


Les champs de rayonnement neuronal (NeRF) sont devenus une nouvelle méthode de synthèse de vues populaire. Bien que NeRF se généralise rapidement à un plus large éventail d’applications et d’ensembles de données, l’édition directe des scénarios de modélisation NeRF reste un énorme défi. Une tâche importante consiste à supprimer les objets indésirables d'une scène 3D et à maintenir la cohérence avec la scène environnante. Cette tâche est appelée inpainting d'image 3D. En 3D, les solutions doivent être cohérentes sur plusieurs vues et être géométriquement valides.
Dans cet article, des chercheurs de Samsung, de l'Université de Toronto et d'autres institutions proposent une nouvelle méthode d'inpainting 3D pour résoudre ces défis, étant donné un petit ensemble d'images de pose et des annotations clairsemées dans une seule image d'entrée, le cadre de modèle proposé est le premier. Obtenez rapidement le masque de segmentation tridimensionnelle de l'objet cible et utilisez le masque, puis introduisez une méthode basée sur l'optimisation perceptuelle, qui utilise les images bidimensionnelles apprises pour réparer, extraire leurs informations dans l'espace tridimensionnel, tout en assurant la cohérence de la vue.
Cette étude apporte également une nouvelle référence pour évaluer les méthodes d'inpainting 3D sur scène en formant un ensemble de données de scène réelles difficiles. En particulier, cet ensemble de données contient des vues de la même scène avec et sans objets cibles, permettant une analyse comparative plus rigoureuse des tâches d'inpainting dans l'espace 3D.

Ce qui suit est une démonstration de l'effet. Après avoir supprimé certains objets, il peut toujours conserver une cohérence avec la scène environnante :

Comparaison entre cette méthode et d'autres méthodes ont des artefacts évidents, alors que cette méthode. Pas si évident :

L'auteur aborde divers défis liés aux tâches d'édition de scènes 3D grâce à une approche intégrée qui obtient des images multi-vues de la scène et extrait des images 3D avec un masque de saisie utilisateur, et s'adapte à l'image du masque en utilisant la formation NeRF, de sorte que l'objet cible soit remplacé par une apparence et une géométrie tridimensionnelles raisonnables. Les méthodes de segmentation 2D interactives existantes ne prennent pas en compte l'aspect 3D, et les méthodes actuelles basées sur NeRF ne peuvent pas obtenir de bons résultats en utilisant des annotations clairsemées et n'atteignent pas une précision suffisante. Bien que certains algorithmes actuels basés sur NeRF permettent la suppression d’objets, ils ne tentent pas de fournir des parties d’espace nouvellement générées. Selon les progrès actuels de la recherche, ce travail est le premier à gérer simultanément la segmentation interactive multi-vues et la restauration complète d'images 3D dans un seul cadre.
Les chercheurs utilisent des modèles prêts à l'emploi et sans 3D pour la segmentation et la restauration d'images, et transfèrent leur sortie dans l'espace 3D de manière cohérente. S'appuyant sur des travaux de segmentation interactive 2D, le modèle proposé part d'un petit nombre de points d'image calibrés par l'utilisateur avec la souris sur un objet cible. À partir de là, leur algorithme initialise le masque avec un modèle vidéo et l’entraîne à une segmentation 3D cohérente en ajustant le NeRF d’un masque sémantique. Ensuite, la restauration d'image 2D pré-entraînée est appliquée à l'ensemble d'images multi-vues. Le processus d'ajustement NeRF est utilisé pour reconstruire la scène d'image 3D, en utilisant la perte de perception pour limiter l'incohérence de l'image 2D et la géométrie de l'image normalisée. masque de la zone d’image de profondeur. Dans l'ensemble, nous proposons une approche complète, de la sélection d'objets à la synthèse de nouvelles vues de scènes intégrées, dans un cadre unifié avec une charge minimale pour l'utilisateur, comme le montre la figure ci-dessous. 
En résumé, les apports de ce travail sont les suivants :
Plus précisément sur la méthode, cette étude décrit d'abord comment initialiser un masque 3D approximatif à partir d'annotations à vue unique. Désignons la vue du code source annoté par I_1. Transmettez des informations éparses sur les objets et les vues sources à un modèle de segmentation interactif pour estimer les masques d'objets sources initiaux 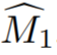 . La vue d'entraînement est ensuite donnée sous forme de séquence vidéo, avec
. La vue d'entraînement est ensuite donnée sous forme de séquence vidéo, avec 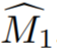 étant donné un modèle de segmentation d'instance vidéo V pour calculer
étant donné un modèle de segmentation d'instance vidéo V pour calculer 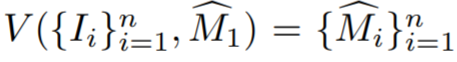 , où
, où 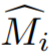 est la supposition initiale du masque d'objet de I_i. Les masques initiaux sont souvent inexacts à proximité des limites, car les vues d'entraînement ne sont pas réellement des images vidéo adjacentes et les modèles de segmentation vidéo sont souvent inconnus en 3D.
est la supposition initiale du masque d'objet de I_i. Les masques initiaux sont souvent inexacts à proximité des limites, car les vues d'entraînement ne sont pas réellement des images vidéo adjacentes et les modèles de segmentation vidéo sont souvent inconnus en 3D.
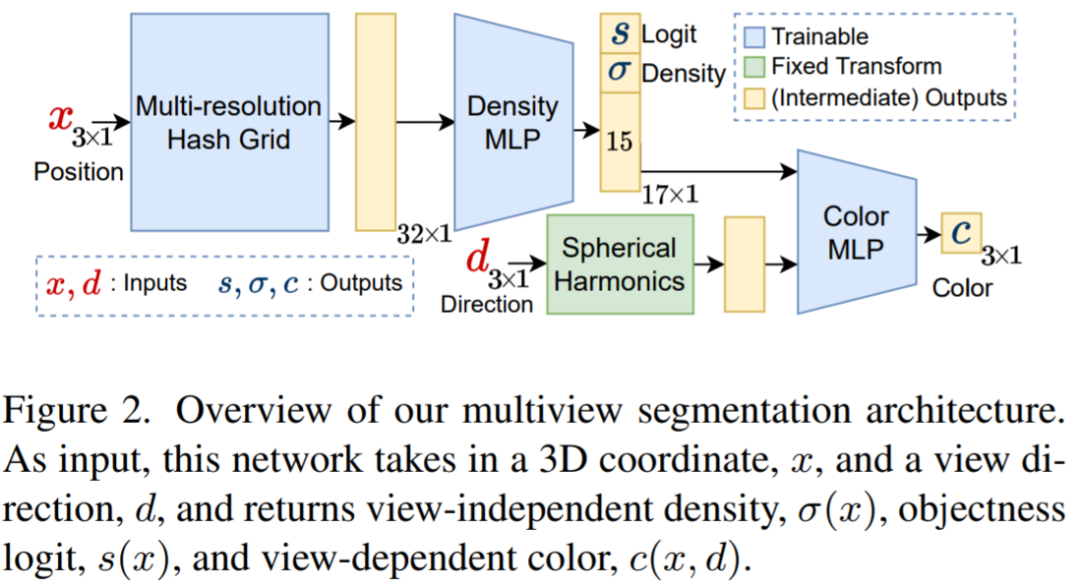
Le module de segmentation multi-vues prend l'image RVB d'entrée, les paramètres intrinsèques et extrinsèques de la caméra correspondants et le masque initial pour former un NeRF sémantique. Le diagramme ci-dessus représente le réseau utilisé dans le NeRF sémantique ; pour un point x et un répertoire de vue d, en plus de la densité σ et de la couleur c, il renvoie un logit d'objet pré-sigmoïde, s (x). Pour sa convergence rapide, les chercheurs ont utilisé le NGP instantané comme architecture NeRF. L'objectivité souhaitée associée à un rayon r est obtenue en présentant le logarithme des points sur r plutôt que leur couleur par rapport à la densité dans l'équation :
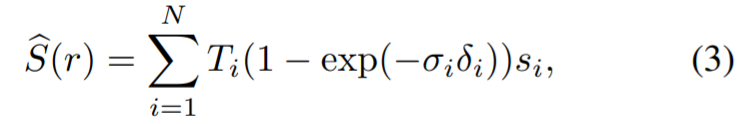
Utilisez ensuite une perte de classification pour la supervision :
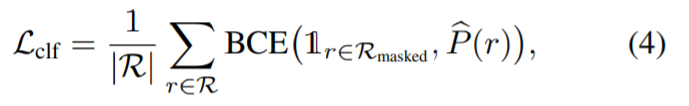
La perte globale utilisée pour superviser le modèle de segmentation multi-vues basé sur NeRF est :
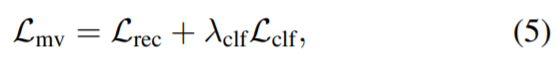
Enfin, deux étapes sont utilisées pour l'optimisation afin d'améliorer encore le masque après l'obtention d'Après ; le masque 3D initial, le masque est rendu à partir des vues d'entraînement et utilisé pour superviser le modèle de segmentation multi-vues secondaire comme hypothèse initiale (au lieu de la sortie de segmentation vidéo).
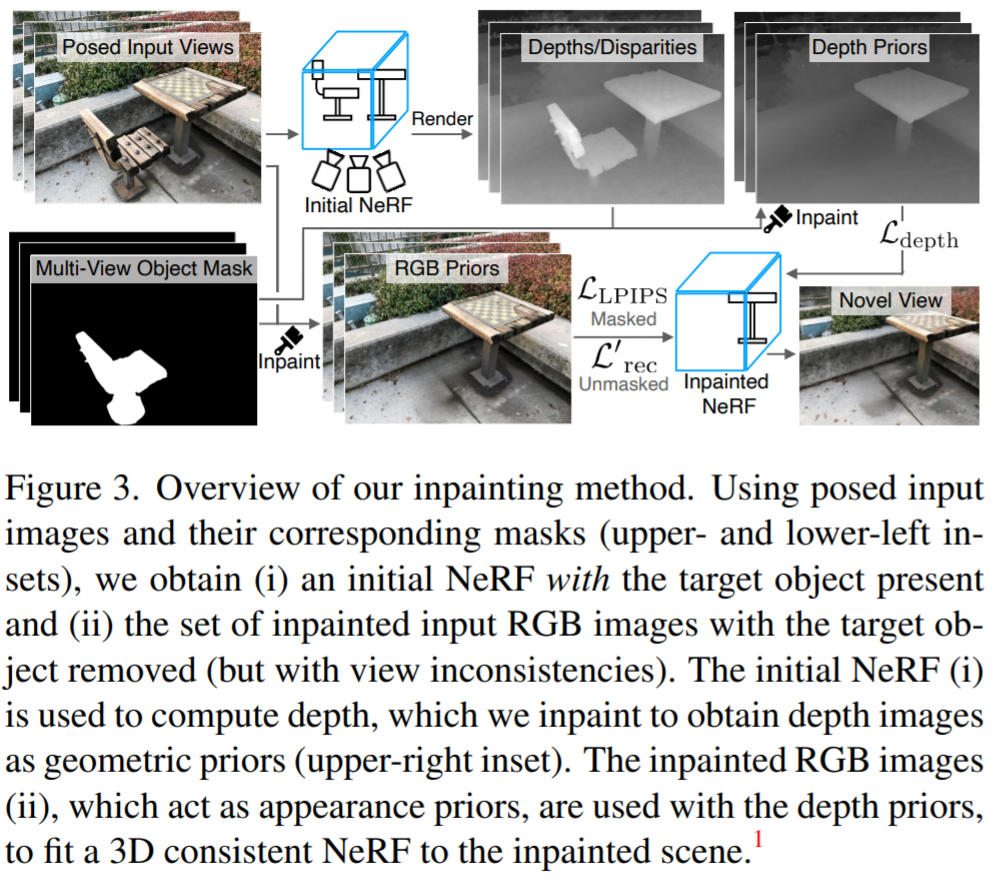
L'image ci-dessus montre un aperçu de la méthode de correction de cohérence de vue. Comme le manque de données empêche la formation directe de modèles d'inpainting modifiés en 3D, cette étude exploite les modèles d'inpainting 2D existants pour obtenir des priors de profondeur et d'apparence, puis supervise le rendu NeRF adapté à la scène complète. Ce NeRF intégré est entraîné en utilisant la perte suivante :
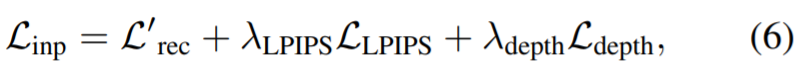
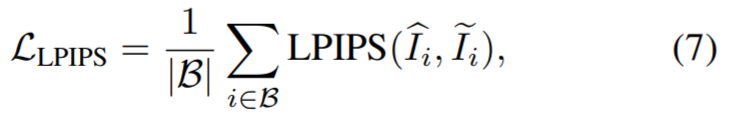
Même avec une perte de perception, la réparation des différences entre les vues peut guider incorrectement le modèle pour qu'il converge vers une géométrie de mauvaise qualité (par exemple, un "flou" peut se former près de la caméra mesure de la géométrie, pour interpréter différentes informations pour chaque vue). Par conséquent, les chercheurs ont utilisé la carte de profondeur générée comme guide supplémentaire pour le modèle NeRF et ont séparé les poids lors du calcul de la perte de perception, en utilisant la perte de perception pour s'adapter uniquement à la couleur de la scène. Pour ce faire, nous avons utilisé un NeRF optimisé pour les images contenant des objets indésirables et rendu des cartes de profondeur correspondant aux vues d'entraînement. La méthode de calcul consiste à utiliser la distance à la caméra au lieu de la couleur du point :
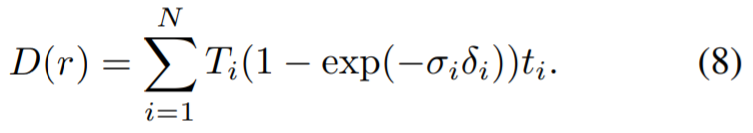
Ensuite, la profondeur rendue est entrée dans le modèle du réparateur pour obtenir la carte de profondeur réparée. Des recherches ont montré que l'utilisation de LaMa pour le rendu en profondeur, tel que RVB, peut donner des résultats de suffisamment haute qualité. Ce NeRF peut être le même modèle que celui utilisé pour la segmentation multi-vues. Si d'autres sources sont utilisées pour obtenir les masques, comme des masques annotés humains, un nouveau NeRF sera installé dans la scène. Ces cartes de profondeur sont ensuite utilisées pour superviser la géométrie du NeRF peint, par lequel la profondeur rendue est ensuite introduite dans le modèle inpainter pour obtenir la carte de profondeur peinte. Des recherches ont montré que l'utilisation de LaMa pour le rendu en profondeur, tel que RVB, peut donner des résultats de suffisamment haute qualité. Ce NeRF peut être le même modèle que celui utilisé pour la segmentation multi-vues. Si d'autres sources sont utilisées pour obtenir les masques, comme des masques annotés humains, un nouveau NeRF sera installé dans la scène. Ces cartes de profondeur sont ensuite utilisées pour superviser la géométrie du NeRF peint par sa profondeur de rendu à la profondeur peinte 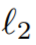 à la profondeur peinte distance :
à la profondeur peinte distance :
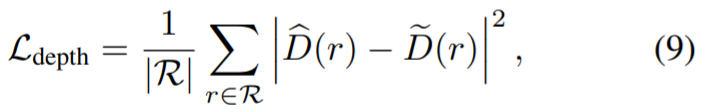
Le tableau ci-dessous montre la comparaison de la méthode MV avec la ligne de base. Dans l'ensemble, la méthode nouvellement proposée surpasse considérablement les autres méthodes de réparation 2D et 3D. Le tableau ci-dessous montre en outre que la suppression du guidage des structures géométriques dégrade la qualité de la scène réparée.
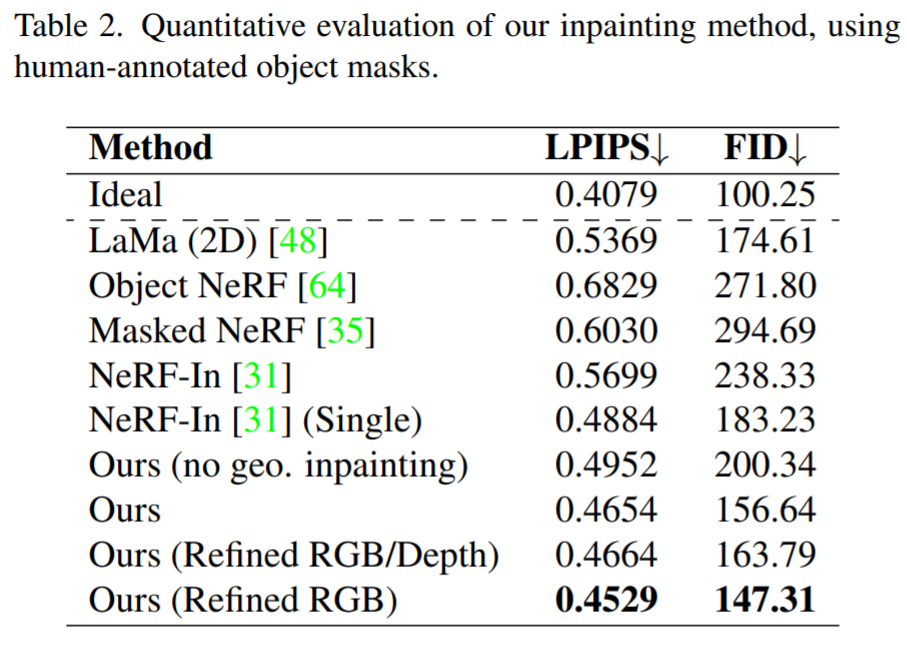
Les résultats qualitatifs sont présentés dans la Figure 6 et la Figure 7. La figure 6 montre que notre méthode peut reconstruire des scènes cohérentes avec des textures détaillées, y compris des vues cohérentes de surfaces brillantes et mates. La figure 7 montre que notre méthode de perception réduit les contraintes sur la reconstruction précise des régions de masque, empêchant ainsi l'apparition de flou lors de l'utilisation de toutes les images, tout en évitant les artefacts provoqués par la supervision d'une seule vue.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



