



Actuellement, les véhicules autonomes sont équipés de divers capteurs de collecte d'informations, tels que le lidar, le radar à ondes millimétriques et les capteurs de caméra. Du point de vue actuel, une variété de capteurs ont montré de grandes perspectives de développement dans les tâches de perception de la conduite autonome. Par exemple, les informations d'image 2D collectées par la caméra capturent de riches caractéristiques sémantiques, et les données de nuages de points collectées par lidar peuvent fournir des informations de position précises et des informations géométriques de l'objet pour le modèle de perception. En utilisant pleinement les informations obtenues par différents capteurs, l'apparition de facteurs d'incertitude dans le processus de perception de la conduite autonome peut être réduite, tandis que la robustesse de détection du modèle de perception peut être améliorée. Aujourd'hui, nous présentons un article sur la perception de la conduite autonome de Megvii. et a été accepté à la conférence visuelle ICCV2023 de cette année. La principale caractéristique de cet article est un algorithme de perception BEV de bout en bout similaire au PETR (il ne nécessite plus l'utilisation d'opérations de post-traitement NMS pour filtrer les cases redondantes dans les résultats de perception. ). Dans le même temps, les informations du nuage de points du lidar sont également utilisées pour améliorer les performances de perception du modèle. Il s'agit d'un très bon article sur l'orientation de la perception de la conduite autonome. Le lien vers l'article et l'entrepôt open source officiel. Les liens sont les suivants :
Lien papier : https://arxiv.org/pdf/2301.01283.pdf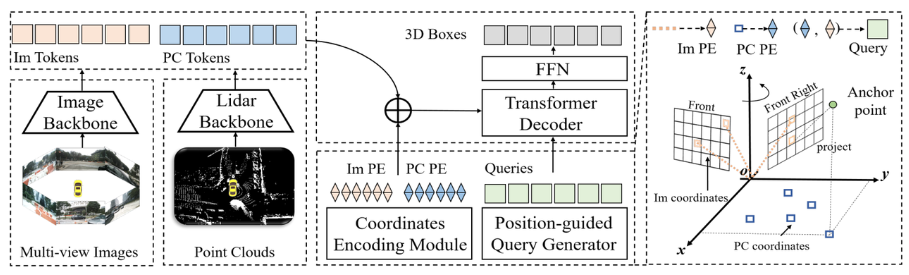 Comme le montre l'ensemble du schéma fonctionnel de l'algorithme, l'ensemble du modèle d'algorithme comprend principalement trois parties
Comme le montre l'ensemble du schéma fonctionnel de l'algorithme, l'ensemble du modèle d'algorithme comprend principalement trois parties
Réseau fédérateur Lidar + réseau fédérateur de caméra (Image Backbone + Lidar Backbone)
Réseau fédérateur Lidar
Tenseur([bs * N, 1024, H/16, W/16])Tensor([bs * N, 1024, H / 16, W / 16])
Tensor([bs * N,2048,H / 16,W / 16])
需要重新写的内容是:张量([bs * N,256,H / 16,W / 16])
Tenseur([bs * N, 3, H, W])Tensor([bs * N,3,H,W])输出张量:Tensor([bs * N,1024,H / 16,W / 16])
输出张量:``Tensor([bs * N,2048,H / 32,W / 32])`
需要进行改写的内容是:2D骨架提取图像特征
Neck(CEFPN)
根据以上介绍,位置编码的生成主要包括三个部分,分别是图像位置嵌入、点云位置嵌入和查询嵌入。下面将逐一介绍它们的生成过程
在BEV空间的网格坐标点利用pos2embed()
Tenseur de sortie : Tensor([bs * N, 1024, H/16, W/ 16] )
Le contenu qui doit être réécrit est : Extraction du squelette 2D Image fonctionnalités
Cou (CEFPN)
Incorporation de position d'image (Im PE)Le processus de génération d'intégration de position d'image est le même que la logique de génération d'encodage de position d'image dans PETR (pour plus de détails, veuillez vous référer à l'article PETR original, qui ne sera pas fait ici Trop d'élaboration), qui peut être résumé dans les quatre étapes suivantes :
Nuage de points du tronc de l'image 3D Utilisez la matrice de paramètres internes de la caméra pour transformer le système de coordonnées de la caméra afin d'obtenir le point de coordonnées de la caméra 3D
Le point 3D dans le système de coordonnées de la caméra est converti en système de coordonnées BEV à l'aide du Matrice de transformation de coordonnées cam2ego
Le processus de génération du nuage de points L'intégration de position peut être divisée en deux étapes suivantes
pos2embed()
Intégration de requêtes
logique de génération bev_query_embeds
Étant donné que la requête d'objet dans l'article est initialement initialisée dans l'espace BEV, l'encodage de position et la fonction bev_embedding() dans la logique de génération d'incorporation de position de nuage de points sont directement réutilisés, c'est-à-dire que oui, le code clé correspondant est le suivant :
# 点云位置编码`bev_pos_embeds`的生成bev_pos_embeds = self.bev_embedding(pos2embed(self.coords_bev.to(device), num_pos_feats=self.hidden_dim))def coords_bev(self):x_size, y_size = (grid_size[0] // downsample_scale,grid_size[1] // downsample_scale)meshgrid = [[0, y_size - 1, y_size], [0, x_size - 1, x_size]]batch_y, batch_x = torch.meshgrid(*[torch.linspace(it[0], it[1], it[2]) for it in meshgrid])batch_x = (batch_x + 0.5) / x_sizebatch_y = (batch_y + 0.5) / y_sizecoord_base = torch.cat([batch_x[None], batch_y[None]], dim=0) # 生成BEV网格.coord_base = coord_base.view(2, -1).transpose(1, 0)return coord_base# shape: (x_size *y_size, 2)def pos2embed(pos, num_pos_feats=256, temperature=10000):scale = 2 * math.pipos = pos * scaledim_t = torch.arange(num_pos_feats, dtype=torch.float32, device=pos.device)dim_t = temperature ** (2 * (dim_t // 2) / num_pos_feats)pos_x = pos[..., 0, None] / dim_tpos_y = pos[..., 1, None] / dim_tpos_x = torch.stack((pos_x[..., 0::2].sin(), pos_x[..., 1::2].cos()), dim=-1).flatten(-2)pos_y = torch.stack((pos_y[..., 0::2].sin(), pos_y[..., 1::2].cos()), dim=-1).flatten(-2)posemb = torch.cat((pos_y, pos_x), dim=-1)return posemb# 将二维的x,y坐标编码成512维的高维向量
def _bev_query_embed(self, ref_points, img_metas):bev_embeds = self.bev_embedding(pos2embed(ref_points, num_pos_feats=self.hidden_dim))return bev_embeds# (bs, Num, 256)
seront mis en premier. Des expériences comparatives entre CMT et d'autres algorithmes de perception de conduite autonome ont été publiées. Les auteurs de l'article ont effectué des comparaisons sur les ensembles de test et de val de nuScenes.
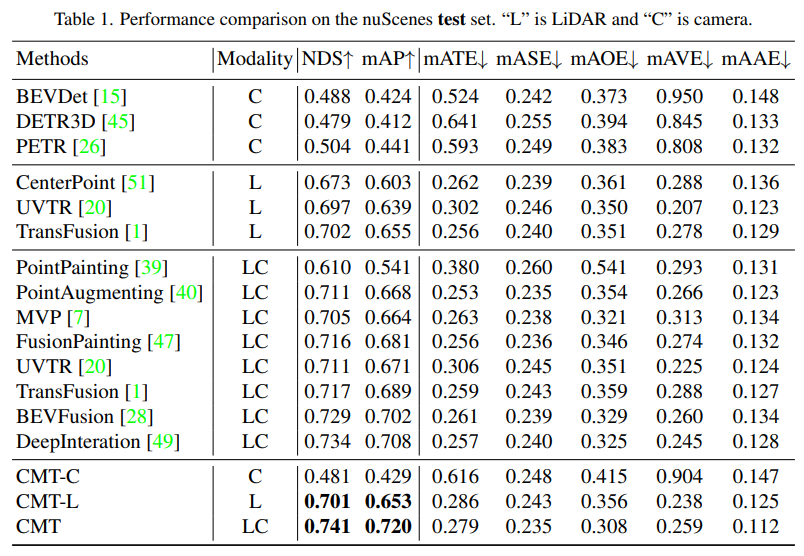
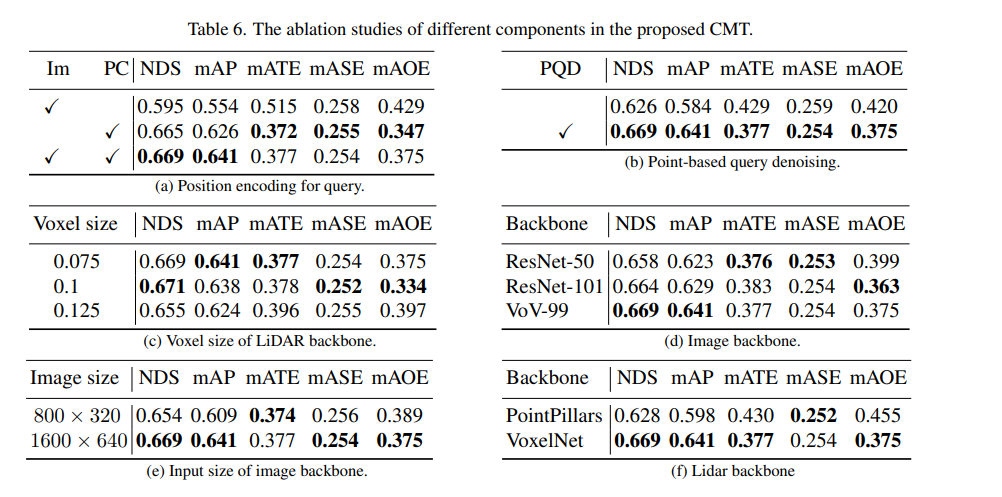
Tout d'abord, nous avons mené une série d'expériences d'ablation pour déterminer s'il fallait utiliser le codage de position. Grâce aux résultats expérimentaux, il a été constaté que les indicateurs NDS et mAP obtenaient les meilleurs résultats en utilisant à la fois la position de l'image et la position lidar. codage. Ensuite, dans (c) et (c) de l’expérience d’ablation, partie f), nous avons expérimenté différents types et tailles de voxels du réseau fédérateur de nuages de points. Dans les expériences d'ablation des parties (d) et (e), nous avons fait différentes tentatives sur le type de réseau fédérateur de caméra et la taille de la résolution d'entrée. Ce qui précède n'est qu'un bref résumé du contenu expérimental. Si vous souhaitez connaître des expériences d'ablation plus détaillées, veuillez vous référer à l'article original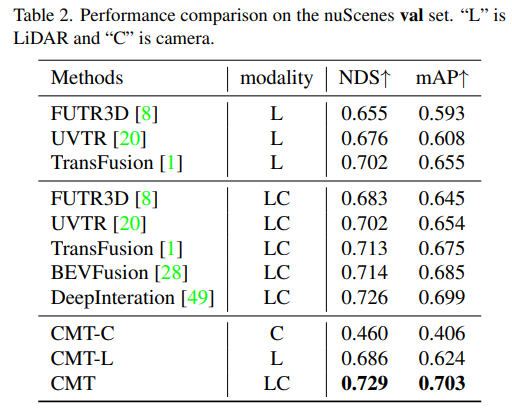
Résumé
Actuellement, la fusion de diverses modalités pour améliorer les performances perceptuelles du modèle est devenue une direction de recherche populaire (en particulier dans les véhicules autonomes, équipés de divers capteurs). Parallèlement, CMT est un algorithme de perception entièrement de bout en bout qui ne nécessite aucune étape de post-traitement supplémentaire et atteint une précision de pointe sur l'ensemble de données nuScenes. Cet article présente cet article en détail, j'espère qu'il sera utile à tout le monde Le contenu qui doit être réécrit est : Lien original : https://mp.weixin.qq.com/s/Fx7dkv8f2ibkfO66-5hEXA
Le contenu qui doit être réécrit est : Lien original : https://mp.weixin.qq.com/s/Fx7dkv8f2ibkfO66-5hEXA
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment acheter de vraies pièces Ripple
Comment acheter de vraies pièces Ripple
 Pourquoi le wifi a-t-il un point d'exclamation ?
Pourquoi le wifi a-t-il un point d'exclamation ?
 des centaines
des centaines
 Que dois-je faire si msconfig ne peut pas être ouvert ?
Que dois-je faire si msconfig ne peut pas être ouvert ?
 Type de vulnérabilité du système
Type de vulnérabilité du système
 Introduction aux raisons pour lesquelles le bureau à distance ne peut pas se connecter
Introduction aux raisons pour lesquelles le bureau à distance ne peut pas se connecter
 horodatage python
horodatage python
 La différence entre la charge rapide PD et la charge rapide générale
La différence entre la charge rapide PD et la charge rapide générale








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



