


GPT-4V pour la détection de cibles ? Test réel par les internautes : pas encore prêt.
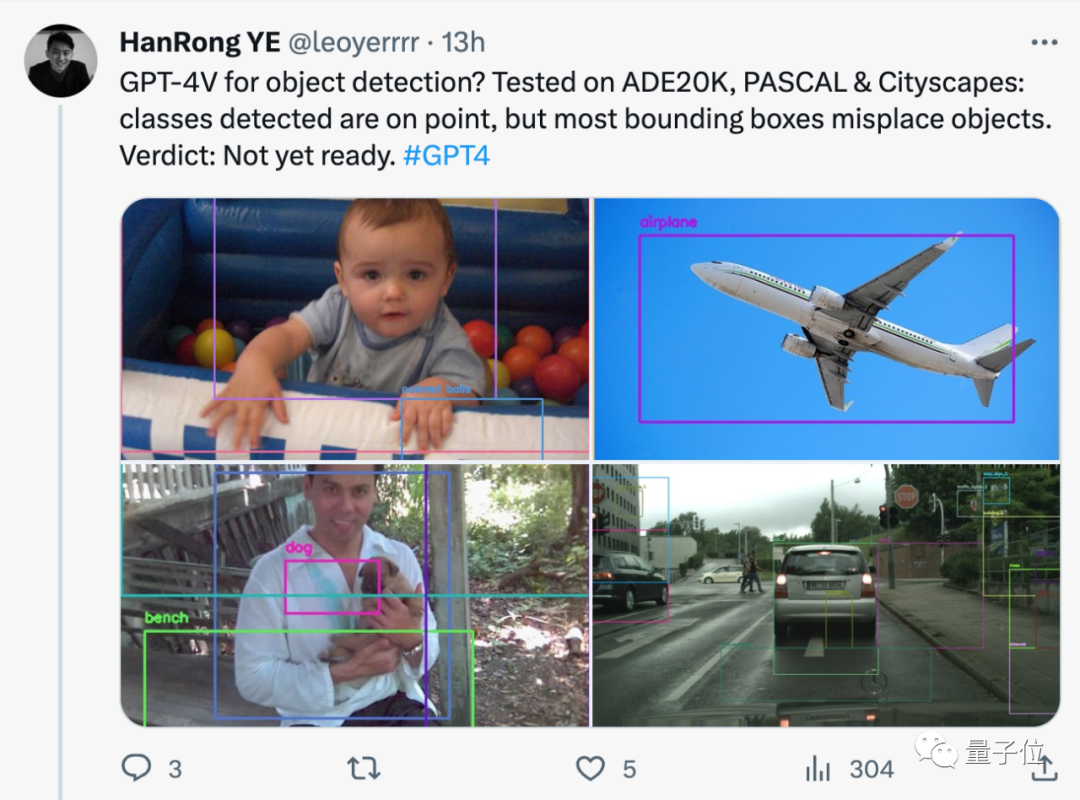
Bien que les catégories détectées soient correctes, la plupart des cadres de délimitation sont mal placés.
Ce n’est pas grave, quelqu’un passera à l’action !
Le Mini GPT-4 qui a battu le GPT-4 de plusieurs mois en termes de capacité de visualisation d'images a été mis à niveau - MiniGPT-v2.
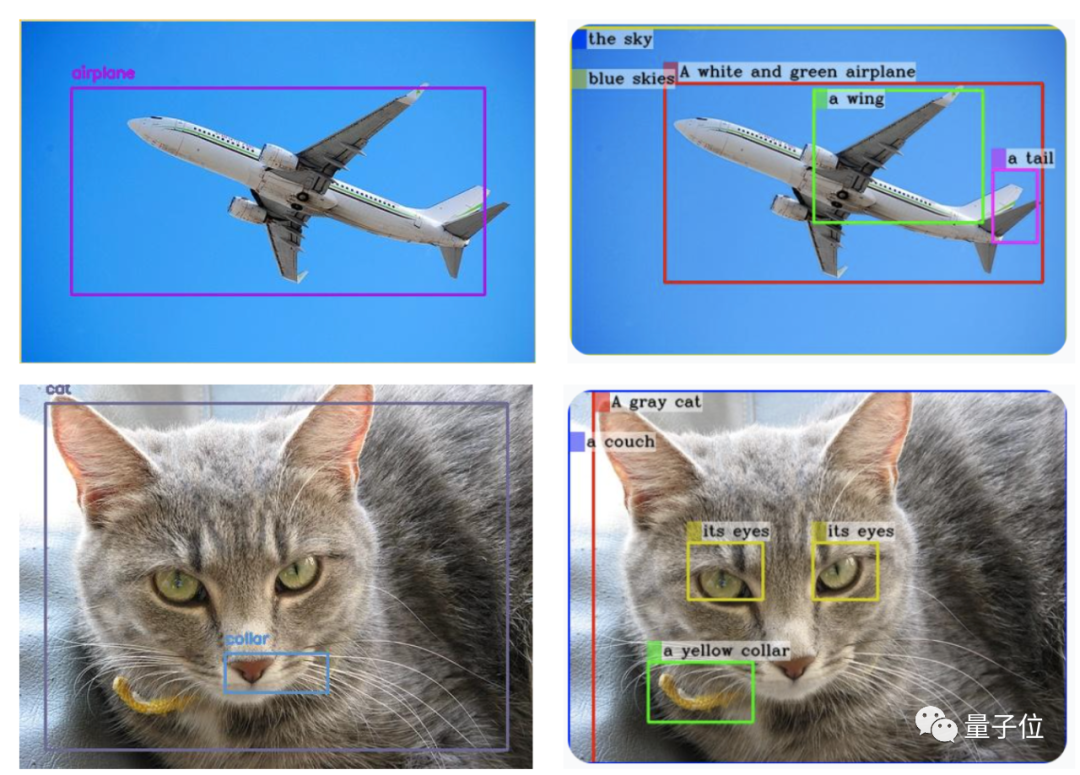
△ (GPT-4V est généré à gauche et MiniGPT-v2 est généré à droite)
Et c'est juste une simple commande : [grounding] décrivez cette image en détail pour obtenir le résultat.
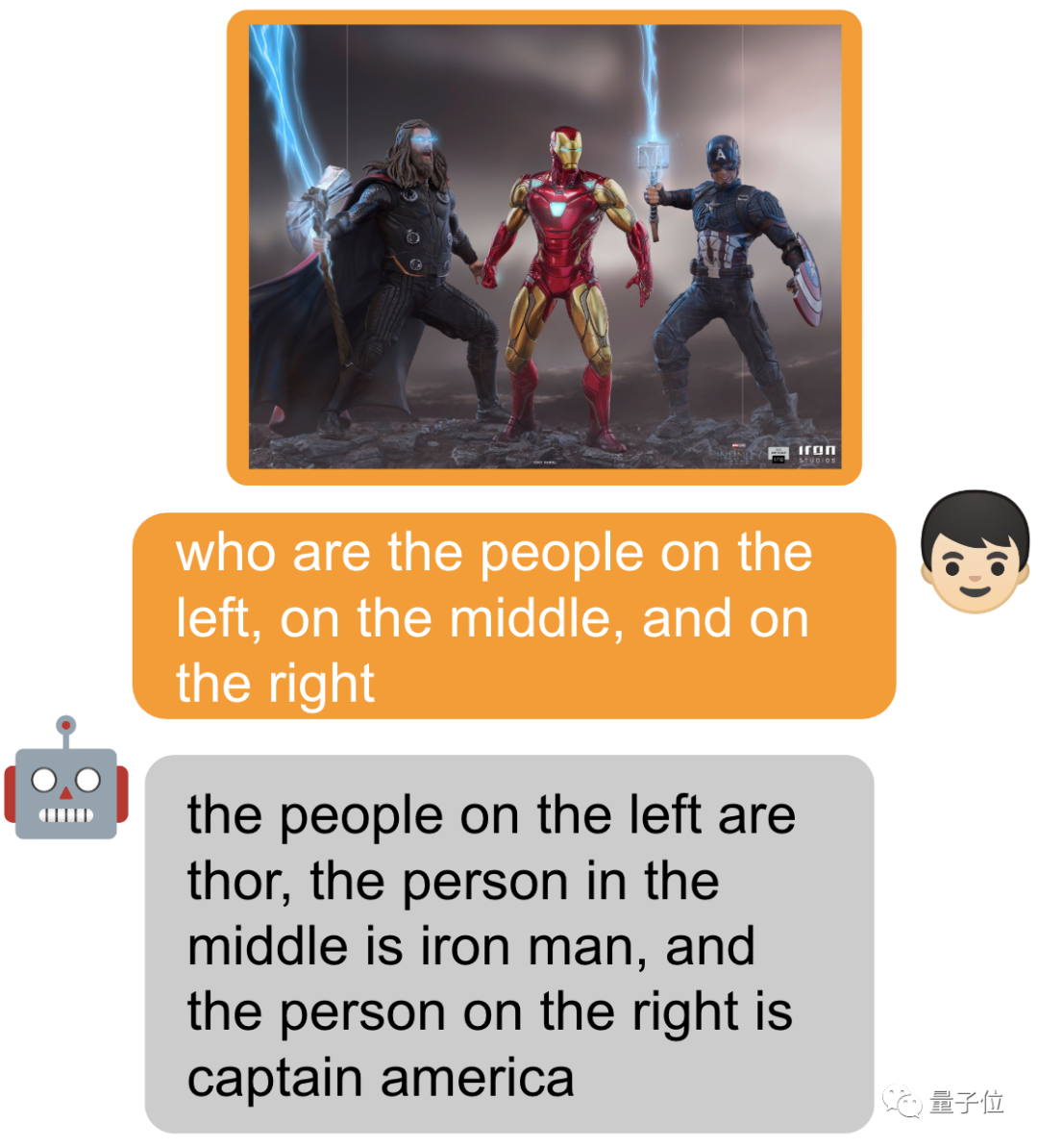
Non seulement cela, il peut également gérer facilement diverses tâches visuelles.
Entourez un objet et ajoutez [identifier] devant le mot d'invite pour permettre au modèle d'identifier directement le nom de l'objet.

Bien sûr, vous pouvez également ne rien ajouter et simplement demander ~
MiniGPT-v2 est composé de l'équipe originale de MiniGPT-4 (Université des sciences et technologies KAUST King Abdullah en Arabie Saoudite) et de cinq chercheurs du développement conjoint Meta.

La dernière fois, MiniGPT-4 a attiré une énorme attention lors de sa sortie, et le serveur a été submergé pendant un moment. Aujourd'hui, le projet GitHub dépasse les 22 000 étoiles.
Avec cette mise à niveau, certains internautes ont déjà commencé à l'utiliser~
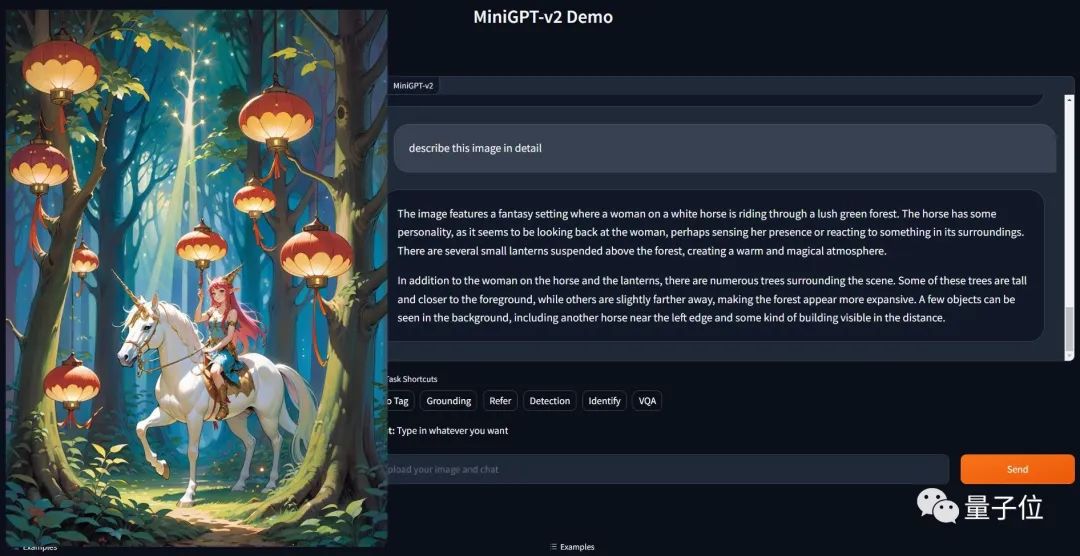
En tant qu'interface universelle pour diverses applications de texte, tout le monde s'y est habitué. S'inspirant de cela, l'équipe de recherche souhaite créer une interface unifiée pouvant être utilisée pour diverses tâches visuelles, telles que la description d'images, la réponse visuelle à des questions, etc.

"Comment utiliser des instructions multimodales simples pour effectuer efficacement diverses tâches sous la condition d'un seul modèle ?" est devenu un problème que l'équipe doit résoudre.
Pour faire simple, MiniGPT-v2 se compose de trois parties : le squelette visuel, la couche linéaire et le grand modèle de langage.
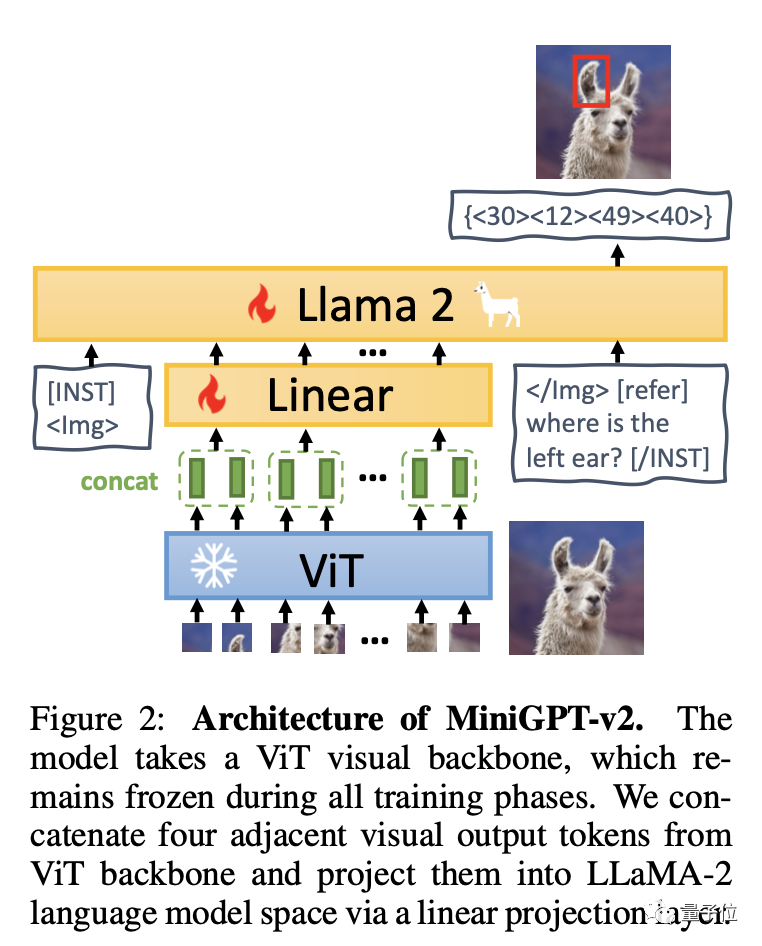
Le modèle est basé sur l'épine dorsale visuelle ViT et reste inchangé à toutes les étapes de formation. Quatre jetons de sortie visuelle adjacents sont induits à partir de ViT et projetés dans l'espace de modèle de langage LLaMA-2 à travers des couches linéaires.
L'équipe recommande d'utiliser des identifiants uniques pour différentes tâches dans le modèle de formation, afin que les grands modèles puissent facilement distinguer chaque instruction de tâche et améliorer l'efficacité d'apprentissage de chaque tâche.
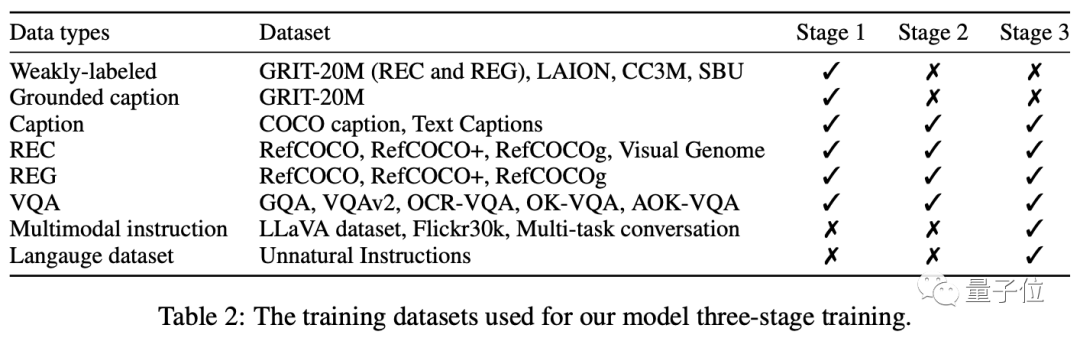
La formation est principalement divisée en trois étapes : pré-formation - formation multi-tâches - ajustement des instructions multi-modes.
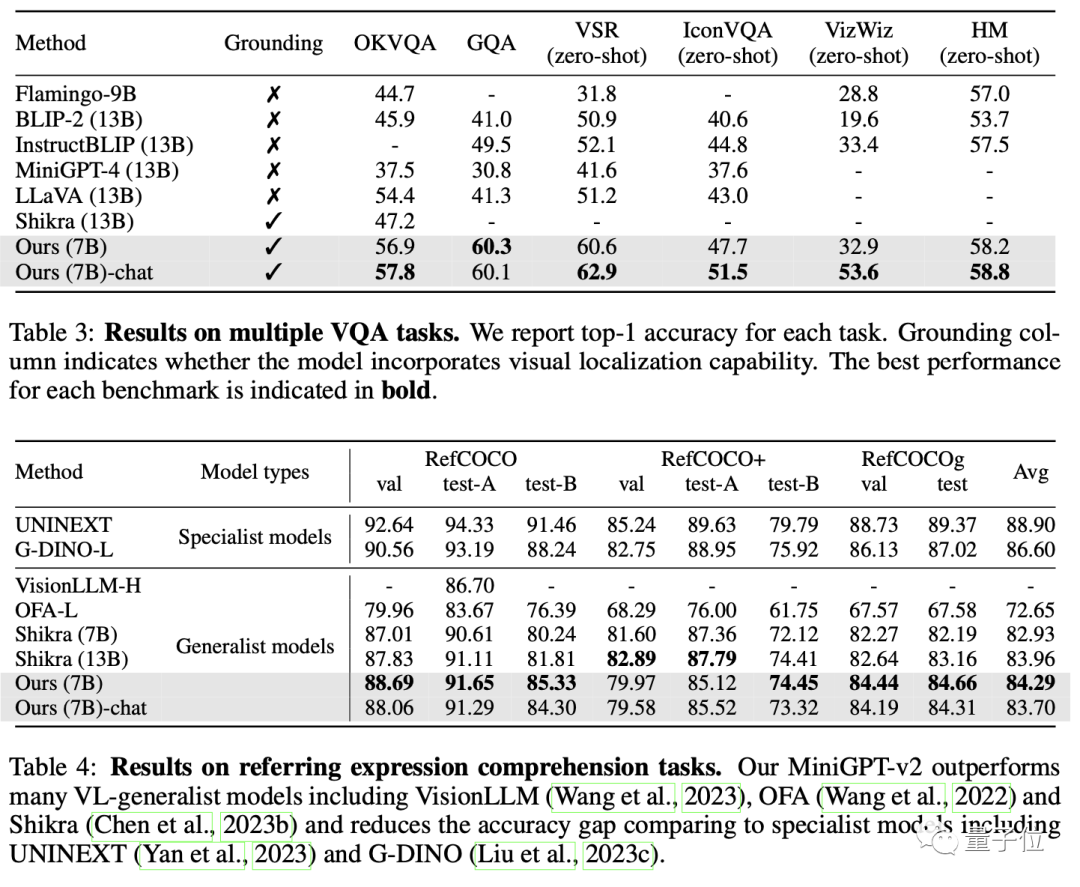
En fin de compte, MiniGPT-v2 a surpassé les autres modèles généraux de langage visuel dans de nombreux tests de réponse visuelle aux questions et de référence visuelle.
En fin de compte, ce modèle peut effectuer une variété de tâches visuelles, telles que la description de l'objet cible, la localisation visuelle, la description de l'image, la réponse visuelle aux questions et l'analyse directe des objets image à partir d'un texte d'entrée donné.

Les amis intéressés peuvent cliquer sur le lien Démo ci-dessous pour en faire l'expérience :
https://minigpt-v2.github.io/
https://huggingface.co/spaces/Vision-CAIR/ MiniGPT -v2
Lien papier : https://arxiv.org/abs/2310.09478
Lien GitHub : https://github.com/Vision-CAIR/MiniGPT-4
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quel fichier est une ressource ?
Quel fichier est une ressource ?
 Comment définir un arrêt programmé dans UOS
Comment définir un arrêt programmé dans UOS
 Springcloud cinq composants principaux
Springcloud cinq composants principaux
 Le rôle de la fonction mathématique en langage C
Le rôle de la fonction mathématique en langage C
 Que signifie le wifi désactivé ?
Que signifie le wifi désactivé ?
 Jailbreak iPhone 4
Jailbreak iPhone 4
 La différence entre les fonctions fléchées et les fonctions ordinaires
La différence entre les fonctions fléchées et les fonctions ordinaires
 Comment ignorer la connexion à Internet après le démarrage de Windows 11
Comment ignorer la connexion à Internet après le démarrage de Windows 11








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



