


Il y a quelques temps, le tout jeune Falcon écrasait LLaMA au classement LLM, provoquant des vagues dans toute la communauté.
Mais, Falcon est-il vraiment meilleur que LLaMA ?
Réponse courte : Probablement pas.
L'équipe Fu Yao a fait une évaluation plus approfondie du modèle : #🎜 🎜#
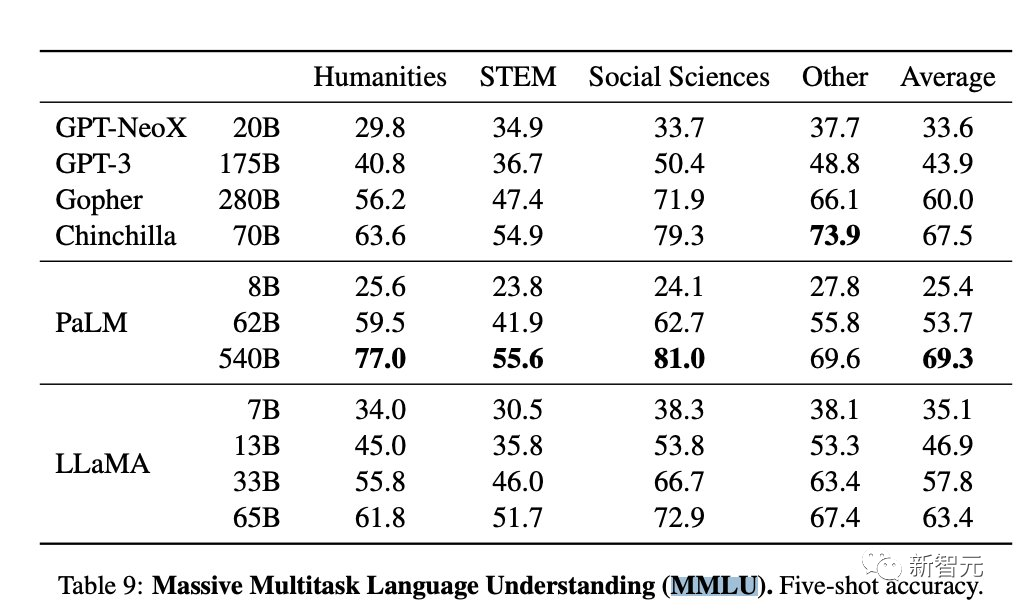
"Nous avons reproduit l'évaluation du LLaMA 65B sur MMLU et obtenu un score de 61,4, proche du score officiel (63,4) et bien supérieur à son score sur l'Open LLM Leaderboard (48,8), et nettement supérieur au Falcon (52,7). "
Pas d'ingénierie d'invite sophistiquée, pas de décodage sophistiqué, tout est le paramètre par défaut.
Actuellement, le code et les méthodes de test ont été rendus publics sur Github.
Il y a des doutes sur le fait que les Falcons dépassent LLaMA, LeCun a exprimé sa position, le problème avec le script de test...#🎜🎜 #
# 🎜🎜#LLaMATrue·Strength
Tout d'abord, un internaute a demandé d'où venaient ces chiffres de LLaMA. Ils semblaient incompatibles avec les chiffres du journal...
#🎜. 🎜# 
Par la suite, le scientifique d'OpenAI Andrej Karpathy a également exprimé son inquiétude quant à la raison pour laquelle le score de LLaMA 65B dans le classement Open LLM était nettement inférieur à celui officiel (48,8 contre 63,4).
Et post, j'ai évité de tweeter sur les Falcons jusqu'à présent à cause de cela, je ne suis pas sûr.
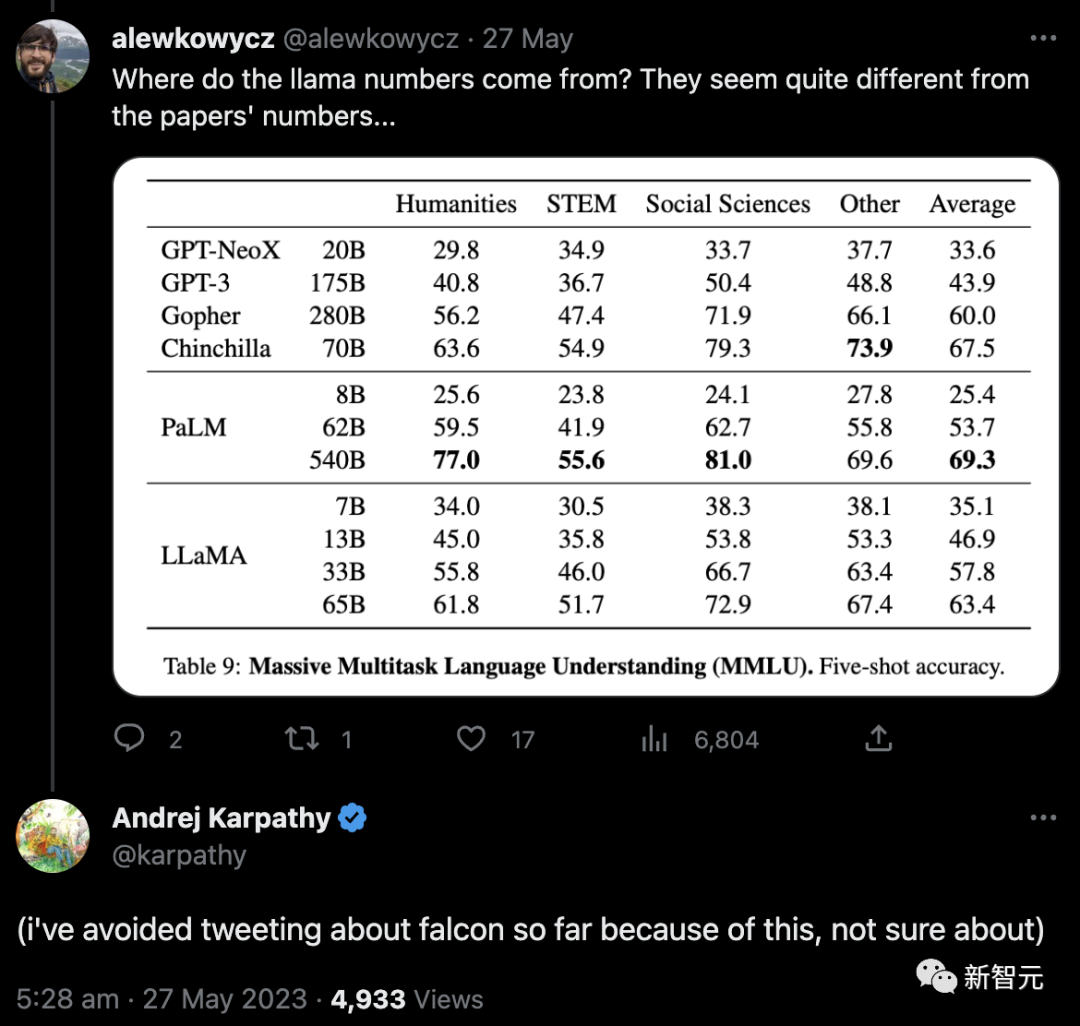 Afin de clarifier ce problème, Fu Yao et les membres de l'équipe ont décidé de mener un test public sur LLaMA 65B, et le résultat était de 61,4 points.
Afin de clarifier ce problème, Fu Yao et les membres de l'équipe ont décidé de mener un test public sur LLaMA 65B, et le résultat était de 61,4 points.
Lors du test, les chercheurs n'ont utilisé aucun mécanisme spécial, et LLaMA 65B a pu atteindre ce score .
Ce résultat prouve juste que si vous souhaitez que le modèle atteigne un niveau proche de GPT-3.5, il est préférable d'utiliser RLHF sur LLaMA 65B.
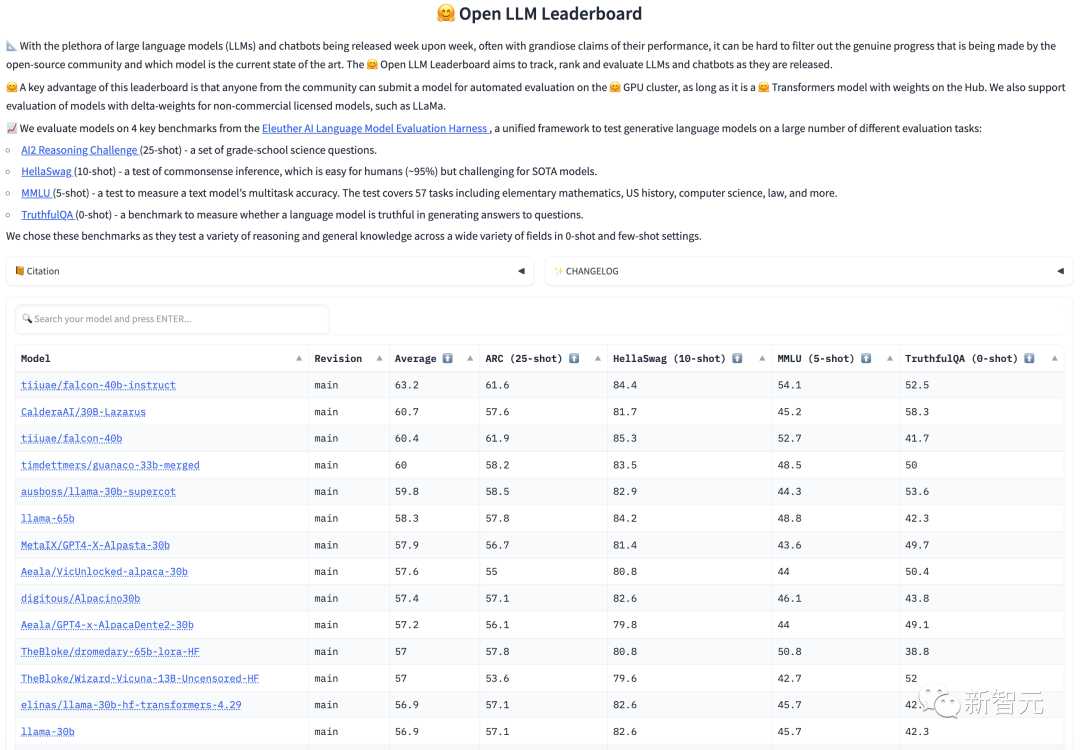 est basé sur les conclusions d'un article du Chain-of-Thought Hub récemment publié par l'équipe de Fu Yao.
est basé sur les conclusions d'un article du Chain-of-Thought Hub récemment publié par l'équipe de Fu Yao.
Bien sûr, Fu Yao a déclaré que leur évaluation n'était pas destinée à provoquer un différend entre LLaMA et Falcon After. dans l’ensemble, ce sont d’excellents modèles open source et ont apporté des contributions significatives au domaine !
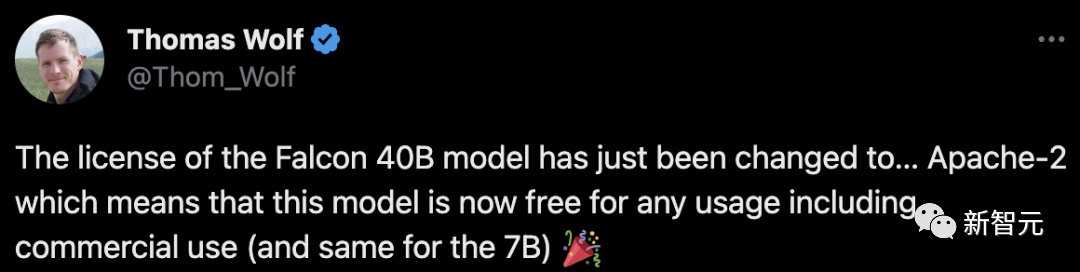
De plus, Falcon dispose d'une licence plus pratique, ce qui lui confère également un grand potentiel de développement.
Pour cette dernière revue, l'internaute BlancheMinerva a souligné qu'une comparaison équitable serait d'exécuter Falcon sur MMLU avec les paramètres par défaut.
En réponse, Fu Yao a déclaré que c'était correct et qu'il y travaillait, et que les résultats devraient être disponibles dans un jour.

Quel que soit le résultat final, il faut savoir que la montagne de GPT-4 est l'objectif que la communauté open source veut vraiment poursuivre.
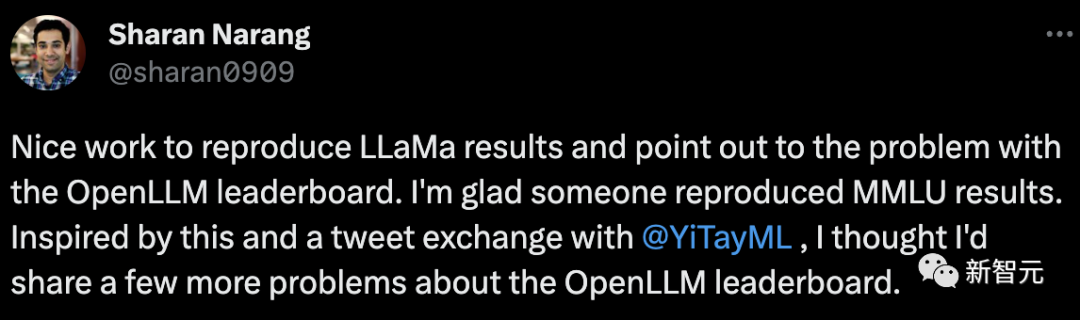
Les chercheurs de Meta ont félicité Fu Yao pour avoir bien reproduit les résultats de LLaMa et ont souligné le problème du classement OpenLLM.
Par la même occasion, il a également partagé quelques questions sur le classement OpenLLM.
Tout d'abord, les résultats MMLU : les résultats LLaMa 65B MMLU sont de 15 points au classement, mais pareil pour le modèle 7B. Il existe également un petit écart de performances entre les modèles 13B et 30B.
OpenLLM doit vraiment examiner cela avant d'annoncer quel modèle est le meilleur.
Benchmarks : Comment ces benchmarks sont-ils choisis ?
Le tir ARC 25 et le tir Hellaswag 10 ne semblent pas particulièrement pertinents pour LLM. Il serait préférable d'inclure des critères de référence génératifs. Même si les benchmarks génératifs ont leurs limites, ils peuvent néanmoins être utiles.

Score moyen unique : Il est toujours tentant de réduire les résultats à un seul score, et le score moyen est le plus simple.
Mais dans ce cas, la moyenne de 4 benchmarks est-elle vraiment utile ? Est-ce qu'obtenir 1 point sur MMLU équivaut à obtenir 1 point sur HellaSwag ?
Dans le monde de l'itération rapide du LLM, il y a certainement une certaine valeur à développer une telle liste de classement.

Et Lucas Beyer, un chercheur de Google, a également exprimé son opinion :
Ce qui est fou, c'est que les chercheurs en PNL ont des compréhensions différentes d'un même benchmark, conduisant ainsi à des résultats complètement différents. En même temps, chaque fois qu'un de mes collègues implémente une métrique, je lui demande immédiatement s'il vérifie réellement une reproduction parfaite du code officiel, et sinon, j'écarte ses résultats.

De plus, pour autant que je sache, quel que soit le modèle, il ne reproduira pas réellement les résultats du benchmark original.

Les internautes ont fait écho au fait que c'est la réalité du benchmark LLM...

En parlant de Falcon, il mérite en fait notre examen .
Selon LeCun, à l'ère des grands modèles, l'open source est le plus important.
Après la fuite du code LLaMA de Meta, des développeurs de tous horizons ont commencé à l'essayer avec impatience.
Falcon est une arme surprise développée par le Technology Innovation Institute (TII) d'Abu Dhabi, aux Émirats arabes unis.
En termes de performances lors de sa première sortie, Falcon a fait mieux que LLaMA.
Actuellement, "Falcon" a trois versions - 1B, 7B et 40B.
TII a déclaré que Falcon est le modèle de langage open source le plus puissant à ce jour. Sa plus grande version, Falcon 40B, possède 40 milliards de paramètres, ce qui est encore un peu plus petit que LLaMA, qui compte 65 milliards de paramètres.
Cependant, TII a précédemment déclaré que malgré sa petite taille, Falcon avait d'excellentes performances.
Faisal Al Bannai, secrétaire général du Conseil de recherche en technologies avancées (ATRC), estime que la sortie de « Falcon » ouvrira la voie à l'obtention d'un LLM et permettra aux chercheurs et les entrepreneurs à l'utiliser pour proposer les cas d'utilisation les plus innovants.

Les deux versions de FalconLM, Falcon 40B Instruct et Falcon 40B sont parmi les deux premières sur le Hugging Face OpenLLM classement en premier, tandis que LLaMA de Meta occupe la troisième place.
Et le problème concernant les classements mentionnés ci-dessus est exactement celui-là.
Bien que le document "Falcon" n'ait pas encore été rendu public, le Falcon 40B a été largement formé sur un ensemble de données réseau de 1 000 milliards de jetons soigneusement examinés.
Des chercheurs ont révélé un jour que « Falcon » attache une grande importance à l'importance d'atteindre des performances élevées sur des données à grande échelle pendant le processus de formation.
Ce que nous savons tous, c'est que le LLM est très sensible à la qualité des données d'entraînement, c'est pourquoi les chercheurs consacrent beaucoup d'efforts à construire un système capable de fonctionner sur des dizaines de milliers de cœurs de processeur pour un traitement efficace.
Le but est d'extraire du contenu de haute qualité d'Internet sur la base du filtrage et de la déduplication.
Actuellement, TII a publié un ensemble de données réseau affiné, qui est un ensemble de données soigneusement filtré et dédupliqué. La pratique a prouvé que c'est très efficace.
Le modèle formé en utilisant uniquement cet ensemble de données peut être à égalité avec d'autres LLM, voire les surpasser en termes de performances. Cela démontre l'excellente qualité et l'influence de "Falcon".

De plus, le modèle Falcon dispose également de capacités multilingues.
Il comprend l'anglais, l'allemand, l'espagnol et le français, et travaille en néerlandais, italien, roumain, portugais, tchèque, polonais et suédois, etc. Il en sait aussi beaucoup des petites langues européennes.
Falcon 40B est également le deuxième modèle véritablement open source après la sortie du modèle H2O.ai.
De plus, il y a un autre point très important : Falcon est actuellement le seul modèle open source qui peut être utilisé gratuitement commercialement.
Au début, TII exigeait que si Falcon est utilisé à des fins commerciales et génère plus d'un million de dollars de revenus attribuables, une « taxe d'utilisation » de 10 % sera accusé ».
Mais il n’a pas fallu longtemps pour que les riches magnats du Moyen-Orient lèvent cette restriction.
Au moins jusqu'à présent, toute utilisation commerciale et tout réglage fin de Falcon seront gratuits.
Les riches ont déclaré qu’ils n’avaient pas besoin de gagner de l’argent grâce à ce modèle pour le moment.
De plus, TII sollicite également des plans de commercialisation du monde entier.
Pour les solutions potentielles de recherche scientifique et de commercialisation, ils fourniront également davantage de « soutien à la puissance de calcul de formation » ou offriront d'autres opportunités de commercialisation.

Cela revient simplement à dire : tant que le projet est bon, le modèle est libre d'utilisation ! Assez de puissance de calcul ! Si vous n’avez pas assez d’argent, nous pouvons quand même le récupérer pour vous !
Pour les start-ups, il s'agit simplement d'une « solution unique pour l'entrepreneuriat de grands modèles d'IA » du magnat du Moyen-Orient.
Selon l'équipe de développement, un aspect important de l'avantage concurrentiel de FalconLM est la sélection des données d'entraînement.
L'équipe de recherche a développé un processus pour extraire des données de haute qualité à partir d'ensembles de données publics explorés et supprimer les données en double.
Après un nettoyage minutieux du contenu en double redondant, 5 000 milliards de jetons ont été conservés - suffisamment pour entraîner un modèle de langage puissant.
Le Falcon LM 40B utilise 1 000 milliards de jetons pour la formation, et la version 7B du jeton de formation modèle atteint 1,5 billion.
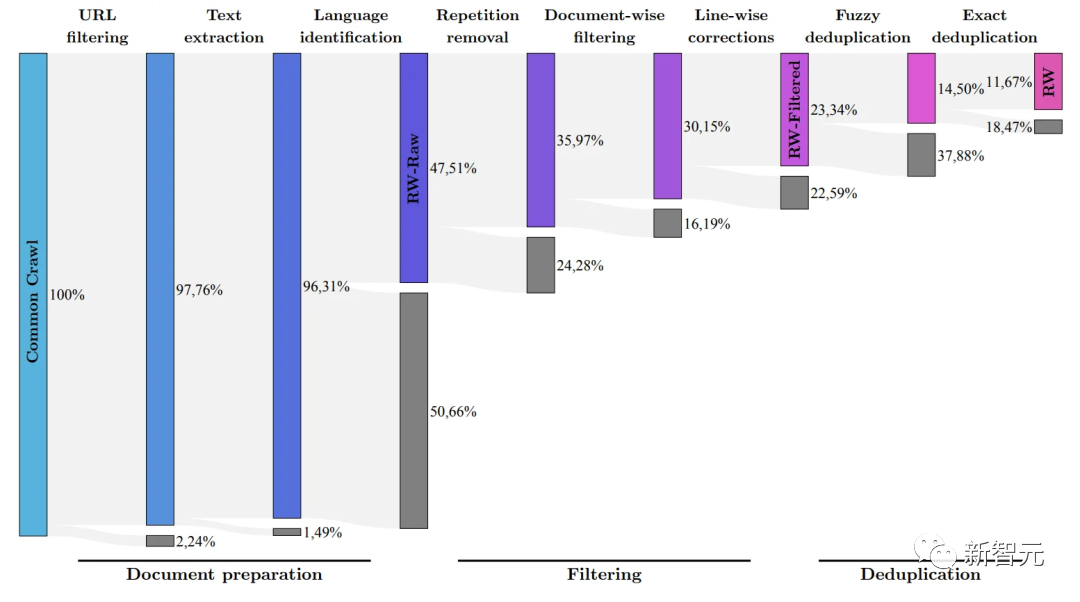
(L'équipe de recherche vise à filtrer uniquement la qualité de Common Crawl à l'aide de l'ensemble de données RefinedWeb Les données brutes les plus élevées)
De plus, le coût de formation de Falcon est relativement plus contrôlable.
TII a déclaré que par rapport à GPT-3, Falcon a obtenu des améliorations de performances significatives tout en utilisant seulement 75 % du budget informatique de formation.
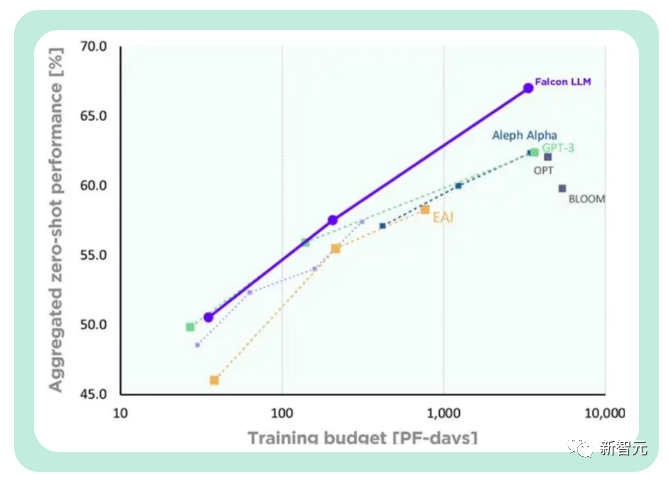
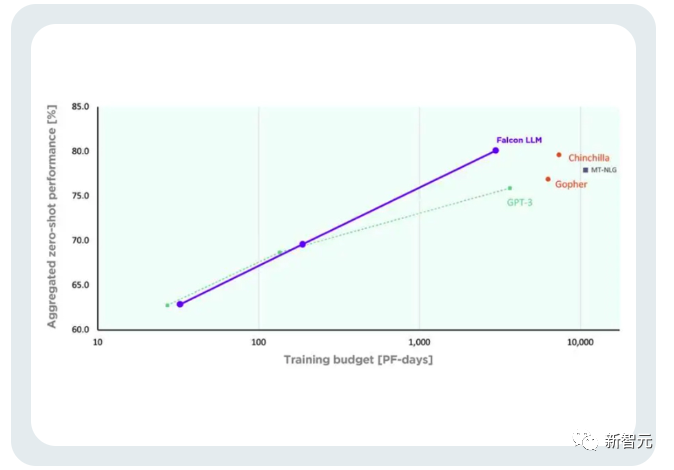
Et pour déduire (Inférence), il vous suffit à Il nécessite 20 % du temps de calcul et permet une utilisation efficace des ressources informatiques.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment utiliser la monnaie numérique
Comment utiliser la monnaie numérique
 Comment ouvrir des fichiers php sur un téléphone mobile
Comment ouvrir des fichiers php sur un téléphone mobile
 Quelles sont les touches de raccourci couramment utilisées dans WPS ?
Quelles sont les touches de raccourci couramment utilisées dans WPS ?
 Comment définir un arrêt programmé dans UOS
Comment définir un arrêt programmé dans UOS
 gestion des exceptions Java
gestion des exceptions Java
 Comment utiliser l'étiquette d'étiquette
Comment utiliser l'étiquette d'étiquette
 Téléchargement de l'application OuYi Exchange
Téléchargement de l'application OuYi Exchange
 Introduction au contenu principal du travail du backend
Introduction au contenu principal du travail du backend








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



