


La revue la plus complète des grands modèles multimodauxest ici !
Écrit par7 chercheurs chinois de Microsoft, 119 pages——

actuellement perfectionné et toujours à l'avant-gardedeux types d'orientations de recherche multimodales sur grands modèles. Au début, cinq sujets de recherche spécifiques sont résumés de manière exhaustive :

Les modèles de base multimodaux sont passés de spécialisés àPs. C'est pourquoi l'auteur a directement dessiné une image deuniversels.
Doraemon au début de l'article.
Qui est apte à lire cette critique(rapport) ?
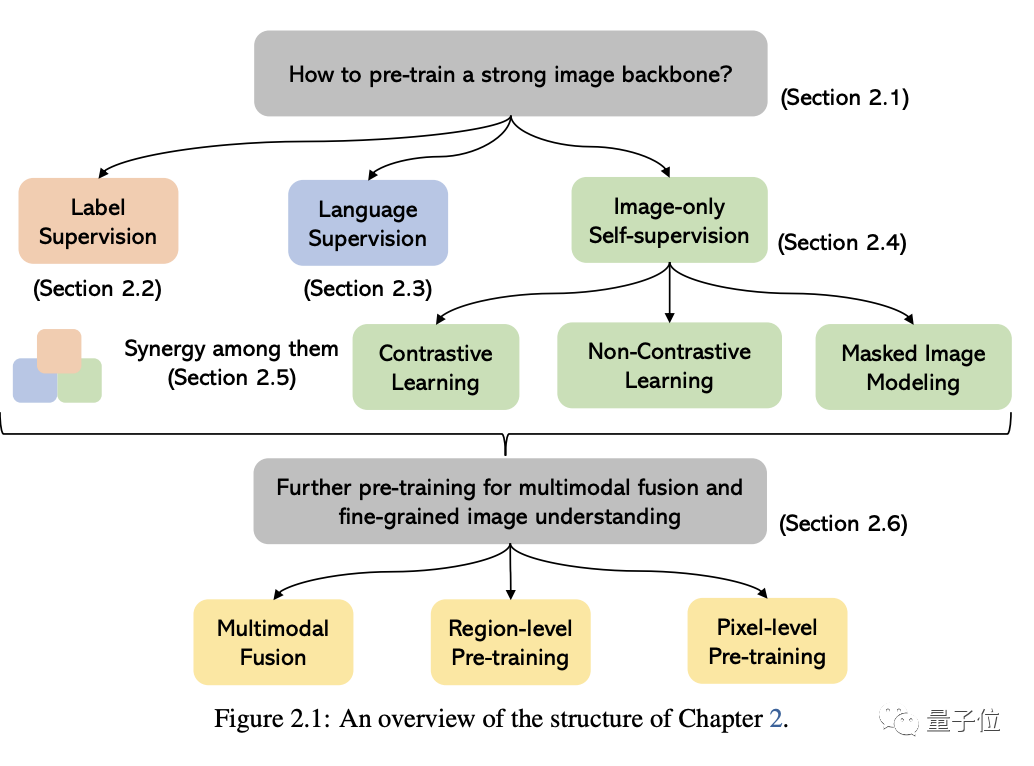
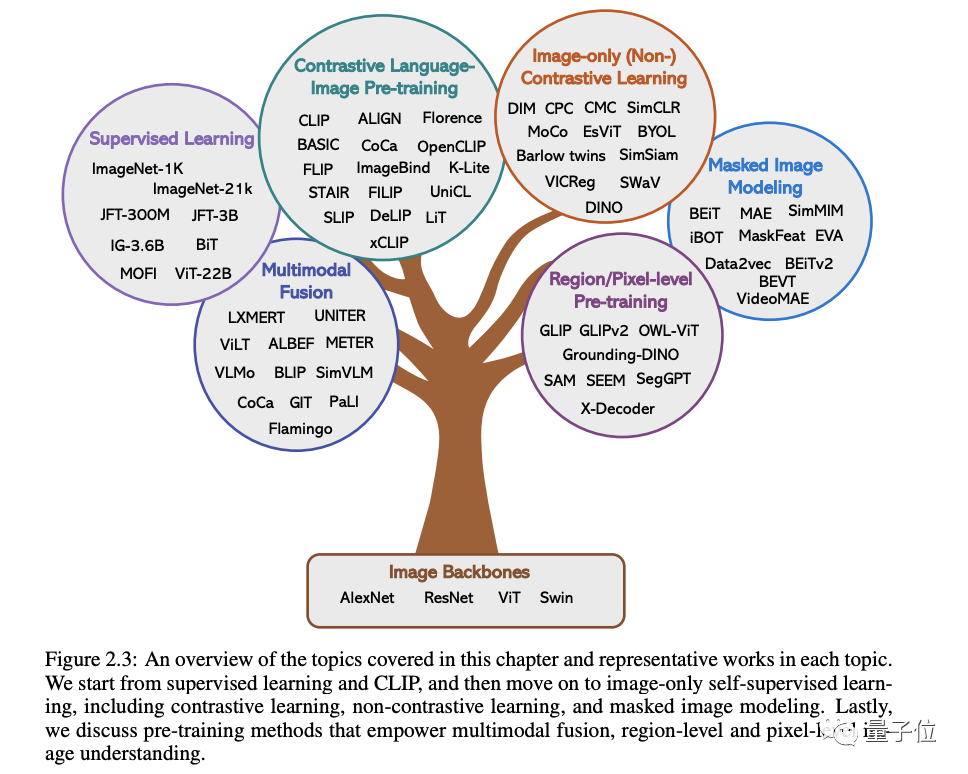
Dans les mots originaux de Microsoft : Tant que vous êtes intéressé à apprendre les connaissances de base et les derniers progrès des modèles de base multimodaux, que vous soyez un chercheur professionnel ou un étudiant, ce contenu vous convient parfaitementJetons un coup d'œil ~Un article pour connaître l'état actuel des grands modèles multimodauxLes deux premiers de ces cinq sujets spécifiques sont des domaines actuellement matures, tandis que les trois derniers sont des domaines de pointe1 . Compréhension visuelleCette partie Le problème principal est de savoir comment pré-former une puissante base de compréhension des images. Comme le montre la figure ci-dessous, selon les différents signaux de supervision utilisés pour entraîner le modèle, nous pouvons diviser les méthodes en trois catégories :
supervision d'étiquettes, supervision linguistique
(représentée par CLIP) et autosupervision par image uniquement .
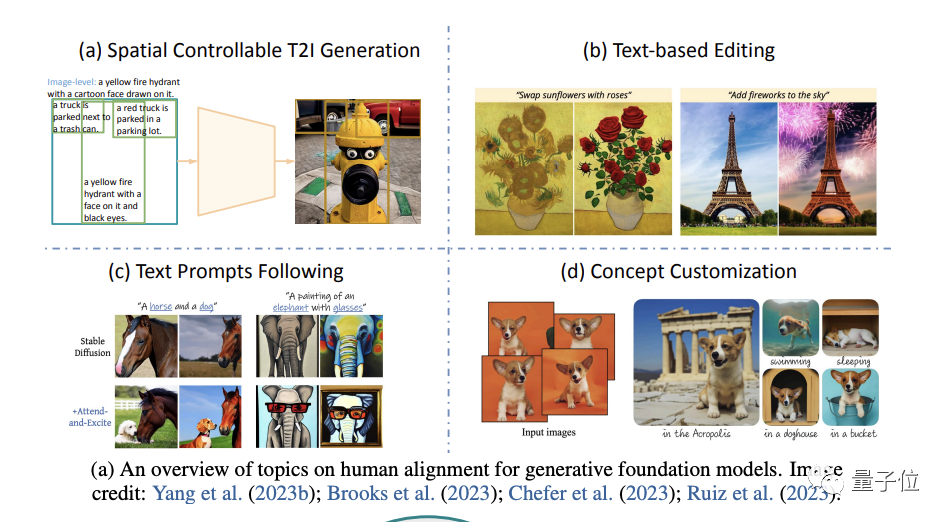
(accent sur la génération d'images) .
Plus précisément, cela commence par quatre aspects : la génération spatiale contrôlable, la réédition basée sur le texte, un meilleur suivi des invites de texte et la personnalisation du concept de génération(personnalisation du concept).
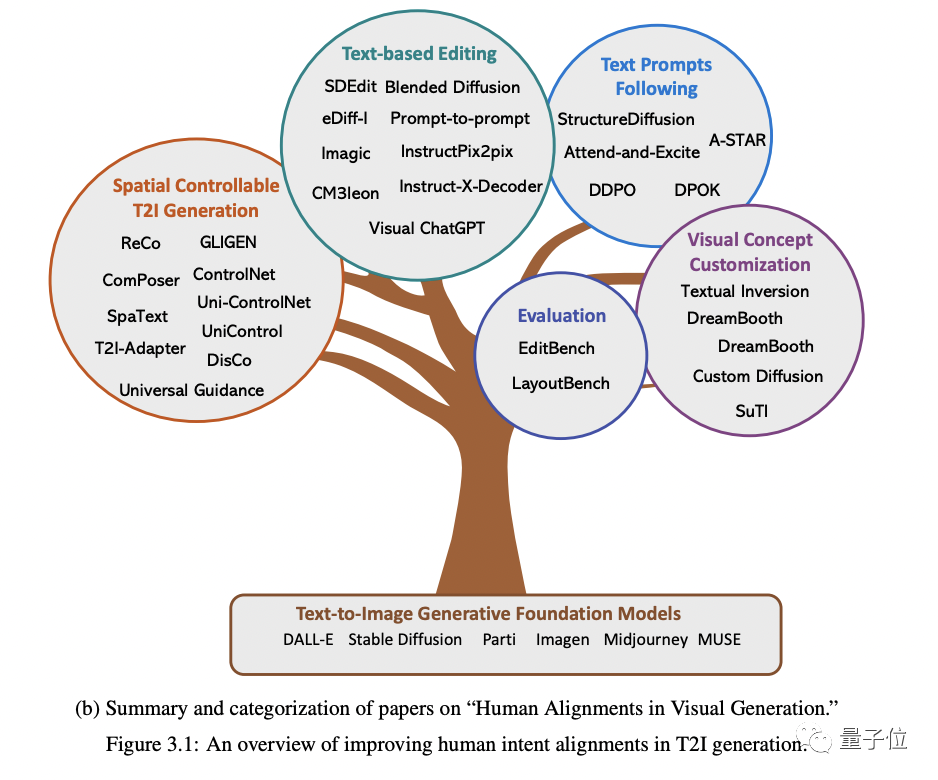
Le. le contenu qui doit être réécrit est : premièrement, le type d'entrée est différent ; Le contenu qui doit être réécrit est : deuxièmement, différentes tâches nécessitent une granularité différente, et la sortie nécessite également différents formats Les données sont également confrontées ; défis , en plus du mannequinat
Par exemple, le coût des différents types d'annotations d'étiquettes varie considérablement et le coût de collecte est bien supérieur à celui des données textuelles, ce qui fait que la taille des données visuelles est généralement bien inférieure à celle des corpus textuels.
Cependant, malgré les nombreux défis, l'auteur souligne :
Le domaine du CV s'intéresse de plus en plus au développement de systèmes de vision générale et unifiée, et trois types de tendances ont émergé :
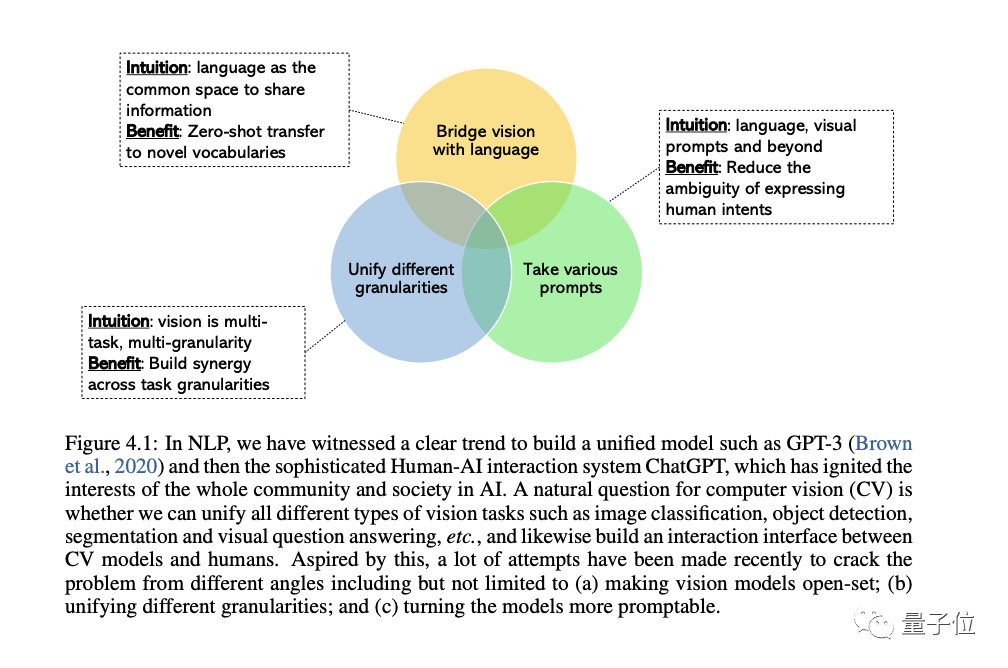
D'abord, à partir des ensembles fermés( close-set) à open-set(open-set), qui peut mieux faire correspondre le texte et les visuels.
La raison la plus importante du passage de tâches spécifiques à des capacités générales est que le coût de développement d'un nouveau modèle pour chaque nouvelle tâche est trop élevé
La troisième est des modèles statiques aux modèles incitatifs, LLM peut adopter différents langages et des invites contextuelles en entrée et produisent la sortie souhaitée par l'utilisateur sans réglage fin. Le modèle de vision générale que nous souhaitons construire doit avoir les mêmes capacités d’apprentissage contextuel.
Cette section traite en détail des grands modèles multimodaux.
Tout d’abord, nous mènerons une étude approfondie du contexte et des exemples représentatifs, discuterons des progrès de la recherche multimodale d’OpenAI et identifierons les lacunes de recherche existantes dans ce domaine.
Ensuite, l'auteur examine en détail l'importance du réglage fin de l'enseignement dans les grands modèles de langage.
Ensuite, l'auteur discute du réglage fin des instructions dans les grands modèles multimodaux, y compris les principes, la signification et les applications.
Enfin, nous aborderons également certains sujets avancés dans le domaine des modèles multimodaux pour une compréhension plus approfondie, notamment :
Plus de modalités au-delà de la vision et du langage, l'apprentissage du contexte multimodal, la formation efficace des paramètres ainsi que les benchmarks et autres contenu.
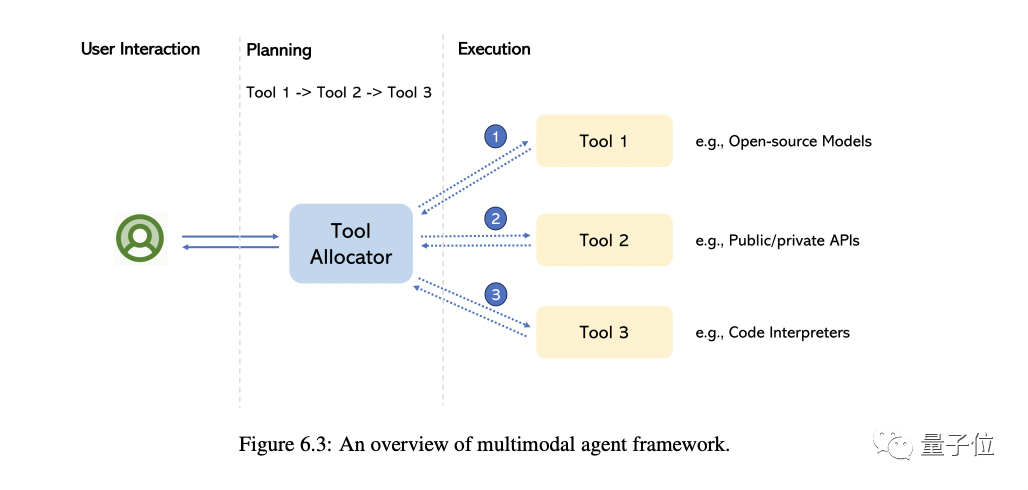
L'agent dit multimodal est une méthode qui connecte différents experts multimodaux avec LLM pour résoudre des problèmes complexes de compréhension multimodale.
Dans cette partie, l'auteur vous emmène principalement revenir sur la transformation de ce modèle et résume les différences fondamentales entre cette méthode et la méthode traditionnelle.
En prenant MM-REACT comme exemple, nous présenterons en détail le fonctionnement de cette méthode
Nous résumons en outre une approche globale sur la façon de construire des agents multimodaux, ainsi que ses capacités émergentes en matière de compréhension multimodale. Nous expliquons également comment étendre facilement cette fonctionnalité, y compris le dernier et le meilleur LLM et potentiellement des millions d'outils
Bien sûr, certains sujets de haut niveau sont également abordés à la fin, notamment comment améliorer/évaluer un agent multimodalité, diverses applications construites à partir de celui-ci, etc.
Il y a 7 auteurs dans ce rapport
L'initiateur et responsable global est Chunyuan Li.
Il est chercheur principal à Microsoft Redmond et est titulaire d'un doctorat de l'Université Duke. Ses récents intérêts de recherche portent sur la pré-formation à grande échelle en CV et en PNL.
Il était responsable de l'introduction d'ouverture et du résumé de clôture, ainsi que de la rédaction du chapitre "Grands modèles multimodaux formés à l'aide du LLM". Contenu réécrit : Il était responsable de la rédaction du début et de la fin de l'article, ainsi que du chapitre sur « Grands modèles multimodaux formés à l'aide du LLM »

Il y a 4 auteurs principaux :
a désormais rejoint Apple AI/ML et est responsable de la vision à grande échelle et de la recherche de modèles de base multimodaux. Auparavant, il était le chercheur principal de Microsoft Azure AI. Il est titulaire d'un baccalauréat et d'un doctorat de l'Université Duke.
Il est chercheur principal chez Microsoft. Il est diplômé de l'Université de Rochester et a reçu le prix de doctorat exceptionnel ACM SIGMM et d'autres distinctions. Il a étudié en tant que premier cycle à l'Université des sciences et technologies de Chine
Chercheur principal du Deep Learning Group de Microsoft Research Redmond. Doctorat du Georgia Institute of Technology.
Chercheuse au sein du Microsoft Cloud & AI Computer Vision Group, diplômée d'une maîtrise de l'Université Purdue.
Ils étaient respectivement responsables de la rédaction des quatre chapitres thématiques restants.
Adresse de révision : https://arxiv.org/abs/2309.10020
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment lier des données dans une liste déroulante
Comment lier des données dans une liste déroulante
 Comment obtenir le numéro d'entrée en Java
Comment obtenir le numéro d'entrée en Java
 Douyin ne peut pas télécharger et enregistrer des vidéos
Douyin ne peut pas télécharger et enregistrer des vidéos
 Quel est le rôle du serveur sip
Quel est le rôle du serveur sip
 lightbox.js
lightbox.js
 le bios ne peut pas détecter le disque SSD
le bios ne peut pas détecter le disque SSD
 Comment configurer WeChat pour qu'il exige mon consentement lorsque des personnes m'ajoutent à un groupe ?
Comment configurer WeChat pour qu'il exige mon consentement lorsque des personnes m'ajoutent à un groupe ?
 Mongodb et MySQL sont faciles à utiliser et recommandés
Mongodb et MySQL sont faciles à utiliser et recommandés








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



