de langage aux scènes 3D, offrant ainsi la possibilité d'un grand modèle unifié de base perceptuelle.
UniPAD est une méthode d'apprentissage auto-supervisée basée sur le MAE et le rendu 3D. Elle peut entraîner un modèle de base avec d'excellentes performances, puis affiner et entraîner des tâches en aval sur le modèle, telles que l'estimation de la profondeur, la détection d'objets et la segmentation. Cette étude a conçu une méthode de représentation spatiale 3D unifiée qui peut être facilement intégrée dans des cadres 2D et 3D, montrant une plus grande flexibilité et cohérente avec le positionnement du modèle de base
Quelle est la relation entre technologie d'encodage automatique masqué et technologie de rendu différenciable 3D ? Pour faire simple : l'auto-encodage masqué consiste à tirer parti des capacités de formation auto-supervisées d'Autoencoder, et la technologie de rendu consiste à calculer la fonction de perte entre l'image générée et l'image d'origine et à effectuer une formation supervisée. La logique reste donc très claire.
Cet article utilise la méthode de pré-formation du modèle de base, puis affine la méthode de détection en aval et la méthode de segmentation. Cette méthode peut également aider à comprendre comment le grand modèle actuel fonctionne avec les tâches en aval.
Il semble que les informations de timing ne soient pas combinées. Après tout, NuScenes NDS de Pure Vision 50.2 est actuellement encore plus faible par rapport aux méthodes de détection de synchronisation (StreamPETR, Sparse4D, etc.). Par conséquent, la méthode 4D MAE vaut également la peine d’être essayée. En fait, GAIA-1 a déjà mentionné une idée similaire.
Qu'en est-il du montant du calcul et de l'utilisation de la mémoire ?
UniPAD encode implicitement les informations spatiales 3D. Ceci s'inspire principalement de l'auto-encodage de masque (MAE, VoxelMAE, etc.). Cet article utilise un masque génératif pour compléter l'amélioration des fonctionnalités de voxel, utilisé. pour reconstruire les structures de forme 3D continues dans la scène et leurs caractéristiques d'apparence complexes sur le plan 2D.
Nos résultats expérimentaux prouvent pleinement la supériorité de l'UniPAD. Par rapport aux lignes de base traditionnelles de fusion lidar, caméra et lidar-caméra, le NDS d'UniPAD s'améliore respectivement de 9,1, 7,7 et 6,9. Notamment, sur l'ensemble de validation nuScenes, notre pipeline de pré-formation a obtenu un NDS de 73,2 tout en atteignant un score mIoU de 79,4 sur la tâche de segmentation sémantique 3D, obtenant ainsi les meilleurs résultats par rapport aux méthodes précédentes
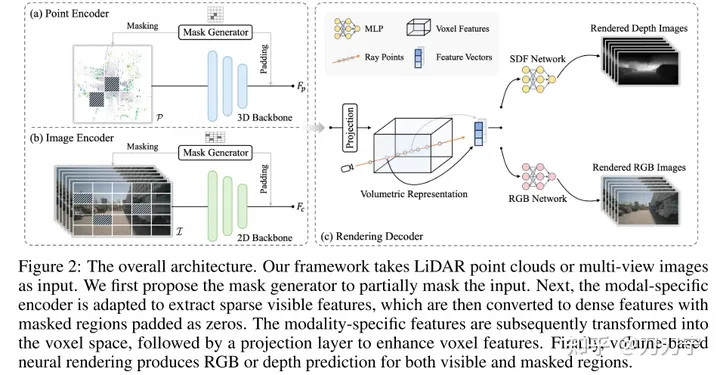
Architecture globale. Le framework prend en entrée des images LiDar et multi-prises, et ces données multimodales sont remplies de zéros via le générateur de masques. L'intégration masquée est convertie en espace voxel et des techniques de rendu sont utilisées pour générer des prédictions RVB ou de profondeur dans cet espace 3D. À ce stade, l'image originale qui n'est pas masquée par le masque peut être utilisée comme données générées pour l'apprentissage supervisé.
Le masque dans Masked AutoEncoder est généré par Mask Generator. Cela peut être compris comme l'amélioration de la capacité de représentation et de généralisation du modèle en augmentant la difficulté de la formation. Un générateur de masques est introduit pour différencier les données de nuages de points des données d'image en occultant sélectivement certaines zones. Dans les données de nuages de points, la stratégie de masquage de blocs est adoptée ; pour les données d'image, la méthode de convolution clairsemée est utilisée et les calculs sont effectués uniquement dans la zone visible. Lorsque les données d'entrée sont masquées, les caractéristiques de codage suivantes seront définies sur 0 dans la zone masquée correspondante et ignorées dans le traitement du modèle. Cela fournit également un apprentissage supervisé ultérieur avec des informations qui peuvent être utilisées pour prédire la cible et les informations Groundtruth correspondantes
.Afin de rendre la méthode de pré-formation applicable à diverses modalités de données, il est important de trouver une représentation unifiée. Les méthodes antérieures telles que BEV et OCC recherchent une forme d'identification unifiée. La projection de points 3D dans le plan de l'image entraînera une perte d'informations sur la profondeur, et leur fusion dans la vue à vol d'oiseau du BEV manquera de détails liés à la hauteur. Par conséquent, cet article propose de convertir les deux modalités en un espace de volume 3D, qui est un espace de voxel 3D similaire à l'OCC
La technologie de rendu différenciable devrait être le plus grand point fort de l'article de l'avis de l'auteur. article passé Les rayons d'échantillonnage similaires au NERF traversent des images multi-vues ou des nuages de points, prédisent la couleur ou la profondeur de chaque point 3D à travers la structure du réseau neuronal et obtiennent enfin la cartographie 2D à travers le chemin parcouru par le rayon. Cela permet de mieux utiliser les indices géométriques ou de texture dans les images et d'améliorer la capacité d'apprentissage et la gamme d'applications du modèle.
Nous représentons la scène comme SDF (champ de fonction de distance signé implicite), lorsque l'entrée est les coordonnées 3D du point d'échantillonnage P (la profondeur correspondante le long du rayon D) et F (l'intégration des caractéristiques peut être extraite de la représentation volumétrique par interpolation trilinéaire), SDF peut être considéré comme un MLP pour prédire la valeur SDF du point d'échantillonnage. Ici, F peut être compris comme le code de codage où se trouve le point P. Ensuite, le résultat est obtenu : N (conditionner le champ de couleur sur la normale de la surface) et H (vecteur de caractéristiques géométriques). À ce moment, le RVB du point d'échantillonnage 3D peut être obtenu via un MLP avec P, D, F, N). , H comme valeur d'entrée et valeur de profondeur, puis superposez les points d'échantillonnage 3D à l'espace 2D à travers des rayons pour obtenir le résultat du rendu. La méthode d'utilisation de Ray ici est fondamentalement la même que celle de Nerf.
La méthode de rendu doit également optimiser la consommation de mémoire, ce qui n'est pas répertorié ici. Cependant, cette question est une question de mise en œuvre plus critique. L'essence des méthodes de masque et de rendu est d'entraîner un modèle pré-entraîné. Le modèle pré-entraîné peut être entraîné en fonction du masque prédit, même sans branches ultérieures. Le travail ultérieur du modèle pré-entraîné génère des prédictions RVB et de profondeur à travers différentes branches, et affine les tâches telles que la détection de cible/la segmentation sémantique pour obtenir des capacités plug-and-play.
Fonction de perte :
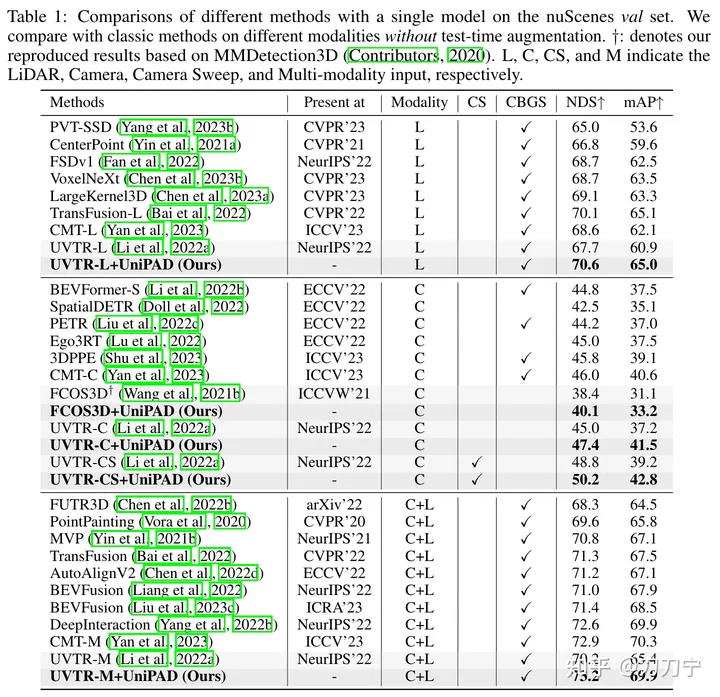
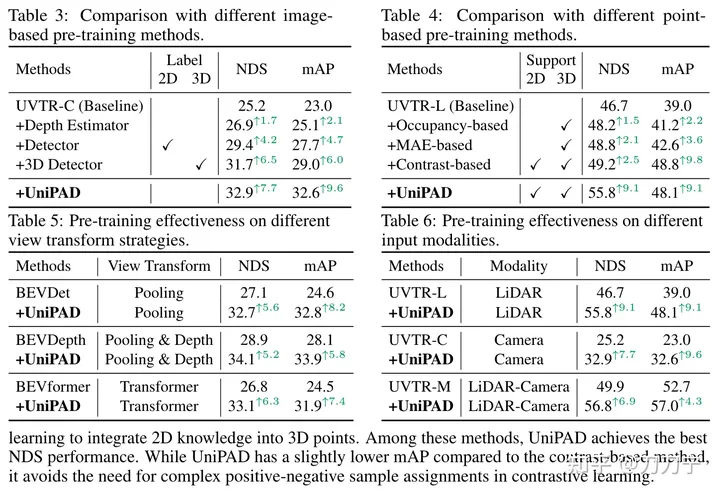
De plus, UniPAD peut être considéré comme une tentative de construction d'un grand modèle multimodal, ou comme un modèle mondial. Bien que l’article n’y insiste pas beaucoup.
Résumé :Cette méthode a non seulement du potentiel dans le domaine 3D, mais peut également être étendue au domaine du timing 4D, et peut également générer beaucoup de nouveaux travaux en termes d'optimisation de sa mémoire et de son volume de calcul, offrant de nouvelles idées et possibilités pour l'avenir. recherche.
 Lien original : https://mp.weixin.qq.com/s/e_reCS-Lwr-KVF80z56_ow
Lien original : https://mp.weixin.qq.com/s/e_reCS-Lwr-KVF80z56_ow
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Introduction aux caractéristiques de l'espace virtuel
Introduction aux caractéristiques de l'espace virtuel
 Utilisation de la valeur de retour Python
Utilisation de la valeur de retour Python
 Comment utiliser la monnaie numérique
Comment utiliser la monnaie numérique
 Que dois-je faire si des lettres anglaises apparaissent lorsque l'ordinateur est allumé et que l'ordinateur ne peut pas être allumé ?
Que dois-je faire si des lettres anglaises apparaissent lorsque l'ordinateur est allumé et que l'ordinateur ne peut pas être allumé ?
 La différence entre vue2.0 et 3.0
La différence entre vue2.0 et 3.0
 Comment changer de ville sur Douyin
Comment changer de ville sur Douyin
 pas de solution de fichier de ce type
pas de solution de fichier de ce type
 Comment configurer la passerelle par défaut
Comment configurer la passerelle par défaut








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



