

Quand il s'agit de Bilibili, la première impression est la vidéo. Je crois que beaucoup d'amis, comme moi, veulent utiliser la technologie des robots d'exploration Web pour obtenir la vidéo de Bilibili. est en fait Ce n'est pas si facile à obtenir, off à la station B pour obtenir la vidéo, a été introduit avant via la bibliothèque you-get, les amis intéressés peuvent lire ceci article :You-Get est tellement fort ! .经 经
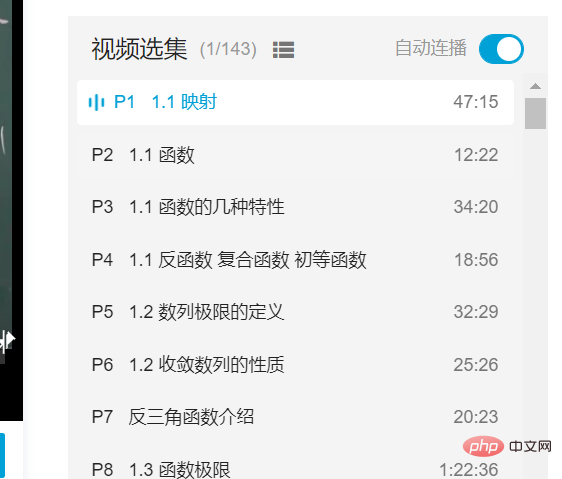
Bien sûrces champs de sélectionpeuvent également être vus à l'œil nu. Juste si vous le mettez en œuvre via un programme, ce n'est peut-être pas aussi simple que vous le pensez. Le but de cet article est donc d'obtenir des sélections vidéo grâce à la technologie de robot d'exploration Web Python et basée sur la bibliothèque Selenium.
La bibliothèque que nous utilisons dans cet article est Selenium, qui est une bibliothèque utilisée pour simuler la connexion des utilisateurs. Bien qu'elle semble lente, dans le domaine des robots d'exploration Web, cette bibliothèque est. encore beaucoup utilisé, et il a été essayé et testé pour simuler la connexion et obtenir des données. Vous trouverez ci-dessous tout le code pour implémenter la collection de sélection de vidéos. Vous êtes invités à le pratiquer vous-même.
# coding: utf-8
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
class Item:
page_num = ""
part = ""
duration = ""
def __init__(self, page_num, part, duration):
self.page_num = page_num
self.part = part
self.duration = duration
def get_second(self):
str_list = self.duration.split(":")
sum = 0
for i, item in enumerate(str_list):
sum += pow(60, len(str_list) - i - 1) * int(item)
return sum
def get_bilili_page_items(url):
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 设置无界面
options.add_experimental_option('excludeSwitches', ['enable-automation'])
# options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2,
# "profile.managed_default_content_settings.flash": 0})
browser = webdriver.Chrome(options=options)
# browser = webdriver.PhantomJS()
print("正在打开网页...")
browser.get(url)
print("等待网页响应...")
# 需要等一下,直到页面加载完成
wait = WebDriverWait(browser, 10)
wait.until(EC.visibility_of_element_located((By.XPATH, '//*[@class="list-box"]/li/a')))
print("正在获取网页数据...")
list = browser.find_elements_by_xpath('//*[@class="list-box"]/li')
# print(list)
itemList = []
second_sum = 0
# 2.循环遍历出每一条搜索结果的标题
for t in list:
# print("t text:",t.text)
element = t.find_element_by_tag_name('a')
# print("a text:",element.text)
arr = element.text.split('\n')
print(" ".join(arr))
item = Item(arr[0], arr[1], arr[2])
second_sum += item.get_second()
itemList.append(item)
print("总数量:", len(itemList))
# browser.page_source
print("总时长/分钟:", round(second_sum / 60, 2))
print("总时长/小时:", round(second_sum / 3600.0, 2))
browser.close()
return itemList
get_bilili_page_items("https://www.bilibili.com/video/BV1Eb411u7Fw")Le sélecteur utilisé ici est XPath, et l'exemple vidéo est la version Tongji "Mathématiques avancées" de la sélection vidéo complète d'enseignement (Teacher Song Hao) de la station B. Si vous souhaitez récupérer autres vidéos Pour la sélection, il vous suffit de modifier le lien URL dans la dernière ligne du code ci-dessus.
在运行过程中小伙伴们应该会经常遇到这个问题,如下图所示。
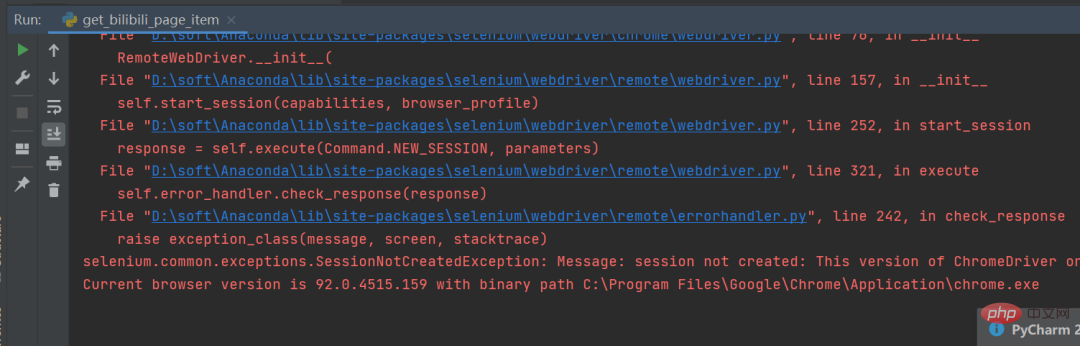
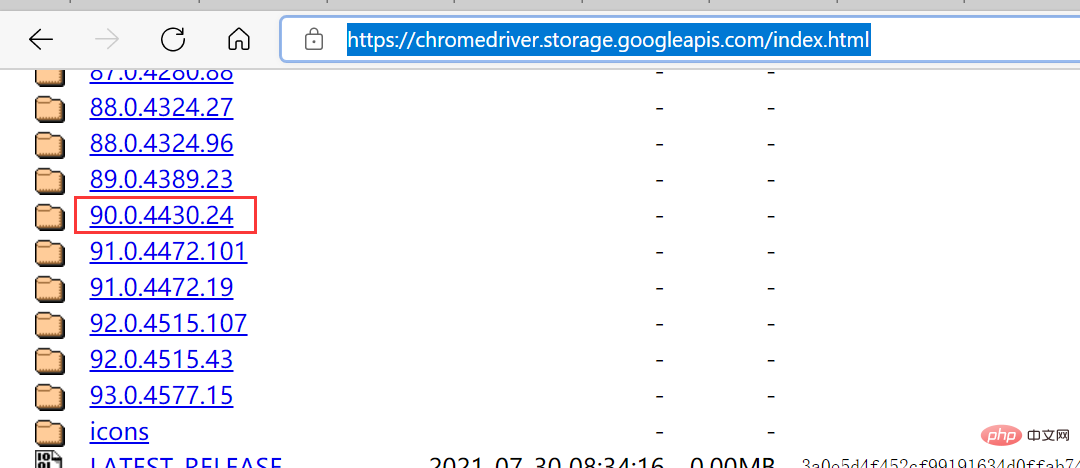
这个是因为谷歌驱动版本问题导致的,只需要根据提示,去下载对应的驱动版本即可,驱动下载链接:
https://chromedriver.storage.googleapis.com/index.html
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!


















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



