


De ChatGPT à la technologie de dessin d'IA, cette récente vague de percées dans le domaine de l'intelligence artificielle est peut-être due à Transformer.
Aujourd'hui, c'est le sixième anniversaire de la soumission du célèbre papier transformateur.

Lien papier : https://arxiv.org /abs/1706.03762
Il y a six ans, un article au nom quelque peu exagéré a été téléchargé sur la plateforme de papier pré-imprimé arXiv, "xx is All" You Need" est constamment répété par les développeurs dans le domaine de l'IA, et est même devenu une tendance dans les titres papier. Transformer ne signifie plus Transformers, il représente désormais la technologie la plus avancée dans le domaine de l'IA.
Six ans plus tard, en regardant cet article, nous pouvons trouver de nombreux aspects intéressants ou peu connus, comme l'a résumé Jim Fan, scientifique de NVIDIA AI.
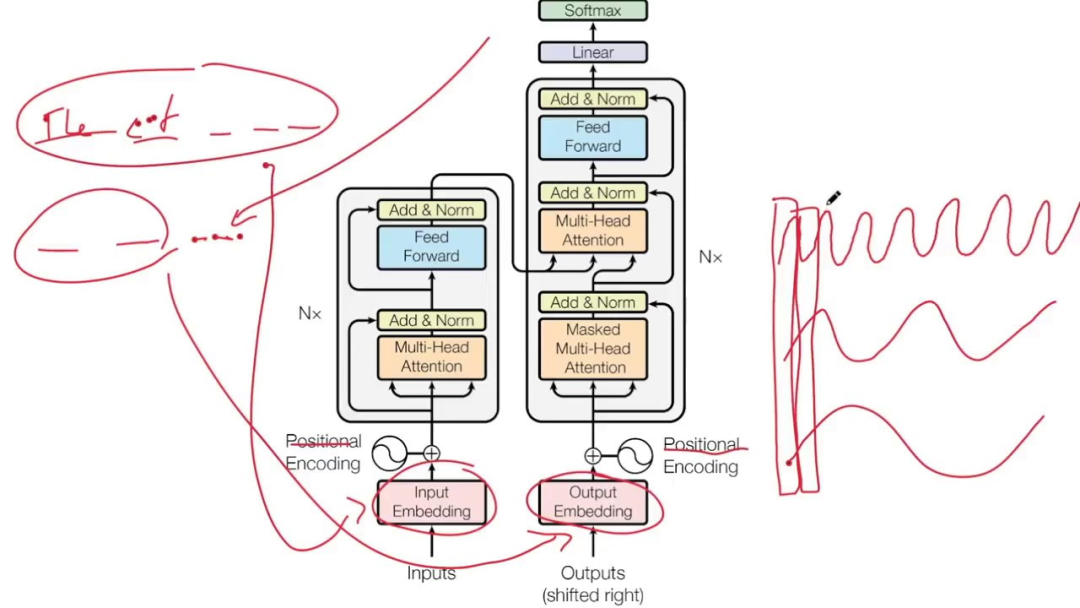
Le modèle Transformer abandonne les unités traditionnelles CNN et RNN, et toute la structure du réseau est entièrement composée de mécanismes d'attention.
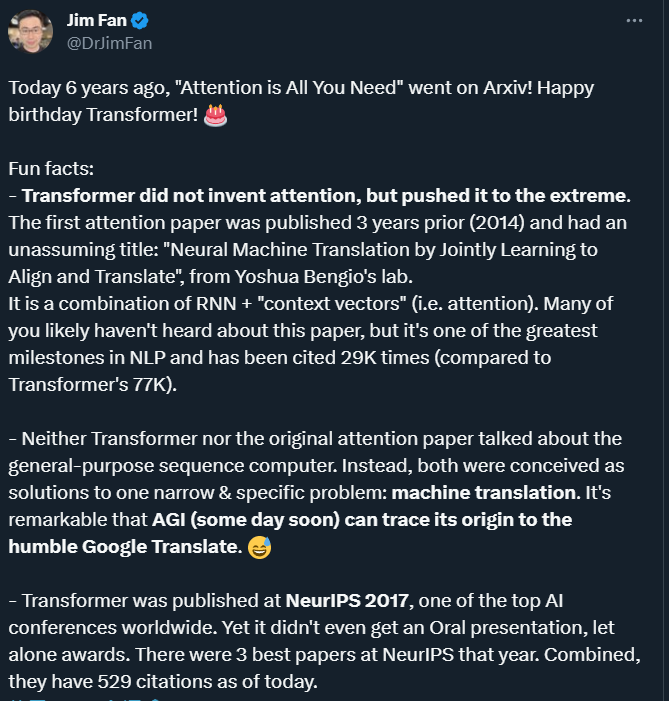
Bien que le nom du papier Transformer soit "L'attention est tout ce dont vous avez besoin" et que nous continuons à promouvoir le mécanisme d'attention à cause de cela, veuillez prêter attention à un fait intéressant : et les chercheurs de Transformer n'ont pas inventé l'attention, mais ils ont poussé ce mécanisme à l'extrême.
Attention Mechanism a été proposé en 2014 par une équipe dirigée par le pionnier du deep learning Yoshua Bengio : #🎜🎜 #
# 🎜🎜# "Traduction automatique neuronale en apprenant conjointement à aligner et traduire", le titre est relativement simple.Dans cet article de l'ICLR 2015, Bengio et al. ont proposé une combinaison de RNN + « vecteur de contexte » (c'est-à-dire attention). Bien qu'il s'agisse de l'une des étapes les plus importantes dans le domaine de la PNL, il est beaucoup moins connu que Transformer. L'article de l'équipe Bengio a été cité 29 000 fois jusqu'à présent, et Transformer 77 000 fois. Mécanisme d’attention de l’IA, la nature est calquée sur l’attention visuelle humaine. Le cerveau humain a une capacité innée : lorsque nous regardons une image, nous la numérisons d’abord rapidement, puis nous nous concentrons sur la zone cible sur laquelle nous devons nous concentrer.
Si vous ne lâchez aucune information partielle, vous ferez forcément beaucoup de travail inutile, qui n'est pas propice à la survie. De même, l’introduction de mécanismes similaires dans les réseaux d’apprentissage profond peut simplifier les modèles et accélérer les calculs. Essentiellement, l'attention consiste à filtrer une petite quantité d'informations importantes à partir d'une grande quantité d'informations et à se concentrer sur ces informations importantes, tout en ignorant la plupart des informations sans importance.
Ces dernières années, le mécanisme d'attention a été largement utilisé dans divers domaines du deep learning, comme par exemple dans le sens de la vision par ordinateur pour capturer le champ réceptif sur l'image , ou en PNL pour localiser les jetons ou fonctionnalités clés. Un grand nombre d'expériences ont prouvé que les modèles dotés de mécanismes d'attention ont permis d'améliorer considérablement les performances dans des tâches telles que la classification, la segmentation, le suivi et l'amélioration d'images, ainsi que la reconnaissance, la compréhension, la réponse aux questions et la traduction du langage naturel. Le modèle Transformer qui introduit le mécanisme d'attention peut être considéré comme un ordinateur de séquence à usage général. Le mécanisme d'attention permet au modèle d'attribuer différents poids d'attention en fonction de la corrélation des différentes positions dans la séquence lors du traitement de la séquence d'entrée. permet au Transformer de capturer les dépendances longue distance et les informations contextuelles, améliorant ainsi l'effet du traitement de séquence. Mais à cette époque, ni Transformer ni le document d'attention original ne parlaient d'ordinateurs à séquence universelle. Au lieu de cela, les auteurs y voient un mécanisme permettant de résoudre un problème étroit et spécifique : la traduction automatique. Ainsi, à l’avenir, lorsque nous retracerons l’origine de l’AGI, nous pourrons peut-être la retracer jusqu’au « modeste » Google Translate. Transformer Bien que cet article soit très influent maintenant, il n'a même pas obtenu d'oral à NeurIPS 2017, la plus grande conférence mondiale sur l'IA. , et encore moins gagner un prix. La conférence a reçu un total de 3 240 soumissions d'articles cette année-là, dont 678 ont été sélectionnées comme articles de conférence. L'article Transformer était l'un des articles acceptés, 40 étaient des articles oraux, 112 étaient des articles Spotlight et 3 étaient les meilleurs. Thèse, un prix Test of time, Transformer n'est pas éligible pour le prix. Même si j'ai raté le prix papier NeurIPS 2017, l'influence de Transformer est évidente pour tous. Jim Fan a commenté : Ce n’est pas la faute des juges s’il est difficile pour les gens de réaliser l’importance d’une étude influente avant qu’elle ne devienne influente. Cependant, il existe également des articles qui ont la chance d'être découverts immédiatement. Par exemple, ResNet proposé par He Yuming et d'autres a remporté le meilleur article du CVPR 2016. Cette recherche est bien méritée et a été correctement reconnue par la plus grande conférence sur l'IA. Mais à l’heure actuelle, en 2017, des chercheurs très intelligents ne sont peut-être pas en mesure de prédire les changements provoqués par le LLM. Tout comme dans les années 1980, peu de gens pouvaient prévoir le tsunami provoqué par l’apprentissage profond depuis 2012. Il y avait 8 auteurs de cet article à cette époque, et ils venaient de Google et de l'Université de Toronto. Cinq ans plus tard, la plupart des auteurs de l'article ont quitté leur. établissements originaux. Le 26 avril 2022, une société appelée « Adept » a été officiellement créée. Elle compte 9 co-fondateurs, dont Ashish Vaswani et Niki Parmar, deux auteurs de l'article Transformer. Ashish Vaswani A obtenu un doctorat de l'Université de Californie du Sud, où il a étudié sous la tutelle des universitaires chinois David Chiang et Liang Huang, en se concentrant sur l'étude de la modernité. profondeur Premières applications de l'apprentissage dans la modélisation du langage. En 2016, il rejoint Google Brain et dirige la recherche Transformer avant de quitter Google en 2021. Niki Parmar est diplômée d'une maîtrise de l'Université de Californie du Sud et a rejoint Google en 2016. Là-bas, elle a développé avec succès des modèles de questions-réponses et de similarité de texte pour la recherche et les annonces Google. Elle a dirigé les premiers travaux d'extension du modèle Transformer à des domaines tels que la génération d'images, la vision par ordinateur, etc. En 2021, elle a également quitté Google. Après leur départ, les deux ont co-fondé Adept et ont respectivement occupé le poste de scientifique en chef (Ashish Vaswani) et de directeur de la technologie (Niki Parmar). La vision d’Adept est de créer une IA appelée « coéquipier en intelligence artificielle » qui est formée pour utiliser une variété d’outils logiciels et d’API différents. En mars 2023, Adept a annoncé la finalisation d'un financement de série B de 350 millions de dollars américains. La valorisation de la société a dépassé le milliard de dollars américains, ce qui en fait une licorne. Cependant, au moment où Adept a levé des fonds publiquement, Niki Parmar et Ashish Vaswani avaient quitté Adept et fondé leur propre nouvelle société d'IA. Cependant, cette nouvelle société reste confidentielle et nous ne sommes pas en mesure d'obtenir des informations détaillées sur la société. Un autre auteur d'article Noam Shazeer est l'un des premiers employés les plus importants de Google. Il rejoint Google fin 2000 jusqu'à son départ définitif en 2021, puis devient PDG d'une start-up baptisée "Character.AI". Character.AI Outre Noam Shazeer, l'autre fondateur est Daniel De Freitas, tous deux issus de l'équipe LaMDA de Google. Auparavant, ils ont construit LaMDA, un modèle de langage qui prend en charge les programmes conversationnels de Google. En mars de cette année, Character.AI a annoncé la finalisation d'un financement de 150 millions de dollars américains, avec une valorisation atteignant 1 milliard de dollars américains. le potentiel de concurrencer OpenAI, l'organisation à laquelle appartient ChatGPT. L'une des rares startups à devenir une licorne en seulement 16 mois. Son application, Character.AI, est un chatbot modèle de langage neuronal qui peut générer des réponses textuelles de type humain et engager des conversations contextuelles. Character.AI est sorti sur l'App Store d'Apple et le Google Play Store le 23 mai 2023 et a été téléchargé plus de 1,7 million de fois au cours de sa première semaine. En mai 2023, le service a ajouté un abonnement payant de 9,99 $ par mois appelé c.ai+, qui permet aux utilisateurs un accès prioritaire au chat, des temps de réponse plus rapides et un accès anticipé aux nouvelles fonctionnalités, entre autres avantages. #🎜🎜 ##### 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#AIDAN N. GOMEZ#🎜🎜 ## 🎜 🎜## 🎜🎜 # Il a quitté Google dès 2019, puis a été chercheur chez FOR.ai et est aujourd'hui co-fondateur et PDG de Cohere. Cohere est une startup d'IA générative fondée en 2019. Son cœur de métier consiste à fournir des modèles PNL et à aider les entreprises à améliorer l'interaction homme-machine. Les trois fondateurs sont Ivan Zhang, Nick Frosst et Aidan Gomez, parmi lesquels Gomez et Frosst sont d'anciens membres de l'équipe Google Brain. En novembre 2021, Google Cloud a annoncé son partenariat avec Cohere, Google Cloud utilisant son infrastructure robuste pour alimenter la plate-forme Cohere, et Cohere utilisant les TPU de Cloud pour développer et déployer ses produits. 
Bien qu'il ait été accepté par NeurIPS 2017, il n'a même pas obtenu d'oral
Huit auteurs, chacun avec une vie merveilleuse


Il est à noter que Cohere vient de recevoir 270 millions de dollars américains en financement de série C, devenant ainsi une licorne d'une valeur marchande de 2,2 milliards de dollars américains.
Łukasz Kaiser
#🎜 🎜#J'ai quitté Google en 2021, j'ai travaillé chez Google pendant 7 ans et 9 mois et je suis aujourd'hui chercheur à OpenAI. Tout en travaillant comme chercheur scientifique chez Google, il a participé à la conception de modèles neuronaux SOTA pour la traduction automatique, l'analyse syntaxique et d'autres tâches algorithmiques et de génération. Il a été co-auteur du système TensorFlow et de la bibliothèque Tensor2Tensor.

Jakob Uszkoreit# 🎜🎜# A quitté Google en 2021 et a travaillé chez Google pendant 13 ans avant de rejoindre Inceptive en tant que co-fondateur. Inceptive est une société pharmaceutique d'IA dédiée à l'utilisation du deep learning pour concevoir des médicaments à ARN.
Alors qu'il travaillait chez Google, Jakob Uszkoreit a participé à la formation de l'équipe de compréhension linguistique de Google Assistant et a également travaillé sur Google Translate au début.
Illia Polosukhin #🎜 🎜# a quitté Google en 2017 et est désormais co-fondateur et CTO de NEAR.AI, une société technologique sous-jacente à la blockchain.

Le seul qui reste encore chez Google est Llion Jones, c'est sa 9ème année de travail chez Google.

Maintenant, 6 ans se sont écoulés depuis la publication de l'article « Attention Is All You Need » Certains des auteurs originaux ont choisi de partir, et d'autres ont choisi de rester chez Google. L'influence de Transformer se poursuit toujours.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Vérifier l'occupation du port sous Linux
Vérifier l'occupation du port sous Linux
 Comment ouvrir le format TIF sous Windows
Comment ouvrir le format TIF sous Windows
 Quels sont les logiciels de dessin ?
Quels sont les logiciels de dessin ?
 Quelles sont les méthodes de stockage des données ?
Quelles sont les méthodes de stockage des données ?
 Comment utiliser l'instruction insert dans MySQL
Comment utiliser l'instruction insert dans MySQL
 Temps de panne du service Windows 10
Temps de panne du service Windows 10
 Collection de touches de raccourci informatique
Collection de touches de raccourci informatique
 Comment résoudre le problème de steam_api.dll manquant
Comment résoudre le problème de steam_api.dll manquant








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



