


Dans le domaine de la conduite autonome, avec le développement de sous-tâches/solutions de bout en bout basées sur BEV, des données d'entraînement multi-vues de haute qualité et la simulation correspondante la construction de scènes est de plus en plus importante. En réponse aux problèmes des tâches actuelles, la « haute qualité » peut être découplée en trois aspects :
Pour la simulation, la génération vidéo qui répond aux conditions ci-dessus peut être générée directement via la mise en page, ce qui est sans aucun doute le moyen le plus direct de construire une entrée de capteur multi-agents. DrivingDiffusion résout les problèmes ci-dessus sous un nouvel angle.
(1) DrivingDiffusion
montré dans l'image L'effet de génération d'images multi-vues en utilisant la projection de mise en page comme entrée est obtenu. 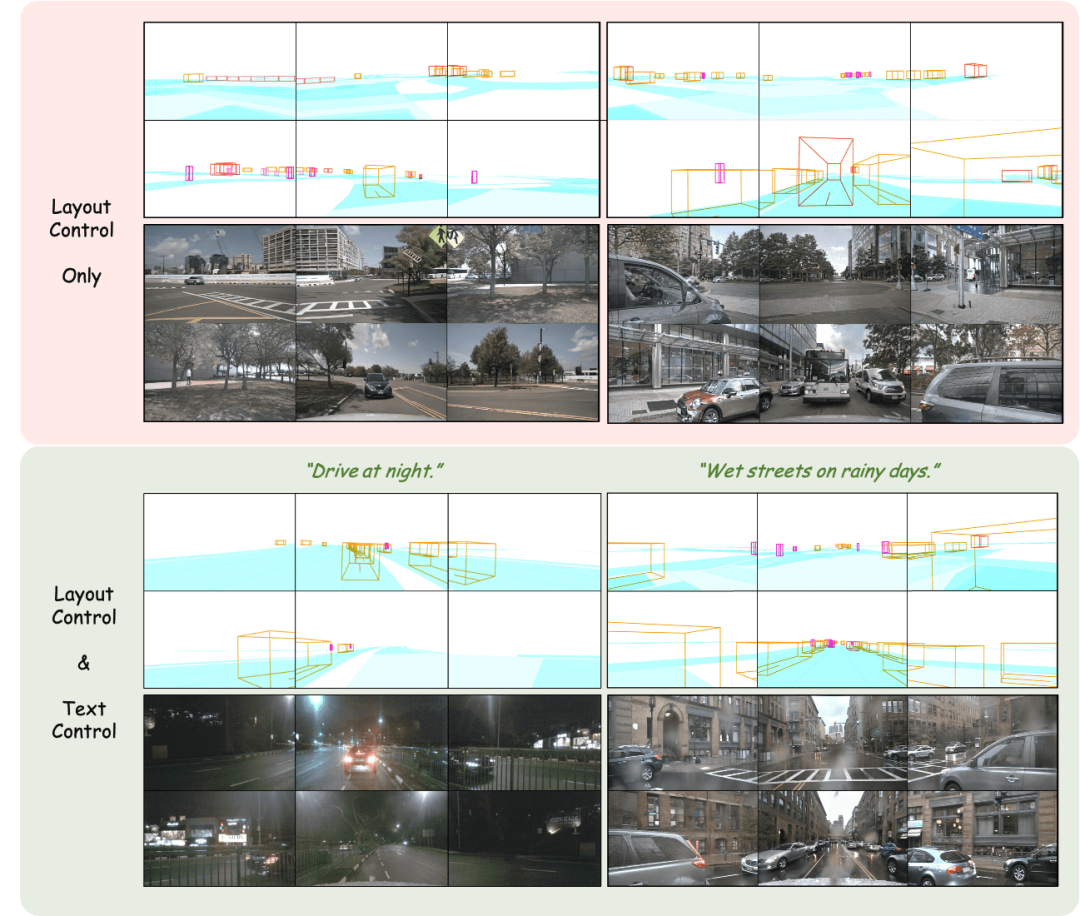
Ajuster la mise en page : contrôler avec précision les résultats générés
La partie supérieure de la figure montre la diversité des résultats générés et l'importance de la conception des modules ci-dessous. La partie inférieure montre les résultats de la perturbation du véhicule directement derrière, y compris les effets de génération de mouvements, de virages, de collisions et même de flottement dans les airs. 
Génération de vidéo multi-vues contrôlée par la mise en page
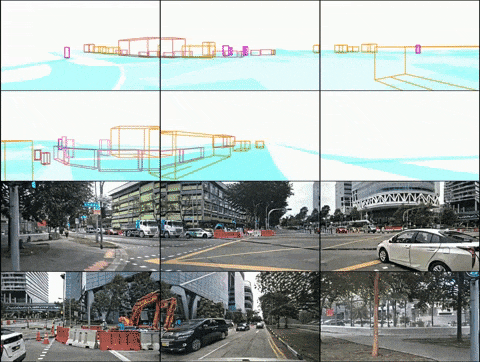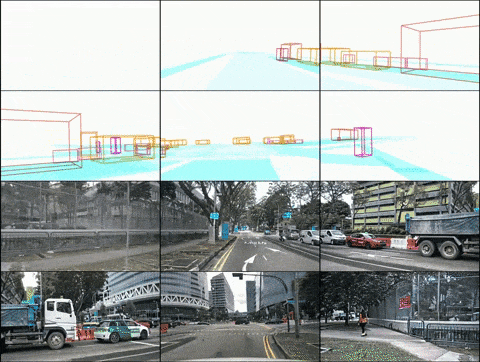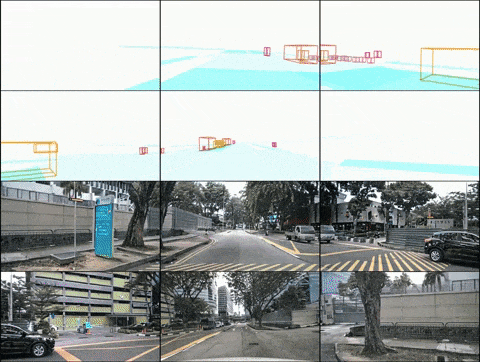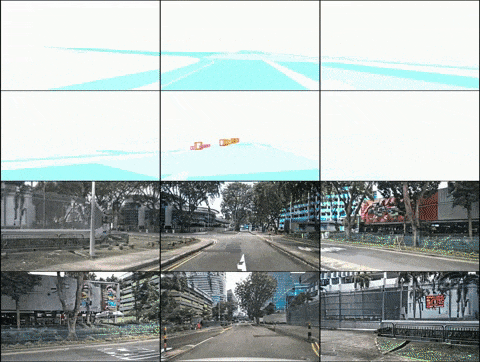

Ci-dessus : résultats de la génération vidéo de DrivingDiffusion après un entraînement sur les données nuScenes. En bas : résultats de la génération vidéo de DrivingDiffusion après un entraînement sur une grande quantité de données privées du monde réel.
(2) DrivingDiffusion-Future
Utilisez une image à image unique comme entrée et créez des scènes de conduite d'images ultérieures en fonction de la description textuelle du voiture principale/autres voitures. Les trois premières lignes et la quatrième ligne de la figure montrent respectivement l'effet de génération après la commande de description textuelle du comportement du véhicule principal et des autres véhicules. (La case verte est l'entrée, la case bleue est la sortie) 
Génère directement les images suivantes en fonction de la trame d'entrée
Aucun autre contrôle n'est requis, une seule image d'image est utilisée comme entrée pour prédire la scène de conduite des images suivantes. (La boîte verte est l'entrée, la boîte bleue est la sortie)
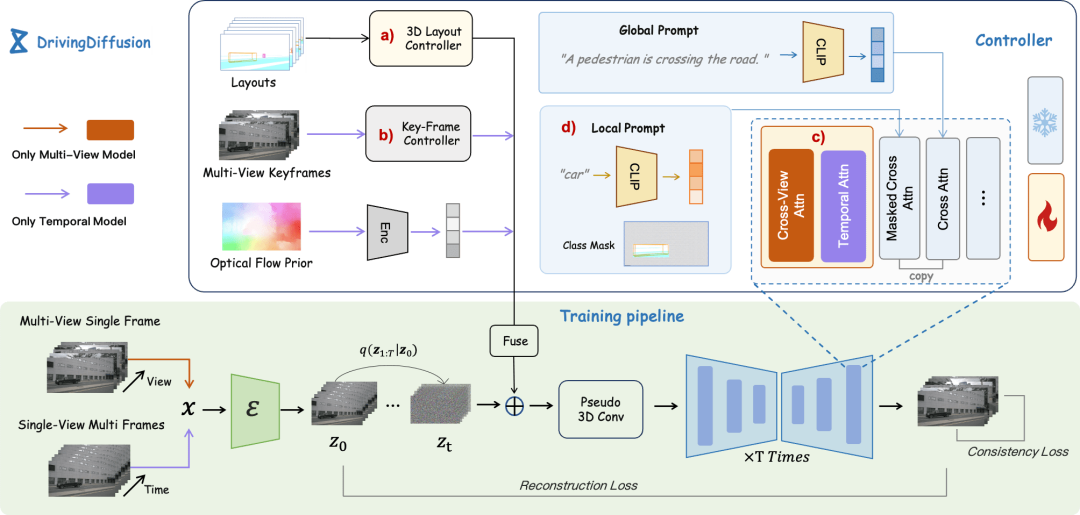
DrivingDiffusion construit d'abord artificiellement toutes les vraies valeurs 3D (obstacles/structures routières) dans la scène. Après avoir projeté les vraies valeurs dans les images de mise en page, elles sont utilisées comme entrée de modèle pour obtenir des images/vidéos réelles à partir de plusieurs caméras. perspectives. La raison pour laquelle les vraies valeurs 3D (vues BEV ou instances codées) ne sont pas utilisées directement comme entrée de modèle, mais les paramètres sont utilisés pour l'entrée post-projection, est d'éliminer les erreurs systématiques de cohérence 3D-2D. (Dans un tel ensemble de données, les valeurs vraies 3D et les paramètres du véhicule sont artificiellement construits en fonction des besoins réels. Les premières apportent la possibilité de construire des données de scènes rares à volonté , et les secondes éliminent les erreurs de production de données traditionnelles. cohérence géométrique)
Il reste encore une question à ce stade : la qualité de l'image/vidéo générée peut-elle répondre aux exigences d'utilisation ? Lorsqu'il s'agit de construire des scénarios, tout le monde pense souvent à utiliser un moteur de simulation. Cependant, il existe un écart important entre les données qu'il génère et les données réelles. Les résultats générés par les méthodes basées sur le GAN présentent souvent un certain biais par rapport à la distribution des données réelles réelles. Les modèles de diffusion sont basés sur les caractéristiques des chaînes de Markov qui génèrent des données par apprentissage du bruit. La fidélité des résultats générés est plus élevée et convient mieux à une utilisation en remplacement des données réelles. DrivingDiffusion génère directement desvues multi-vues séquentielles basées sur des scènes artificiellement construites et des paramètres du véhicule, qui peuvent non seulement être utilisées comme données d'entraînement pour les tâches de conduite autonome en aval, mais également construire un système de simulation pour le feedback sur la conduite autonome. algorithmes de conduite.
La "scène artificiellement construite" contient ici uniquement des informations sur les obstacles et la structure de la route, mais le cadre de DrivingDiffusion peut facilement introduire des informations de disposition telles que des panneaux de signalisation, des feux de circulation, des zones de construction et même des modes de contrôle tels qu'une grille d'occupation/carte de profondeur de bas niveau.Il existe plusieurs difficultés lors de la génération de vidéos multi-vues :
keyframe control et fine- réglage. De plus, DrivingDiffusion a proposé le module de cohérence et l'invite locale, qui résolvent respectivement les problèmes de cohérence entre vues/trames et de qualité des instances.
DrivingDiffusion génère un long processus vidéo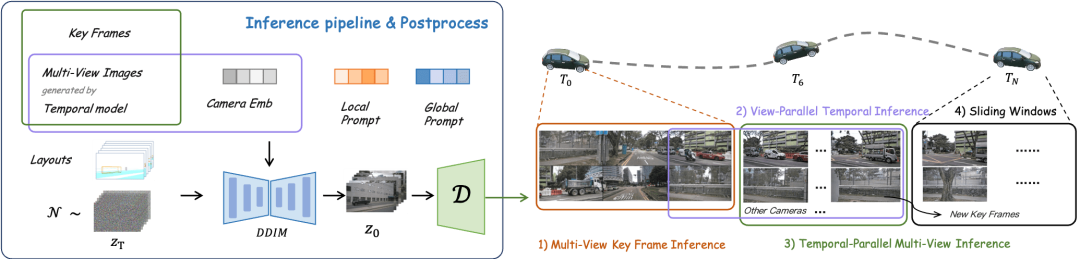
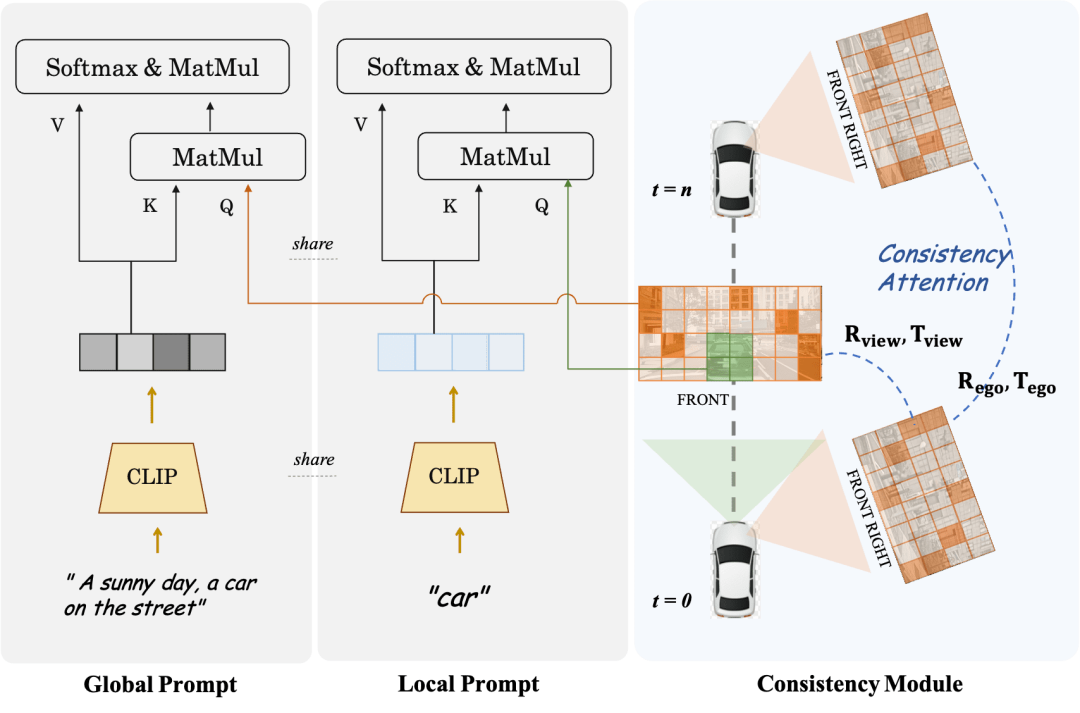
Module de cohérence est divisé en deux parties : Mécanisme d'attention de cohérence et Perte d'association de cohérence.
Le mécanisme d'attention à la cohérence se concentre sur l'interaction entre les vues adjacentes et les images liées dans le temps. Plus précisément, pour la cohérence entre images, il se concentre uniquement sur l'interaction des informations entre les vues adjacentes gauche et droite avec chevauchement. Pour le modèle temporel, chaque image uniquement. se concentre sur l’image clé et l’image précédente. Cela évite l’énorme charge de calcul causée par les interactions globales.
La perte de corrélation cohérente ajoute des contraintes géométriques par corrélation par pixel et régression de la pose, dont le gradient est fourni par un régresseur de pose pré-entraîné. Le régresseur ajoute une tête de régression de pose basée sur LoFTR et est entraîné en utilisant les vraies valeurs de pose sur les données réelles de l'ensemble de données correspondant. Pour les modèles multi-vues et les modèles de séries chronologiques, ce module supervise respectivement la pose relative de la caméra et la pose du mouvement principal du véhicule.
Local Prompt et Global Prompt travaillent ensemble pour réutiliser la sémantique des paramètres de CLIP et stable-diffusion-v1-4 afin d'effectuer une amélioration locale sur des zones d'instance de catégorie spécifiques. Comme le montre la figure, sur la base du mécanisme d'attention croisée des jetons d'image et des invites de description de texte globales, l'auteur conçoit une invite locale pour une certaine catégorie et utilise le jeton d'image dans la zone de masque de la catégorie pour interroger le local. rapide. Ce processus utilise au maximum le concept de génération d'images guidées par texte dans le domaine ouvert dans les paramètres du modèle d'origine.
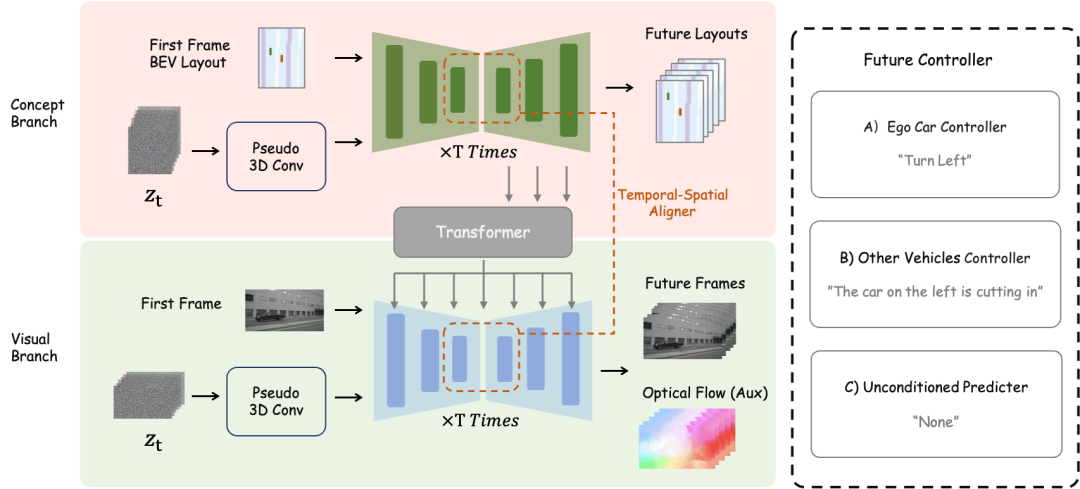
Pour les tâches de construction de scènes futures, DrivingDiffusion-Future utilise deux méthodes : l'une consiste à prédire les images d'image suivantes (branche visuelle) directement à partir de la première image d'image, et à utiliser inter- flux optique de trame comme perte auxiliaire. Cette méthode est relativement simple, mais l'effet de la génération d'images ultérieures basées sur des descriptions textuelles est moyen. Une autre façon consiste à ajouter une nouvelle branche conceptuelle basée sur la première, qui prédit la vue BEV des images suivantes via la vue BEV de la première image. En effet, la prédiction de la vue BEV aide le modèle à capturer les informations de base de la conduite. scène et établir des concepts. À ce stade, la description textuelle agit sur les deux branches en même temps, et les caractéristiques de la branche conceptuelle sont appliquées sur la branche visuelle via le module de conversion de perspective de BEV2PV. Certains paramètres du module de conversion de perspective sont pré-entraînés à l'aide. images à valeur réelle pour remplacer l'entrée de bruit (et en gel lors de l'entraînement ultérieur). Il convient de noter que le contrôleur de description du texte de contrôle du véhicule principal et le autre contrôleur de description du texte de contrôle du véhicule/environnement sont découplés.
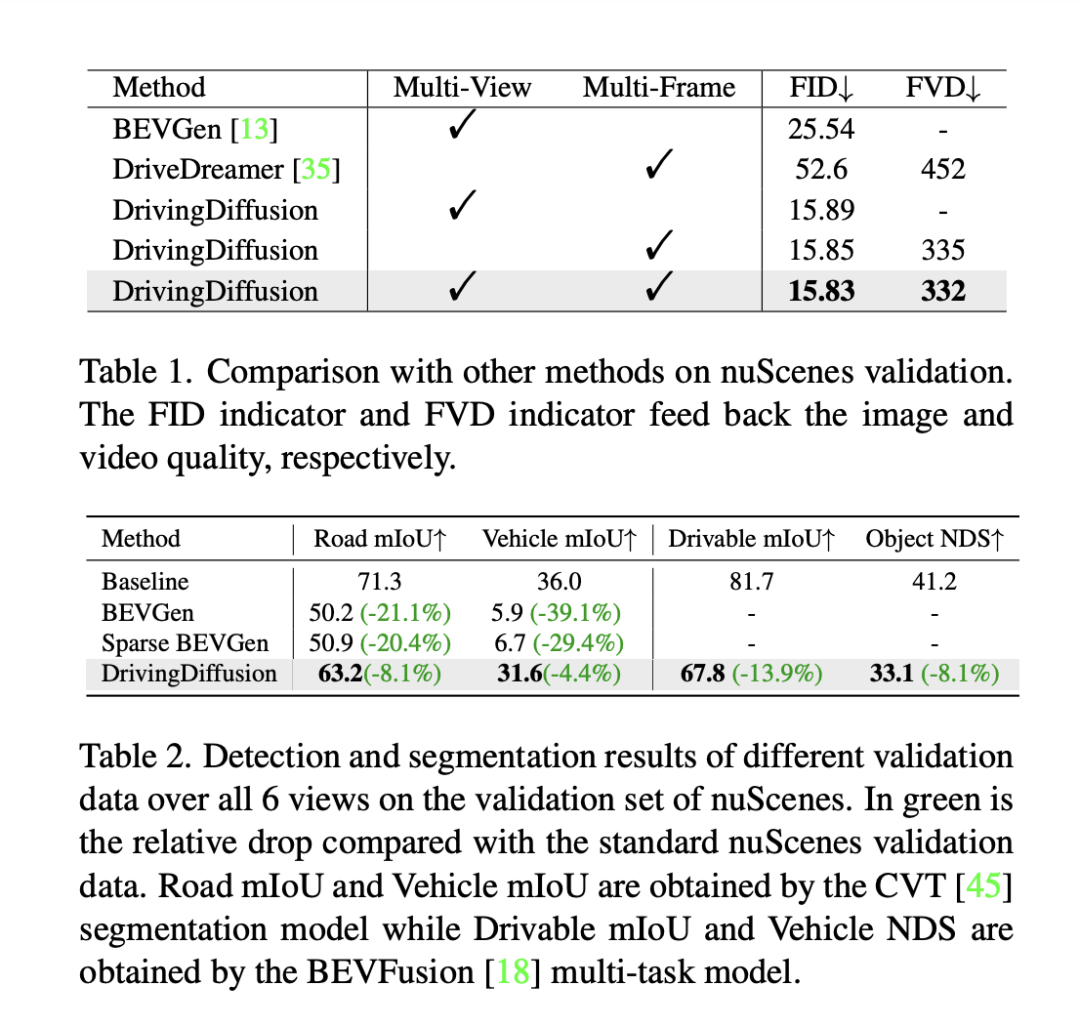
Pour évaluer les performances du modèle, DrivingDiffusion utilise la distance de démarrage de Fréchet (FID) au niveau de l'image pour évaluer la qualité des images générées, et utilise par conséquent FVD pour évaluer la qualité des vidéos générées. Toutes les métriques sont calculées sur l'ensemble de validation nuScenes. Comme le montre le tableau 1, par rapport à la tâche de génération d'images BEVGen et à la tâche de génération vidéo DriveDreamer dans des scénarios de conduite autonome, DrivingDiffusion présente de plus grands avantages en termes d'indicateurs de performance dans différents paramètres.
Bien que des méthodes telles que le FID soient souvent utilisées pour mesurer la qualité de la synthèse d'images, elles ne reflètent pas pleinement les objectifs de conception de la tâche, ni ne reflètent la qualité de la synthèse pour les différentes catégories sémantiques. La tâche étant dédiée à la génération d'images multi-vues cohérentes avec une mise en page 3D, DrivingDiffuison propose d'utiliser la métrique du modèle perceptuel BEV pour mesurer les performances en termes de cohérence : en utilisant les modèles officiels de CVT et BEVFusion comme évaluateurs, en utilisant la même 3D réelle. modèle comme ensemble de validation nuScenes Générez des images conditionnellement à la mise en page, effectuez une inférence CVT et BevFusion sur chaque ensemble d'images générées, puis comparez les résultats prédits avec les résultats réels, y compris le score moyen d'intersection sur U (mIoU) de la zone carrossable et les NDS de toutes les classes d'objets. Les statistiques sont présentées dans le tableau 2. Les résultats expérimentaux montrent que les indicateurs de perception de l'ensemble d'évaluation des données synthétiques sont très proches de ceux de l'ensemble d'évaluation réel, ce qui reflète la grande cohérence des résultats générés et des valeurs vraies 3D et la haute fidélité de la qualité de l'image.
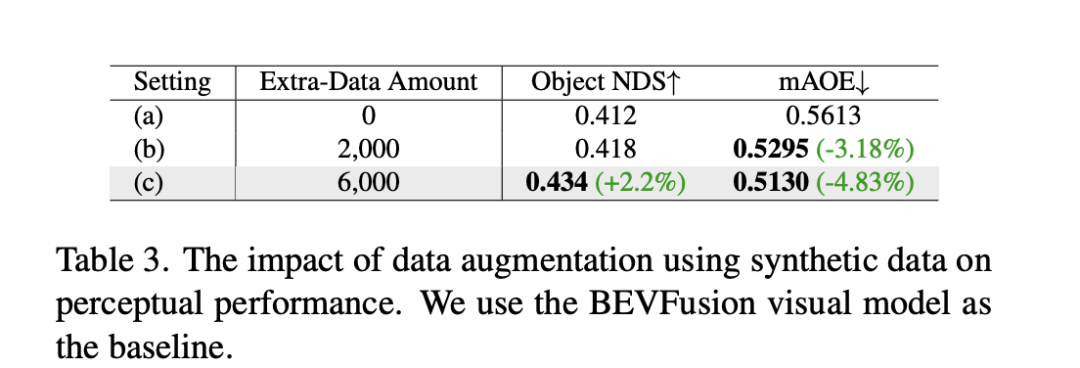
En plus des expériences ci-dessus, DrivingDiffusion a mené des expériences sur l'ajout d'un entraînement aux données synthétiques pour résoudre le principal problème qu'il a résolu : l'amélioration des performances des tâches de conduite autonome en aval. Le tableau 3 montre les améliorations de performances obtenues par l'augmentation des données synthétiques dans les tâches de perception BEV. Dans les données d'entraînement originales, il existe des problèmes avec les distributions à longue traîne, en particulier pour les petites cibles, les véhicules à courte portée et les angles d'orientation des véhicules. DrivingDiffusion se concentre sur la génération de données supplémentaires pour ces classes avec des échantillons limités pour résoudre ce problème. Après avoir ajouté 2 000 images de données axées sur l’amélioration de la répartition des angles d’orientation des obstacles, le NDS s’est légèrement amélioré, tandis que le mAOE a considérablement diminué, passant de 0,5613 à 0,5295. Après avoir utilisé 6 000 images de données synthétiques plus complètes et axées sur des scènes rares pour faciliter l'entraînement, une amélioration significative peut être observée sur l'ensemble de validation nuScenes : le NDS a augmenté de 0,412 à 0,434 et le mAOE a diminué de 0,5613 à 0,5130. Cela démontre l’amélioration significative que l’augmentation des données synthétiques peut apporter aux tâches de perception. Les utilisateurs peuvent réaliser des statistiques sur la répartition de chaque dimension dans les données en fonction des besoins réels, puis les compléter avec des données synthétiques ciblées.
DrivingDiffusion réalise simultanément la capacité de générer des vidéos multi-vues de scènes de conduite autonome et de prédire l'avenir, ce qui est d'une grande importance pour les tâches de conduite autonome. Parmi eux, layout et parameters sont tous construits artificiellement et la conversion entre 3D et 2D se fait par projection plutôt que par des paramètres de modèle apprenables. Cela élimine les erreurs géométriques dans le processus précédent d'obtention de données et a une forte valeur pratique. Dans le même temps, DrivingDiffuson est extrêmement évolutif et prend en charge de nouvelles dispositions de contenu de scène et des contrôleurs supplémentaires. Il peut également améliorer sans perte la qualité de génération grâce à la technologie de super-résolution et d'insertion d'images vidéo.
Dans la simulation de conduite autonome, les tentatives de Nerf se multiplient. Cependant, dans la tâche de génération de Street View, la séparation du contenu dynamique et statique, la reconstruction de blocs à grande échelle, le découplage du contrôle de l'apparence de la météo et d'autres dimensions, etc., nécessitent en outre une énorme quantité de travail. être réalisé dans une gamme spécifique de scènes. Ce n'est qu'après une formation qu'il peut prendre en charge de nouvelles tâches de synthèse de perspective dans les simulations ultérieures. DrivingDiffusion contient naturellement une certaine quantité de connaissances générales préalables, notamment les connexions visuel-texte, la compréhension conceptuelle du contenu visuel, etc. Il peut rapidement créer une scène en fonction des besoins simplement en construisant la mise en page. Cependant, comme mentionné ci-dessus, l'ensemble du processus est relativement complexe et la génération de vidéos longues nécessite un ajustement et une extension du modèle de post-traitement. DrivingDiffusion continuera d'explorer la compression des dimensions de perspective et des dimensions temporelles, ainsi que de combiner Nerf pour de nouvelles générations et conversions de perspectives, et continuera d'améliorer la qualité et l'évolutivité de la génération.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quelles compétences sont nécessaires pour travailler dans l'industrie PHP ?
Quelles compétences sont nécessaires pour travailler dans l'industrie PHP ?
 Comment dessiner un diagramme de Pert
Comment dessiner un diagramme de Pert
 Qu'est-ce qu'un équipement terminal ?
Qu'est-ce qu'un équipement terminal ?
 Introduction aux touches de raccourci pour réduire Windows Windows
Introduction aux touches de raccourci pour réduire Windows Windows
 Tutoriel de création de tableaux de documents Word
Tutoriel de création de tableaux de documents Word
 La raison pour laquelle la fonction d'en-tête renvoie un échec 404
La raison pour laquelle la fonction d'en-tête renvoie un échec 404
 Collection complète d'instructions de requête SQL
Collection complète d'instructions de requête SQL
 Le commutateur Bluetooth Win10 est manquant
Le commutateur Bluetooth Win10 est manquant








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



