


Le CPM-1 sorti en décembre 2020 est le premier grand modèle chinois en Chine ; le CPM-Ant sorti en septembre 2022 peut surpasser l'effet de réglage fin des paramètres en n'affinant que 0,06 % des paramètres publiés ; en mai 2023, le chinois est le premier modèle de questions-réponses open source basé sur la recherche. Le grand modèle CPM-Bee 10 milliards est le dernier modèle de base publié par l'équipe. Sa capacité en chinois est en tête de la liste faisant autorité ZeroCLUE, et sa capacité en anglais égale LLaMA.
Réalisant à plusieurs reprises des réalisations révolutionnaires, la série de grands modèles CPM a conduit les grands modèles nationaux à grimper au sommet, et le VisCPM récemment publié en est une autre preuve ! VisCPM est une grande série de modèles multimodaux open source conjointe de Wallface Intelligence, du laboratoire NLP de l'Université Tsinghua et de Zhihu dans OpenBMB. Parmi eux, le modèle VisCPM-Chat prend en charge les capacités de dialogue multimodal bilingue chinois et anglais, ainsi que VisCPM-Paint. Le modèle prend en charge la capacité de génération de graphiques WenDao, l'évaluation montre que VisCPM atteint le meilleur niveau parmi les modèles open source multimodaux chinois.
VisCPM est formé sur la base des dizaines de milliards de modèles de base de paramètres CPM-Bee et intègre l'encodeur visuel (Q-Former et le décodeur visuel (Diffusion-UNet) pour prendre en charge l'entrée et la sortie de signaux visuels. Grâce à CPM-Bee Grâce aux excellentes capacités bilingues de la base, VisCPM peut être pré-entraîné avec uniquement des données multimodales en anglais et généralisé pour obtenir d'excellentes capacités multimodales en chinois
 Schéma d'architecture simple VisCPM
Schéma d'architecture simple VisCPM
Regardons de plus près VisCPM-Chat. Où est la vache avec VisCPM-Paint ? VisCPM-Chat prend en charge le traitement bilingue orienté image en chinois et en anglais.
Le modèle utilise Q-Former comme encodeur visuel, utilise CPM-Bee (10B) comme modèle de base d'interaction linguistique et fusionne le visuel. et des modèles linguistiques via des objectifs de formation à la modélisation linguistique. La formation des modèles comprend une pré-formation et un réglage précis des instructions. 
100 millions de données d'images et de texte en anglais de haute qualité pour pré-entraîner VisCPM-Chat. , CC12M, COCO, Visual Genome, Laion, etc. en pré-formation. À ce stade, les paramètres du modèle de langage restent fixes et seuls certains paramètres de Q-Former sont mis à jour pour prendre en charge un alignement efficace des représentations visuelles et linguistiques à grande échelle. L'équipe a ensuite affiné les instructions de VisCPM-Chat,
en utilisant les données de réglage fin de la commande LLaVA-150K, et a mélangé les données chinoises traduites correspondantes pour affiner le modèle afin d'aligner le multi du modèle. -capacités de base modales et intentions d'utilisation des utilisateurs. Lors de la phase de réglage fin de la commande, ils ont mis à jour tous les paramètres du modèle pour améliorer l'efficacité de l'utilisation des données de réglage fin Fait intéressant, l'équipe a constaté que même s'il ne s'agissait que d'instructions en anglais. les données ont été utilisées pour affiner l'instruction, le modèle a pu comprendre les questions en chinois, mais n'a pu répondre qu'en anglais. Cela montre que les capacités modales ont été bien généralisées en ajoutant davantage de données de traduction en chinois. lors de la phase de mise au point de l'instruction, le langage de réponse du modèle peut être aligné sur le langage des questions de l'utilisateur
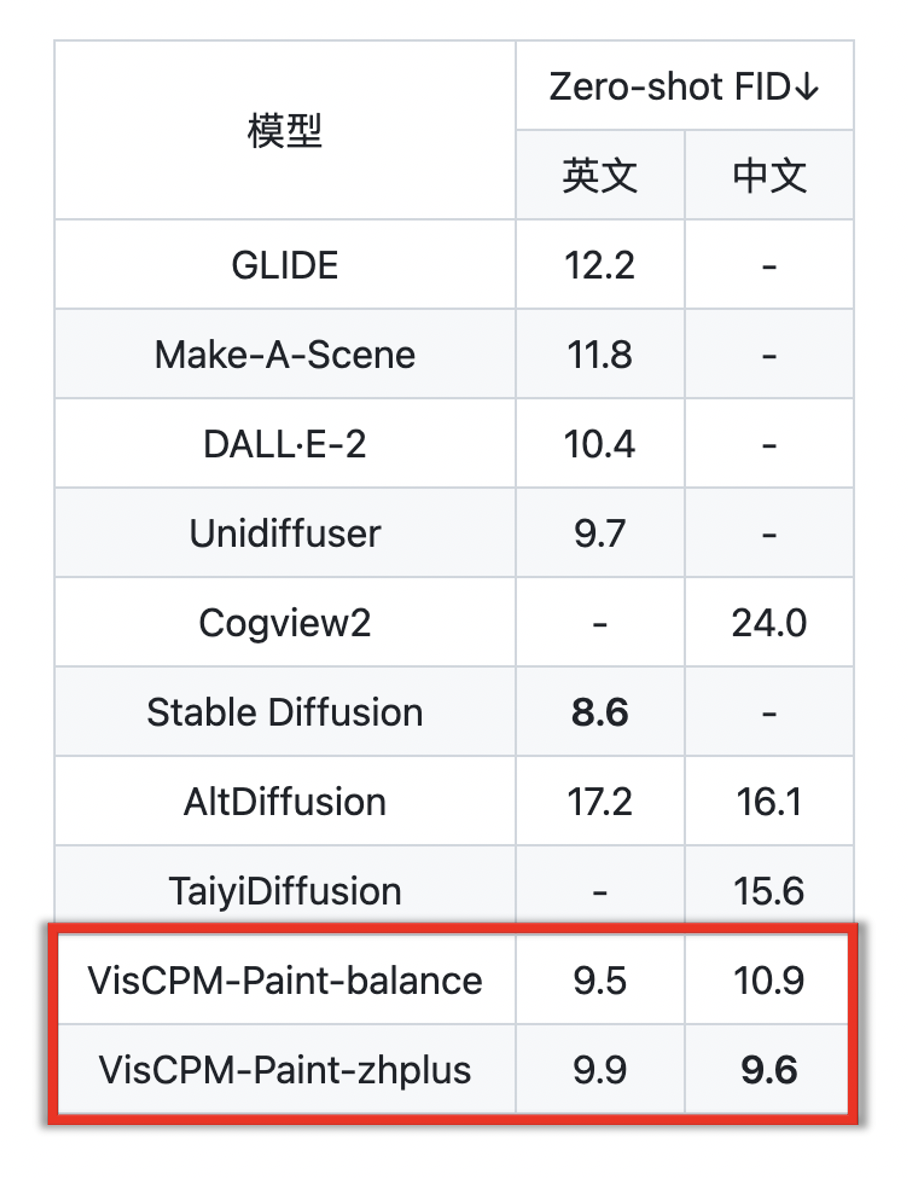
L'équipe a testé l'ensemble de tests d'anglais LLaVA et la traduction en chinois. Le modèle a été évalué sur ce référentiel d'évaluation. examine les performances du modèle dans le dialogue en domaine ouvert, la description détaillée de l'image et le raisonnement complexe, et utilise GPT-4 pour la notation. On peut observer que VisCPM-Chat a d'excellentes capacités multimodales chinoises. a bien performé dans le dialogue de domaine général et le raisonnement complexe, et a également montré de bonnes capacités multimodales en anglais
VisCPM-Chat propose deux versions de modèle, respectivement VisCPM -Chat-balance et VisCPM-Chat-zhplus, La première a un. une capacité plus équilibrée en anglais et en chinois, tandis que ce dernier est plus important en matière de chinois. Les deux modèles utilisent les mêmes données dans la phase de réglage fin des instructions. VisCPM-Chat-zhplus ajoute 20 millions de données supplémentaires de paire image-texte chinoise native nettoyées et 120 millions de données de paire image-texte chinois traduites dans la phase de pré-formation.
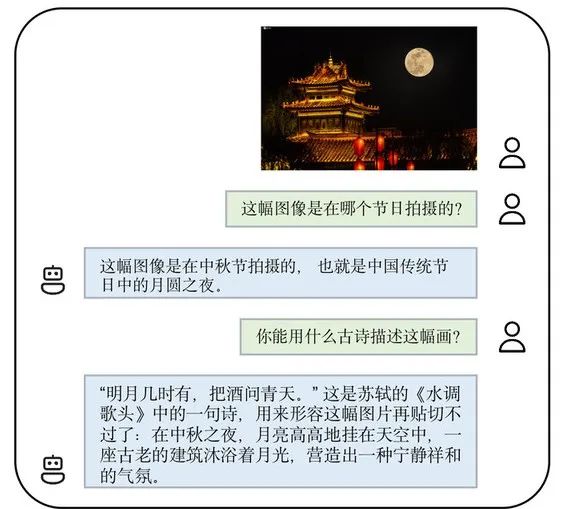
photos Ce qui suit est une démonstration des capacités de dialogue multimodal de VisCPM-Chat. Il peut non seulement reconnaître des cartes de zones spécifiques, mais également lire des graffitis et des affiches de films, et même reconnaître le logo Starbucks. De plus, je suis très bilingue en chinois et en anglais ! Regardons VisCPM-Paint, qui prend en charge la génération de texte en image bilingue en chinois et en anglais. Le modèle utilise CPM-Bee (10B) comme encodeur de texte, UNet comme décodeur d'image, et cible des modèles linguistiques et visuels fusionnés grâce à la formation de modèles de diffusion. Pendant le processus de formation, les paramètres du modèle de langage restent toujours fixes. Initialisez le décodeur visuel à l'aide des paramètres UNet de Stable Diffusion 2.1 et fusionnez-le avec le modèle de langage en dégelant progressivement ses paramètres de pontage clés : entraînez d'abord la couche linéaire de la représentation textuelle mappée sur le modèle visuel, puis débloquez davantage l'attention croisée. couche de UNet. Le modèle a été formé sur des données image-texte anglaises Laion 2B. Semblable à VisCPM-Paint, grâce à la capacité bilingue du modèle de base CPM-Bee, VisCPM-Paint peut être formé uniquement à travers des paires d'images et de texte en anglais et généralisé pour obtenir de bonnes capacités de génération de texte à image en chinois , atteignant le meilleur des modèles open source chinois. En ajoutant encore 20 millions de données de paires image-texte chinoises natives nettoyées et 120 millions de données de paires image-texte traduites en chinois, la capacité de génération de texte à image chinois du modèle a été encore améliorée. De même, VisCPM-Paint a deux versions différentes : balance et zhplus. Ils ont échantillonné 30 000 images sur l’ensemble de test de génération d’images standard MSCOCO et ont calculé la métrique de génération d’images d’évaluation couramment utilisée FID (Fréchet Inception Distance) pour évaluer la qualité des images générées. Saisissez deux invites dans le modèle VisCPM-Paint : "La lune brillante se lève sur la mer, le monde est à cette époque, style esthétique, style abstrait" et "Les gens sont oisifs, les fleurs d'osmanthus tombent, le "La lune est calme dans le ciel printanier", et les deux suivantes sont générées. Image : (La stabilité de l'effet de génération peut encore être améliorée) est assez étonnante. On peut le dire qu'il saisit avec précision la conception artistique de la poésie ancienne. Si vous ne parvenez pas à comprendre le poème à l'avenir, générez simplement une image pour le comprendre ! Si elle est appliquée à la conception, elle peut permettre d’économiser beaucoup de main d’œuvre. Non seulement vous pouvez "dessiner", en utilisant VisCPM-Chat, vous pouvez également "réciter des poèmes" : Recherche inversée de poèmes à l'aide d'images. Par exemple, je peux utiliser les poèmes de Li Bai pour décrire et interpréter la scène du fleuve Jaune, et je peux également utiliser « Shui Tiao Ge Tou » de Su Shi pour exprimer mes émotions face à la nuit de la lune de la mi-automne. VisCPM a non seulement de bons résultats de génération, mais la version téléchargeable est soigneusement conçue et est également très facile à installer et à utiliser. VisCPM propose des versions de modèles avec différentes capacités en chinois et en anglais que chacun peut télécharger et choisir. Les étapes d'installation sont simples. -la modélisation avec quelques lignes de code lors de l'utilisation. Le dialogue dynamique et les contrôles de sécurité pour le texte d'entrée et les images de sortie sont activés par défaut dans le code. (Voir le README pour des didacticiels spécifiques) À l'avenir, l'équipe intégrera également VisCPM dans le cadre de code huggingface et améliorera progressivement le modèle de sécurité, prendra en charge le déploiement rapide de pages Web, prendra en charge les fonctions de quantification du modèle, prendra en charge le réglage fin du modèle et autres fonctions. Restez à l’écoute des mises à jour ! Il convient de mentionner que les Les modèles de la série VisCPM sont les bienvenus pour un usage personnel et à des fins de recherche. Si vous souhaitez utiliser le modèle à des fins commerciales, vous pouvez également contacter cpm@modelbest.cn pour discuter des questions de licence commerciale. Les modèles traditionnels se concentrent sur le traitement des données monomodales. Les informations dans le monde réel sont souvent multimodales. Les grands modèles multimodaux améliorent les capacités d'interaction perceptuelle des systèmes d'intelligence artificielle et résolvent des problèmes complexes de perception et d'interaction dans le monde réel. pour l’IA. Comprendre les tâches ouvre de nouvelles opportunités. Il faut dire que les grandes entreprises de modèles basées à Tsinghua disposent de solides capacités de recherche et de développement en matière d'intelligence face aux murs. Le grand modèle multimodal VisCPM publié conjointement est puissant et fonctionne de manière étonnante. Nous attendons avec impatience la publication ultérieure de ses résultats ! 


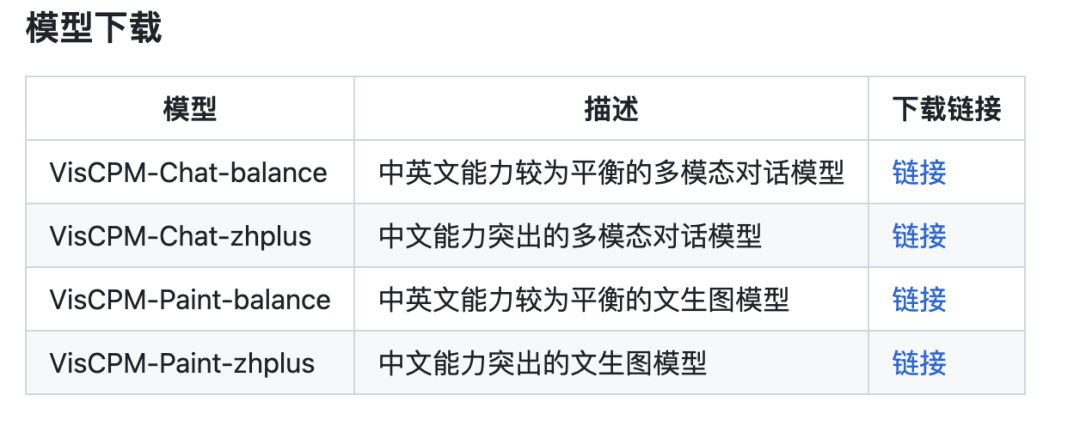 VisCPM propose des modèles avec différentes capacités en chinois et en anglais
VisCPM propose des modèles avec différentes capacités en chinois et en anglais 
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment illuminer le moment des amis proches de Douyin
Comment illuminer le moment des amis proches de Douyin
 Que dois-je faire si mon ordinateur démarre et que l'écran affiche un écran noir sans signal ?
Que dois-je faire si mon ordinateur démarre et que l'écran affiche un écran noir sans signal ?
 Pare-feu Kaspersky
Pare-feu Kaspersky
 Erreur d'application plugin.exe
Erreur d'application plugin.exe
 nvidia geforce 940mx
nvidia geforce 940mx
 Savez-vous si vous annulez l'autre personne immédiatement après l'avoir suivie sur Douyin ?
Savez-vous si vous annulez l'autre personne immédiatement après l'avoir suivie sur Douyin ?
 Comment calculer les frais de traitement du remboursement du chemin de fer 12306
Comment calculer les frais de traitement du remboursement du chemin de fer 12306
 Les dix principaux échanges de devises numériques
Les dix principaux échanges de devises numériques








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



