


Le contenu généré par l'IA est devenu l'un des sujets les plus brûlants dans le domaine actuel de l'intelligence artificielle et représente la technologie de pointe dans ce domaine. Ces dernières années, avec la sortie de nouvelles technologies telles que Stable Diffusion, DALL-E3 et ControlNet, le domaine de la génération et de l'édition d'images IA a permis d'obtenir des effets visuels époustouflants et a suscité une large attention et de nombreuses discussions dans le monde universitaire et industriel. La plupart de ces méthodes sont basées sur des modèles de diffusion, ce qui est la clé de leur capacité à obtenir une génération contrôlable puissante, une génération photoréaliste et une diversité.
Cependant, par rapport aux simples images statiques, les vidéos contiennent des informations sémantiques plus riches et des changements dynamiques. La vidéo peut montrer l’évolution dynamique des objets physiques, de sorte que les besoins et les défis dans le domaine de la génération et du montage vidéo sont plus complexes. Bien que dans ce domaine, la recherche sur la génération vidéo ait été confrontée à des difficultés en raison des limitations des données annotées et des ressources informatiques, certains travaux de recherche représentatifs, tels que les méthodes Make-A-Video, Imagen Video et Gen-2, ont déjà commencé progressivement. sur la position dominante.
Ces travaux de recherche orientent le développement de la technologie de génération et de montage vidéo. Les données de recherche montrent que depuis 2022, les travaux de recherche sur les modèles de diffusion sur les tâches vidéo ont connu une croissance explosive. Cette tendance reflète non seulement la popularité des modèles de diffusion vidéo dans le monde universitaire et industriel, mais souligne également le besoin urgent pour les chercheurs dans ce domaine de continuer à faire des percées et des innovations dans la technologie de génération vidéo.
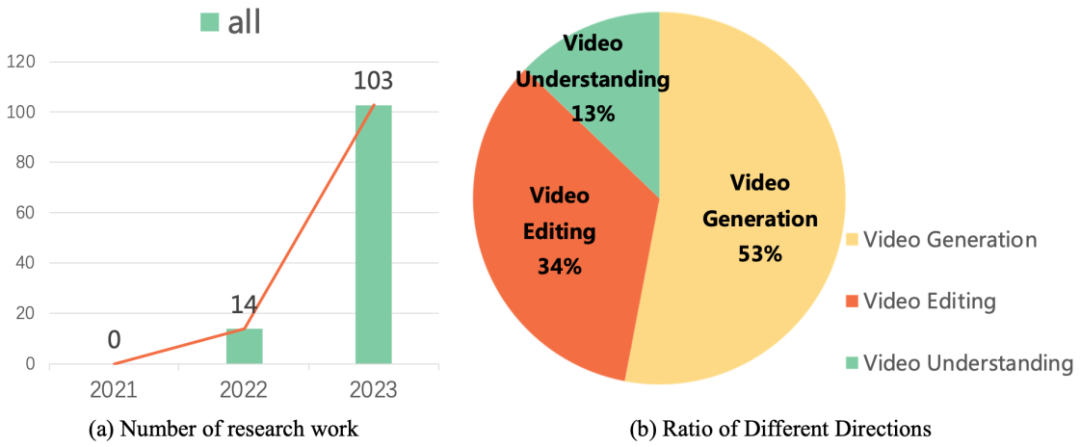
Récemment, le Laboratoire de Vision et d'Apprentissage de l'Université de Fudan, en collaboration avec Microsoft, Huawei et d'autres institutions académiques, a publié la première revue du travail des modèles de diffusion sur les tâches vidéo, triant systématiquement l'application de modèles de diffusion en génération vidéo, vidéo Résultats académiques de pointe en matière de montage et de compréhension vidéo.

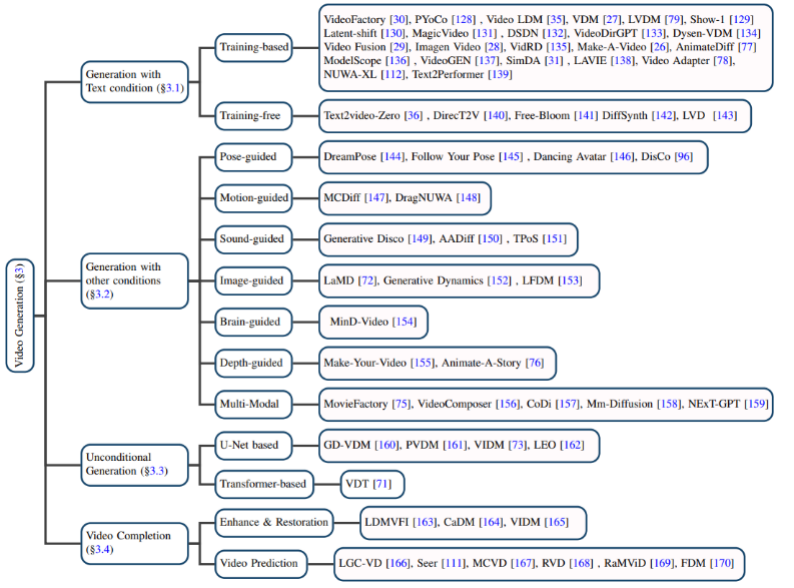
Génération vidéo basée sur du texte : La génération vidéo avec le langage naturel comme entrée est l'une des tâches les plus importantes dans le domaine de la génération vidéo. L'auteur passe d'abord en revue les résultats de la recherche dans ce domaine avant que le modèle de diffusion ne soit proposé, puis présente respectivement des modèles de génération texte-vidéo basés sur la formation et sans formation.

Animation de neige d'hiver pour la célébration des vacances de l'arbre de Noël.
Génération vidéo basée sur d'autres conditions : La génération vidéo fonctionne dans des domaines de niche. L'auteur les classe en fonction des conditions suivantes : pose (pose guidée), action (guidée par le mouvement), son (guidée par le son), image (guidée par l'image), carte de profondeur (guidée en profondeur), etc.


Génération vidéo inconditionnelle : Cette tâche fait référence à la génération vidéo sans conditions d'entrée dans un domaine spécifique. Selon l'architecture du modèle, l'auteur est principalement divisé en U-Net. modèle génératif basé sur et basé sur un transformateur.
Achèvement vidéo : Comprend principalement l'amélioration et la restauration vidéo, la prédiction vidéo et d'autres tâches.
Ensemble de données : Les ensembles de données utilisés dans la tâche de génération de vidéo peuvent être divisés en deux catégories suivantes :
1.Niveau de légende : chaque vidéo a des informations de description de texte correspondantes, et la dernière le plus représentatif est l’ensemble de données WebVid10M.
2.Niveau de catégorie : les vidéos n'ont que des étiquettes de classification, mais aucune information de description textuelle. L'UCF-101 est actuellement l'ensemble de données le plus couramment utilisé pour des tâches telles que la génération vidéo et la prédiction vidéo.
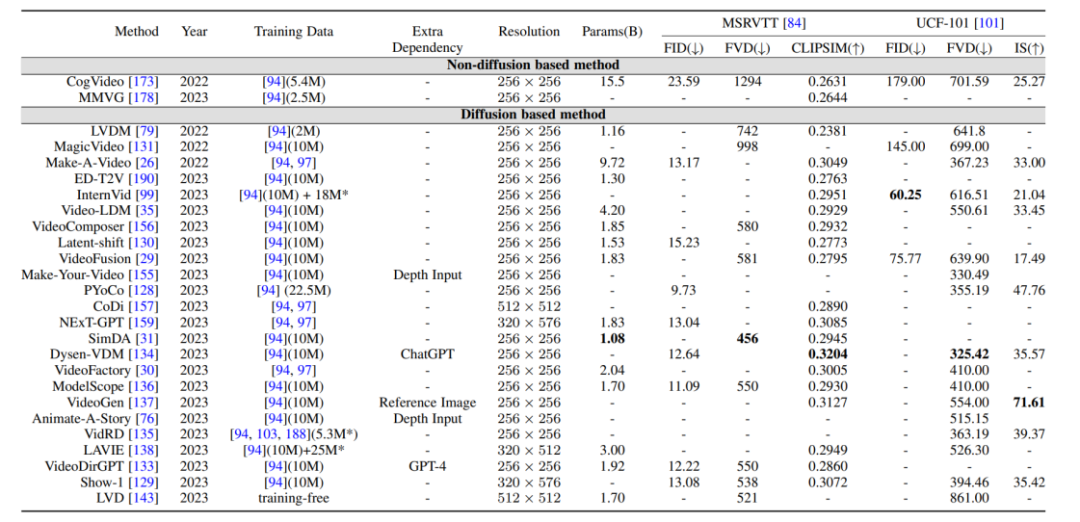
Comparaison des indicateurs d'évaluation et des résultats : Les indicateurs d'évaluation générés par la vidéo sont principalement divisés en indicateurs d'évaluation de niveau qualité et indicateurs d'évaluation de niveau quantitatif. Les indicateurs d'évaluation de niveau qualité sont principalement basés sur des indicateurs manuels subjectifs. notation, tandis que le quantitatif Les indicateurs d'évaluation au niveau de l'image peuvent être divisés en :
1 Indicateurs d'évaluation au niveau de l'image : La vidéo est composée d'une série de cadres d'image, donc la méthode d'évaluation au niveau de l'image fait essentiellement référence à la indicateurs d’évaluation du modèle T2I.
2. Indicateurs d'évaluation au niveau vidéo : par rapport aux indicateurs d'évaluation au niveau de l'image, qui sont davantage orientés vers la mesure image par image, les indicateurs d'évaluation au niveau vidéo peuvent mesurer des aspects tels que la cohérence temporelle de la vidéo générée.
De plus, l'auteur a également effectué une comparaison horizontale des indicateurs d'évaluation des modèles génératifs susmentionnés sur l'ensemble de données de référence.
En passant au peigne fin de nombreuses études, l'auteur a découvert que l'objectif principal de la tâche de montage vidéo est d'atteindre :
1. Les images vidéo éditées doivent être cohérentes dans leur contenu avec la vidéo originale.
2. Alignement : la vidéo éditée doit être alignée sur les conditions d'entrée.
3. Haute qualité : La vidéo montée doit être cohérente et de haute qualité.
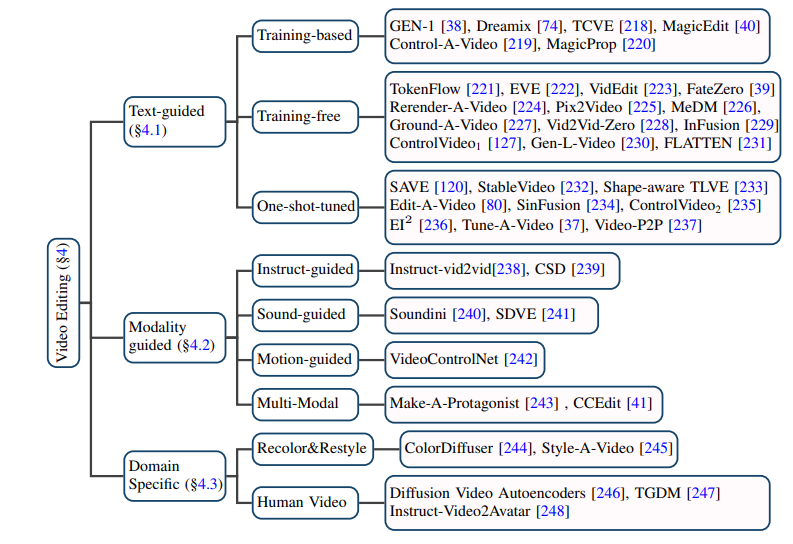
Montage vidéo basé sur texte : compte tenu de l'échelle limitée des données texte-vidéo existantes, la plupart des tâches de montage vidéo basées sur texte actuelles ont tendance à utiliser des modèles T2I pré-entraînés et à résoudre les images vidéo sur cette base, problèmes de cohérence et incohérence sémantique. L'auteur subdivise en outre ces tâches en méthodes basées sur la formation, sans formation et optimisées en une seule fois, et les résume respectivement.


Montage vidéo basé sur d'autres conditions : Avec l'avènement de l'ère des grands modèles, en plus des informations en langage naturel les plus directes comme le montage vidéo conditionnel, il est composé d'instructions, les sons, les actions, le montage vidéo multimode avec le statut et d'autres conditions comme condition reçoivent de plus en plus d'attention, et l'auteur a également classé et trié le travail correspondant.
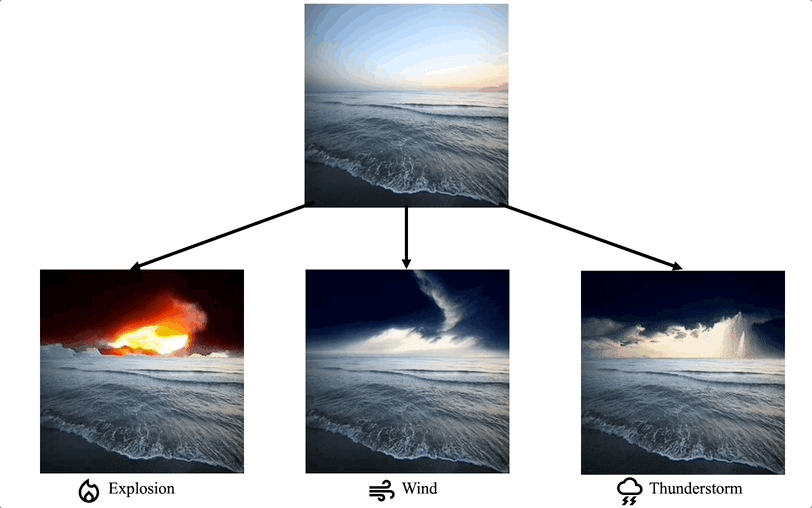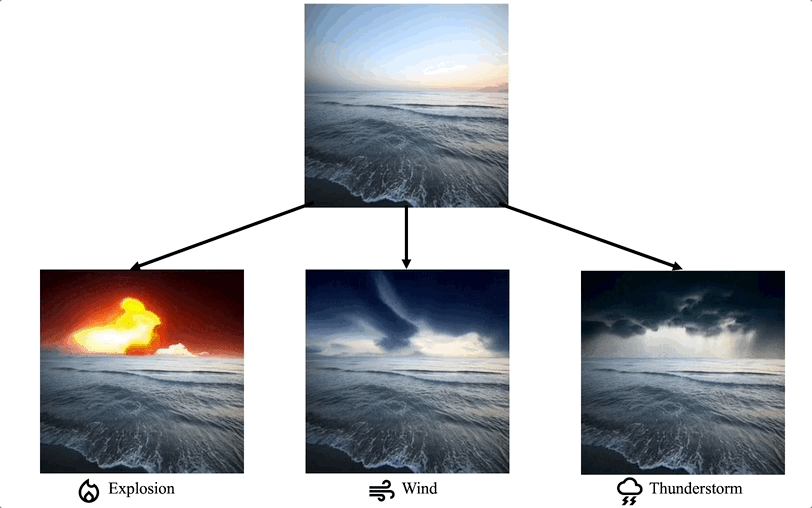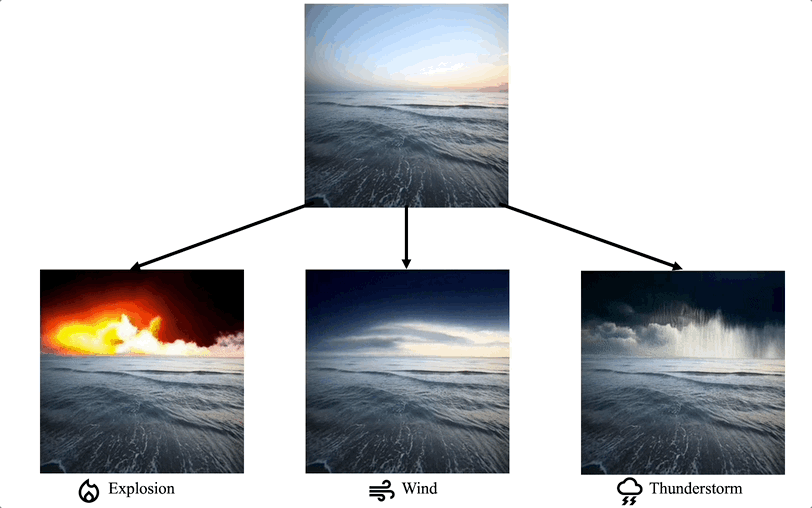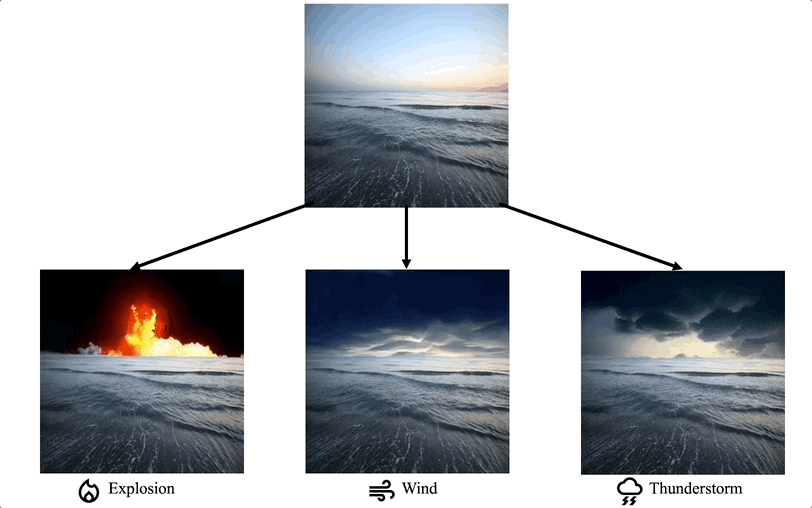
Montage vidéo dans des domaines de niche spécifiques : certains travaux se concentrent sur la nécessité d'une personnalisation particulière des tâches de montage vidéo dans des domaines spécifiques, tels que la coloration vidéo, le montage vidéo en portrait, etc.
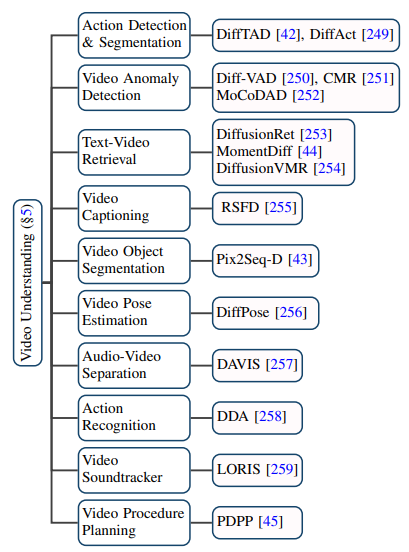
L'application du modèle de diffusion dans le domaine vidéo est allée bien au-delà des tâches traditionnelles de génération et d'édition de vidéo. Elle a également montré un grand potentiel dans les tâches de compréhension vidéo. En suivant des articles de pointe, l'auteur a résumé 10 scénarios d'application existants tels que la segmentation temporelle vidéo, la détection d'anomalies vidéo, la segmentation d'objets vidéo, la récupération de texte vidéo et la reconnaissance d'actions.
Cette revue résume de manière complète et méticuleuse les dernières recherches sur les tâches vidéo dans le modèle de diffusion de l'ère AIGC. Elle classe et résume plus d'une centaine de travaux de pointe basés sur des objets de recherche et des caractéristiques techniques. Ces modèles sont comparés sur certains benchmarks classiques. De plus, le modèle de diffusion présente également de nouvelles orientations de recherche et de nouveaux défis dans le domaine des tâches vidéo, tels que :
1 Collecte d'ensembles de données texte-vidéo à grande échelle : le succès du modèle T2I est indissociable de centaines. De même, le modèle T2V nécessite également une grande quantité de données texte-vidéo haute résolution sans filigrane comme support.
2. Formation et inférence efficaces : par rapport aux données d'image, les données vidéo sont énormes et la puissance de calcul requise dans les étapes de formation et d'inférence a également augmenté de façon exponentielle. Des algorithmes de formation et d'inférence efficaces peuvent réduire considérablement les coûts.
3. Repères et indicateurs d'évaluation fiables : Les indicateurs d'évaluation existants dans le domaine de la vidéo mesurent souvent la différence de distribution entre la vidéo générée et la vidéo originale, mais ne parviennent pas à mesurer pleinement la qualité de la vidéo générée. Dans le même temps, les tests utilisateurs restent l’une des méthodes d’évaluation importantes. Étant donné qu’ils nécessitent beaucoup de main d’œuvre et sont très subjectifs, il existe un besoin urgent d’indicateurs d’évaluation plus objectifs et plus complets.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 fonction utilisation de la fonction
fonction utilisation de la fonction
 Comment afficher les procédures stockées dans MySQL
Comment afficher les procédures stockées dans MySQL
 Comment vérifier les enregistrements d'appels supprimés
Comment vérifier les enregistrements d'appels supprimés
 La différence entre insérer avant et avant
La différence entre insérer avant et avant
 Quel langage est généralement utilisé pour écrire du vscode ?
Quel langage est généralement utilisé pour écrire du vscode ?
 Comment convertir nef au format jpg
Comment convertir nef au format jpg
 Classement des dix principaux échanges de devises numériques
Classement des dix principaux échanges de devises numériques
 Quel est le cœur d'un système de base de données ?
Quel est le cœur d'un système de base de données ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



