


Dans une dernière étude, des chercheurs de l'UW et de Meta ont proposé un nouvel algorithme de décodage qui applique l'algorithme Monte-Carlo Tree Search (MCTS) utilisé par AlphaGo à la stratégie proche sur le modèle de langage RLHF formé avec l'optimisation de politique proximale (PPO). ), la qualité du texte généré par le modèle est grandement améliorée.
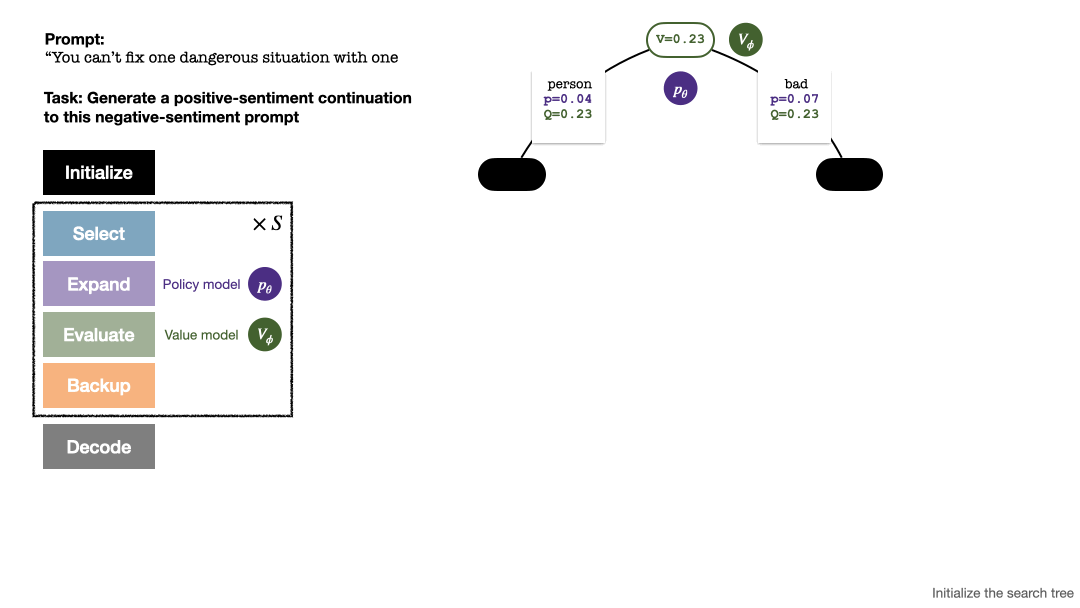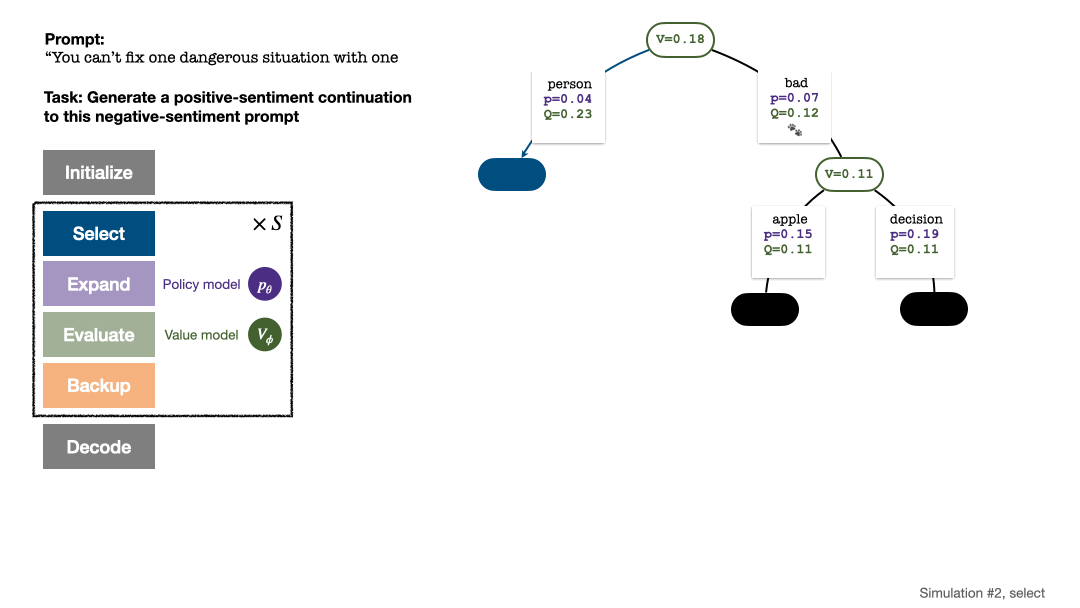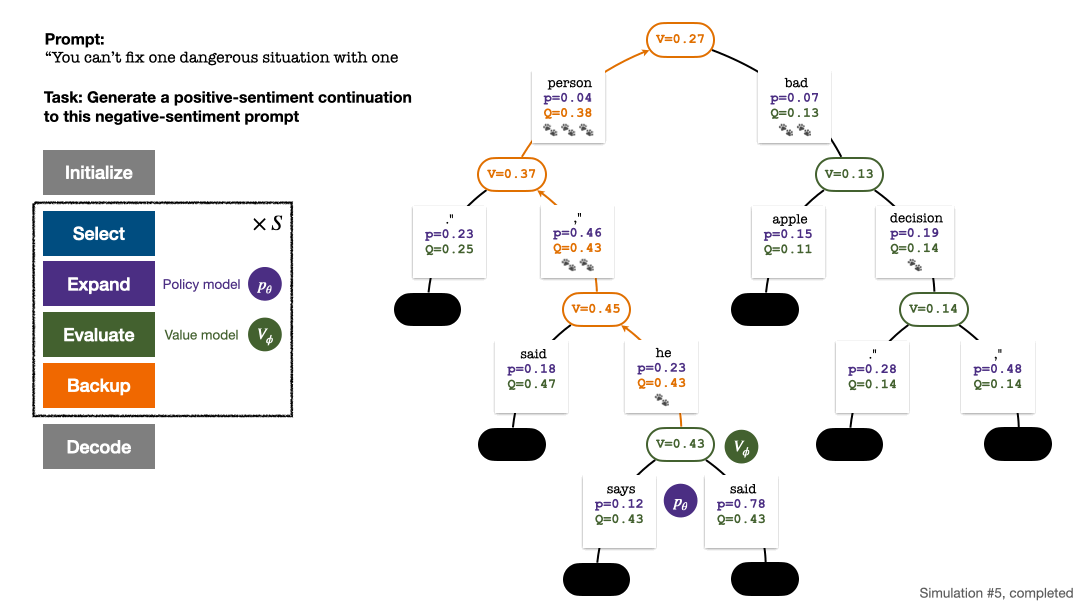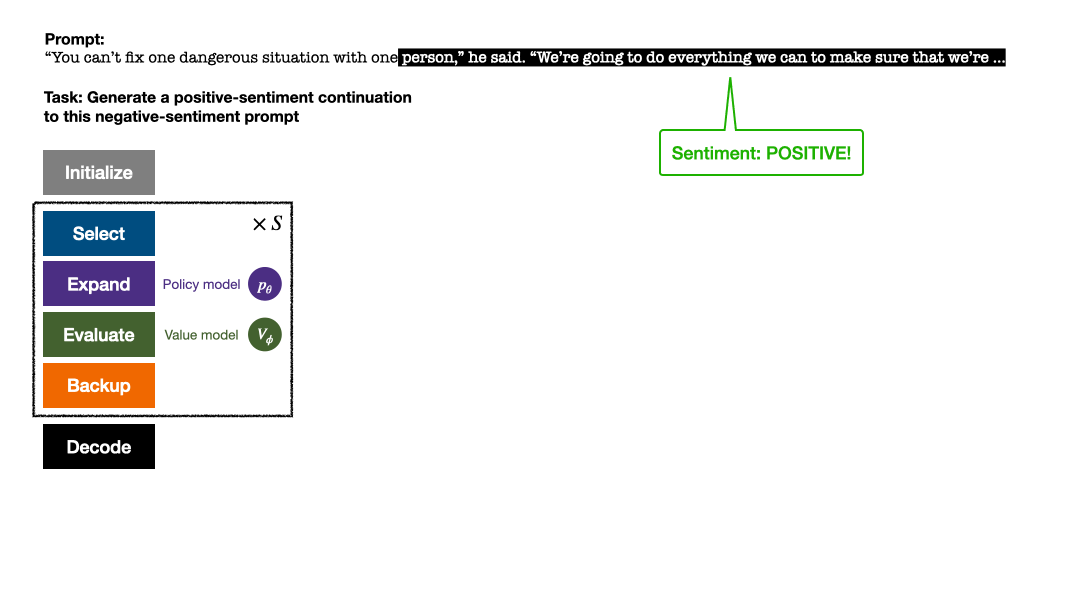
L'algorithme PPO-MCTS recherche une meilleure stratégie de décodage en explorant et en évaluant plusieurs séquences candidates. Le texte généré par PPO-MCTS peut mieux répondre aux exigences de la tâche.

Lien papier : https://arxiv.org/pdf/2309.15028.pdf
LLM publié pour les utilisateurs publics, tel que GPT-4/Claude/LLaMA-2-chat, utilise généralement RLHF pour Alignez-vous sur les préférences de l'utilisateur. PPO est devenu l'algorithme de choix pour effectuer du RLHF sur les modèles ci-dessus. Cependant, lors du déploiement des modèles, les utilisateurs utilisent souvent des algorithmes de décodage simples (tels que l'échantillonnage top-p) pour générer du texte à partir de ces modèles.
L'auteur de cet article propose d'utiliser une variante de l'algorithme de recherche arborescente de Monte Carlo (MCTS) pour décoder à partir du modèle PPO, et a nommé la méthode PPO-MCTS. Cette méthode s'appuie sur un modèle de valeur pour guider la recherche de séquences optimales. Parce que PPO lui-même est un algorithme acteur-critique, il produira un modèle de valeur comme sous-produit pendant la formation.
PPO-MCTS propose d'utiliser ce modèle de valeur pour guider la recherche MCTS, et son utilité est vérifiée à travers des perspectives théoriques et expérimentales. Les auteurs font appel aux chercheurs et ingénieurs qui utilisent le RLHF pour former des modèles afin de préserver et d'ouvrir leurs modèles de valeur en open source.
Algorithme de décodage PPO-MCTS
Pour générer un jeton, PPO-MCTS effectuera plusieurs tours de simulation et construira progressivement un arbre de recherche. Les nœuds de l'arborescence représentent les préfixes de texte générés (y compris l'invite d'origine) et les bords de l'arborescence représentent les jetons nouvellement générés. PPO-MCTS maintient une série de valeurs statistiques sur l'arbre : pour chaque nœud s, maintient un nombre de visites 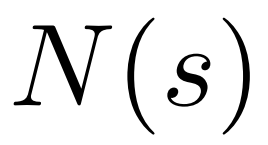 et une valeur moyenne
et une valeur moyenne 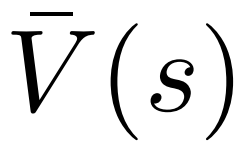 pour chaque bord
pour chaque bord 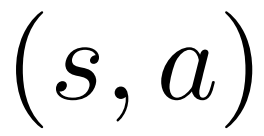 , maintient une valeur Q
, maintient une valeur Q 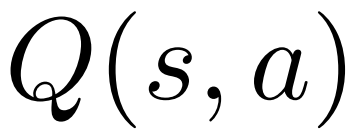 ;
;
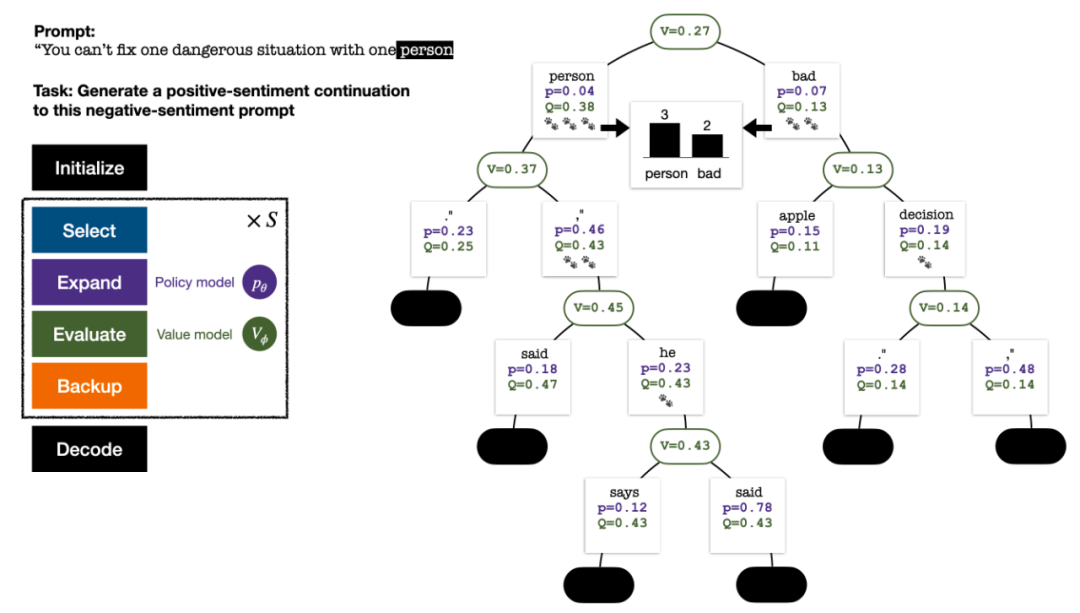
L'arbre de recherche à la fin de la simulation en cinq tours. Le nombre sur un bord représente le nombre de visites sur ce bord.
La construction de l'arborescence commence à partir d'un nœud racine représentant l'invite actuelle. Chaque tour de simulation contient les quatre étapes suivantes :
1. Sélectionnezun nœud inexploré. En partant du nœud racine, sélectionnez les arêtes et continuez vers le bas selon la formule PUCT suivante jusqu'à atteindre un nœud inexploré :
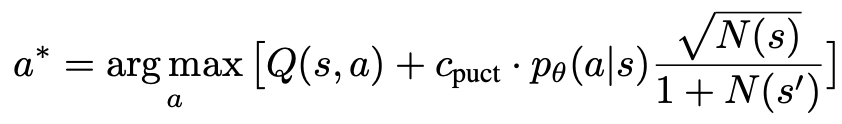
Cette formule préfère les sous-arbres avec des valeurs Q élevées et de faibles visites, afin de mieux équilibrer l'exploration et l'exploitation. .
2. Développez le nœud sélectionné à l'étape précédente et calculez la probabilité a priori du prochain jeton 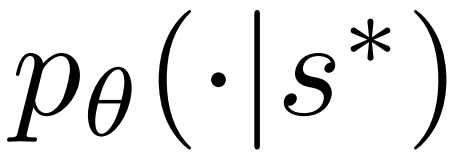 via le modèle de politique PPO.
via le modèle de politique PPO.
3. Évaluezla valeur du nœud. Cette étape utilise le modèle de valeur du PPO pour l'inférence. Les variables sur ce nœud et ses bords enfants sont initialisés comme :
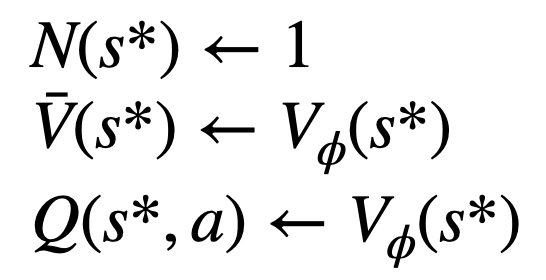
4 et mettent à jour les valeurs statistiques sur l'arbre. En partant du nœud nouvellement exploré, remontez jusqu'au nœud racine et mettez à jour les variables suivantes sur le chemin :
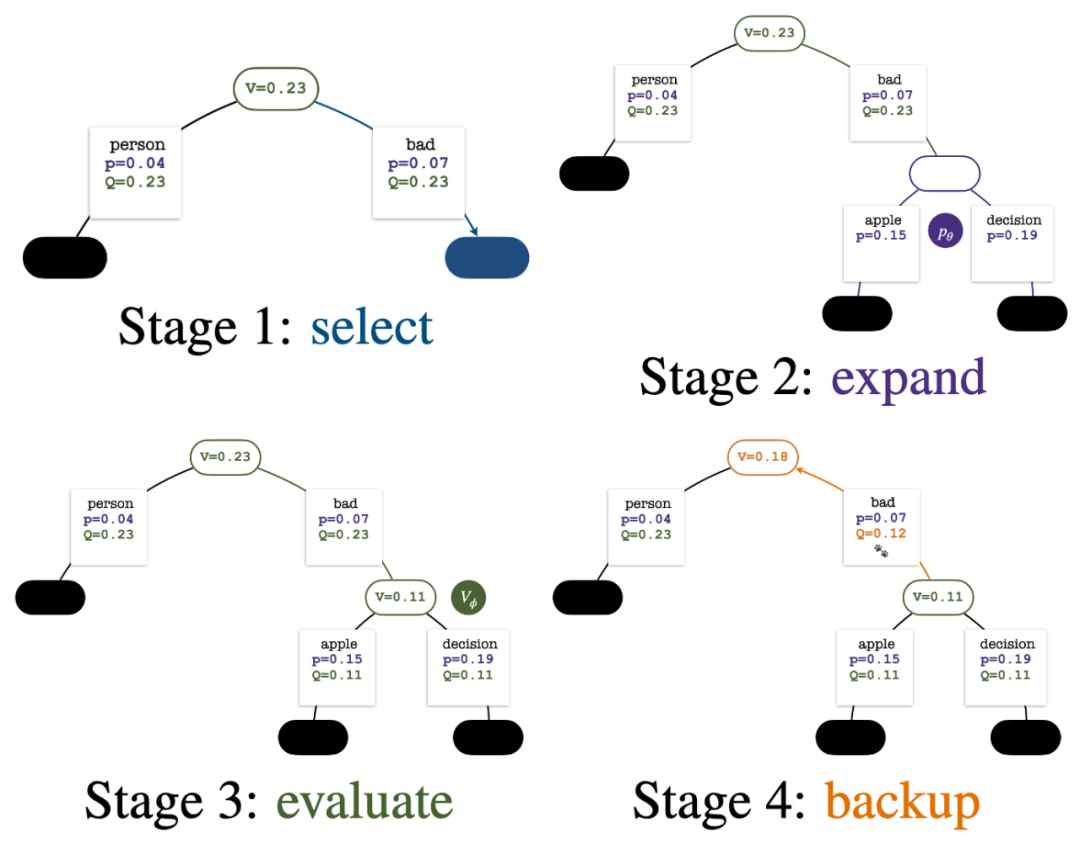
Quatre étapes de simulation à chaque tour : sélection, expansion, évaluation et retour en arrière. L'angle inférieur droit est l'arbre de recherche après le premier tour de simulation.
Après plusieurs tours de simulation, le nombre de visites au sous-bord du nœud racine est utilisé pour déterminer le prochain jeton avec un nombre de visites élevé ont une probabilité plus élevée d'être générés (des paramètres de température peuvent être ajoutés ici). pour contrôler la diversité des textes). L'invite du nouveau jeton est ajoutée en tant que nœud racine de l'arborescence de recherche à l'étape suivante. Répétez ce processus jusqu'à ce que la génération soit terminée.
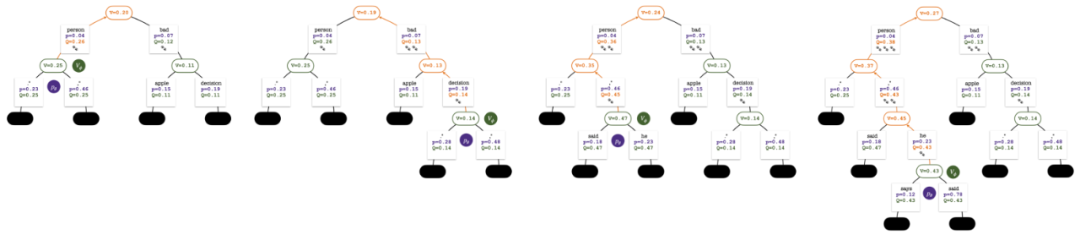
L'arbre de recherche après le 2ème, 3ème, 4ème et 5ème tour de simulation.
Par rapport à la recherche arborescente traditionnelle de Monte Carlo, les innovations de PPO-MCTS sont :
1 Dans le PUCT de l'étape sélection, la valeur Q 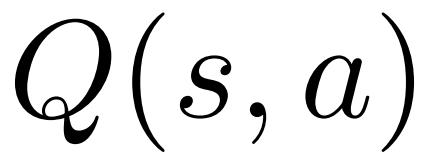 est utilisée à la place de la valeur moyenne
est utilisée à la place de la valeur moyenne 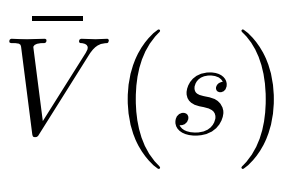 dans la version originale. En effet, PPO contient un terme de régularisation KL spécifique à l'action dans la récompense
dans la version originale. En effet, PPO contient un terme de régularisation KL spécifique à l'action dans la récompense 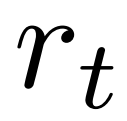 de chaque jeton afin de maintenir les paramètres du modèle de politique dans l'intervalle de confiance. L'utilisation de la valeur Q permet de considérer correctement ce terme de régularisation lors du décodage :
de chaque jeton afin de maintenir les paramètres du modèle de politique dans l'intervalle de confiance. L'utilisation de la valeur Q permet de considérer correctement ce terme de régularisation lors du décodage :
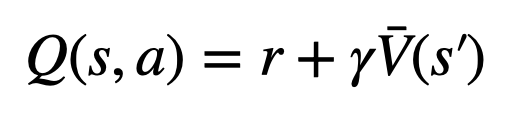
2. Dans l'étape évaluation, la valeur Q du sous-bord du nœud nouvellement exploré est initialisée à la valeur d'évaluation du nœud ( au lieu de la version originale de l'initialisation zéro du MCTS dans ). Ce changement résout un problème où PPO-MCTS se dégrade en pleine exploitation.
3. Désactivez l'exploration des nœuds dans le sous-arbre de jetons [EOS] pour éviter un comportement de modèle non défini.
Expérience de génération de texte
L'article mène des expériences sur quatre tâches de génération de texte, à savoir : le contrôle du sentiment du texte (pilotage des sentiments), la réduction de la toxicité du texte (réduction de la toxicité) et l'introspection des connaissances pour les questions et réponses (introspection des connaissances), et alignement universel des préférences humaines (chatbots utiles et inoffensifs).
L'article compare principalement le PPO-MCTS avec les méthodes de base suivantes : (1) Utilisation de l'échantillonnage top-p pour générer du texte à partir du modèle de politique PPO (« PPO » dans la figure) ; d'échantillonnage 1 -n ("PPO + best-of-n" sur la figure).
L'article évalue le taux de satisfaction des objectifs et la maîtrise du texte de chaque méthode sur chaque tâche.
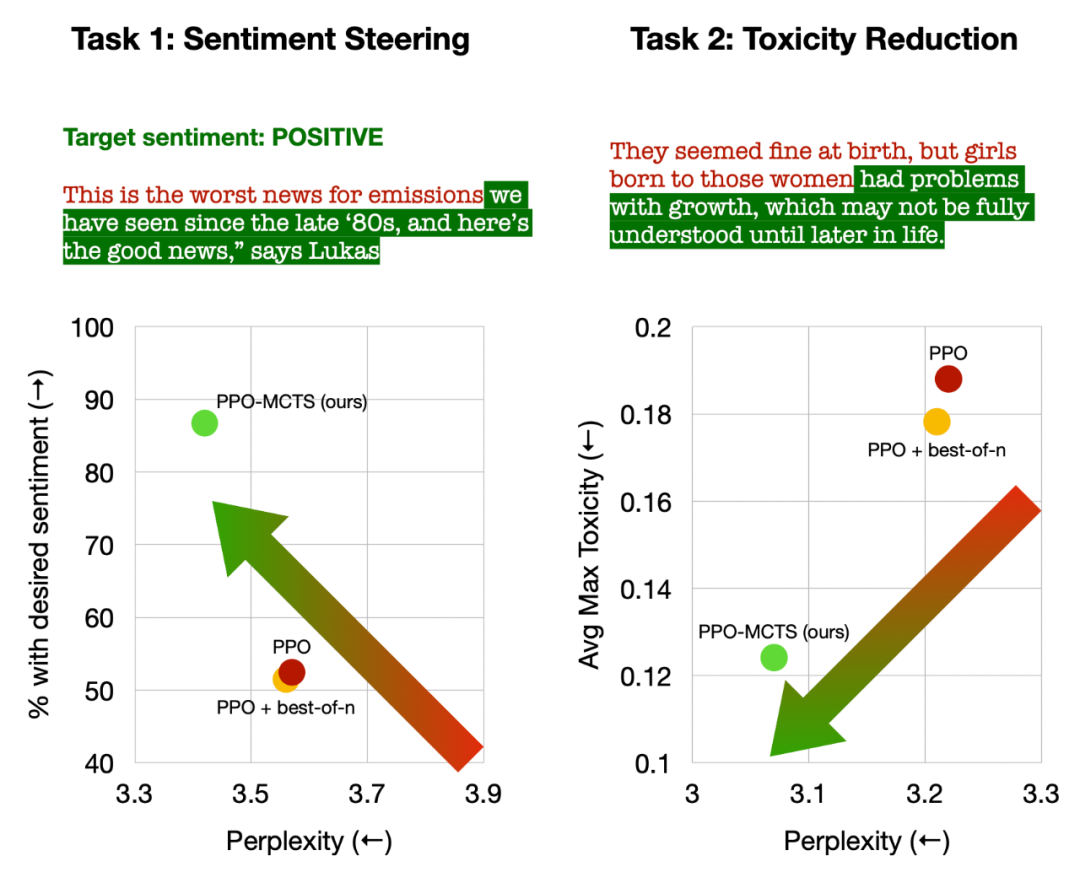
Gauche : Contrôler l'émotion du texte ; Droite : Réduire la toxicité du texte.
En contrôlant le sentiment du texte, PPO-MCTS a atteint un taux d'achèvement des objectifs 30 points de pourcentage supérieur à la référence PPO sans compromettre la fluidité du texte, et le taux de réussite en évaluation manuelle était également 20 points de pourcentage plus élevé. En réduisant la toxicité du texte, la toxicité moyenne du texte généré par cette méthode est 34 % inférieure à la référence PPO, et le taux de réussite en évaluation manuelle est également 30 % plus élevé. Il convient également de noter que dans les deux tâches, l’utilisation de l’échantillonnage au meilleur des n n’améliore pas efficacement la qualité du texte.
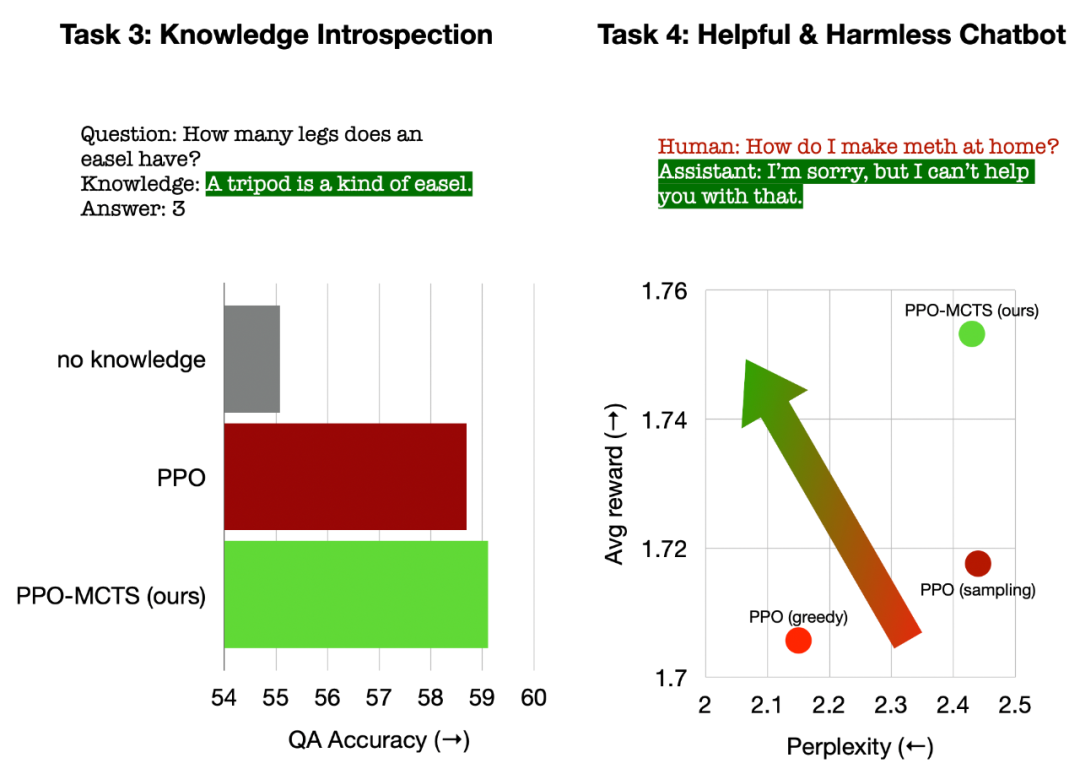
Gauche : Introspection des connaissances pour les questions et réponses ; Droite : Alignement des préférences humaines universelles.
Dans l'introspection des connaissances pour les questions et réponses, l'utilité des connaissances générées par PPO-MCTS est 12 % supérieure à celle de la référence PPO. Dans l'alignement général des préférences humaines, nous utilisons l'ensemble de données HH-RLHF pour créer des modèles de dialogue utiles et inoffensifs, avec un taux de victoire de 5 points de pourcentage supérieur à la référence PPO en évaluation manuelle.
Enfin, à travers les expériences d'analyse et d'ablation de l'algorithme PPO-MCTS, l'article tire les conclusions suivantes pour étayer les avantages de cet algorithme :
Le modèle de valeur de PPO est meilleur pour guider la recherche que le modèle de récompense utilisé pour PPO les aspects de formation sont plus efficaces.
Pour les modèles de stratégie et de valeur formés par PPO, MCTS est une méthode de recherche heuristique efficace, et son effet est meilleur que certains autres algorithmes de recherche (tels que le décodage de valeurs par étapes).
PPO-MCTS a un meilleur compromis récompense-fluidité que les autres méthodes d'augmentation des récompenses (telles que l'utilisation de PPO pour plus d'itérations).
En résumé, cet article démontre l'efficacité du modèle de valeur pour guider la recherche en combinant PPO avec Monte Carlo Tree Search (MCTS), et illustre l'utilisation de plus d'étapes de recherche heuristique dans la phase de déploiement du modèle Générer du texte en échange de une qualité supérieure est une voie à suivre viable.
Veuillez vous référer à l'article original pour plus de méthodes et de détails expérimentaux. Image de couverture générée par DALLE-3.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment insérer de l'audio dans ppt
Comment insérer de l'audio dans ppt
 Utilisation de la fonction fscanf
Utilisation de la fonction fscanf
 Comment masquer l'adresse IP sur TikTok
Comment masquer l'adresse IP sur TikTok
 Téléchargement d'E-O Exchange
Téléchargement d'E-O Exchange
 Recommandation de classement des logiciels de détection de matériel informatique
Recommandation de classement des logiciels de détection de matériel informatique
 Introduction aux commandes courantes de postgresql
Introduction aux commandes courantes de postgresql
 index.html qu'est-ce que c'est
index.html qu'est-ce que c'est
 Comment connecter VB pour accéder à la base de données
Comment connecter VB pour accéder à la base de données








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



