


Je ne m'attendais pas à ce que ChatGPT fasse encore des erreurs stupides à ce jour ?
Maître Andrew Ng l'a souligné lors du dernier cours :
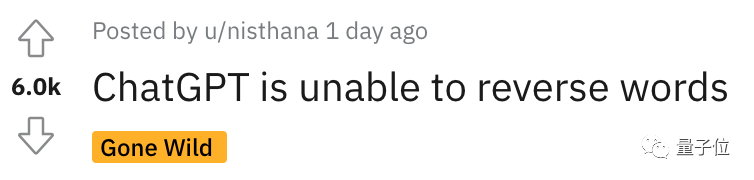
ChatGPT n'inverse pas les mots !
Par exemple, si vous inversez le mot sucette, le résultat est pilollol, ce qui est complètement déroutant.

Oh, c'est en effet un peu surprenant.
À tel point qu'après qu'un internaute ait écouté le cours posté sur Reddit, celui-ci a immédiatement attiré un grand nombre de spectateurs, et le message a rapidement atteint 6 000 vues.
Et ce n'est pas un bug accidentel. Les internautes ont découvert que ChatGPT est en effet incapable de terminer cette tâche, et les résultats de nos tests personnels sont également les mêmes.

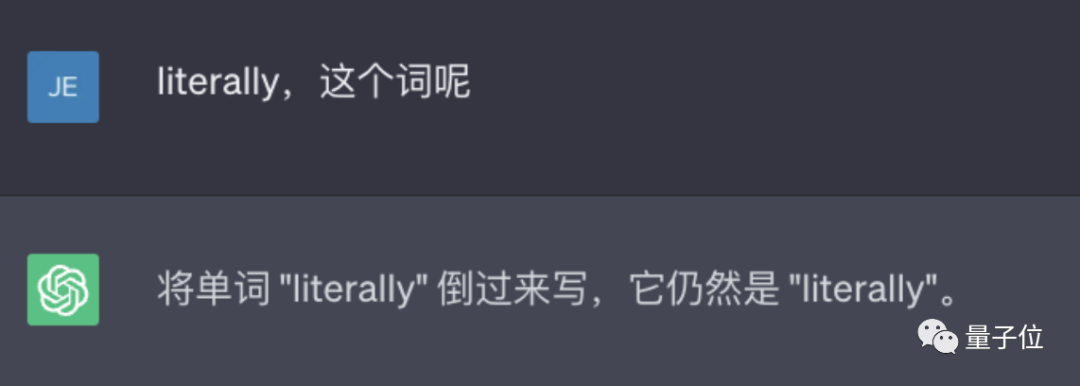
Même de nombreux produits, dont Bard, Bing, Wen Xinyiyan, etc., ne fonctionnent pas.
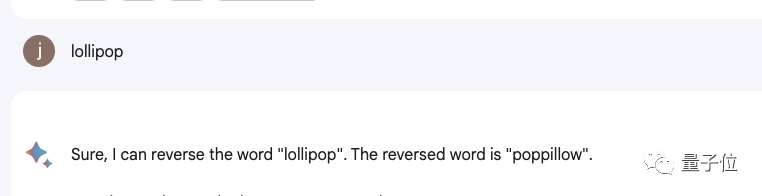

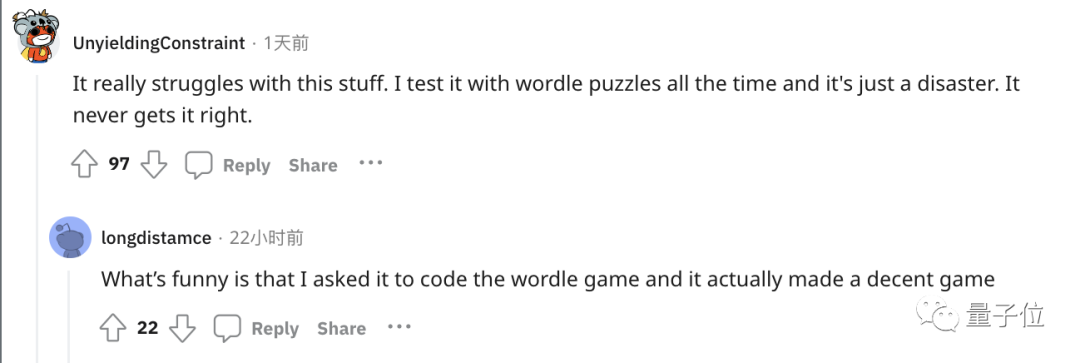
Certaines personnes ont suivi et se sont plaintes que ChatGPT est très mauvais pour gérer ces simples tâches de mots.
Par exemple, jouer au jeu de mots populaire Wordle a été un désastre et n'a jamais réussi.
hein ? Pourquoi est-ce ?
La clé de ce phénomène réside dans le jeton. Les grands modèles utilisent souvent des jetons pour traiter le texte, car les jetons sont les séquences de caractères les plus courantes dans le texte.
Il peut s'agir d'un mot entier ou d'un fragment de mot. Les grands modèles connaissent les relations statistiques entre ces jetons et peuvent habilement générer le jeton suivant.
Ainsi, lorsqu'il s'agit de la petite tâche d'inversion de mots, il peut s'agir simplement de retourner chaque jeton au lieu de la lettre.

C'est encore plus évident dans le contexte chinois : un mot est un jeton, ou un mot est un jeton.

Concernant l'exemple du début, quelqu'un a essayé de comprendre le processus de raisonnement de ChatGPT.
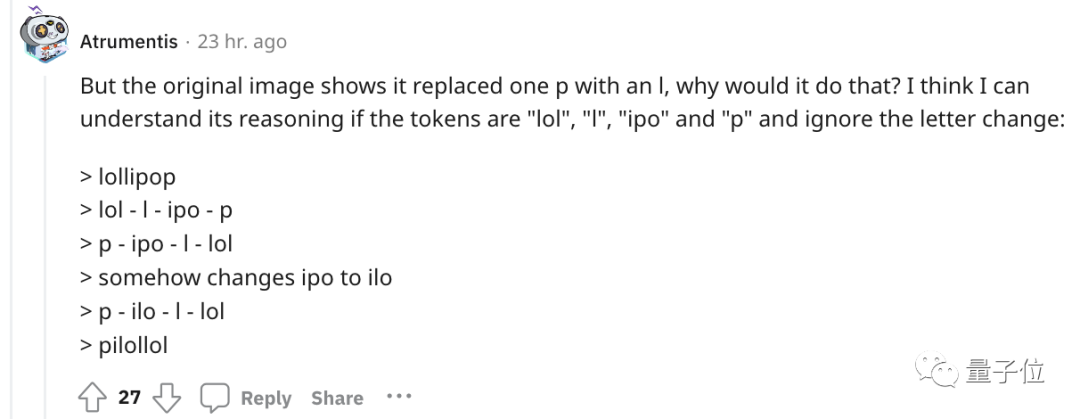
Pour une compréhension plus intuitive, OpenAI a même publié un Tokenizer GPT-3.
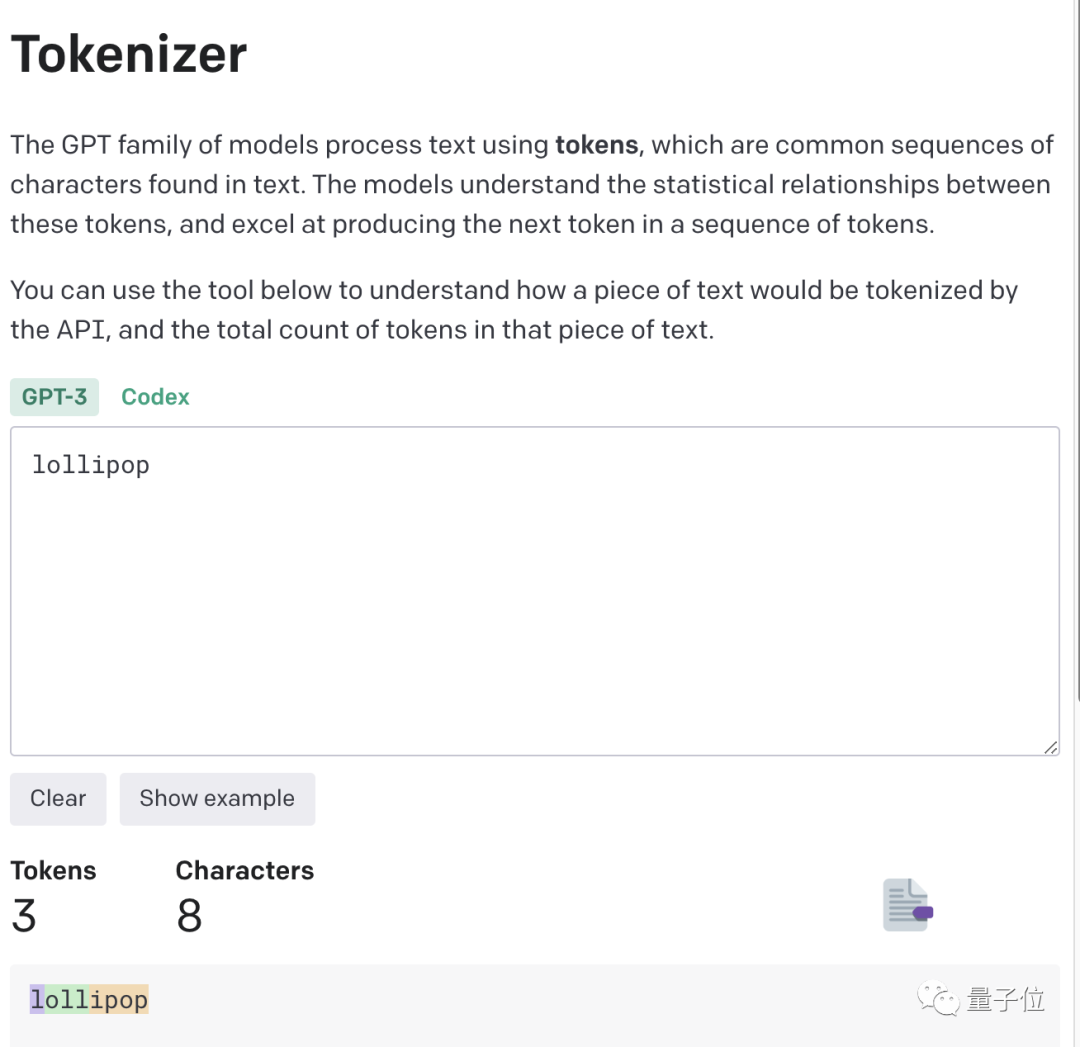
Par exemple, le mot sucette sera compris par GPT-3 comme trois parties : I, oll et ipop.
Basées sur l'expérience, certaines règles non écrites sont nées.
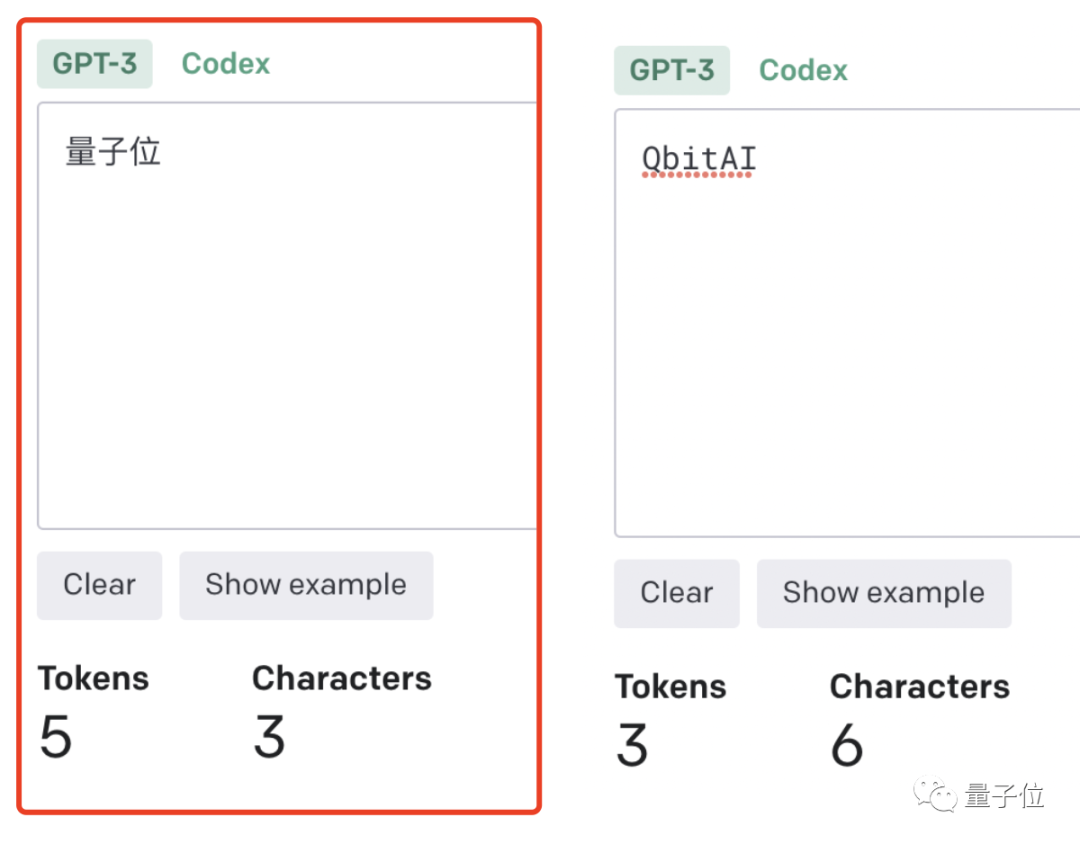
Plus le ratio jeton/caractère (jeton/mot) est élevé, plus le coût de traitement est élevé. Par conséquent, le traitement des tokens chinois est plus coûteux que celui de l’anglais.
Vous pouvez le comprendre de cette façon, le token est un moyen pour les grands modèles de comprendre le monde réel des humains. C'est très simple et réduit considérablement la complexité de la mémoire et du temps.
Mais il y a un problème avec la tokenisation des mots, ce qui rend difficile pour le modèle d'apprendre des représentations d'entrée significatives. La représentation la plus intuitive est qu'il ne peut pas comprendre la signification des mots.
Les transformateurs avaient été optimisés en conséquence à cette époque. Par exemple, un mot complexe et peu courant était divisé en un jeton significatif et un jeton indépendant.
Tout comme « ennuyeux » est divisé en deux parties : « ennuyeux » et « ly », le premier conserve son propre sens, tandis que le second est plus courant.
Cela a également abouti aux effets étonnants de ChatGPT et d'autres produits de grande taille aujourd'hui, qui peuvent très bien comprendre le langage humain.
Quant à l'incapacité de gérer une tâche aussi petite que l'inversion de mots, il existe naturellement une solution.
Le moyen le plus simple et le plus direct est de séparer d'abord les mots vous-même~

Ou vous pouvez laisser ChatGPT le faire étape par étape et symboliser d'abord chaque lettre.

Ou laissez-le écrire un programme qui inverse les lettres, et le résultat du programme sera correct. (tête de chien)

Cependant, GPT-4 peut également être utilisé, et il n'y a pas de problème de ce type dans les tests réels.

En bref, le jeton est la pierre angulaire de la compréhension du langage naturel par l'IA.
En tant que pont permettant à l'IA de comprendre le langage naturel humain, l'importance des jetons est devenue de plus en plus évidente.
C'est devenu un déterminant clé des performances des modèles d'IA et la norme de facturation pour les grands modèles.
Comme mentionné ci-dessus, les jetons peuvent faciliter la capture par le modèle d'informations sémantiques plus fines, telles que la signification des mots, l'ordre des mots, la structure grammaticale, etc. Dans les tâches de modélisation de séquences (telles que la modélisation du langage, la traduction automatique, la génération de texte, etc.), la position et l'ordre sont très importants pour la construction du modèle.
Ce n'est que lorsque le modèle comprend avec précision la position et le contexte de chaque jeton dans la séquence qu'il peut mieux prédire le contenu et donner un résultat raisonnable.
Par conséquent, la qualité et la quantité des jetons ont un impact direct sur l'effet du modèle.
À partir de cette année, lorsque de plus en plus de grands modèles seront publiés, le nombre de jetons sera souligné. Par exemple, les détails de l'exposition Google PaLM 2 mentionnaient qu'il utilisait 3,6 billions de jetons pour la formation.
Et de nombreux grands noms de l'industrie ont également déclaré que les jetons étaient vraiment cruciaux !
Andrej Karpathy, un scientifique en IA qui est passé de Tesla à OpenAI cette année, a déclaré dans son discours :
Plus de jetons peuvent permettre au modèle de mieux réfléchir.

Et il a souligné que les performances du modèle ne sont pas seulement déterminées par la taille du paramètre.
Par exemple, la taille des paramètres de LLaMA est beaucoup plus petite que celle de GPT-3 (65B contre 175B), mais comme il utilise plus de jetons pour l'entraînement (1,4T contre 300B), LLaMA est plus puissant.
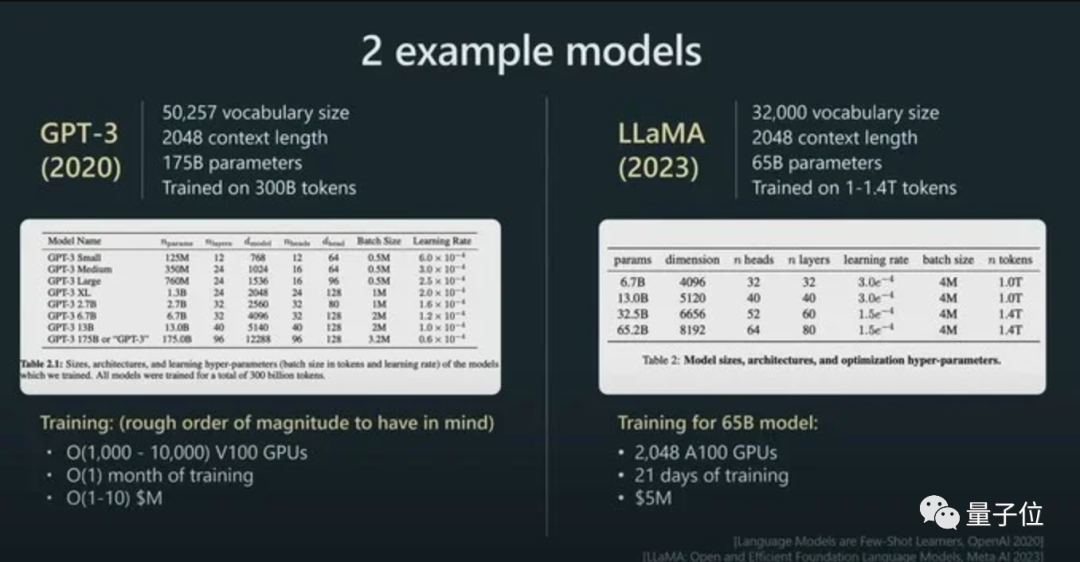
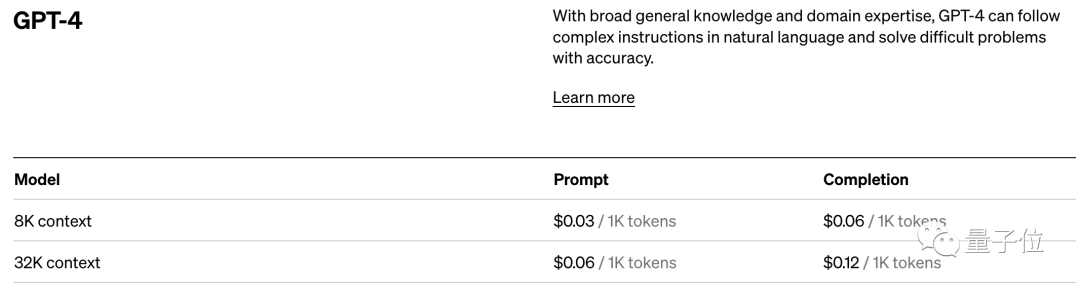
Et avec son impact direct sur les performances des modèles, le token est également la norme de facturation pour les modèles d'IA.
Prenons l'exemple de la norme de tarification d'OpenAI. Ils facturent par unités de 1 000 jetons. Différents modèles et différents types de jetons ont des prix différents.
En bref, une fois que vous entrez dans le domaine des grands modèles d'IA, vous constaterez que le token est un point de connaissance incontournable.
Eh bien, la littérature symbolique a même été dérivée...
Cependant, il convient de mentionner que la traduction du jeton dans le monde chinois n'a pas encore été complètement déterminée.
La traduction littérale de « jeton » est toujours un peu bizarre.
GPT-4 pense qu'il vaut mieux l'appeler « élément de mot » ou « tag », qu'en pensez-vous ?

Lien de référence :
[1]https://www.reddit.com/r/ChatGPT/comments/13xxehx/chatgpt_is_unable_to_reverse_words/
[2]https://help.openai.com/en/ articles/4936856-que-sont-les-jetons-et-comment-les-compter
[3]https://openai.com/pricing
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Le jeton de connexion n'est pas valide
Le jeton de connexion n'est pas valide
 Que faire si le jeton de connexion n'est pas valide
Que faire si le jeton de connexion n'est pas valide
 Comment obtenir un jeton
Comment obtenir un jeton
 Que signifie le jeton ?
Que signifie le jeton ?
 Les caractéristiques les plus importantes des réseaux informatiques
Les caractéristiques les plus importantes des réseaux informatiques
 Que signifie formater un téléphone mobile ?
Que signifie formater un téléphone mobile ?
 Utilisation de UpdatePanel
Utilisation de UpdatePanel
 Une collection de commandes informatiques couramment utilisées
Une collection de commandes informatiques couramment utilisées








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



