



Tout d'abord, présentons notre perception du contenu multimodal.
Améliorez les capacités de compréhension du contenu, permettant au système publicitaire de mieux comprendre le contenu dans des scénarios segmentés.

Lors de l'amélioration des capacités de compréhension du contenu, vous rencontrerez de nombreux problèmes pratiques :
Qu'est-ce qu'une bonne représentation de base multimodale.
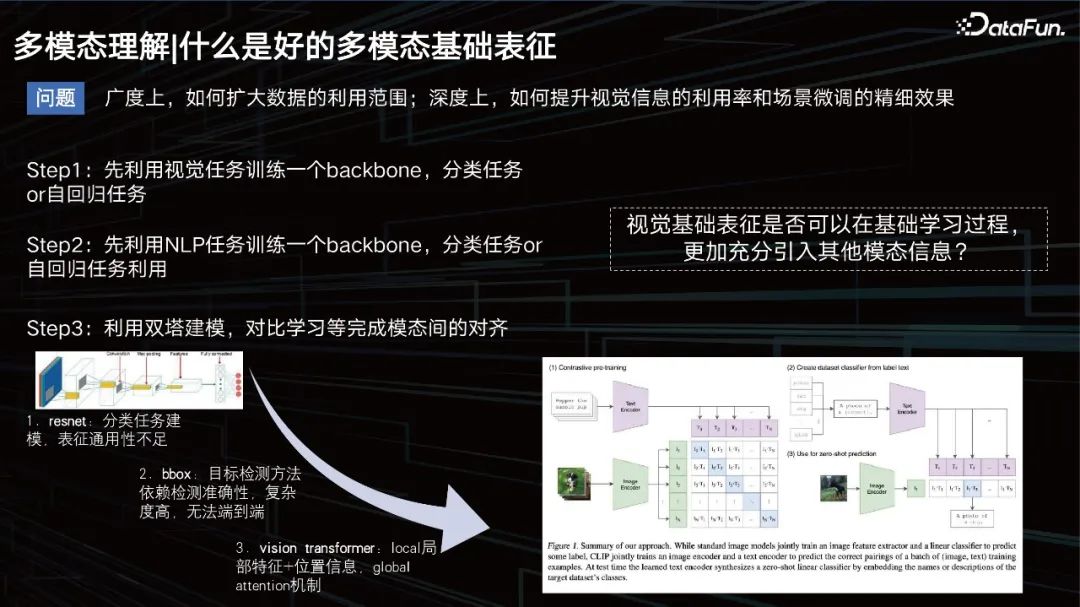
Qu'est-ce qu'une bonne représentation multimodale ?
En termes d'ampleur, le champ d'application des données doit être élargi, en termes de profondeur, les effets visuels doivent être améliorés, et en même temps, le réglage fin des données de la scène doit être assuré.
Avant, l'idée conventionnelle était de former un modèle pour apprendre la modalité des images, une tâche autorégressive, puis d'effectuer la tâche de texte, puis d'appliquer des modèles de tours jumelles pour fermer la relation modale entre les deux. À cette époque, la modélisation de texte était relativement simple et tout le monde étudiait davantage comment modéliser la vision. Cela a commencé avec CNN, et a ensuite inclus certaines méthodes basées sur la détection de cibles pour améliorer la représentation visuelle, comme la méthode bbox. Cependant, cette méthode a des capacités de détection limitées et est trop lourde, ce qui n'est pas propice à la formation de données à grande échelle.
Vers 2020 et 2021, la méthode VIT est devenue courante. L'un des modèles les plus célèbres que je dois mentionner ici est CLIP, un modèle publié par OpenAI en 2020, basé sur l'architecture à deux tours pour la représentation textuelle et visuelle. Utilisez ensuite le cosinus pour réduire la distance entre les deux. Ce modèle est très performant en récupération, mais est légèrement moins performant dans certaines tâches qui nécessitent un raisonnement logique telles que les tâches VQA.
Représentation d'apprentissage : Améliorez la capacité de perception de base du langage naturel à la vision.
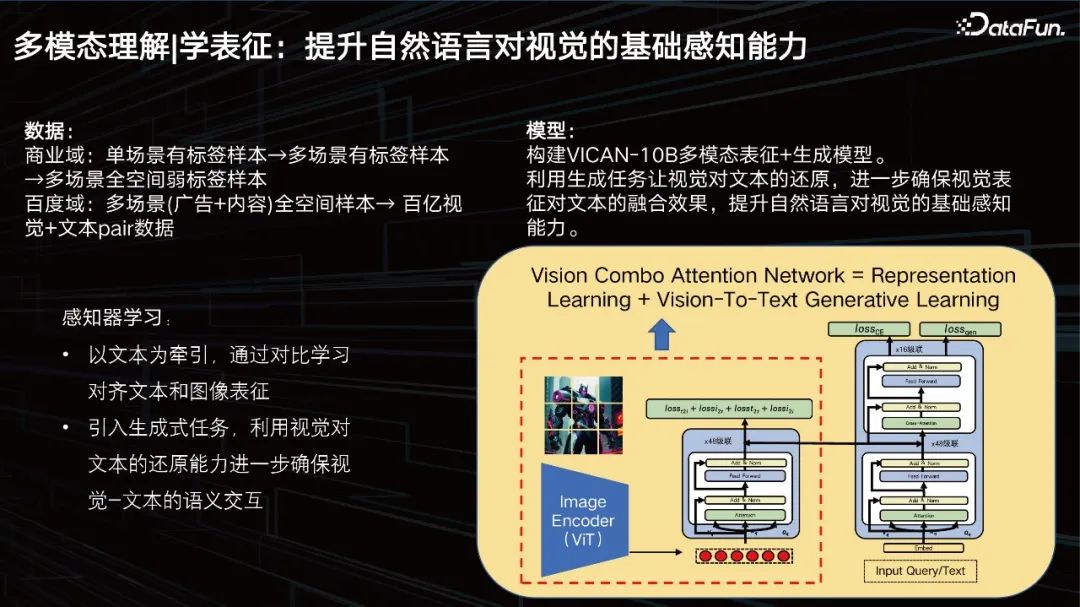
Notre objectif est d'améliorer la perception visuelle de base du langage naturel. En termes de données, notre domaine commercial contient des milliards de données, mais ce n'est toujours pas suffisant. Nous devons continuer à nous développer, à introduire les données antérieures du domaine commercial, à les nettoyer et à les trier. Un ensemble de formation de plusieurs dizaines de milliards a été construit.
Nous avons construit le modèle de représentation + génération multimodale VICAN-12B, en utilisant la tâche de génération pour permettre à la vision de restaurer le texte, garantissant ainsi l'effet de fusion de la représentation visuelle sur le texte et améliorant la perception de base du langage naturel sur la vision. . L'image ci-dessus montre la structure globale du modèle. Vous pouvez voir qu'il s'agit d'une structure composite de tours jumelles + tour unique. Parce que la première chose à résoudre est une tâche de récupération d’images à grande échelle. La partie dans l'encadré de gauche est ce que nous appelons le perceptron visuel, qui est une structure ViT avec une échelle de 2 milliards de paramètres. Le côté droit peut être visualisé en deux couches. La partie inférieure est une pile de transformateurs de texte pour la récupération et la partie supérieure est pour la génération. Le modèle est divisé en trois tâches, l'une est une tâche de génération, l'autre est une tâche de classification et l'autre est une tâche de comparaison d'images. Le modèle est formé sur la base de ces trois objectifs différents, il a donc obtenu des résultats relativement bons, mais nous. l’optimisera davantage.
Un ensemble de solutions de représentation globale multi-scénarios efficaces, unifiées et transférables.

Combiné aux données de scénarios commerciaux, le modèle LLM est introduit pour améliorer les capacités de compréhension du modèle. Le modèle CV est le perceptron et le modèle LLM est le compréhenseur. Notre approche consiste à transférer les caractéristiques visuelles en conséquence, car comme mentionné tout à l'heure, la représentation est multimodale et le grand modèle est basé sur du texte. Il nous suffit de l'adapter au grand modèle de notre Wenxin LLM, nous devons donc utiliser l'attention Combo pour effectuer la fusion des fonctionnalités correspondantes. Nous devons conserver les capacités de raisonnement logique du grand modèle, c'est pourquoi nous essayons de ne pas laisser le grand modèle seul et d'ajouter uniquement des données de retour d'expérience sur les scénarios commerciaux pour promouvoir l'intégration de fonctionnalités visuelles dans le grand modèle. Nous pouvons utiliser quelques tirs pour soutenir la tâche. Les tâches principales incluent :
Maintenant, concentrons-nous sur le réglage fin basé sur la scène.
Scène de récupération visuelle, réglage fin des tours jumelles basé sur la représentation de base.
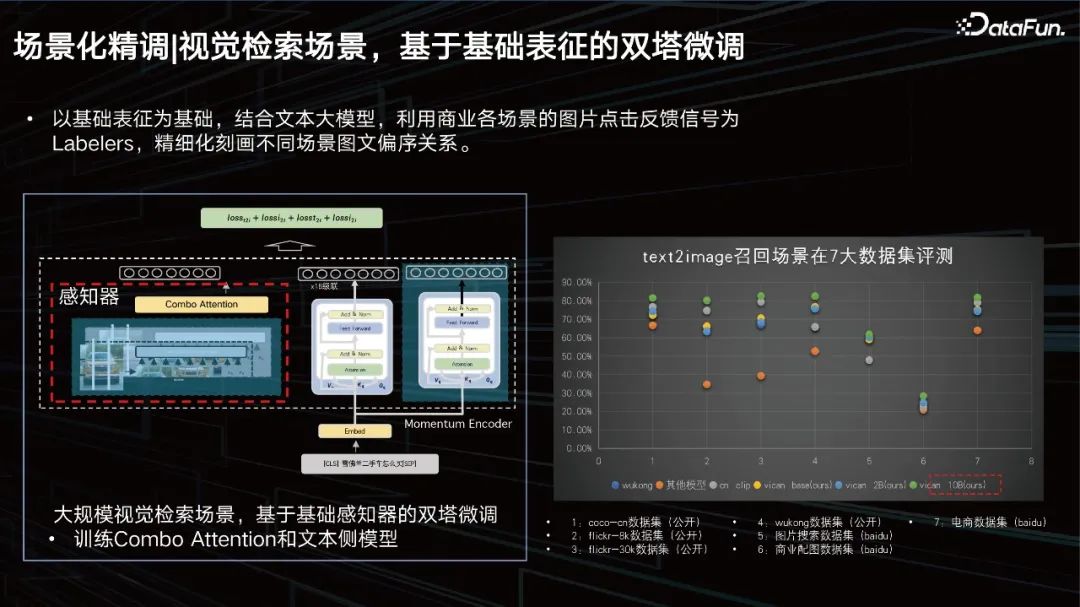
Sur la base de la représentation de base, combinée au grand modèle de texte, les signaux de retour de clic d'image de diverses scènes commerciales sont utilisés comme étiqueteurs pour affiner la relation d'ordre partiel entre les images et les textes dans différentes scènes. Nous avons mené des évaluations sur 7 ensembles de données majeurs, et tous peuvent atteindre des résultats SOTA.
Le scénario de tri, inspiré de la segmentation de texte, quantifie la sémantique des fonctionnalités multimodales.
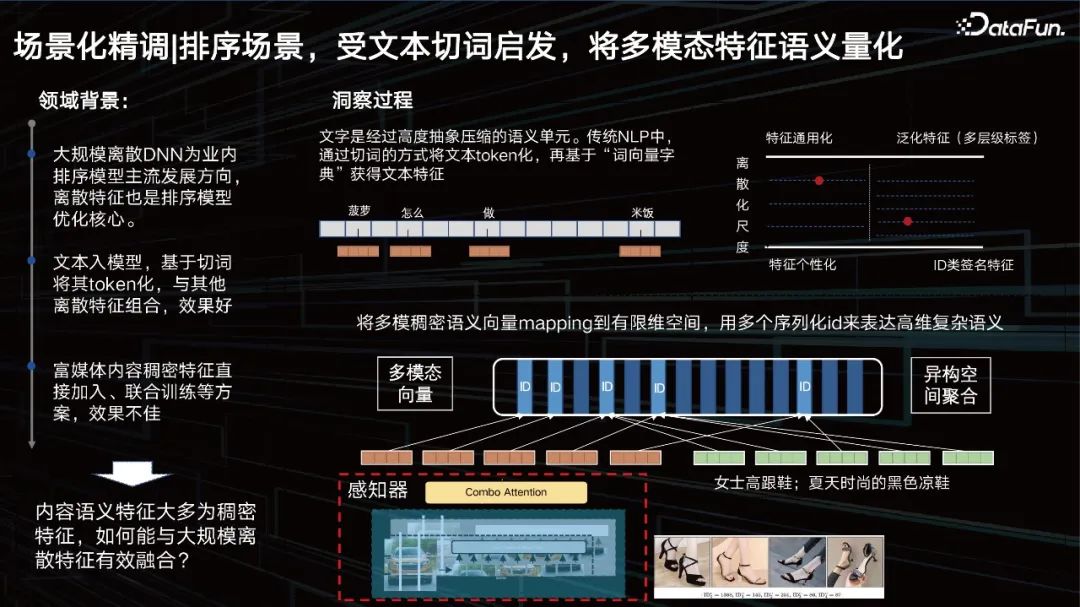
En plus de la représentation, un autre problème est de savoir comment améliorer l'effet visuel dans la scène de tri. Examinons d'abord le contexte du domaine. Le DNN discret à grande échelle est la principale direction de développement des modèles de classement dans l'industrie, et les fonctionnalités discrètes sont également au cœur de l'optimisation des modèles de classement. Le texte est saisi dans le modèle, tokenisé sur la base de la segmentation des mots et combiné avec d'autres fonctionnalités discrètes pour obtenir de bons résultats. Quant à la vision, nous espérons également la symboliser.
La fonctionnalité de type ID est en fait une fonctionnalité très personnalisée, mais à mesure que la fonctionnalité généralisée devient plus polyvalente, sa précision de caractérisation peut se détériorer. Nous devons ajuster dynamiquement ce point d’équilibre grâce aux données et aux tâches. C'est-à-dire que nous espérons trouver une échelle la plus pertinente pour les données, pour « segmenter » les fonctionnalités en un identifiant en conséquence et pour segmenter les fonctionnalités multimodales comme le texte. Par conséquent, nous avons proposé une méthode d’apprentissage de quantification de contenu multi-échelle et multi-niveau pour résoudre ce problème.
Tri des scènes, fusion de fonctionnalités multimodales et de modèles MmDict.
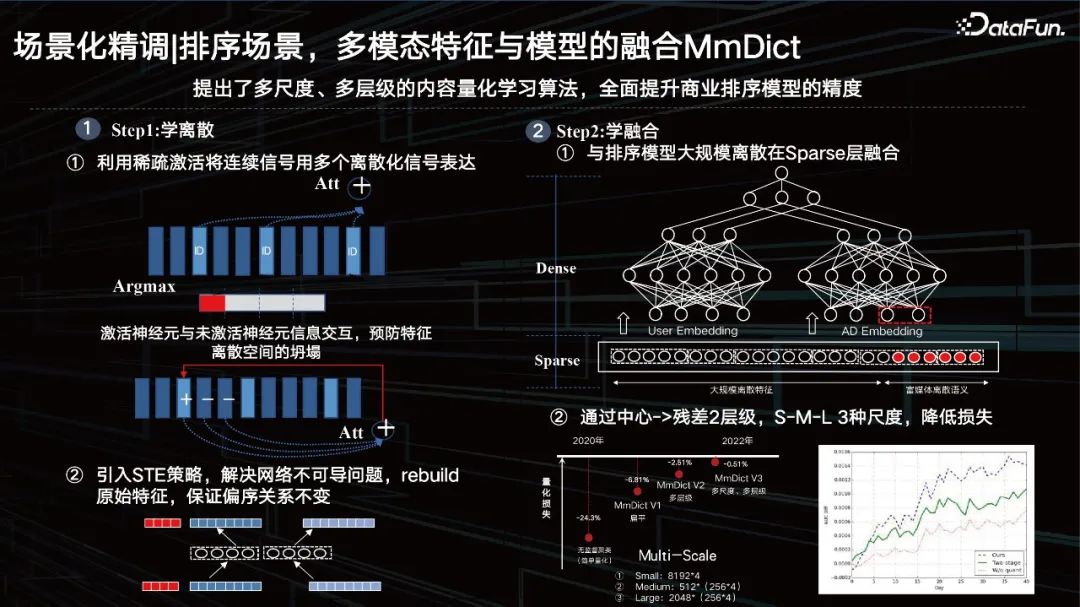
Principalement divisée en deux étapes, la première étape consiste à apprendre la discrétion, et la deuxième étape consiste à apprendre la fusion.
① Utilisez l'activation clairsemée pour exprimer des signaux continus avec plusieurs signaux discrétisés ; c'est-à-dire utilisez l'activation clairsemée pour segmenter les fonctionnalités denses, puis activez les identifiants dans le livre de codes multimodal correspondant, mais il y a en fait, seule l'opération argmax, ce qui entraînera des problèmes non différenciables. En même temps, afin d'éviter l'effondrement de l'espace des fonctionnalités, une interaction d'informations entre les neurones activés et les neurones inactifs est ajoutée.
② Présenter la stratégie STE pour résoudre le problème de la non-différentiabilité du réseau, reconstruire les fonctionnalités d'origine et garantir que la relation d'ordre partiel reste inchangée.
Utilisez la méthode encodeur-décodeur pour quantifier les caractéristiques denses en séquence, puis restaurez les caractéristiques quantifiées de la manière correcte. Il est nécessaire de s'assurer que sa relation d'ordre partiel reste inchangée avant et après la restauration, et il peut presque contrôler la perte quantitative de fonctionnalités sur des tâches spécifiques à moins de 1 %. Un tel identifiant peut non seulement personnaliser la distribution actuelle des données, mais également. ont des propriétés de généralisation.
① et fusion discrète à grande échelle du modèle de tri au niveau de la couche Sparse.
Ensuite, la réutilisation du calque caché que nous venons de mentionner est placée directement sur le dessus, mais l'effet est en réalité moyen. Si vous l'identifiez, le quantifiez et le fusionnez avec la couche de fonctionnalités clairsemée et d'autres types de fonctionnalités, cela aura un meilleur effet.
② Réduisez la perte par le centre -> résiduel 2 niveaux et S-M-L 3 échelles.
Bien sûr, nous utilisons également des méthodes résiduelles et multi-échelles. À partir de 2020, nous avons progressivement réduit la perte de quantification, atteignant moins d'un point l'année dernière, de sorte qu'après que le grand modèle ait extrait les caractéristiques, nous puissions utiliser cette méthode de quantification apprenable pour caractériser le contenu visuel, avec une association sémantique ID. Les caractéristiques sont en fait très adapté à nos systèmes métiers actuels, y compris une telle méthode de recherche exploratoire sur l'ID du système de recommandation.

Inspiration : Compréhension de l'IA (contenu et compréhension des utilisateurs). L’IA peut-elle nous aider à trouver quel type d’invite est bon ? De la connaissance matérielle à la direction créative.

Graphique de connaissances, comme la vente de voitures, de voitures Quels éléments commerciaux doit-il être inclus ? La marque seule ne suffit pas. Les annonceurs espèrent également disposer d'un système de connaissances complet.
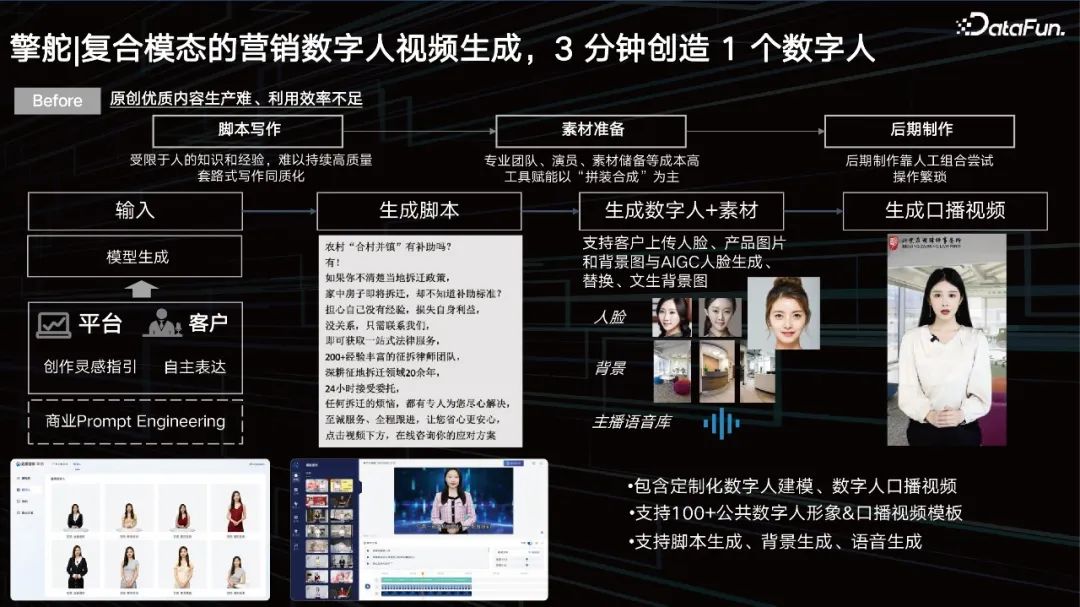
Écriture de scénarios : limité par les connaissances et l'expérience humaines, il est difficile de maintenir une écriture de haute qualité, et l'homogénéité est un problème sérieux.
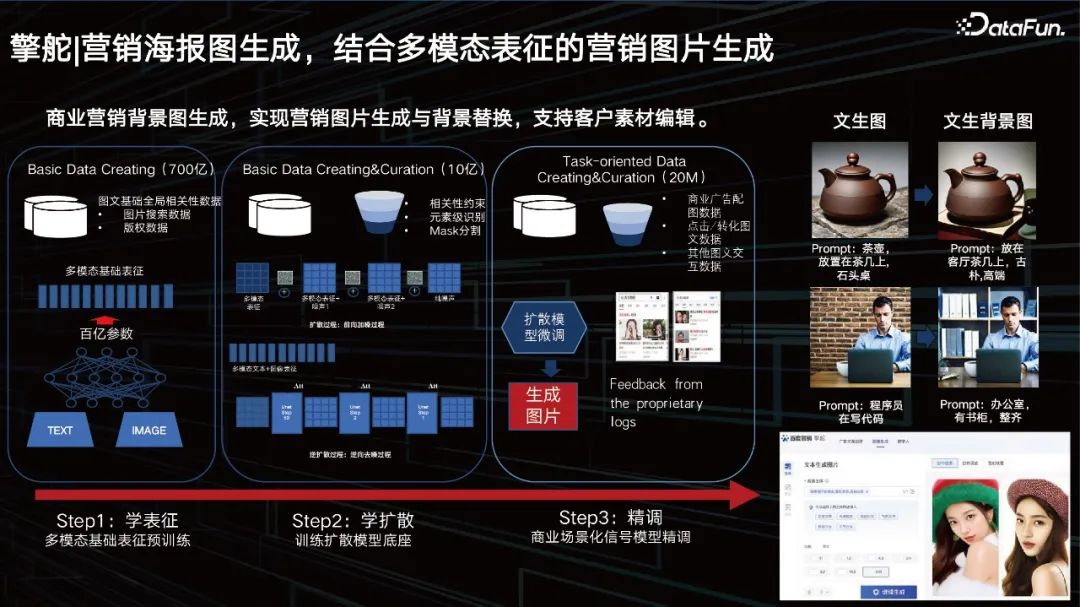
Le grand modèle peut également aider les entreprises à générer des affiches marketing et à remplacer les arrière-plans de produits. Nous disposons déjà de dizaines de milliards de représentations multimodales. La couche intermédiaire est une diffusion que nous avons apprise sur la base de bonnes représentations dynamiques. Après une formation avec le Big Data, les clients veulent aussi quelque chose de particulièrement personnalisé, nous devons donc également ajouter quelques méthodes de réglage fin. Nous fournissons une solution pour aider les clients à affiner le réglage, une solution de chargement dynamique de petits paramètres pour les grands modèles, qui est également une solution courante dans l'industrie. Tout d'abord, nous offrons aux clients la possibilité de générer des images. Les clients peuvent modifier l'arrière-plan derrière l'image via une modification ou une invite. 4. Génération d'images d'affiches marketing, génération d'images marketing combinée à une représentation multimodale
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 le démarrage d'Apache a échoué
le démarrage d'Apache a échoué
 utilisation de la fonction memset
utilisation de la fonction memset
 Comment modifier le fichier hosts
Comment modifier le fichier hosts
 Introduction au contenu principal du travail du backend
Introduction au contenu principal du travail du backend
 ASUS x402c
ASUS x402c
 Quelle est la différence entre ibatis et mybatis
Quelle est la différence entre ibatis et mybatis
 Comment aligner les zones de texte en HTML
Comment aligner les zones de texte en HTML
 Analyse coût-efficacité de l'apprentissage de Python, Java et C++
Analyse coût-efficacité de l'apprentissage de Python, Java et C++








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



