


Le premier grand modèle open source de dialogue vocal bilingue chinois-anglais est là !
Ces derniers jours, un article sur un grand modèle multimodal de texte vocal est apparu sur arXiv, et le nom de la grande société de modèles de Kai-fu Lee, 01.ai - Zero One Thousand Things - est apparu parmi la signature entreprises.
 Picture
Picture
Cet article présente un modèle de conversation bilingue chinois-anglais disponible dans le commerce appelé LLaSM. Ce modèle prend non seulement en charge l'enregistrement et la saisie de texte, mais peut également réaliser la fonction de « double hybride »
 image
image
La recherche souligne que le « chat vocal » est un moyen d'interaction plus pratique et naturel entre l'IA et les personnes. , pas seulement via la saisie de texte
utilise de grands modèles, et certains internautes imaginent déjà le scénario « d'écrire du code en étant allongé et en parlant ».
 Pictures
Pictures
Cette recherche a été réalisée conjointement par LinkSoul.AI, l'Université de Pékin et Zero One Wish. Elle est désormais open source et peut être essayée directement dans Huugian
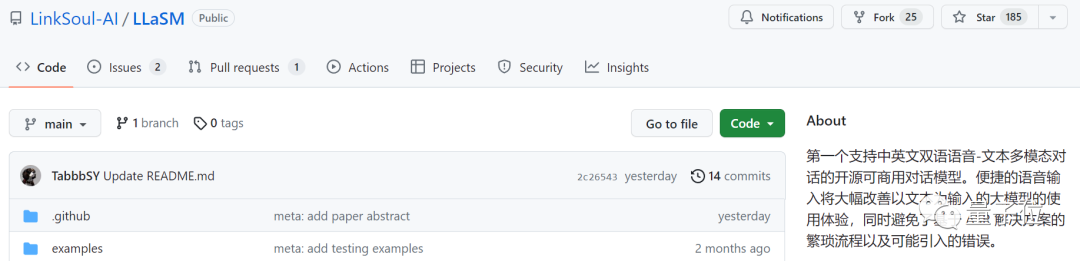 Pictures
Pictures
Jetons un coup d'œil à. à quel point il est efficace
Selon les chercheurs, LLaSM est le premier open source et open source disponible dans le commerce qui prend en charge le multimodal discours-texte bilingue chinois et anglais Modèle de dialogue.
Jetons donc un coup d’œil à sa saisie vocale de texte et à ses capacités bilingues en chinois et en anglais.
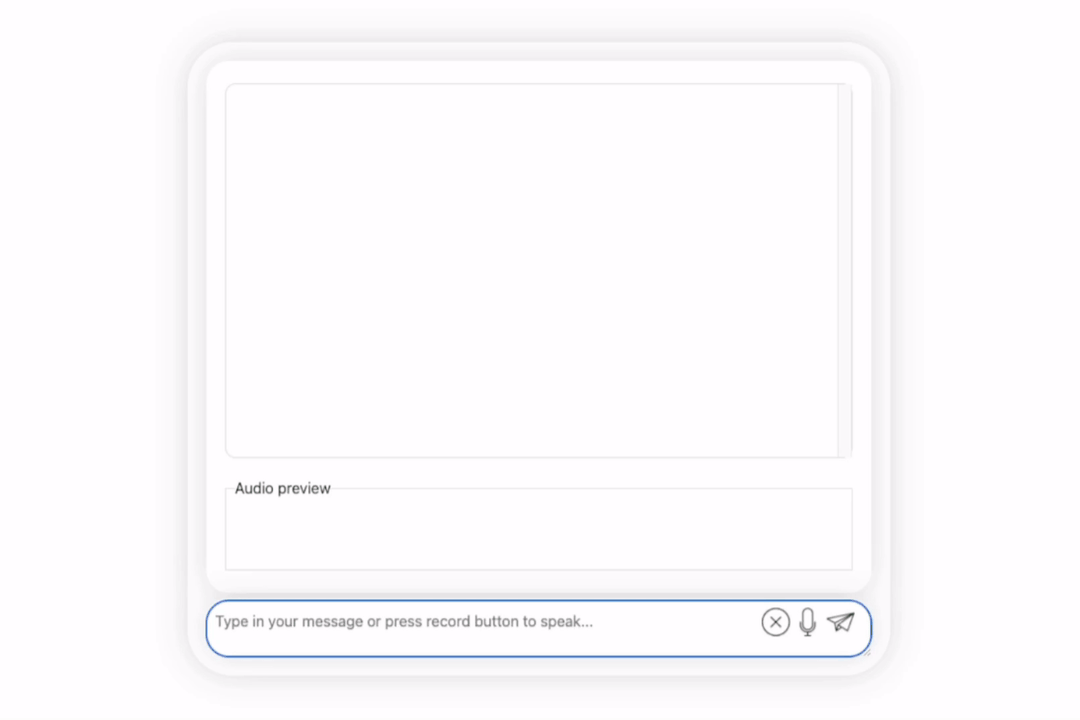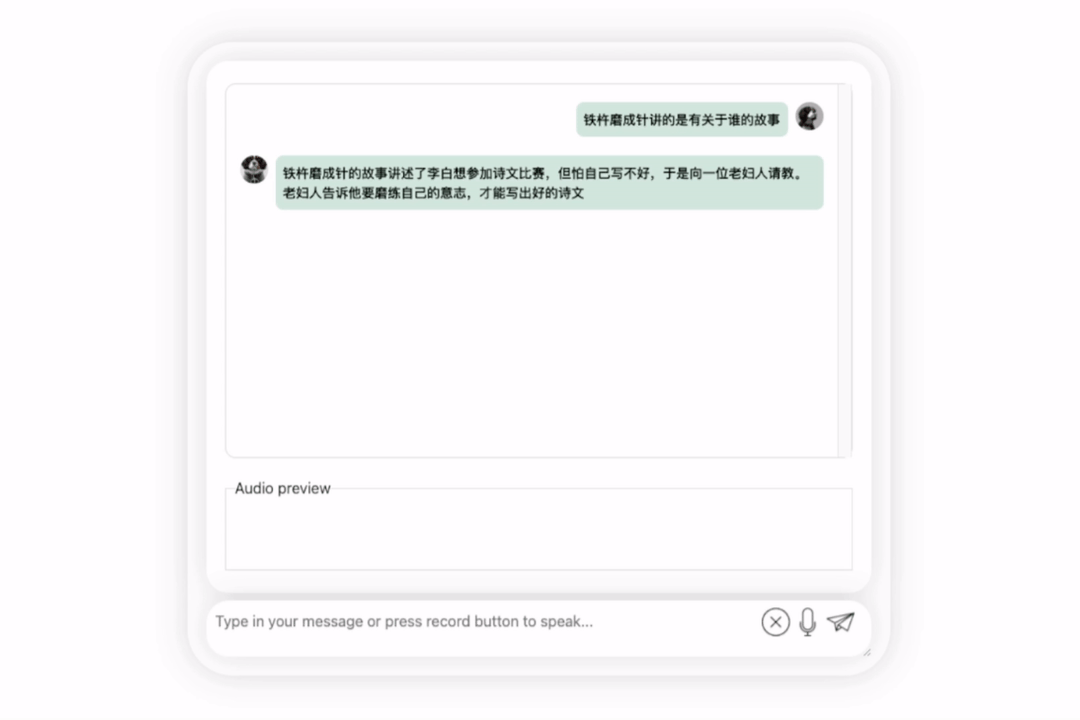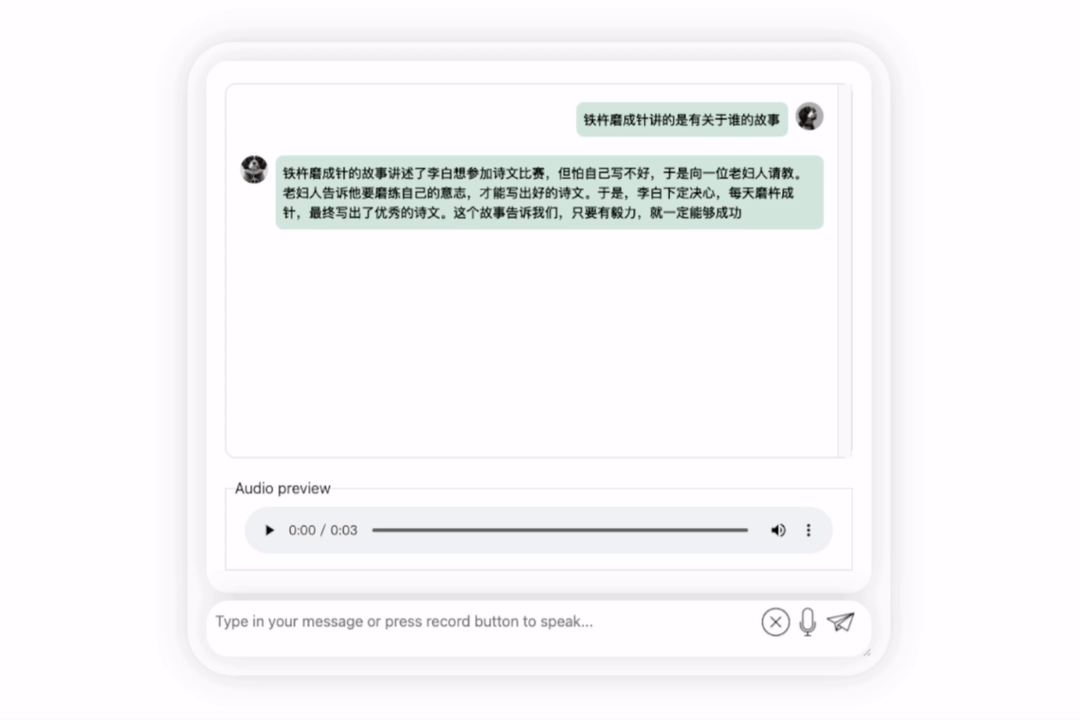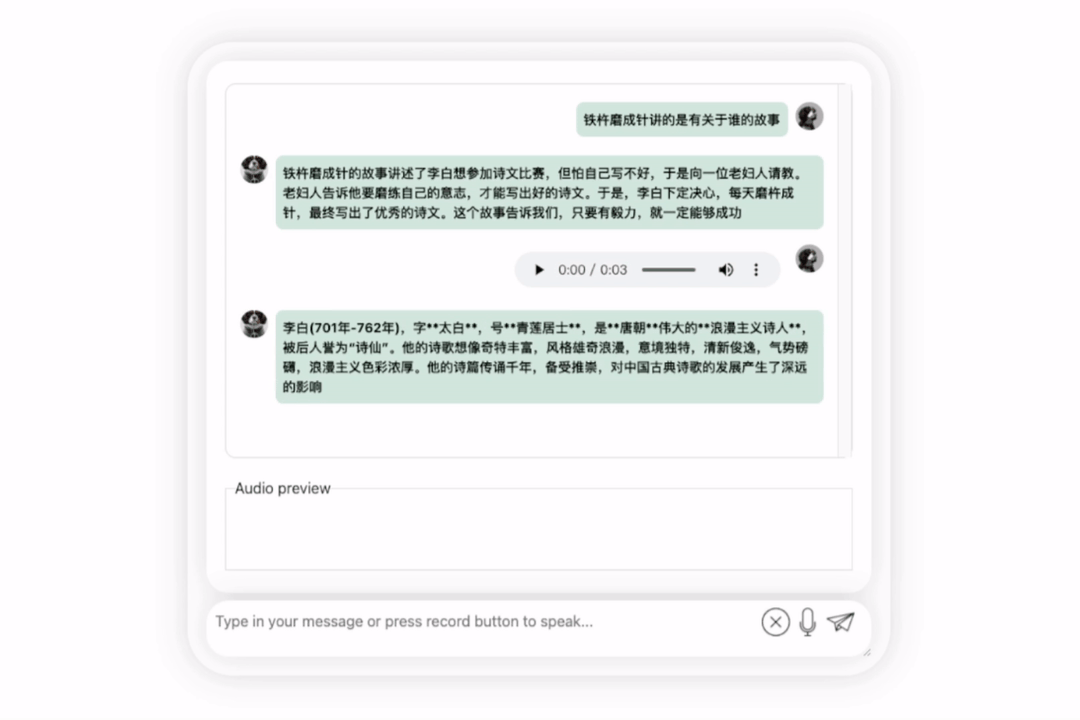
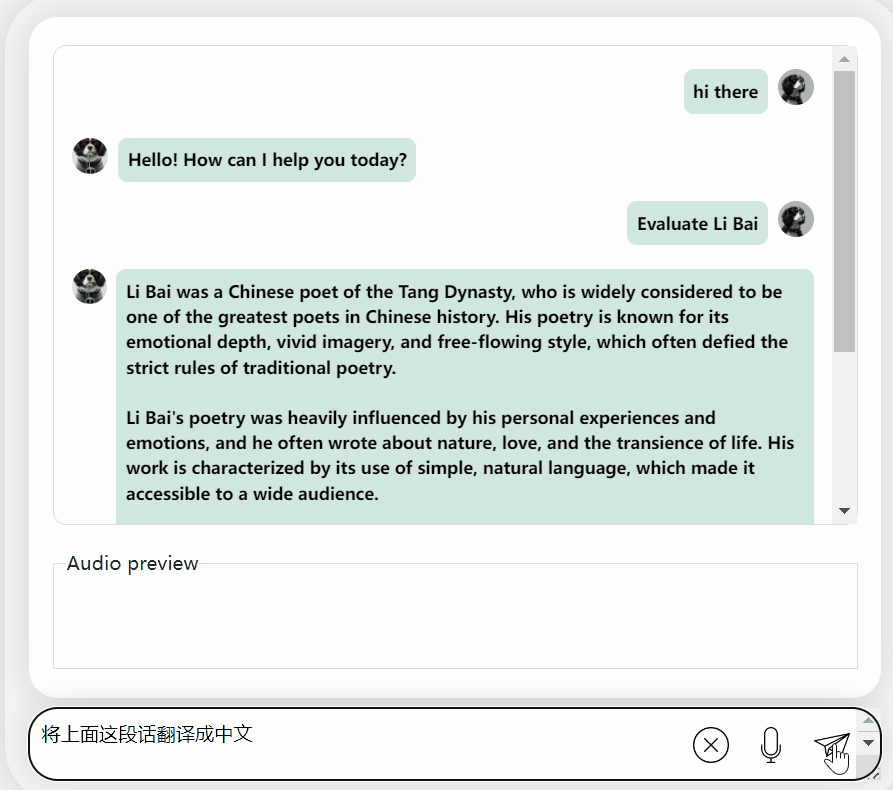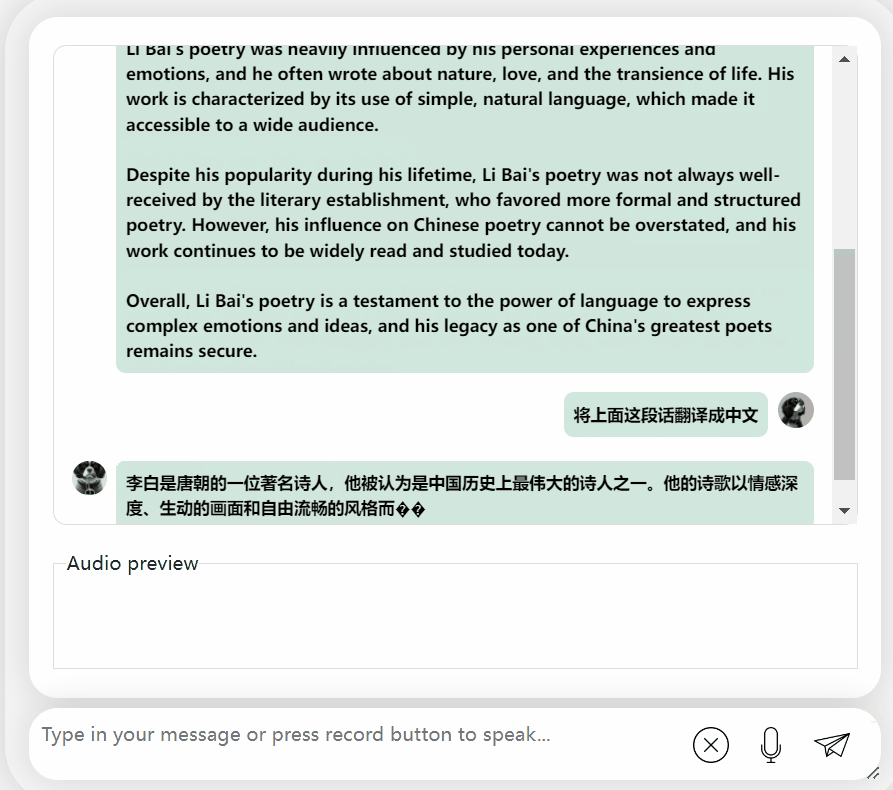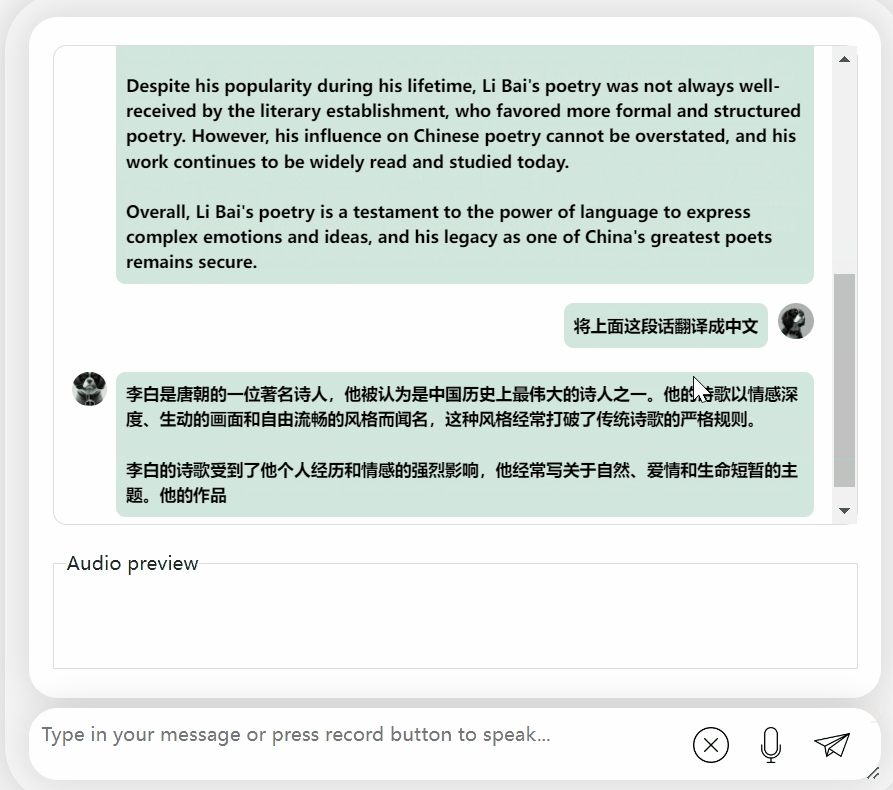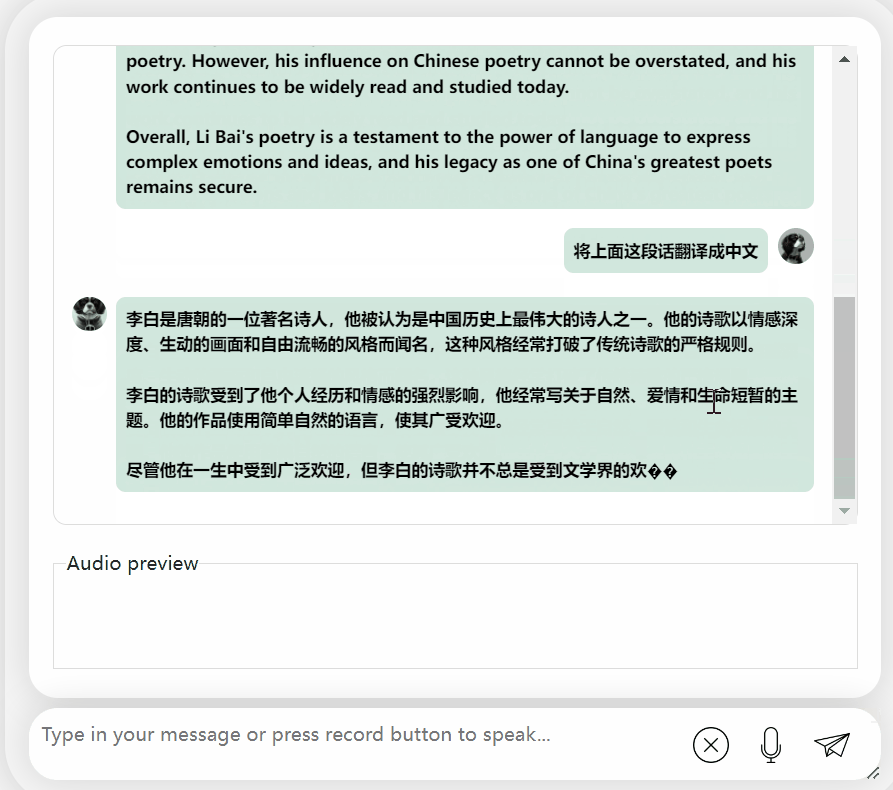
Tout d'abord, faisons une collision culturelle entre le chinois et l'anglais et évaluons Li Bai en anglais :
 Photos
Photos
C'est bon, et cela décrit correctement la dynastie de Li Bai. Si vous ne savez pas lire l'anglais, ce n'est pas un problème de le faire traduire directement en chinois :
 Images
Images
Dans le prochain exercice, essayons une question mixte chinois-anglais en ajoutant le mot « fried food » dans Phrases chinoises. L'effet de sortie du modèle est également assez bon :
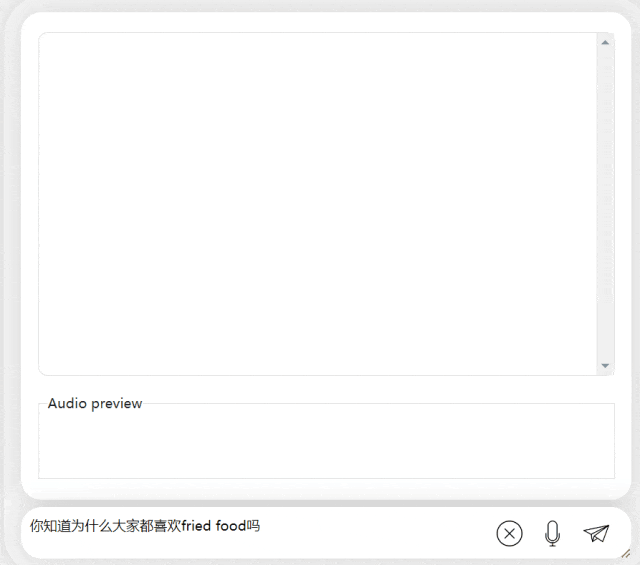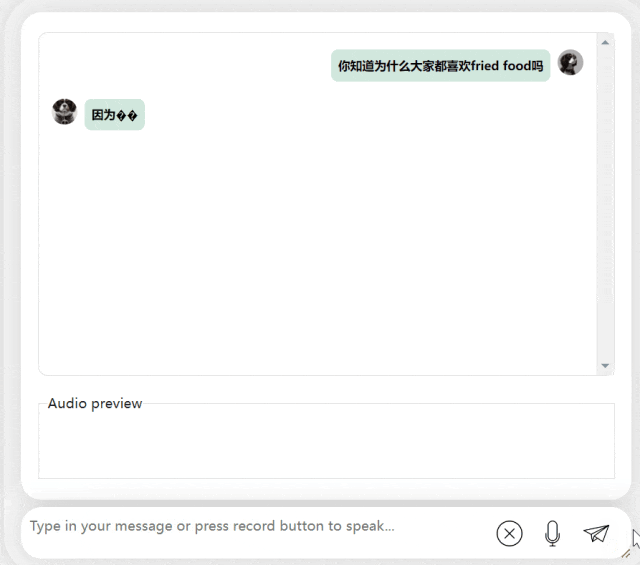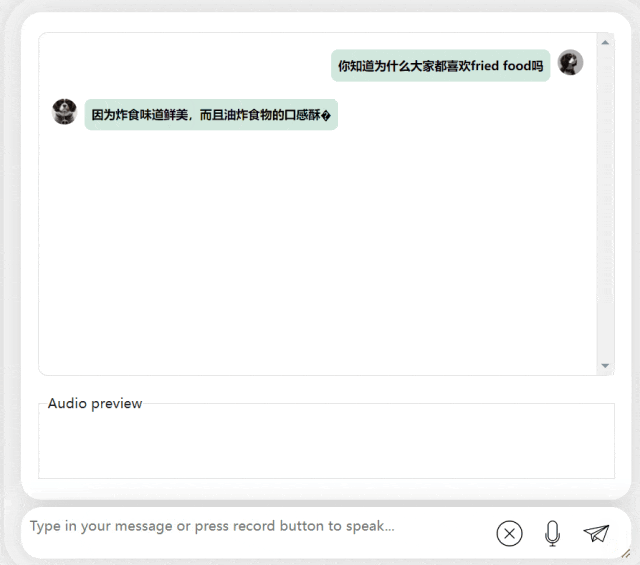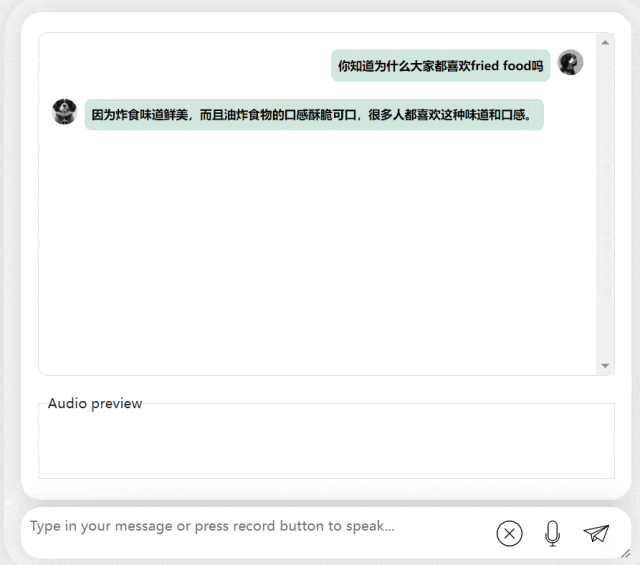 Photos
Photos
Essayons à nouveau le modèle et laissons-le faire une évaluation pour voir lequel est le meilleur, Li Bai ou Du Fu
On peut observer que après une période de réflexion , ce modèle donne une évaluation très objective et neutre, et possède également les connaissances de base et le bon sens nécessaires aux maquettes à grande échelle (tête de chien manuelle)
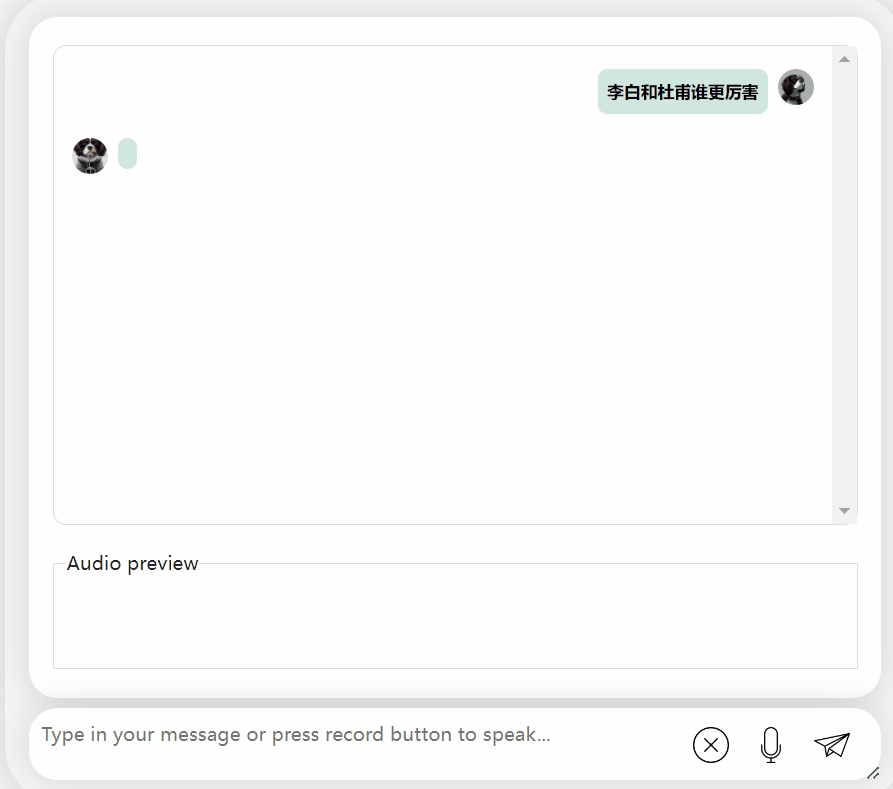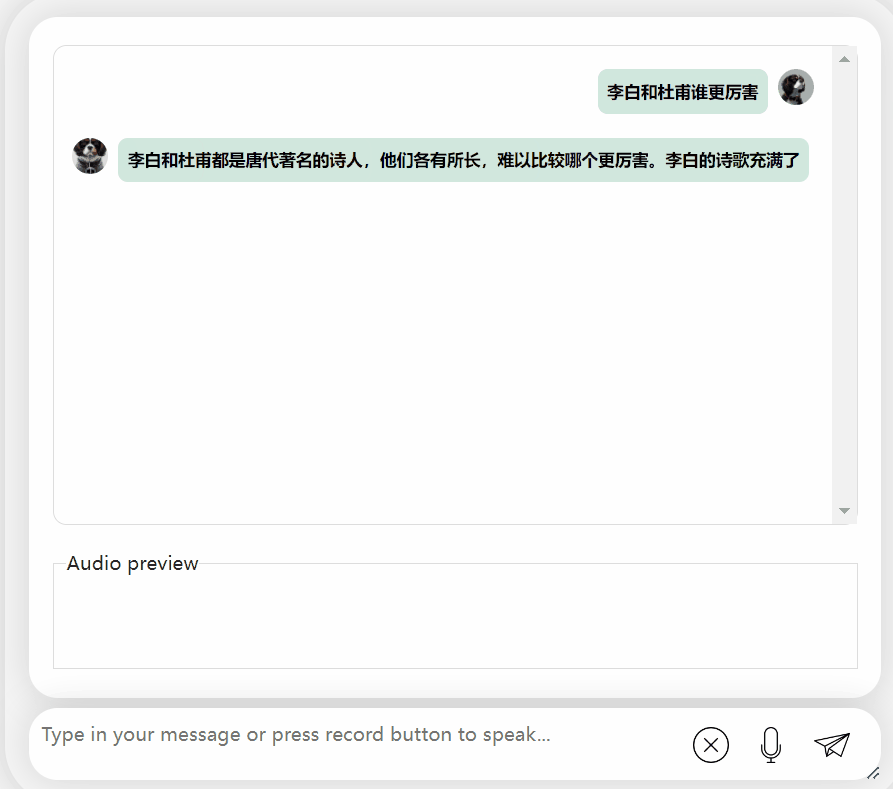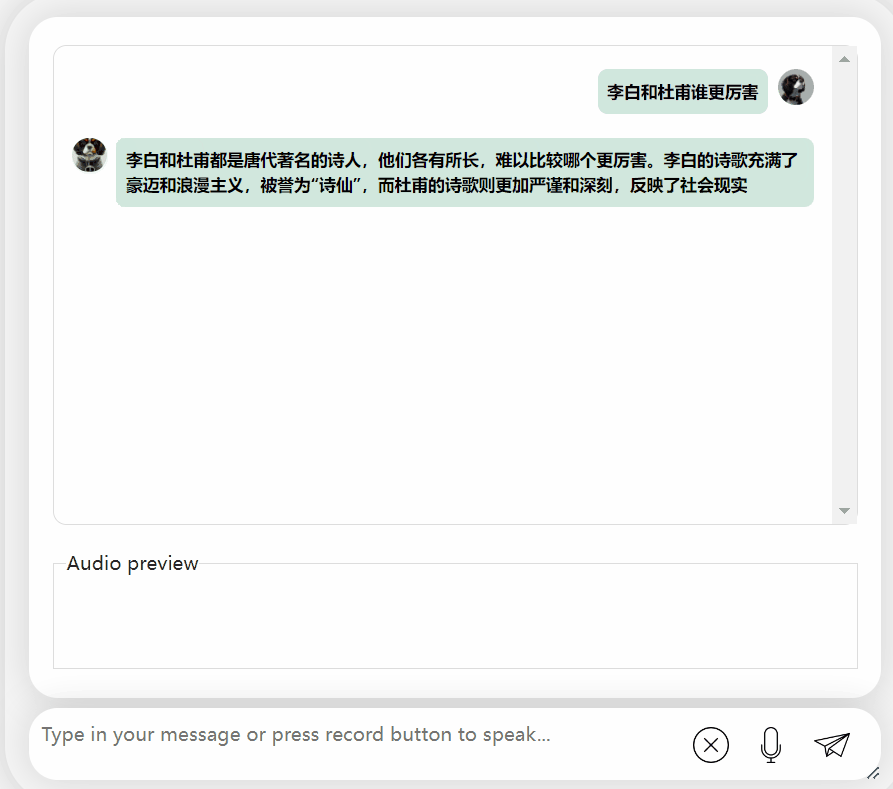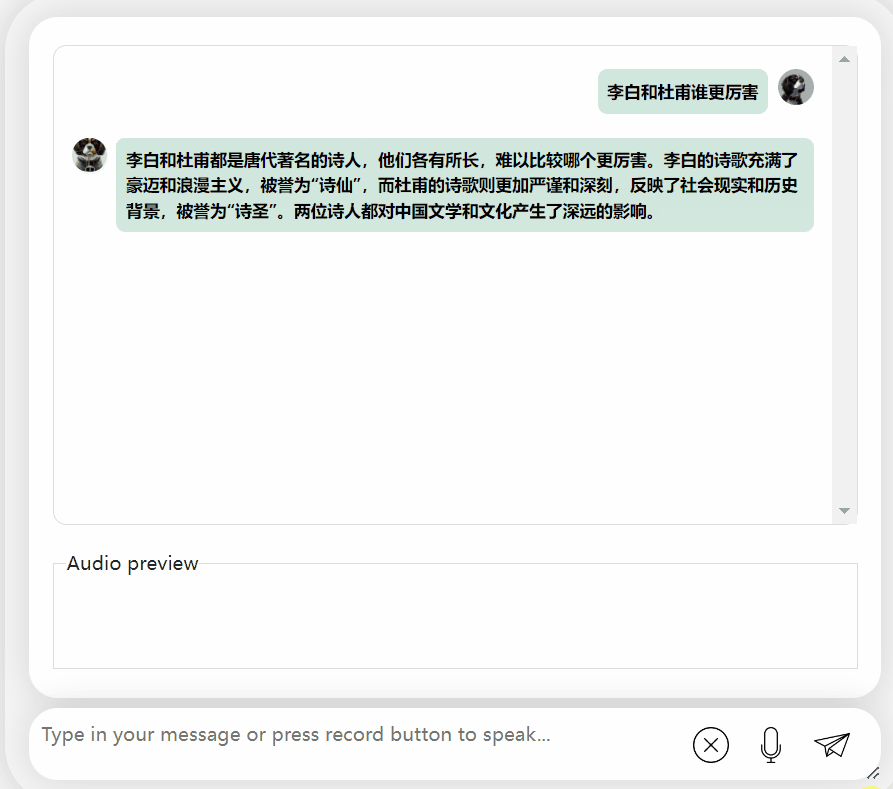 photos
photos
Bien sûr, cela peut être joué non seulement sur les ordinateurs, mais aussi sur les téléphones mobiles.
Nous essayons de saisir « me recommander une recette » à l'aide de la voix :
Vous pouvez voir que le modèle génère avec précision une recette de « fromage aubergine », mais je ne sais pas si elle a bon goût ou pas.
Cependant, lorsque nous l'avons essayé, nous avons également constaté que ce modèle présentait parfois des bugs.
Par exemple, parfois, il ne « comprend pas très bien la parole humaine ».
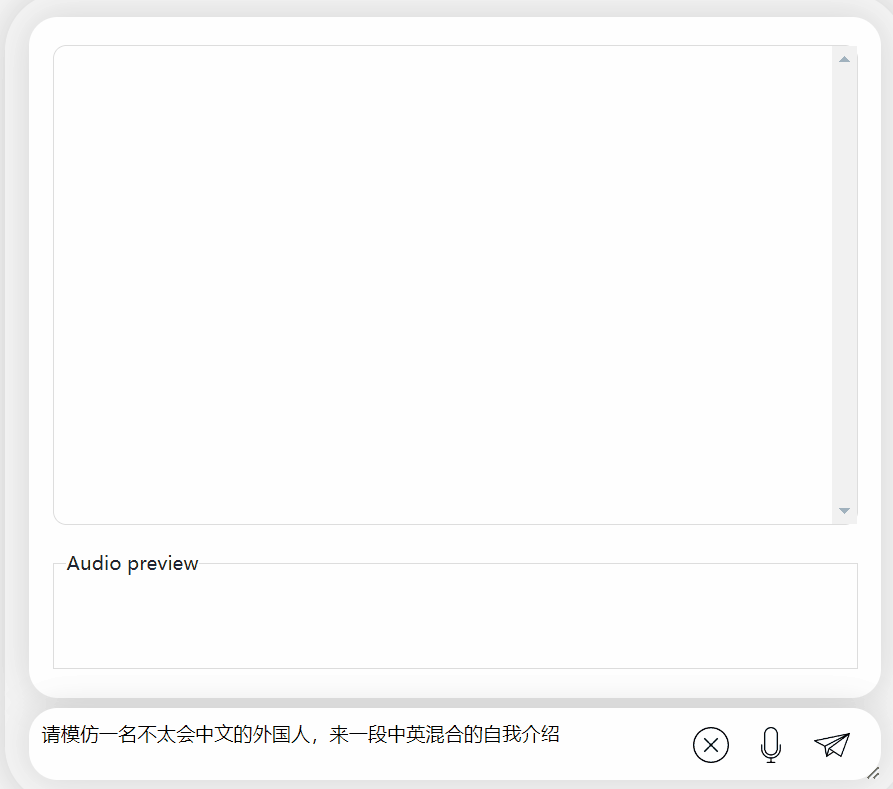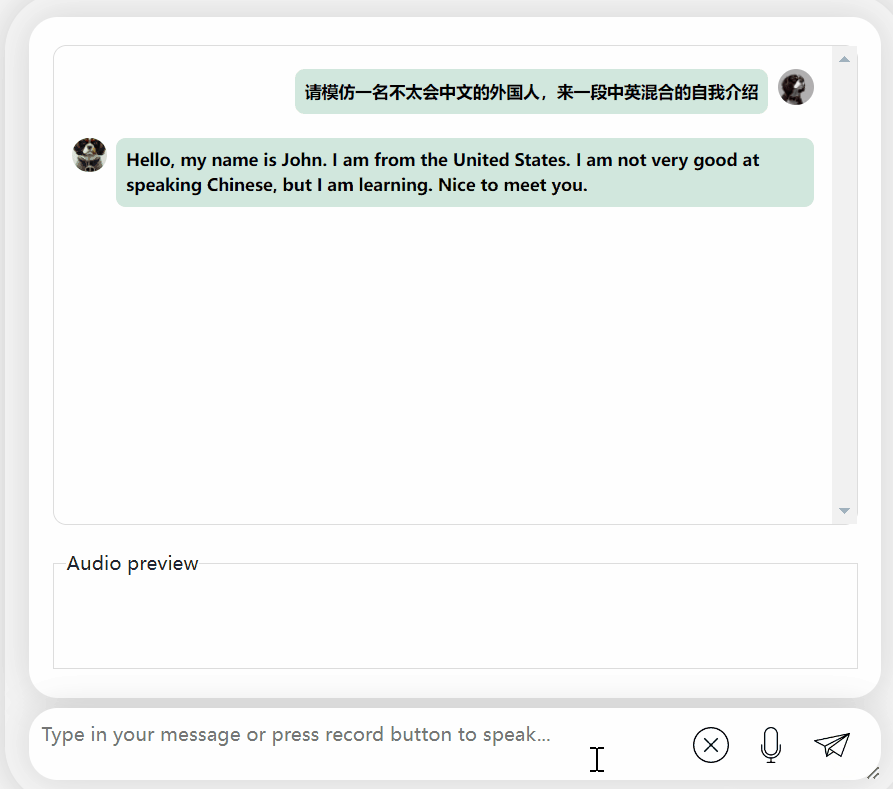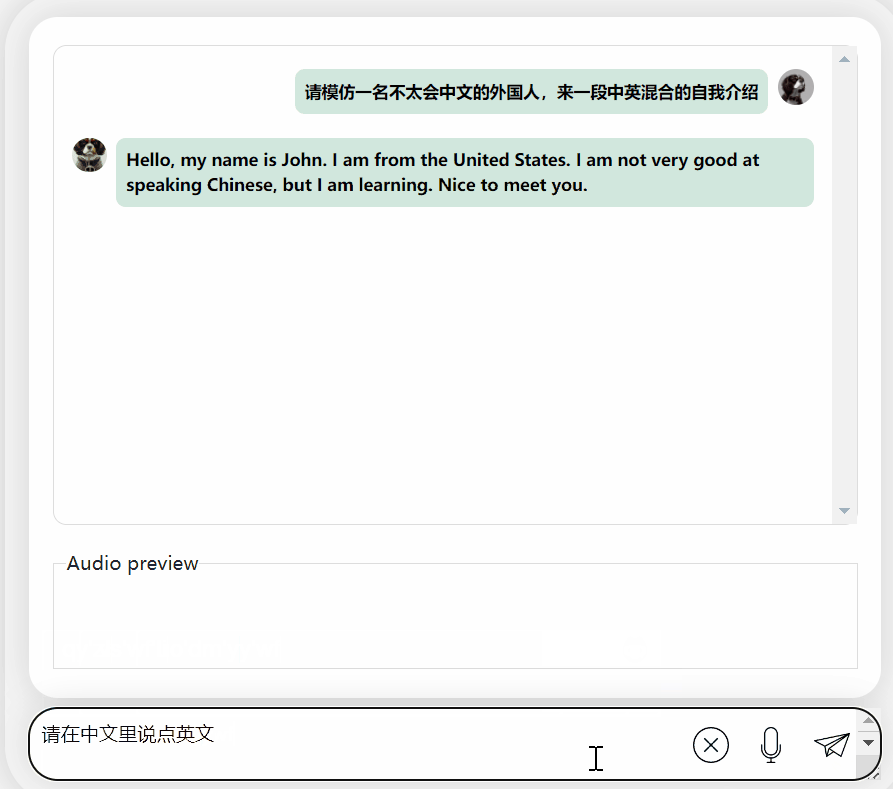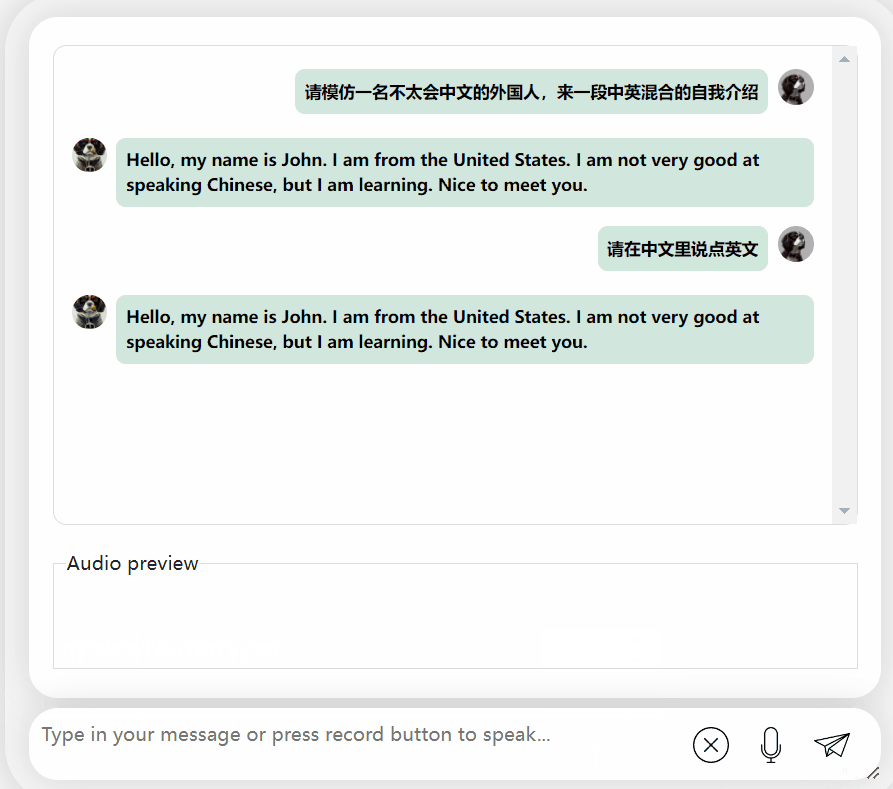
Demandé de produire un contenu mixte chinois et anglais, il fera semblant de ne pas comprendre et affichera en anglais :
 Photos
Photos
Lorsque un mélange de chinois et d'anglais lui a demandé d'écouter "Taylor Swift's Red", le modèle a eu un sérieux erreur et j'ai continué à afficher à plusieurs reprises la même phrase, même incapable de m'arrêter...
 Photos
Photos
Dans l'ensemble, face à des questions ou des demandes mélangées en chinois et en anglais, la capacité de sortie du modèle n'est toujours pas très bonne.
Mais s'il est séparé, sa capacité à exprimer le chinois et l'anglais est toujours bonne.
Alors, comment un tel modèle est-il mis en œuvre ?
À en juger par l'essai, LLaSM a deux fonctionnalités principales : l'une consiste à prendre en charge la saisie en chinois et en anglais, et l'autre est la double saisie vocale et textuelle.
Pour atteindre ces deux points, nous devons apporter quelques ajustements respectivement à l'architecture et aux données de formation.
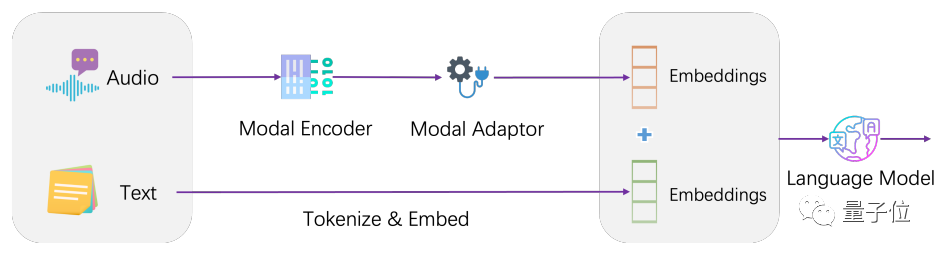
Architecturalement, LLaSM intègre le modèle de reconnaissance vocale actuel et le grand modèle de langage.
LLaSM se compose de trois parties, dont le modèle de reconnaissance vocale automatique Whisper, l'adaptateur modal et le grand modèle LLaMA.
Dans ce processus, Whisper est responsable de la réception de l'entrée vocale originale et de la sortie d'une représentation vectorielle des caractéristiques vocales. Le rôle de l'adaptateur modal est d'aligner les intégrations de parole et de texte. LLaMA est chargée de comprendre les instructions de saisie vocale et textuelle et de générer des réponses
 images
images
La formation du modèle est divisée en deux étapes. La première étape consiste à entraîner l'adaptateur de modalité, où l'encodeur et le grand modèle sont gelés, permettant au modèle d'apprendre l'alignement de la parole et du texte. La deuxième étape consiste à geler l'encodeur, à entraîner des adaptateurs modaux et de grands modèles pour améliorer les capacités de dialogue multimodal du modèle.
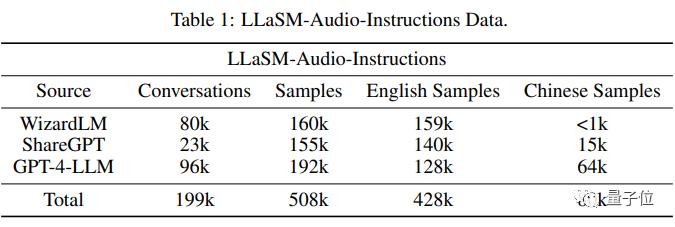
Sur les données d'entraînement, les chercheurs ont compilé une collection de 199 000 dialogues et 508 000 échantillons de texte vocal. L'ensemble de données LLaSM -Instructions audio.
Parmi les 508 000 échantillons de texte vocal, 80 000 sont des échantillons de discours chinois, tandis que 428 000 sont des échantillons de discours anglais
Les chercheurs se sont principalement basés sur des ensembles de données tels que WizardLM, ShareGPT et GPT-4-LLM, via la synthèse vocale La technologie génère des paquets vocaux pour ces ensembles de données tout en filtrant les conversations invalides.
 Photos
Photos
Il s'agit actuellement de la plus grande commande de texte vocal en chinois et en anglais suivant l'ensemble de données, mais elle est toujours en cours de tri. Selon les chercheurs, elle sera open source une fois triée.
Cependant, il n'existe actuellement aucune comparaison des effets de sortie de cet article avec d'autres modèles de parole ou de texte
Les auteurs de cet article proviennent de LinkSoul.AI, de l'Université de Pékin et de Zero One Thing
Les co-auteurs Yu Shu et Siwei Dong viennent tous deux de LinkSoul.AI et ont déjà travaillé à l'Institut de recherche sur l'intelligence artificielle Zhiyuan de Pékin.
LinkSoul.AI est une startup d'IA qui a déjà lancé le premier grand modèle open source Llama 2 en langue chinoise.
 Photos
Photos
En tant que grande société de mannequins appartenant à Kai-fu Lee, Zero One et One World ont également contribué à cette recherche. La page Hugging Face de l'auteur Wenhao Huang montre qu'il est diplômé de l'Université de Fudan.
 Photos
Photos
Adresse papier :
//m.sbmmt.com/link/47c917b09f2bc64b2916c0824c715923
Adresse de démonstration :
//m.sbmmt.com/link/ bcd 0049c35799cdf57d06eaf2eb3cff6
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment résoudre l'erreur d'identifiant MySQL invalide
Comment résoudre l'erreur d'identifiant MySQL invalide
 Comment supprimer des pages vierges dans Word sans affecter les autres formats
Comment supprimer des pages vierges dans Word sans affecter les autres formats
 js utilisation partagée
js utilisation partagée
 utilisation de la fonction stripslashes
utilisation de la fonction stripslashes
 Comment copier un tableau Excel pour lui donner la même taille que l'original
Comment copier un tableau Excel pour lui donner la même taille que l'original
 Introduction à l'utilisation de vscode
Introduction à l'utilisation de vscode
 Linux ajoute une méthode de source de mise à jour
Linux ajoute une méthode de source de mise à jour
 Utilisation de base de l'instruction insert
Utilisation de base de l'instruction insert








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



