


Parlons des solutions de déploiement couramment utilisées dans MySQL.
Réplication MySQL est une solution de synchronisation maître-esclave officiellement fournie, utilisée pour synchroniser une instance MySQL avec une autre instance. La réplication a apporté d'importantes garanties pour garantir la sécurité des données et constitue actuellement la solution de reprise après sinistre MySQL la plus utilisée. La réplication utilise deux instances ou plus pour créer un cluster de réplication maître-esclave MySQL, fournissant des services d'écriture monopoint et de lecture multipoint, permettant ainsi une évolutivité de la lecture. MySQL Replication 是官方提供的主从同步方案,用于将一个 MySQL 的实例同步到另一个实例中。Replication 为保证数据安全做了重要的保证,是目前运用最广的 MySQL 容灾方案。Replication 用两个或以上的实例搭建了 MySQL 主从复制集群,提供单点写入,多点读取的服务,实现了读的 scale out。
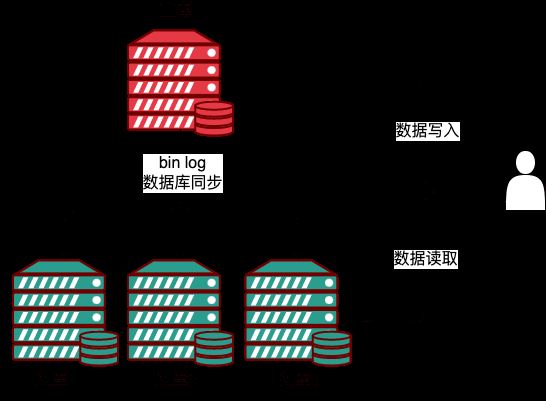
上面的栗子,一个主库(M),三个从库(S),通过 replication,Master 生成 event 的 binlog,然后发给 slave,Slave 将 event 写入 relaylog,然后将其提交到自身数据库中,实现主从数据同步。
对于数据库之上的业务层来说,基于 MySQL 的主从复制集群,单点写入 Master ,在 event 同步到 Slave 后,读逻辑可以从任何一个 Slave 读取数据,以读写分离的方式,大大降低 Master 的运行负载,同时提升了 Slave 的资源利用。
优点:
1、通过读写分离实现横向扩展的能力,写入和更新操作在源服务器上进行,从服务器中进行数据的读取操作,通过增大从服务器的个数,能够极大的增强数据库的读取能力;
2、数据安全,因为副本可以暂停复制过程,所以可以在副本上运行备份服务而不会破坏相应的源数据;
3、方便进行数据分析,可以在写库中创建实时数据,数据的分析操作在从库中进行,不会影响到源数据库的性能;
实现原理
在主从复制中,从库利用主库上的 binlog 进行重播,实现主从同步,复制的过程中蛀主要使用到了 dump thread,I/O thread,sql thread 这三个线程。
IO thread: 在从库执行 start slave 语句时创建,负责连接主库,请求 binlog,接收 binlog 并写入 relay-log;
dump thread:用于主库同步 binlog 给从库,负责响应从 IO thread 的请求。主库会给每个从库的连接创建一个 dump thread,然后同步 binlog 给从库;
sql thread:读取 relay log 执行命令实现从库数据的更新。
来看下复制的流程:
1、主库收到更新命令,执行更新操作,生成 binlog;
2、从库在主从之间建立长连接;
3、主库 dump_thread 从本地读取 binlog 传送刚给从库;
4、从库从主库获取到 binlog 后存储到本地,成为 relay log(中继日志);
5、sql_thread 线程读取 relay log 解析、执行命令更新数据。
不过 MySQL Replication
Dans l'exemple ci-dessus, il y a une bibliothèque maître (M) et trois bibliothèques esclaves (S). Par réplication, le maître génère le binlog de l'événement puis l'envoie à l'esclave. L'esclave écrit l'événement dans le relaylog et. puis le soumet à sa propre base de données pour réaliser la synchronisation des données maître-esclave. Pour la couche métier située au-dessus de la base de données, le cluster de réplication maître-esclave basé sur MySQL a un seul point d'écriture sur le maître. Une fois l'événement synchronisé avec l'esclave, la logique de lecture peut lire les données de n'importe quel esclave lors d'une lecture. -Manière de séparation d'écriture. , réduisant considérablement la charge de fonctionnement du maître et améliorant l'utilisation des ressources de l'esclave. Avantages : 1. La possibilité de réaliser une expansion horizontale grâce à la séparation de la lecture et de l'écriture. Les opérations d'écriture et de mise à jour sont effectuées sur le serveur source, et les opérations de lecture des données sont effectuées à partir du serveur. cela peut grandement améliorer la capacité de lecture de la base de données ; 2. La sécurité des données, car la copie peut suspendre le processus de réplication, de sorte que le service de sauvegarde peut être exécuté sur la copie sans détruire les données source correspondantes 3. pour l'analyse des données, vous pouvez créer des données en temps réel dans la base de données d'écriture, et l'opération d'analyse des données est effectuée dans la base de données esclave, ce qui n'affectera pas les performances de la base de données source Principe de mise en œuvreDans la réplication maître-esclave ; , la base de données esclave utilise le binlog de la base de données maître pour la relecture. Pour réaliser la synchronisation maître-esclave, les trois threads du
dump thread, du thread I/O et du thread sql sont principalement utilisés pendant le processus de copie. .
IO thread : Créé lorsque la bibliothèque esclave exécute l'instruction start slave Il est responsable de la connexion à la bibliothèque principale, de la demande de binlog, de la réception de binlog et de l'écriture dans relay-. log;
dump thread : utilisé pour synchroniser binlog de la bibliothèque principale vers la bibliothèque esclave, chargée de répondre aux requêtes du thread IO. La bibliothèque principale créera un dump thread pour chaque connexion à la bibliothèque esclave, puis synchronisera le binlog avec la bibliothèque esclave
sql thread : lisez le relay log code> Exécutez la commande pour mettre à jour les données de l'esclave. <p></p>Jetons un coup d'œil au processus de réplication : <p></p>1. La bibliothèque principale reçoit la commande de mise à jour, effectue l'opération de mise à jour et génère un binlog ; <p></p>2. La bibliothèque esclave établit une longue connexion entre le maître et l'esclave ; <p>3. La bibliothèque principale dump_thread slave Lit le binlog localement et l'envoie à la bibliothèque esclave </p>
<p>4. La bibliothèque esclave obtient le binlog de la bibliothèque principale et le stocke localement, devenant un <code>journal de relais ( journal de relais);
5. lecture du fil sql_thread Obtenez le journal de relais pour analyser et exécuter des commandes pour mettre à jour les données.
Cependant, la Réplication MySQL présente un sérieux inconvénient, qui est le retard dans la synchronisation maître-esclave.
2. Réplication entièrement synchrone : signifie que lorsque la bibliothèque principale termine une transaction et attend que toutes les bibliothèques esclaves aient également terminé la transaction, la bibliothèque principale soumet la transaction et renvoie les données au client. Parce que vous devez attendre que toutes les bibliothèques esclaves soient synchronisées avec les données de la bibliothèque maître avant de renvoyer les données, la cohérence des données maître-esclave peut être garantie, mais les performances de la base de données seront inévitablement affectées #🎜🎜 ; #
3. Réplication semi-synchrone : c'est une sorte de synchronisation entre une synchronisation complète et une synchronisation asynchrone complète. La bibliothèque principale doit attendre qu'au moins une bibliothèque esclave reçoive et écrive dans leRelay Log<.> fichier. La bibliothèque principale n'a pas besoin d'attendre que toutes les bibliothèques esclaves l'envoient à la bibliothèque principale. La bibliothèque principale reçoit un ACK, indiquant que la transaction est terminée et renvoie les données au client. <p><code>Relay Log 文件即可,主库不需要等待所有从库给主库返回 ACK。主库收到 ACK ,标识这个事务完成,返回数据给客户端。
MySQL 中默认的复制是异步的,所以主库和从库的同步会存在一定的延迟,更重要的是异步复制还可能引起数据的丢失。全同步复制的性能又太差了,所以从 MySQL 5.5 开始,MySQL 以插件的形式支持 semi-sync 半同步复制。
半同步复制潜在的问题
在传统的半同步复制中,主库写数据到 binlog,并且执行 commit 提交事务后,会一直等待一个从库的 ACK。从库会在写入 Relay Log 后,将数据落盘,然后回复给主库 ACK,主库收到这个 ACK 才能给客户端事务完成的确认。
这样会存在问题就是,主库已经将该事务的 commit 存储到了引擎层,应用已经可以看到数据的变化了,只是在等待从库的返回,如果此时主库宕机,可能从库还没有写入 Relay Log,就会发生主从库数据不一致。
为了解决这个问题,MySQL 5.7 引入了增强半同步复制。主库写入数据到 binlog 后,就开始等待从库的应答 ACK,直到至少一个从库写入 Relay Log 后,并将数据落盘,然后返回给主库 ACK,通知主库可以进行 commit 操作,然后主库再将事务提交到事务引擎,应用此时才能看到数据的变化。
不过看下来增强半同步复制,在同步给从库之后,因为自己的数据还没有提交,然后宕机了,主库中也是会存在数据的丢失,不过应该想到的是,这时候主库宕机了,是会重新在从库中选主的,这样新选出的主库数据是没有发生丢失的。
MySQL Group Replication 组复制,又称为 MGR。是 Oracle MySQL 于 2016 年 12 月发布 MySQL 5.7.17 推出的一个全新高可用和高扩展的解决方案。
引入复制组主要是为了解决传统异步复制和半同步复制可能产生数据不一致的问题。
MGR 由若干个节点共同组成一个复制组,一个事务的提交,必须经过组内大多数节点 (N / 2 + 1) 决议并通过,才能得以提交。
当客户端发起一个更新事务时,该事务先在本地执行,执行完成之后就要发起对事务的提交操作。需要在实际提交之前,将所产生的复制写集广播给其他成员进行复制。组中的成员只有在接收到事务广播时,才能全部接收或全部不接收,因为事务是原子性广播。如果组中的所有成员收到了该广播消息(事务),那么他们会按照之前发送事务的相同顺序收到该广播消息。因此,所有的组成员都会按照相同的顺序接收事务的写集,并为该事务建立全局顺序。因此,所有的组成员都会按照相同的顺序接收事务的写集,并为该事务建立全局顺序。
在不同组成员并发执行的事务可能存在冲突。冲突是通过检查和比较两个不同并发事务的 write setLa réplication par défaut dans MySQL est asynchrone, il y aura donc un certain retard dans la synchronisation de la base de données maître et de la base de données esclave. Plus important encore, la réplication asynchrone peut également entraîner une perte de données. Les performances de la réplication synchrone complète sont trop faibles, donc à partir de MySQL 5.5, MySQL prend en charge la réplication semi-synchrone semi-synchrone sous la forme d'un plug-in.
Problèmes potentiels avec la réplication semi-synchrone
Dans la réplication semi-synchrone traditionnelle, la bibliothèque principale écrit les données dans le journal binaire et exécute la validation pour valider la transaction. Elle attendra toujours. pour une bibliothèque esclave ACK. La bibliothèque esclave écrira les données sur le disque après avoir écrit le Relay Log, puis répondra à la bibliothèque maître avec un ACK. Ce n'est que lorsque la bibliothèque maître recevra cet ACK qu'elle pourra confirmer l'achèvement de la transaction. le client. 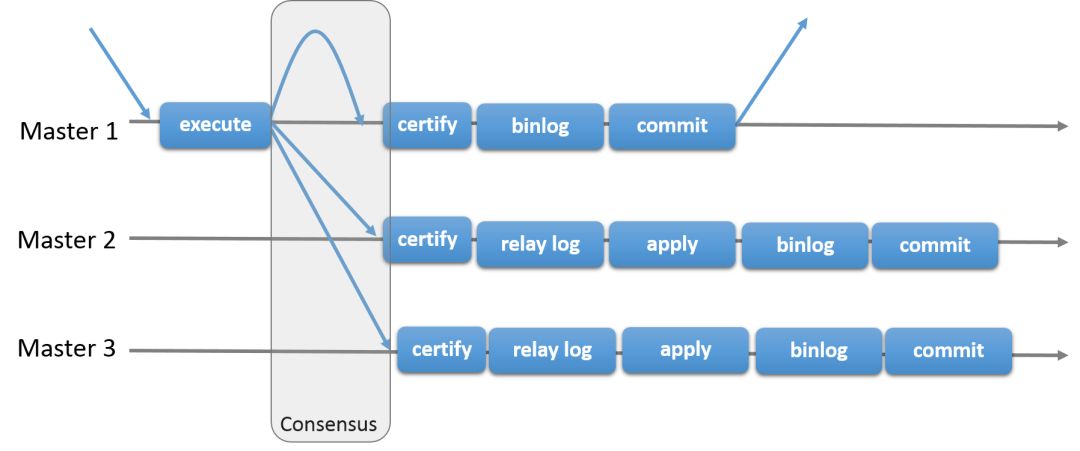
MySQL 5.7 introduit la réplication semi-synchrone améliorée. Une fois que la bibliothèque maître a écrit les données dans le journal binaire, elle commence à attendre la réponse ACK de la bibliothèque esclave jusqu'à ce qu'au moins une bibliothèque esclave écrive le Relay Log, écrit les données sur le disque, puis renvoie l'ACK à la bibliothèque principale pour notifier La bibliothèque principale peut effectuer une opération de validation, puis la bibliothèque principale soumet la transaction au moteur de transaction. Ce n'est qu'alors que l'application peut voir les modifications des données. Cependant, cela ressemble à une réplication semi-synchrone améliorée. Après la synchronisation avec la base de données esclave, comme ses propres données n'ont pas encore été soumises, puis tombent en panne, il y aura également une perte de données dans la base de données principale. base de données, mais vous devriez y penser. Oui, si la base de données maître est en panne à ce moment-là, le maître sera à nouveau sélectionné dans la base de données esclave, afin que les données de la base de données maître nouvellement sélectionnée ne soient pas perdues. #🎜🎜#Réplication de groupe MySQL Réplication de groupe, également connue sous le nom de MGR. Il s'agit d'une nouvelle solution à haute disponibilité et haute évolutivité lancée par Oracle MySQL avec MySQL 5.7.17 publié en décembre 2016. #🎜🎜##🎜🎜#L'introduction de groupes de réplication vise principalement à résoudre le problème d'incohérence des données qui peut survenir dans la réplication asynchrone traditionnelle et la réplication semi-synchrone. #🎜🎜##🎜🎜#MGR est constitué de plusieurs nœuds qui forment ensemble un groupe de réplication. La soumission d'une transaction doit être résolue et passée par la majorité des nœuds du groupe (N/2 + 1)code> avant de pouvoir être soumis. #🎜🎜##🎜🎜#Lorsque le client lance une transaction de mise à jour, la transaction est d'abord exécutée localement, et une fois l'exécution terminée, l'opération de validation de la transaction est lancée. L’ensemble d’écritures répliqué résultant doit être diffusé aux autres membres pour être répliqué avant la validation réelle. Les membres du groupe ne peuvent recevoir tout ou aucune des transactions que lorsqu'ils reçoivent la diffusion de la transaction, car la transaction est une diffusion atomique. Si tous les membres du groupe reçoivent le message diffusé (transaction), ils le reçoivent dans le même ordre dans lequel les transactions précédemment envoyées ont été envoyées. Par conséquent, tous les membres du groupe reçoivent les jeux d'écriture de la transaction dans le même ordre, établissant ainsi un ordre global pour la transaction. Par conséquent, tous les membres du groupe reçoivent les jeux d'écriture de la transaction dans le même ordre, établissant ainsi un ordre global pour la transaction. #🎜🎜##🎜🎜#Les transactions exécutées simultanément par des membres de différents groupes peuvent entrer en conflit. Les conflits sont vérifiés en examinant et en comparant le ensemble d'écriture de deux transactions simultanées différentes, un processus appelé authentification. Lors de l'authentification, la détection des conflits est effectuée au niveau de la ligne : si deux transactions simultanées exécutées sur des membres différents du groupe mettent à jour la même ligne de données, un conflit existe. Selon le mécanisme de détection d'authentification de conflit, dans l'ordre, la première transaction soumise sera exécutée normalement, la deuxième transaction soumise sera annulée sur le membre du groupe d'origine où la transaction a été initiée et les autres membres du groupe supprimeront la transaction. Si deux transactions entrent souvent en conflit, il est préférable d'exécuter les deux transactions dans le même membre du groupe, afin qu'elles aient une chance de s'engager avec succès sous la coordination du gestionnaire de verrous local, et non parce qu'elles sont dans deux des transactions. est fréquemment annulé en raison d'une authentification conflictuelle entre les différents membres du groupe. #🎜🎜##🎜🎜#Finalement, tous les membres du groupe reçoivent le même ensemble de transactions dans le même ordre. Afin d'assurer une forte cohérence des données au sein du groupe, les membres du groupe doivent effectuer les mêmes opérations de modification dans le même ordre. #🎜🎜##🎜🎜##🎜🎜##🎜🎜##🎜🎜# présente les caractéristiques suivantes : #🎜🎜##🎜🎜#1. Évitez le fractionnement du cerveau : il n'y aura pas de phénomène de fractionnement du cerveau dans MGR. ;#🎜🎜#2. Garantie de cohérence des données : MGR a de très bonnes capacités de redondance et peut garantir que Binlog Event est copié sur au moins plus de la moitié des membres, à condition que pas plus de la moitié des membres ne soient copiés. les membres sont en panne en même temps. Aucune perte de données ne se produira. MGR garantit également que tant que l'Événement Binlog n'est pas transmis à plus de la moitié des membres, les membres locaux n'écriront pas l'Événement Binlog de la transaction dans le fichier Binlog et ne valideront pas le transaction, garantissant ainsi les temps d'arrêt. Il n'y aura aucune donnée sur le serveur qui n'existe pas sur les membres en ligne du groupe. Par conséquent, une fois le serveur en panne redémarré, il ne nécessite plus de traitement spécial pour rejoindre le groupe ; Binlog Event 至少被复制到超过一半的成员上,只要同时宕机的成员不超过半数便不会导致数据丢失。MGR还保证只要 Binlog Event 没有被传输到半数以上的成员,本地成员不会将事务的 Binlog Event 写入 Binlog 文件和提交事务,从而保证宕机的服务器上不会有组内在线成员上不存在的数据。因此,宕机的服务器重启后,不再需要特殊的处理就可以加入组;
3、多节点写入支持:多写模式下支持集群中的所有节点都可以写入。
组复制的应用场景
1、弹性复制:需要非常灵活的复制基础设施的环境,其中MySQL Server的数量必须动态增加或减少,并且在增加或减少Server的过程中,对业务的副作用尽可能少。例如,云数据库服务;
2、高可用分片:分片是实现写扩展的一种流行方法。基于 组复制 实现的高可用分片,其中每个分片都会映射到一个复制组上(逻辑上需要一一对应,但在物理上,一个复制组可以承载多个分片);
3、替代主从复制:在某些情况下,使用一个主库会造成单点争用。在一些场景下,将数据同时写入组中多个成员,能给应用程序带来更好的可扩展性
4、自治系统:可以利用组复制内置的自动故障转移、数据在不同组成员之间的原子广播和最终数据一致性的特性来实现一些运维自动化。
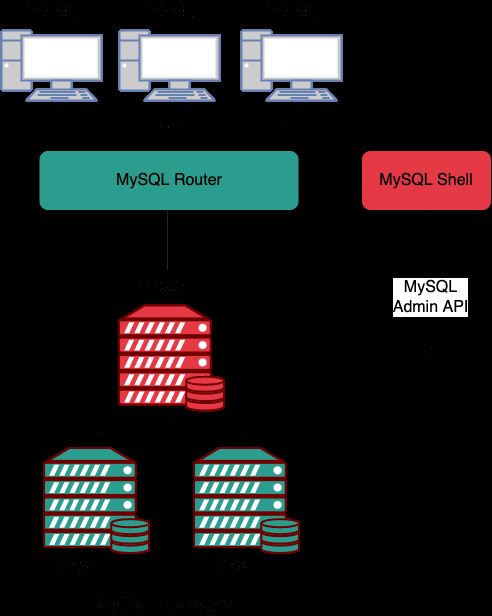
InnoDB Cluster 是官方提供的高可用方案,是 MySQL 的一种高可用性(HA)解决方案,它通过使用 MySQL Group Replication 来实现数据的自动复制和高可用性,InnoDB Cluster 通常包含下面三个关键组件:
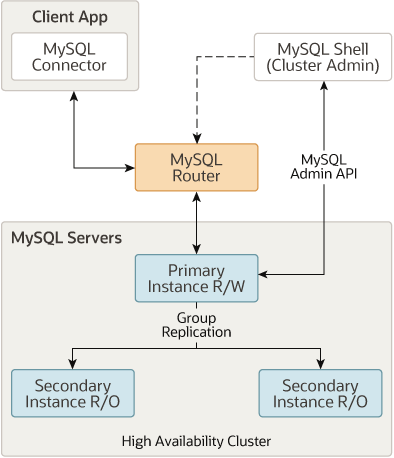
1、MySQL Shell: 它是 MySQL 的高级管理客户端;
2、MySQL Server 和 MGR,使得一组 MySQL 实例能够提供高可用性,对于 MGR,Innodb Cluster 提供了一种更加易于编程的方式来处理 MGR;
3、MySQL Router,一种轻量级中间件,主要进行路由请求,将客户端发送过来的请求路由到不同的 MySQL 服务器节点。
MySQL Server 基于 MySQL Group Replication 构建,提供自动成员管理,容错,自动故障转移动能等。InnoDB Cluster 通常以单主模式运行,一个读写实例和多个只读实例。不过也可以选用多主模式。
优点:
1、高可用性:通过 MySQL Group Replication,InnoDB Cluster 能够实现数据在集群中的自动复制,从而保证数据的可用性;
2、简单易用:InnoDB Cluster 提供了一个简单易用的管理界面,使得管理员可以快速部署和管理集群;
3、全自动故障转移: InnoDB Cluster 能够自动检测和诊断故障,并进行必要的故障转移,使得数据可以继续可用。
缺点:
1、复杂性:InnoDB Cluster 的部署和管理比较复杂,需要对 MySQL 的工作原理有一定的了解;
2、性能影响:由于自动复制和高可用性的要求,InnoDB Cluster 可能对 MySQL 的性能造成一定的影响;
3、限制:InnoDB Cluster 的功能对于一些特殊的应用场景可能不够灵活,需要更多的定制。
MySQL InnoDB ClusterSet 通过将主 InnoDB Cluster 与其在备用位置(例如不同数据中心)的一个或多个副本链接起来,为 InnoDB Cluster 部署提供容灾能力。
InnoDB ClusterSet 使用专用的 ClusterSet 复制通道自动管理从主集群到副本集群的复制。如果主集群由于数据中心损坏或网络连接丢失而变得无法使用,用户可以激活副本集群以恢复服务的可用性。
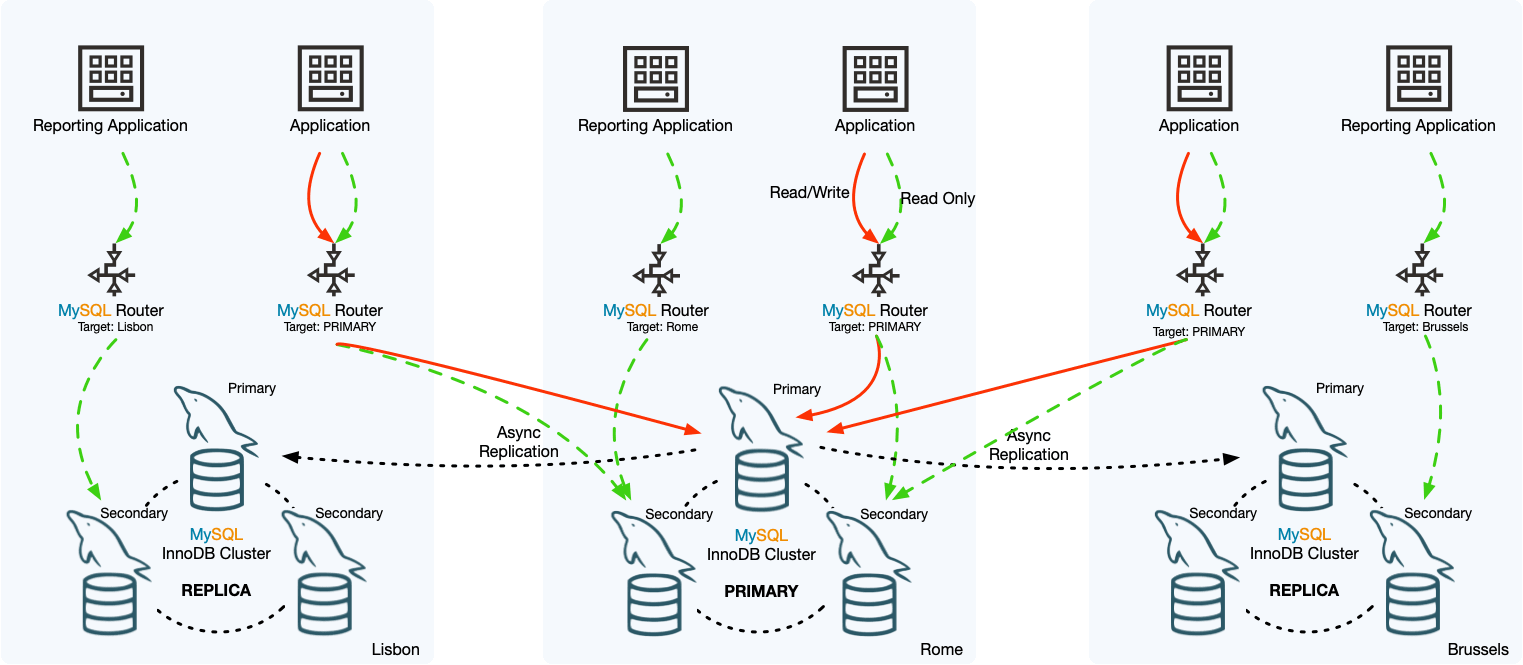
InnoDB ClusterSet 的特点:
1、主集群和副本集群之间的紧急故障转移可以由管理员通过 MySQL Shell
InnoDB Cluster est une solution officielle de haute disponibilité (HA) pour MySQL. code>Réplication de groupe MySQL pour obtenir une réplication automatique des données et une haute disponibilité, le InnoDB Cluster contient généralement les trois composants clés suivants : #🎜🎜##🎜🎜# #🎜🎜##🎜🎜#1 ,
#🎜🎜##🎜🎜#1 , MySQL Shell : C'est un client de gestion avancé pour MySQL ; #🎜🎜##🎜🎜#2, MySQL Server et MGR, faisant A Un groupe d'instances MySQL peut fournir une haute disponibilité pour MGR, Innodb Cluster fournit un moyen plus programmable de gérer MGR ;#🎜🎜##🎜🎜#3 , MySQL Router, un middleware léger qui achemine principalement les requêtes et achemine les requêtes envoyées par le client vers différents nœuds du serveur MySQL. #🎜🎜##🎜🎜#MySQL Server est construit sur MySQL Group Replication et fournit une gestion automatique des membres, une tolérance aux pannes, des capacités de basculement automatique, etc. InnoDB Cluster s'exécute généralement en mode maître unique, avec une instance en lecture-écriture et plusieurs instances en lecture seule. Cependant, vous pouvez également choisir le mode multi-maître. #🎜🎜##🎜🎜#Avantages : #🎜🎜##🎜🎜#1 Haute disponibilité : grâce à la Réplication de groupe MySQL, le InnoDB Cluster peut réaliser des données dans le cluster. Réplication automatique pour garantir la disponibilité des données ; #🎜🎜##🎜🎜#2. Facile à utiliser : InnoDB Cluster fournit une interface de gestion simple et facile à utiliser, permettant aux administrateurs de déployer rapidement un cluster de gestion. ; #🎜🎜##🎜🎜#3. Basculement entièrement automatique : InnoDB Cluster peut automatiquement détecter et diagnostiquer les pannes, et effectuer le basculement nécessaire pour que les données puissent continuer à être disponibles. #🎜🎜##🎜🎜#Inconvénients : #🎜🎜##🎜🎜#1 Complexité : Le déploiement et la gestion de InnoDB Cluster sont relativement complexes et nécessitent une certaine compréhension du principe de fonctionnement de MySQL. ; #🎜🎜##🎜🎜#2. Impact sur les performances : En raison des exigences de réplication automatique et de haute disponibilité, InnoDB Cluster peut avoir un certain impact sur les performances de MySQL #🎜🎜## ; 🎜🎜#3, Limitations : les fonctions de InnoDB Cluster peuvent ne pas être suffisamment flexibles pour certains scénarios d'application spéciaux et nécessitent plus de personnalisation. #🎜🎜#MySQL InnoDB ClusterSet En combinant le InnoDB Cluster principal avec celui qui se trouve dans un emplacement de sauvegarde (tel que un autre centre de données) Une ou plusieurs répliques sont liées entre elles pour fournir des capacités de reprise après sinistre pour un déploiement de InnoDB Cluster. #🎜🎜##🎜🎜#InnoDB ClusterSet Gère automatiquement la réplication du cluster maître vers le cluster réplica à l'aide d'un canal de réplication ClusterSet dédié. Si le cluster principal devient indisponible en raison de dommages au centre de données ou d'une perte de connectivité réseau, les utilisateurs peuvent activer le cluster de réplique pour restaurer la disponibilité du service. #🎜🎜##🎜🎜##🎜🎜##🎜🎜#Caractéristiques d'InnoDB ClusterSet : #🎜🎜##🎜🎜#1. Le basculement d'urgence entre le cluster principal et le cluster de réplique peut être effectué par l'administrateur via MySQL Shell, utilisez AdminAPI pour fonctionner ; #🎜🎜##🎜🎜#2 Il n'y a pas de limite définie sur le nombre de clusters de répliques pouvant être utilisés dans un déploiement InnoDB ClusterSet #🎜🎜#.<p>3. Le canal de réplication asynchrone réplique les transactions du cluster principal vers le cluster réplica. <code>clusterset_replication Lors du processus de création de InnoDB ClusterSet, un canal de réplication nommé ClusterSet est mis en place sur chaque cluster. Lorsque le cluster est une réplique, il utilise ce canal pour obtenir les données du cluster. cluster principal. Copiez la transaction. La technologie de réplication de groupe sous-jacente gère le canal et garantit que la réplication s'effectue toujours entre le serveur principal du cluster maître (en tant qu'expéditeur) et le serveur maître du cluster réplica (en tant que récepteur) ; . Pour chaque cluster InnoDB ClusterSet, seul le cluster principal peut recevoir des requêtes d'écriture. La plupart du trafic de requêtes de lecture sera également acheminé vers le cluster principal, mais vous pouvez également spécifier des requêtes de lecture vers d'autres clusters ; clusterset_replication 在 InnoDB ClusterSet 创建过程中,在每个集群上都设置了名为 ClusterSet 的复制通道,当集群是副本时,它使用该通道从主集群复制事务。底层组复制技术管理通道并确保复制始终在主集群的主服务器(作为发送方)和副本集群的主服务器(作为接收方)之间进行;
4、每个 InnoDB ClusterSet 集群,只有主集群能够接收写请求,大多数的读请求流量也会被路由到主集群,不过也可以指定读请求到其他的集群;
InnoDB ClusterSet 的限制:
1、InnoDB ClusterSet 只支持异步复制,不能使用半同步复制,无法避免异步复制的缺陷:数据延迟、数据一致性等;
2、InnoDB Cluster Set只支持单主模式的Cluster实例,不支持多主模式。 即只能包含一个读写主集群, 所有副本集群都是只读的, 不允许具有多个主集群的双活设置,因为在集群发生故障时无法保证数据一致性;
3、已有的 InnoDB Cluster 不能用作 InnoDB ClusterSet 部署中的副本集群。为了创建一个新的 InnoDB 集群,副本集群必须从单个服务器实例启动
4、只支持 MySQL 8.0。
InnoDB ReplicaSet 是 MySQL 团队在 2020 年推出的一款产品,用来帮助用户快速部署和管理主从复制,在数据库层仍然使用的是主从复制技术。
InnoDB ReplicaSet 由单个主节点和多个辅助节点(传统上称为 MySQL 复制源和副本)组成。
与 InnoDB cluster 类似, MySQL Router 支持针对 InnoDB ReplicaSet 的引导, 这意味着可以自动配置 MySQL Router 以使用 InnoDB ReplicaSet, 而无需手动配置文件. 这使得 InnoDB ReplicaSet 成为一种快速简便的方法, 可以启动和运行 MySQL 复制和 MySQL Router, 非常适合扩展读取, 并在不需要 InnoDB 集群提供高可用性的用例中提供手动故障转移功能。
InnoDB ReplicaSet 的限制:
1、没有自动故障转移,在主节点不可用的情况下,需要使用 AdminAPI 手动触发故障转移,然后才能再次进行任何更改。但是,辅助实例仍可用于读取;
2、由于意外停止或不可用,无法防止部分数据丢失:在意外停止时未完成的事务可能会丢失;
3、在意外退出或不可用后无法防止不一致。如果手动故障转移提升了一个辅助实例,而前一个主实例仍然可用,例如,由于网络分区,裂脑情况可能会导致数据不一致;
4、InnoDB ReplicaSet 不支持多主模式。允许写入所有成员的经典复制拓扑无法保证数据一致性;
5、读取横向扩展是有限的。InnoDB ReplicaSet 基于异步复制,因此无法像 Group Replication 那样调整流量控制;
6、一个 ReplicaSet 最多由一个主实例组成。支持一个或多个辅助。尽管可以添加到 ReplicaSet 的辅助节点的数量没有限制,但是连接到 ReplicaSet 的每个 MySQL Router 都必须监视每个实例。因此,一个 ReplicaSet 中加入的实例越多,监控就越多。
使用 InnoDB ReplicaSets 的主要原因是你有更好的写性能。使用 InnoDB ReplicaSets 的另一个原因是它们允许在不稳定或慢速网络上部署,而 InnoDB Cluster 则不允许。
MMM(Master-Master replication manager for MySQL)是一套支持双主故障切换和双主日常管理的脚本程序。MMM 使用 Perl 语言开发,主要用来监控和管理 MySQL Master-Master Limitations d'InnoDB ClusterSet :
1. InnoDB ClusterSet ne prend en charge que la réplication asynchrone et ne peut pas utiliser la réplication semi-synchrone. Il ne peut pas éviter les défauts de la réplication asynchrone : retard des données, cohérence des données, etc. ;
#🎜🎜 #2. InnoDB Cluster Set ne prend en charge que les instances de cluster en mode maître unique et ne prend pas en charge le mode multi-maître. Autrement dit, il ne peut contenir qu'un seul cluster maître en lecture-écriture, et tous les clusters de répliques sont en lecture seule. Les paramètres actifs-actifs avec plusieurs clusters maîtres ne sont pas autorisés car la cohérence des données ne peut pas être garantie en cas de panne du cluster ; 🎜🎜 #3. Le cluster InnoDB existant ne peut pas être utilisé comme cluster de réplique dans le déploiement InnoDB ClusterSet. Afin de créer un nouveau cluster InnoDB, le cluster de répliques doit être démarré à partir d'une seule instance de serveur 4 Prend uniquement en charge MySQL 8.0.
InnoDB ReplicaSet est un produit lancé par l'équipe MySQL en 2020 pour aider les utilisateurs à déployer et gérer rapidement la réplication maître-esclave. la technologie de réplication esclave est toujours utilisée au niveau de la couche de base de données. InnoDB ReplicaSet se compose d'un seul nœud principal et de plusieurs nœuds secondaires (traditionnellement appelés sources et répliques de réplication MySQL).
InnoDB cluster, le MySQL Router prend en charge le démarrage de InnoDB ReplicaSet, ce qui signifie qu'il peut être configuré automatiquementMySQL Router pour utiliser InnoDB ReplicaSet sans avoir besoin de fichiers de configuration manuels. Cela fait de InnoDB ReplicaSet un moyen rapide et facile de faire fonctionner MySQL. et MySQL Router, sont idéaux pour mettre à l'échelle les lectures et fournir des capacités de basculement manuel dans les cas d'utilisation qui ne nécessitent pas la haute disponibilité fournie par un cluster InnoDB. #🎜🎜##🎜🎜##🎜🎜##🎜🎜#InnoDB ReplicaSet : #🎜🎜##🎜🎜#1. Il n'y a pas de basculement automatique. Il doit être utilisé lorsque le maître Le nœud n'est pas disponible. AdminAPI déclenche manuellement un basculement avant que des modifications puissent être apportées à nouveau. Cependant, l'instance auxiliaire peut toujours être utilisée pour la lecture ;#🎜🎜##🎜🎜#2. Une perte partielle de données ne peut être évitée en raison d'un arrêt inattendu ou d'une indisponibilité : les transactions non terminées peuvent être perdues en cas d'arrêt inattendu ;#🎜🎜. ## 🎜🎜#3. Impossible d'éviter une incohérence après une sortie inattendue ou une indisponibilité. Si un basculement manuel favorise une instance secondaire alors que l'instance principale précédente est toujours disponible, par exemple en raison de partitions réseau, une situation de split-brain peut entraîner une incohérence des données ; #🎜🎜##🎜🎜#4. mode multi-maître . Les topologies de réplication classiques qui autorisent les écritures sur tous les membres ne peuvent pas garantir la cohérence des données ; #🎜🎜##🎜🎜#5 L'expansion horizontale des lectures est limitée. InnoDB ReplicaSet est basé sur la réplication asynchrone, il ne peut donc pas ajuster le contrôle de flux comme la Group Replication ; #🎜🎜##🎜🎜#6 ; exemple. Prend en charge un ou plusieurs auxiliaires. Bien qu'il n'y ait aucune limite quant au nombre de nœuds secondaires pouvant être ajoutés à un ReplicaSet, chaque routeur MySQL connecté au ReplicaSet doit surveiller chaque instance. Par conséquent, plus il y a d’instances ajoutées à un ReplicaSet, plus la surveillance est requise. #🎜🎜##🎜🎜#La principale raison d'utiliser InnoDB ReplicaSets est que vous avez de meilleures performances d'écriture. Une autre raison d'utiliser les InnoDB ReplicaSets est qu'ils permettent le déploiement sur des réseaux instables ou lents, ce que le InnoDB Cluster ne permet pas. #🎜🎜#MySQL Master-Master (double maître). On peut dire qu'il s'agit du gestionnaire de réplication MySQL maître-maître. #🎜🎜##🎜🎜#Mode double maître, en entreprise, une seule base de données maître peut écrire des données en même temps. L'autre base de données active et en veille effectuera la commutation et le basculement en cas de panne du serveur principal. #🎜🎜##🎜🎜#MMM utilise un mécanisme VIP (IP virtuelle) pour assurer la haute disponibilité du cluster. Dans l'ensemble du cluster, le nœud maître fournira une adresse VIP pour fournir des services de lecture et d'écriture de données. Lorsqu'une panne se produit, le nœud VIP sera transféré du nœud maître d'origine vers d'autres nœuds, et les autres nœuds fourniront des services. #🎜🎜##🎜🎜##🎜🎜##🎜🎜##🎜🎜#MMM ne peut pas garantir complètement la cohérence des données, il convient donc aux scénarios où les exigences de cohérence des données ne sont pas très élevées. (Étant donné que les données sur les serveurs principal et secondaire ne sont pas nécessairement les plus récentes, elles ne peuvent pas être plus récentes que la base de données esclave. Solution : activer la semi-synchronisation). #🎜🎜#Avantages et inconvénients de MMM
Avantages : haute disponibilité, bonne évolutivité, commutation automatique en cas de panne, pour la synchronisation maître-maître, une seule opération d'écriture dans la base de données est prévue en même temps pour assurer la cohérence des données sexuelles.
Inconvénients : La cohérence des données ne peut pas être complètement garantie. Il est recommandé d'utiliser la réplication semi-synchrone pour réduire la probabilité d'échec. Actuellement, la communauté MMM manque de maintenance et ne prend pas en charge la réplication basée sur GTID.
Scénarios applicables :
MMM convient aux scénarios dans lesquels l'accès à la base de données est important, la croissance de l'entreprise est rapide et la séparation en lecture et en écriture peut être obtenue.
Maîtrisez le gestionnaire et outils de haute disponibilité pour MySQL, appelé MHA. Il s'agit d'un excellent ensemble de logiciels à haute disponibilité pour le basculement et la promotion maître-esclave dans un environnement MySQL à haute disponibilité.
Cet outil est spécialement utilisé pour surveiller l'état de la bibliothèque principale. Lorsque le nœud maître s'avère défectueux, il promouvra automatiquement le nœud esclave avec de nouvelles données pour devenir le nouveau nœud maître. pendant cette période, MHA passera par d'autres nœuds esclaves pour obtenir des informations supplémentaires pour éviter les problèmes de cohérence des données. MHA fournit également une fonction permettant de mettre en ligne les nœuds maître-esclave, qui peuvent être commutés selon les besoins. MHA peut mettre en œuvre un basculement en 30 secondes tout en garantissant au maximum la cohérence des données.
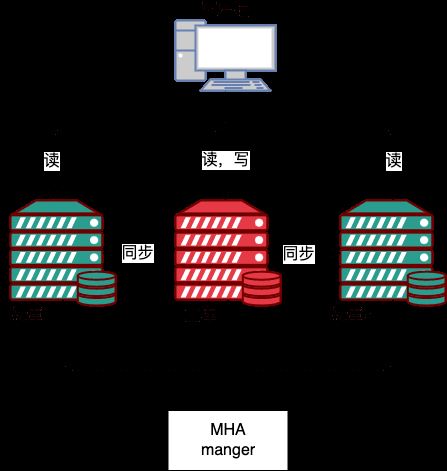
MHA se compose de deux parties
MHA Manager (nœud de gestion) et MHA Node (nœud de données).
MHA Manager peut être déployé sur une machine indépendante pour gérer plusieurs clusters maître-esclave, ou il peut être déployé sur un nœud esclave. MHA Node s'exécute sur chaque serveur MySQL. MHA Manager détectera régulièrement le nœud maître dans le cluster lorsque le maître échoue, il peut automatiquement promouvoir l'esclave avec les dernières données. vers le nouveau maître, puis redirigez tous les autres esclaves vers le nouveau maître. MHA Manager 可以单独部署在一台独立的机器上管理多个 master-slave 集群,也可以部署在一台 slave节点上。MHA Node 运行在每台 MySQL 服务器上,MHA Manager 会定时探测集群中的 master 节点,当 master 出现故障时,它可以自动将最新数据的 slave 提升为新的 master,然后将所有其他的 slave 重新指向新的 master。
整个故障转移过程对应用程序完全透明。
在 MHA 自动故障切换过程中,MHA 试图从宕机的主服务器上最大限度的保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,主服务器硬件故障或无法通过 ssh 访问,MHA 没法保存二进制日志,只进行故障转移而丢失了最新的数据。
使用 MySQL 5.5 开始找支持的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一个 slave 已经收到了最新的二进制日志,MHA 可以将最新的二进制日志应用于其他所有的 slave 服务器上,因此可以保证所有节点的数据一致性。
目前 MHA 主要支持一主多从的架构,要搭建 MHA,要求一个复制集群中必须最少有三台数据库服务器 ,一主二从,即一台 master,一台充当备用 master,另外一台充当从库,因为至少需要三台服务器。
MHA 工作原理总结如下:
1、从宕机崩溃的 master 保存二进制日志事件(binlog events);
2、识别最新更新的 slave;
3、应用差异的中继日志(relay log) 到其他slave;
4、应用从master保存的二进制日志事件(binlog events);
5、提升一个 slave 为新master;
6、使用其他的 slave 连接新的 master 进行复制。
优点:
1、可以支持基于 GTID 的复制模式;
2、MHA 在进行故障转移时更不易产生数据丢失;
3、同一个监控节点可以监控多个集群。
缺点:
1、需要编写脚本或利用第三方工具来实现 Vip 的配置;
2、MHA 启动后只会对主数据库进行监控;
3、需要基于 SSH 免认证配置,存在一定的安全隐患。
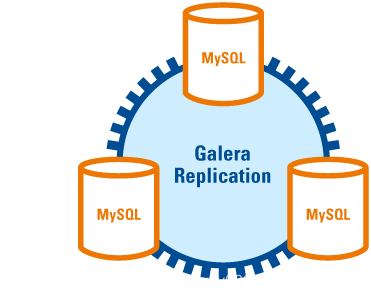
Galera Cluster 是由 Codership 开发的MySQL多主集群,包含在 MariaDB 中,同时支持 Percona xtradb、MySQL,是一个易于使用的高可用解决方案,在数据完整性、可扩展性及高性能方面都有可接受的表现。
其本身具有 multi-master 特性,支持多点写入,Galera Cluster
 Pendant le processus de basculement automatique de MHA, MHA essaie de sauvegarder au maximum le journal binaire du serveur principal en panne pour garantir que les données ne soient pas perdues au maximum, mais cela n'est pas toujours réalisable. Par exemple, si le matériel du serveur maître tombe en panne ou n'est pas accessible via ssh, MHA ne peut pas enregistrer le journal binaire et ne fait que basculer et perdre les dernières données.
Pendant le processus de basculement automatique de MHA, MHA essaie de sauvegarder au maximum le journal binaire du serveur principal en panne pour garantir que les données ne soient pas perdues au maximum, mais cela n'est pas toujours réalisable. Par exemple, si le matériel du serveur maître tombe en panne ou n'est pas accessible via ssh, MHA ne peut pas enregistrer le journal binaire et ne fait que basculer et perdre les dernières données.
Utilisez MySQL 5.5 pour commencer à rechercher une réplication semi-synchrone prise en charge, ce qui peut réduire considérablement le risque de perte de données. MHA peut être combiné avec une réplication semi-synchrone. Si un seul esclave a reçu le dernier journal binaire, MHA peut appliquer le dernier journal binaire à tous les autres serveurs esclaves, garantissant ainsi la cohérence des données sur tous les nœuds.
Actuellement, MHA prend principalement en charge une architecture à un maître et à plusieurs esclaves. Pour construire MHA, un cluster de réplication doit avoir au moins trois serveurs de base de données, un maître et deux esclaves, c'est-à-dire un maître et l'un sert de maître de sauvegarde et l'autre fait office de base de données esclave, car au moins trois serveurs sont nécessaires.
Le principe de fonctionnement de MHA est résumé comme suit :
1 Enregistrez les événements du journal binaire (événements binlog) du maître en panne ; . Identification Le dernier esclave mis à jour ;
3. Appliquer le journal de relais de différence aux autres esclaves
4. 🎜#5. Promouvez un esclave comme nouveau maître ;
6. Utilisez d'autres esclaves pour vous connecter au nouveau maître pour la réplication.
Avantages :
#🎜🎜#1. Peut prendre en charge le mode de réplication basé sur GTID ; #🎜🎜##🎜🎜#2. 🎜##🎜🎜#3. Le même nœud de surveillance peut surveiller plusieurs clusters. #🎜🎜##🎜🎜#Inconvénients : #🎜🎜##🎜🎜#1 Après le démarrage de MHA, ce sera uniquement La base de données principale est surveillée ; #🎜🎜##🎜🎜#3. Elle nécessite une configuration sans authentification basée sur SSH, ce qui présente certains risques de sécurité. #🎜🎜##🎜🎜#Galera Cluster#🎜🎜##🎜🎜#Galera Cluster est un cluster multi-maître MySQL développé par Codership, inclus dans MariaDB, et prend également en charge Percona xtradb , MySQL, est une solution haute disponibilité facile à utiliser avec des performances acceptables en termes d'intégrité des données, d'évolutivité et de hautes performances. #🎜🎜##🎜🎜#Il possède la fonctionnalité multi-maître et prend en charge l'écriture multipoint. Chaque instance du Galera Cluster est peer-to-peer, maître-esclave l'une par rapport à l'autre. Lorsque le client lit et écrit des données, il peut choisir n'importe quelle instance MySQL Pour les opérations de lecture, les données lues par chaque instance sont les mêmes. Pour les opérations d'écriture, lorsque des données sont écrites sur un nœud, le cluster les synchronise avec d'autres nœuds. Cette architecture ne partage aucune donnée et constitue une architecture hautement redondante. #🎜🎜##🎜🎜##🎜🎜##🎜🎜##🎜🎜#Fonctions principales#🎜🎜##🎜🎜#1. Réplication synchrone #🎜🎜##🎜🎜#2. c'est-à-dire que tous les nœuds peuvent lire et écrire dans la base de données en même temps ; #🎜🎜##🎜🎜#3. Contrôle automatique des membres du nœud, les nœuds défaillants sont automatiquement effacés ; #🎜🎜##🎜🎜#4. les données et copient automatiquement ;# 🎜🎜##🎜🎜#5. Véritable réplication parallèle, au niveau de la ligne ; #🎜🎜##🎜🎜#6. . #🎜🎜##🎜🎜#Avantage#🎜🎜#1. Cohérence des données : la réplication synchrone garantit la cohérence des données de l'ensemble du cluster. Chaque fois que la même requête de sélection est exécutée sur un nœud, les résultats seront les mêmes ;
2. : car toutes les données des nœuds sont cohérentes et un crash d'un seul nœud ne nécessite pas de basculement complexe et fastidieux, et n'entraînera pas non plus de perte de données ou d'interruption de service ;
3. tous les nœuds du cluster exécutent des transactions en parallèle pour améliorer les performances de lecture et d'écriture ;
4, latence client plus petite
5, avec des capacités d'extension de lecture et d'écriture.
Analyse du principe
Galera Cluster utilise principalement la réplication synchrone. Une seule transaction de mise à jour dans la bibliothèque principale doit être mise à jour de manière synchrone dans tous les esclaves. bibliothèques. , lorsque la base de données principale valide la transaction, les données de tous les nœuds du cluster restent cohérentes. Galera Cluster 中主要用到了同步复制,主库中的单个更新事务需要在所有从库中同步更新,当主库提交事务,集群中的所有节点数据保持一致。
异步复制,主库将数据更新传播给从库后立即提交事务,而不论从库是否成功读取或重放数据变化,所以异步复制会存在短暂的,主从数据同步不一致的情况出现。
不过同步复制的缺点也是很明显的,同步复制协议通常使用两阶段提交或分布式锁协调不同节点的操作,也及时说节点越多需要协调的节点也就越多,那么事务冲突和死锁的概率也就会随之增加。
我们知道 MGR 组复制的引入也是为了解决传统异步复制和半同步复制可能产生数据不一致的问题,MGR 中的组复制,基于 Paxos 协议,原则上事务的提交,主要大多数节点 ACK 就可以提交了。
Galera Cluster 中的同步需要同步数据到所有节点,保证所有节点都成功。基于专有通信组系统 GCommon ,所有节点都必须有 ACK。
Galera 复制是一种基于验证的复制,基于验证的复制使用通信和排序技术实现同步复制,通过广播并发事务之间建立的全局总序来协调事务提交。简单的讲就是事务必须以相同的顺序应用于所有实例。
事务现在本地执行,然后发送的其他节点做冲突验证,没有冲突的时候所有节点提交事务,否则在所有节点回滚。
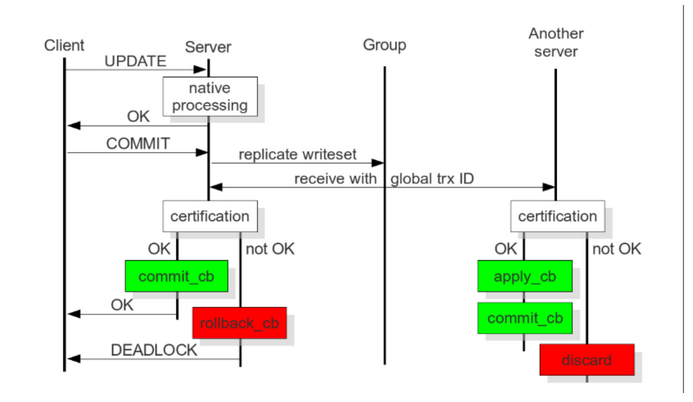
当客户端发出 commit 命令时,在实际提交之前,对数据所做的更改都会收集到一个写集合中,写集合中包含事务信息和所更改行的主键,数据库将写集发送到其它节点。
节点用写集中的主键与当前节点中未完成事务的所有写集的主键比较,确定节点是否可以提交事务,同时满足下面三个条件会被任务存在冲突,验证失败:
1、两个事务来源于不同节点;
2、两个事务包含相同的主键;
3、老事务对新事务不可见,即老事务未提交完成。新老事务的划定依赖于全局事务总序,即 GTID。
每个节点独立进行验证,如果验证失败,该节点将删除写集并回滚原始事务,所有节点都会执行相同的操作。所有节点按照相同顺序接收事务,导致它们都做出相同的结果决定,要么全部成功,要么全部失败。成功后自然就提交了,所有的节点又会重新达到数据一致的状态。节点之间不交换“是否冲突”的信息,各个节点独立异步处理事务。
MySQL Cluster 是一个高度可扩展的,兼容 ACID 事务的实时数据库,基于分布式架构不存在单点故障,MySQL Cluster 支持自动水平扩容,并能做自动的读写负载均衡。
MySQL Cluster 使用了一个叫 NDB 的内存存储引擎来整合多个 MySQL 实例,提供一个统一的服务集群。
NDB是一种采用不共享的Sharding-Nothing架构的内存存储引擎。Sarding-Nothing 指的是每个节点有独立的处理器,磁盘和内存,节点之间没有共享资源完全独立互不干扰,节点之间通过告诉网络组在一起,每个节点相当于是一个小型的数据库,存储部分数据。这种架构的好处是可以利用节点的分布性并行处理数据,调高整体的性能,还有就是有很高的水平扩展性能,只需要增加节点就能增加数据的处理能力。
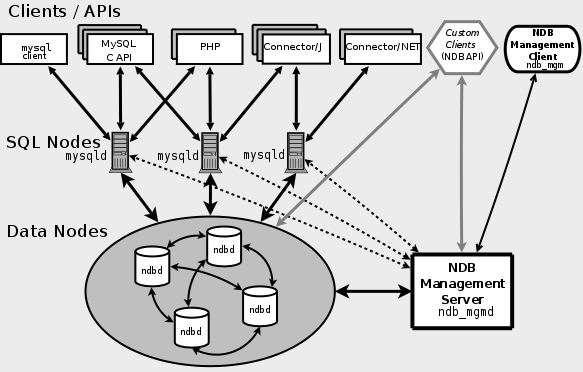
MySql Cluster 中包含三种节点,分别是管理节点(NDB Management Server)、数据节点(Data Nodes)和 SQL查询节点(SQL Nodes) 。
SQL Nodes 是应用程序的接口,像普通的 mysqld 服务一样,接受用户的 SQL 输入,执行并返回结果。Data Nodes 是数据存储节点,NDB Management Server
Galera Cluster nécessite la synchronisation des données sur tous les nœuds pour garantir que tous les nœuds réussissent. Basé sur le système de groupe de communication propriétaire GCommon, tous les nœuds doivent avoir un ACK. #🎜🎜##🎜🎜#La réplication Galera est une sorte de réplication basée sur la vérification. La réplication basée sur la vérification utilise la technologie de communication et de tri pour réaliser une réplication synchrone et coordonne la soumission des transactions en diffusant l'ordre total global établi entre les transactions simultanées. En termes simples, les transactions doivent être appliquées à toutes les instances dans le même ordre. #🎜🎜##🎜🎜#La transaction est désormais exécutée localement, puis envoyée aux autres nœuds pour vérification du conflit. Lorsqu'il n'y a pas de conflit, tous les nœuds valident la transaction, sinon elle est annulée sur tous les nœuds. #🎜🎜##🎜🎜##🎜🎜##🎜🎜#Lorsque le client émet la commande de validation, avant la validation réelle, les modifications apportées aux données seront collectées dans une collection d'écriture, qui contient les informations de transaction et les lignes modifiées. Clé primaire , la base de données envoie le jeu d'écriture à d'autres nœuds. #🎜🎜##🎜🎜#Le nœud compare la clé primaire de l'ensemble d'écriture avec les clés primaires de tous les ensembles d'écriture de transactions inachevées dans le nœud actuel pour déterminer si le nœud peut soumettre la transaction si les trois conditions suivantes sont remplies. en même temps, la tâche sera en conflit et la vérification échouera : #🎜🎜##🎜🎜#1 Les deux transactions proviennent de nœuds différents #🎜🎜##🎜🎜#2. clé primaire ; #🎜🎜##🎜🎜#3. L'ancienne paire de transactions La nouvelle transaction n'est pas visible, c'est-à-dire que l'ancienne transaction n'a pas été soumise et terminée. La délimitation des nouvelles et anciennes transactions dépend de l'ordre total de la transaction globale, c'est-à-dire du GTID. #🎜🎜##🎜🎜#Chaque nœud effectue la vérification indépendamment. Si la vérification échoue, le nœud supprimera le jeu d'écriture et annulera la transaction d'origine, et tous les nœuds effectueront la même opération. Tous les nœuds reçoivent les transactions dans le même ordre, ce qui les amène tous à prendre la même décision, soit tous réussissent, soit tous échouent. Après succès, il sera soumis naturellement et tous les nœuds atteindront à nouveau un état de données cohérent. Aucune information sur les « conflits » n'est échangée entre les nœuds et chaque nœud traite les transactions de manière indépendante et asynchrone. #🎜🎜#MySQL Cluster est une base de données en temps réel hautement évolutive et compatible avec les transactions ACID qui n'a pas de point de défaillance unique basé sur un système distribué. L'architecture MySQL Cluster prend en charge l'expansion horizontale automatique et peut effectuer un équilibrage automatique de la charge en lecture et en écriture. #🎜🎜##🎜🎜#MySQL Cluster utilise un moteur de stockage en mémoire appelé NDB pour intégrer plusieurs instances MySQL et fournir un cluster de services unifié. #🎜🎜##🎜🎜#NDB est un moteur de stockage mémoire utilisant l'architecture Sharding-Nothing. Sarding-Nothing signifie que chaque nœud dispose d'un processeur, d'un disque et d'une mémoire indépendants. Il n'y a pas de ressources partagées entre les nœuds et ils sont complètement indépendants et n'interfèrent pas les uns avec les autres. Les nœuds sont regroupés via un réseau équivalent. une petite base de données, stocke certaines données. L'avantage de cette architecture est qu'elle peut utiliser la distribution des nœuds pour traiter les données en parallèle et améliorer les performances globales. Elle offre également des performances d'expansion horizontale élevées. Le simple ajout de nœuds peut augmenter les capacités de traitement des données. #🎜🎜##🎜🎜##🎜🎜##🎜🎜#MySql Cluster contient trois types de nœuds, à savoir le nœud de gestion (NDB Management Server), le nœud de données (Data Nodes) et le nœud de requête SQL (SQL Nodes) . #🎜🎜##🎜🎜#SQL Nodes est l'interface du programme d'application, comme le service mysqld ordinaire, il accepte les entrées SQL de l'utilisateur, exécute et renvoie les résultats. Les Data Nodes sont des nœuds de stockage de données et le NDB Management Server est utilisé pour gérer chaque nœud du cluster. #🎜🎜#Le nœud de données stockera les partitions de données et les copies de partitions dans le cluster. Voyons comment le MySql Cluster effectue les opérations de partitionnement sur les données. Tout d'abord, comprenons les concepts suivants #🎜. 🎜#MySql Cluster 是如何对数据进行分片的操作的,首先来了解下下面几个概念
节点组(Node Group): 一组数据节点的集合。节点组的个数=节点数 / 副本数;
比如有集群中 4 个节点,副本数为 2(对应 NoOfReplicas 的设置),那么节点组个数为2。
另外,在可用性方面,数据的副本在组内交叉分配,一个节点组内只有要一台机器可用,就可以保证整个集群的数据完整性,实现服务的整体可用。
分区(Partition):MySql Cluster 是一个分布式的存储系统,数据按照 分区 划分成多份存储在各数据节点中,分区个数由系统自动计算,分区数 = 数据节点数 / LDM 线程数;
副本(Replica):分区数据的备份,有几个分区就有几个副本,为了避免单点,保证 MySql Cluster 集群的高可用,原始数据对应的分区和副本通常会保存在不同的主机上,在一个节点组内进行交叉备份。
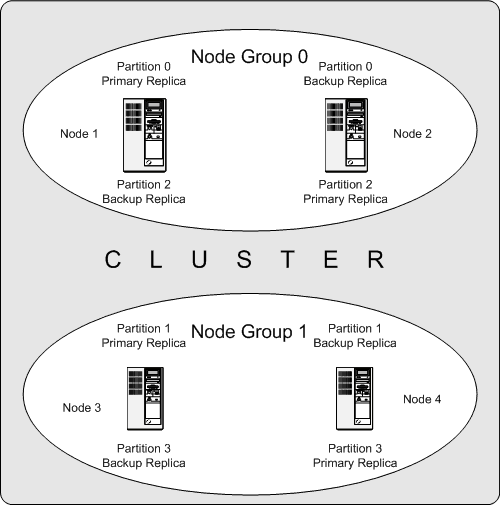
栗如,上面的例子,有四个数据节点(使用ndbd),副本数为2的集群,节点组被分为2组(4/2),数据被分为4个分区,数据分配情况如下:
分区0(Partition 0)保存在节点组 0(Node Group 0)中,分区数据(主副本 — Primary Replica)保存在节点1(node 1) 中,备份数据(备份副本,Backup Replica)保存在节点2(node 2) 中;
分区1(Partition 1)保存在节点组 1(Node Group 1)中,分区数据(主副本 — Primary Replica)保存在节点3(node 3) 中,备份数据(备份副本,Backup Replica)保存在节点4(node 4) 中;
分区2(Partition 2)保存在节点组 0(Node Group 0)中,分区数据(主副本 — Primary Replica)保存在节点2(node 2) 中,备份数据(备份副本,Backup Replica)保存在节点1(node 1) 中;
分区3(Partition 2)保存在节点组 1(Node Group 1)中,分区数据(主副本 — Primary Replica)保存在节点4(node 4) 中,备份数据(备份副本,Backup Replica)保存在节点3(node 3) 中;
这样,对于一张表的一个 Partition 来说,在整个集群有两份数据,并分布在两个独立的 Node 上,实现了数据容灾。同时,每次对一个 Partition 的写操作,都会在两个 Replica 上呈现,如果 Primary Replica 异常,那么 Backup Replica 可以立即提供服务,实现数据的高可用。
mysql cluster 的优点
1、99.999%的高可用性;
2、快速的自动失效切换;
3、灵活的分布式体系结构,没有单点故障;
4、高吞吐量和低延迟;
5、可扩展性强,支持在线扩容。
mysql cluster 的缺点
1、存在很多限制,比如:不支持外键,数据行不能超过8K(不包括BLOB和text中的数据);
2、部署、管理、配置很复杂;
3、占用磁盘空间大,内存大;
4、备份和恢复不方便;
5、重启的时候,数据节点将数据 load 到内存需要很长时间。
MySQL Fabric 会组织多个 MySQL 数据库,将大的数据分散到多个数据库中,即数据分片(Data Shard),同时同一个分片数据库中又是一个主从结构,Fabric 会挑选合适的库作为主库,当主库挂掉的时候,又会重新在从库中选出一个主库。
MySQL Fabric 的特点:
1、高可用;
2、使用数据分片的横向功能。
MySQL Fabric-aware 连接器把从 MySQL Fabric 获取的路由信息存储到缓存中,然后凭借该信息将事务或查询发送给正确的 MySQL 服务器。
同时,每一个分片组,可以又多个一个服务器组成,构成主从结构,当主库挂掉的时候,又会重新在从库中选出一个主库。保证节点的高可用。
HA Group 保证访问指定 HA Group 的数据总是可用的,同时其基础的数据复制是基于 MySQL ReplicationNode Group : Une collection de nœuds de données. Le nombre de groupes de nœuds =Nombre de nœuds/Nombre de réplicas;
Par exemple, il y a 4 nœuds dans le cluster et le nombre de réplicas est de 2 (correspondant au paramètre de NoOfReplicas), puis le nombre de groupes de nœuds Le nombre est 2. 
MySql Cluster est un système de stockage distribué. Les données sont divisées en plusieurs parties selon les partitions et stockées dans chaque nœud de données. Le nombre de partitions est automatiquement déterminé par le. système. Calcul, nombre de partitions = nombre de nœuds de données/nombre de threads LDM ; Réplique : sauvegarde des données de partition, il y aura plusieurs copies pour autant de partitions que de partitions. possible, afin d'éviter qu'un point unique assure la haute disponibilité du cluster MySql Cluster. Les partitions et copies correspondant aux données d'origine sont généralement stockées sur différents hôtes et sauvegardées de manière croisée au sein d'un groupe de nœuds. . #🎜🎜##🎜🎜##🎜🎜##🎜🎜#Li Ru, dans l'exemple ci-dessus, il y a quatre nœuds de données (utilisant ndbd), un cluster avec un numéro de réplique de 2, le groupe de nœuds est divisé en 2 groupes (4/ 2), les données sont divisées en 4 partitions et la répartition des données est la suivante : #🎜🎜##🎜🎜#Partition 0 (Partition 0) est stockée dans le groupe de nœuds 0 (groupe de nœuds 0) et les données de partition (réplique principale - Réplique principale) est stockée dans le nœud 1 (nœud 1), les données de sauvegarde (réplique de sauvegarde, réplique de sauvegarde) sont enregistrées dans le nœud 2 (nœud 2) #🎜🎜##🎜🎜# ; La partition 1 (Partition 1) est enregistrée dans le groupe de nœuds 1 (Node Group 1), les données de partition (réplique principale - Réplique principale) sont stockées dans le nœud 3 (nœud 3) et les données de sauvegarde (réplique de sauvegarde, réplique de sauvegarde ) est stocké dans le nœud 4 (nœud 4) ; #🎜🎜##🎜🎜# La partition 2 est stockée dans le groupe de nœuds 0, les données de partition (réplique principale) sont stockées dans le nœud 2 et les données de sauvegarde (réplique de sauvegarde) sont stockées dans le nœud 2. 1 (nœud 1 ), les données de sauvegarde (Backup Replica) sont stockées dans le nœud 3 (nœud 3) ; #🎜🎜##🎜🎜#De cette façon, pour une partition de une table, il y a deux copies des données dans l'ensemble du cluster, et distribuées sur deux nœuds indépendants, réalisant la reprise après sinistre des données. Dans le même temps, chaque opération d'écriture sur une partition sera présentée sur deux réplicas. Si la Réplique principale est anormale, alors la Réplique de sauvegarde peut fournir des services immédiatement pour obtenir une efficacité élevée des données. . Disponible. #🎜🎜##🎜🎜#cluster mysql Avantages#🎜🎜##🎜🎜#1, haute disponibilité à 99,999% #🎜🎜##🎜🎜#2, basculement automatique rapide #🎜🎜 ; ##🎜🎜#3. Architecture distribuée flexible, pas de point de défaillance unique ; #🎜🎜##🎜🎜#4. Débit élevé et faible latence ; #🎜🎜#5. expansion. #🎜🎜##🎜🎜#mysql cluster Inconvénients#🎜🎜##🎜🎜#1 Il existe de nombreuses restrictions, telles que : les clés étrangères ne sont pas prises en charge et les lignes de données ne peuvent pas dépasser 8 Ko (à l'exclusion. BLOB et texte); #🎜🎜##🎜🎜#2 Le déploiement, la gestion et la configuration sont compliqués #🎜🎜##🎜🎜#3. Cela prend beaucoup d'espace disque et de mémoire ; 🎜🎜# 4. La sauvegarde et la récupération ne sont pas pratiques ; #🎜🎜##🎜🎜#5. Lors du redémarrage, le nœud de données met beaucoup de temps à charger les données dans la mémoire. #🎜🎜#MySQL Fabric organisera plusieurs bases de données MySQL et dispersera les données volumineuses dans plusieurs bases de données, c'est-à-dire le partage de données(Data Shard ), en même temps, il existe une structure maître-esclave dans la même base de données partitionnée. Fabric sélectionnera la bibliothèque appropriée comme bibliothèque maître. Lorsque la bibliothèque maître échoue, elle effectuera une nouvelle sélection dans la bibliothèque esclave. .Une bibliothèque principale. #🎜🎜##🎜🎜#MySQL Fabric Caractéristiques : #🎜🎜##🎜🎜#1 Haute disponibilité ; #🎜🎜##🎜🎜#2. #🎜🎜##🎜🎜#MySQL Fabric-aware Le connecteur stocke les informations de routage obtenues à partir de MySQL Fabric dans le cache, puis envoie la transaction ou la requête en fonction de celles-ci. information Donnez le bon serveur MySQL. #🎜🎜##🎜🎜#Dans le même temps, chaque groupe de partitionnement peut être composé de plusieurs serveurs pour former une structure maître-esclave. Lorsque la base de données maître raccroche, une base de données maître sera à nouveau sélectionnée dans la base de données esclave. Assurer la haute disponibilité des nœuds. #🎜🎜##🎜🎜#HA Group garantit que l'accès aux données du HA Group spécifié est toujours disponible et que sa réplication de base des données est basée sur Réplication MySQL implémentée. #🎜🎜##🎜🎜##🎜🎜##🎜🎜##🎜🎜#Inconvénients#🎜🎜##🎜🎜#Les transactions et les requêtes ne sont prises en charge qu'au sein de la même partition, et les données mises à jour dans la transaction ne peuvent pas traverser les partitions , les données renvoyées par l'instruction de requête ne peuvent pas traverser les partitions. #🎜🎜#Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



