


Introduction#🎜🎜 ## 🎜🎜#
Comment créer un Chatbot spécifique à l'entreprise qui vous comprend mieux sur la base d'une base de données vectorielle + LLM (Large Language Model) ? 1 Pourquoi Chatbot a-t-il besoin d'un grand modèle de langage + base de données vectorielles ?
Ce printemps, le produit technologique le plus choquant est l'émergence de ChatGPT, qui permet aux gens de voir ce que l'IA générative peut réaliser grâce à de grands modèles de langage (LLM) Avec la capacité Pour exprimer un langage très similaire au langage humain, l'IA n'est plus hors de portée et peut désormais entrer dans le travail et la vie humaine. Cela a revitalisé le domaine de l'IA qui était en sommeil depuis un certain temps, et d'innombrables praticiens se précipitent. pour s'y consacrer. La prochaine opportunité de changer les temps ; selon des statistiques incomplètes, en seulement 4 mois, les États-Unis ont réalisé plus de 4 000 financements de l'industrie de l'IA générative. Dans la prochaine génération technologique, l’IA générative est devenue une partie incontournable du capital et des entreprises, et un niveau plus élevé de capacités d’infrastructure est de plus en plus nécessaire pour soutenir son développement.
# 🎜 🎜#
Les grands modèles peuvent répondre à des questions plus universelles, mais s'ils veulent servir des domaines professionnels verticaux, il y aura des problèmes de connaissances insuffisantes et d'opportunité. Alors, comment les entreprises peuvent-elles saisir les opportunités et créer des domaines verticaux. ? Servir? Il existe actuellement deux modèles. Le premier est Fine Tune, qui est un modèle de domaine vertical basé sur un grand modèle. Il a un coût d'investissement global important et une faible fréquence de mise à jour, et le second est de construire le modèle. Les propres actifs de connaissances de l'entreprise dans la base de données vectorielle et la création de services approfondis dans des domaines verticaux via de grands modèles + bases de données vectorielles. L'essence est d'utiliser la base de données pour une ingénierie rapide. Les entreprises peuvent utiliser des catégories verticales de dispositions juridiques et de précédents pour créer des services de technologie juridique dans des domaines spécifiques tels que le secteur juridique. Par exemple, Harvey, une entreprise de technologie juridique, construit un « Copilot for Lawyer » pour améliorer les services de rédaction et de recherche juridiques. L'extraction de documents de la base de connaissances d'entreprise et d'informations en temps réel via des fonctionnalités vectorielles, puis leur stockage dans une base de données vectorielle, combinée au grand modèle de langage LLM, peut rendre les réponses du Chatbot (robot de questions et réponses) plus professionnelles et plus rapides, et créer une entreprise. Chatbot spécifique.
# 🎜 🎜#
basé sur un grand modèle de langage# 🎜🎜 #Laissez Chatbot mieux répondre aux questions d'actualité ? Bienvenue sur le compte vidéo "Alibaba Cloud Yaochi Database" pour regarder la démo Demo.
# 🎜 🎜# Cet article se concentrera ensuite sur les principes et les processus de création d'un Chatbot spécifique à l'entreprise basé sur un grand modèle de langage (LLM) + une base de données vectorielle, ainsi que sur les capacités de base d'ADB-PG pour construire ce scénario.2. base de données ?
Dans le monde réel, la plupart des données sont sous forme non structurée, comme les images, l'audio, les vidéos et le texte. Avec l’émergence des villes intelligentes, des courtes vidéos, des recommandations de produits personnalisées, de la recherche visuelle de produits et d’autres applications, ces données non structurées ont connu une croissance explosive. Afin de pouvoir traiter ces données non structurées, nous utilisons généralement la technologie de l'intelligence artificielle pour extraire les caractéristiques de ces données non structurées et les convertir en vecteurs de caractéristiques, puis analyser et récupérer ces vecteurs de caractéristiques pour atteindre l'objectif d'analyse des données non structurées. traitement. Par conséquent, nous appelons une base de données capable de stocker, d’analyser et de récupérer des vecteurs de caractéristiques une base de données vectorielles.
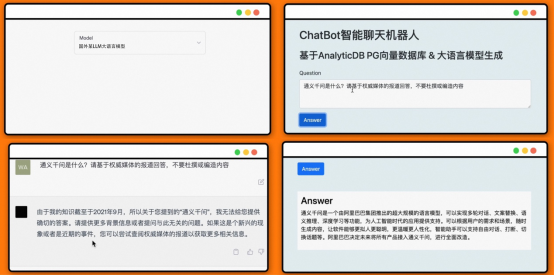
Pour une récupération rapide des vecteurs de caractéristiques, les bases de données vectorielles utilisent généralement les moyens techniques de construction d'index vectoriels. Les index vectoriels dont nous parlons habituellement appartiennent à l'ANNS (Recherche des voisins les plus proches, Recherche des voisins les plus proches). Il se limite à renvoyer uniquement les éléments de résultat les plus précis, mais recherche uniquement les éléments de données qui peuvent être les plus proches voisins, c'est-à-dire en sacrifiant un peu de précision dans la plage acceptable en échange d'une efficacité de récupération améliorée. C'est également la plus grande différence entre les bases de données vectorielles et les bases de données traditionnelles. Actuellement, dans les environnements de production réels, il existe deux pratiques principales dans l'industrie pour appliquer plus facilement l'indice vectoriel ANNS. L'une consiste à gérer séparément l'index vectoriel ANNS pour fournir des capacités de création et de récupération d'index vectoriels, formant ainsi une base de données vectorielles propriétaire. L'autre consiste à intégrer l'index vectoriel ANNS dans une base de données structurée traditionnelle pour former un SGBD doté de capacités de récupération vectorielle ; Dans les scénarios commerciaux réels, les bases de données vectorielles propriétaires doivent souvent être utilisées conjointement avec d'autres bases de données traditionnelles, ce qui entraînera des problèmes courants, tels qu'une redondance des données, une migration excessive des données, des problèmes de cohérence des données, etc. Par rapport à un véritable SGBD, un système propriétaire La base de données vectorielle nécessite une maintenance professionnelle supplémentaire, des coûts supplémentaires et des capacités de langage de requête, une programmabilité, une évolutivité et une intégration d'outils très limitées. Le SGBD qui intègre la fonction de récupération de vecteurs est différent C'est tout d'abord une plateforme de base de données moderne très complète qui peut répondre aux besoins en fonction de base de données des développeurs d'applications puis elle intègre Vector ; les capacités de récupération peuvent également implémenter les fonctions de bases de données vectorielles propriétaires et permettre au stockage et à la récupération de vecteurs d'hériter des excellentes capacités du SGBD, telles que la facilité d'utilisation (en utilisant directement SQL pour traiter les vecteurs), les transactions, la haute disponibilité et la haute évolutivité. bientôt. L'ADB-PG présenté dans cet article est un SGBD avec fonction de récupération de vecteurs. Il inclut non seulement une fonction de récupération de vecteurs, mais dispose également de capacités de base de données à guichet unique. Avant de présenter les capacités spécifiques d'ADB-PG, examinons d'abord le processus de création et les principes associés de Chatbot dans la vidéo de démonstration. Pour la vidéo de démonstration précédente, combinez le grand modèle de langage LLM et ADB-PG commentera l'actualité. À titre d'exemple de réponse, laissez LLM répondre "Qu'est-ce que Tongyi Qianwen". On peut voir que si nous demandons à LLM de répondre directement, la réponse obtenue n'a aucun sens car l'ensemble de données de formation LLM ne contient pas de contenu pertinent. Et lorsque nous utilisons la base de données vectorielles comme stockage de connaissances locales et laissons LLM extraire automatiquement les connaissances pertinentes, il a correctement répondu « Qu'est-ce que Tongyi Qianwen ». Réponse à "Qu'est-ce que Tongyi Qianwen" L'ensemble de données couvre les documents, les PDF, les e-mails s, informations réseau et autres contenus. Par exemple : a Processus de traitement et de stockage des données back-end b. en même temps, sa couche inférieure repose principalement sur deux modules : 1 Module d'inférence basé sur un grand modèle de langage 2. base de données L La partie noire dans l'image ci-dessus se trouve le processus de traitement des données back-end, il s'agit principalement de résoudre l'intégration de nos données originales et de les stocker avec les données originales dans la base de données vectorielle ADB-PG. Ici, il vous suffit de prêter attention à la partie bleue en pointillés de l’image ci-dessus. Module de traitement du noir et base de données vectorielles ADB-PG. 1. Partie d'affinage des questions ; connaissances pertinentes ; 3. Partie inférence et solution. Ici, nous devons nous concentrer sur la partie orange. Il peut être un peu obscur de parler uniquement du principe, mais nous utiliserons l'exemple ci-dessus pour illustrer. # 🎜 🎜#L Part1 Question Raffinement# 🎜🎜# Cette partie est facultative et existe car certaines questions doivent dépendre du contexte de. Car les nouvelles questions posées par l'utilisateur risquent de ne pas permettre à LLM de comprendre les intentions de l'utilisateur. # 🎜 🎜#Par exemple, la nouvelle question de l'utilisateur est « Que peut-il faire ? » LLM ne sait pas à qui il fait référence et doit combiner l'historique des discussions précédentes, tel que « Qu'est-ce que Tongyi Qianwen » pour en déduire la question indépendante à laquelle l'utilisateur doit répondre « Que peut faire Tongyi Qianwen ? LLM ne peut pas répondre correctement à la question vague « À quoi sert-il », mais il peut répondre correctement à la question indépendante « À quoi sert Tongyi Qianwen ». Si votre problème est autonome, vous n'avez pas besoin de cette section. # 🎜 🎜#Après avoir obtenu le problème indépendant, nous pouvons trouver l'intégration de ce problème indépendant basé sur ce problème indépendant. Recherchez ensuite dans la base de données vectorielles les vecteurs les plus similaires afin de trouver le contenu le plus pertinent. Ce comportement fait partie des fonctionnalités du plugin de récupération Part2. # 🎜 🎜#Part2 Récupération de vecteur La fonction d'intégration indépendante des problèmes sera exécutée dans le modèle text2vec . Après avoir obtenu l'intégration, vous pouvez utiliser cette intégration pour rechercher à l'avance les données stockées dans la base de données vectorielles. Par exemple, nous avons stocké le contenu suivant dans ADB-PG. Nous pouvons obtenir le contenu ou les connaissances les plus similaires grâce au vecteur obtenu, tel que le premier et le troisième élément. Tongyi Qianwen est..., Tongyi Qianwen peut nous aider xxx. # 🎜 🎜# Après avoir obtenu les connaissances les plus pertinentes, nous pouvons laisser LLM effectuer un raisonnement de solution basé sur les connaissances les plus pertinentes et des questions indépendantes pour obtenir la réponse finale. Voici la réponse à la question "A quoi sert Tongyi Qianwen" en combinant les informations les plus efficaces telles que "Tongyi Qianwen est...", "Tongyi Qianwen peut nous aider xxx" et ainsi de suite. En fin de compte, la solution d'inférence de GPT ressemble à ceci : Pourquoi ADB - PG est-il adapté comme base de connaissances pour Chatbot ? ADB-PG est un entrepôt de données cloud natif doté de capacités de traitement parallèle à grande échelle. Il prend en charge les modes de stockage de lignes et de colonnes, qui peuvent non seulement fournir un traitement de données hors ligne hautes performances, mais également prendre en charge l'analyse et l'interrogation en ligne à haute concurrence de données massives. Par conséquent, nous pouvons dire qu'ADB-PG est une plate-forme d'entrepôt de données qui prend en charge les transactions distribuées et les charges mixtes, et prend également en charge le traitement d'une variété de sources de données non structurées et semi-structurées. Par exemple, le plug-in de récupération vectorielle permet une récupération et une analyse vectorielles hautes performances de données non structurées telles que des images, des langues, des vidéos et des textes, ainsi qu'une récupération et une analyse de texte intégral de données semi-structurées telles que JSON. Par conséquent, dans le scénario AIGC, ADB-PG peut être utilisé comme base de données vectorielles pour répondre à ses besoins de stockage et de récupération de vecteurs, et peut également répondre au stockage et à la requête d'autres données structurées et peut également fournir des capacités de recherche en texte intégral, offrant ainsi une solution unique pour les applications métier dans les scénarios AIGC. Ci-dessous, nous présenterons en détail les trois capacités d'ADB-PG : la récupération de vecteurs, la récupération par fusion et la récupération de texte intégral. Les fonctions de récupération de vecteurs et de récupération de fusion ADB-PG ont été lancées pour la première fois sur le cloud public en 2020 et sont désormais largement utilisées dans le domaine de la reconnaissance faciale. La base de données vectorielle d'ADB-PG est héritée de la plate-forme d'entrepôt de données, elle présente donc presque tous les avantages du SGBD, tels que ANSISQL, les transactions ACID, la haute disponibilité, la récupération sur panne, la récupération à un moment précis, la programmabilité, l'évolutivité, etc. Dans le même temps, il prend en charge les recherches de similarité vectorielle et vectorielle de la distance du produit scalaire, de la distance de Hamming et de la distance euclidienne. Ces fonctions sont actuellement largement utilisées dans la reconnaissance faciale, la reconnaissance de produits et la recherche sémantique textuelle. Avec l’explosion de l’AIGC, ces fonctionnalités constituent une base solide pour les chatbots textuels. De plus, le moteur de récupération de vecteurs ADB-PG utilise également les instructions Intel SIMD pour obtenir une correspondance de similarité vectorielle extrêmement efficace. Ci-dessous, nous utilisons un exemple spécifique pour illustrer comment utiliser la récupération de vecteurs et la récupération de fusion d'ADB-PG. Supposons qu'il existe une base de connaissances textuelle, qui divise un lot d'articles en morceaux et les convertit en vecteurs d'intégration avant d'entrer dans la base de données. La table des morceaux contient les champs suivants : . Ensuite, le DDL de création de table correspondant est le suivant :
Afin d'accélérer la récupération des vecteurs, nous devons également créer un index vectoriel En même temps, afin d'accélérer les requêtes de fusion structurées vectorielles, nous devons également créer des index pour les colonnes structurées couramment utilisées : Lors de l'insertion de données, nous pouvons directement utiliser la syntaxe d'insertion SQL : #🎜 🎜# # 🎜🎜#
# 🎜 🎜#ADB-PG dispose également de riches fonctions de recherche en texte intégral, prenant en charge des conditions de combinaison complexes, le classement des résultats et d'autres capacités de recherche. De plus, pour les ensembles de données chinois, ADB-PG prend également en charge les fonctions de segmentation de mots chinois, qui peuvent traiter efficacement les textes chinois ; et segmentation de mots personnalisée ; en même temps, ADB-PG prend également en charge l'utilisation d'index pour accélérer les performances de récupération et d'analyse du texte intégral. Ces capacités peuvent également être pleinement utilisées dans les scénarios commerciaux AIGC. Par exemple, l'entreprise peut effectuer un rappel bidirectionnel de documents de la base de connaissances combiné aux capacités de récupération de vecteurs et de récupération de texte intégral mentionnées ci-dessus. # 🎜 🎜#La partie recherche de la base de données de connaissances comprend la récupération traditionnelle de texte intégral par mot-clé et la récupération de texte intégral par mot-clé garantit l'exactitude de la requête. La récupération de caractéristiques vectorielles fournit une généralisation et une correspondance sémantique, rappelle-t-il. connaissances avec correspondance sémantique, réduire le taux de non-résultat, fournir un contexte plus riche pour les grands modèles et faciliter la synthèse et l'induction de grands modèles de langage. Combiné avec ce qui a été mentionné plus tôt dans Contenu de cet article, si vous comparez le Chatbot compétent à 人 , alors le grand modèle de langage peut être vu comme ce que Chatbot a obtenu de tous les livres et informations publiques dans divers domaines avant obtenir un diplôme universitaire Connaissances et apprentissage des compétences de raisonnement. Par conséquent, sur la base d'un modèle de langage étendu, Chatbot peut répondre à des questions liées à son diplôme, mais si la question concerne un domaine professionnel spécifique (les informations pertinentes sont la propriété de l'organisation de l'entreprise et ne sont pas publiques) ou un nouveau concept d'espèce (il s'agit d'un domaine professionnel spécifique). n'est pas encore sorti à la sortie de l'université) Naissance), il est impossible de l'aborder sereinement en s'appuyant uniquement sur les connaissances acquises à l'école (correspondant à de grands modèles de langage pré-formés. Il faut disposer de canaux pour continuer à acquérir). de nouvelles connaissances après l'obtention du diplôme (telles que des bases de données d'apprentissage professionnel liées au travail), combinées à vos propres capacités d'apprentissage et de raisonnement, pour apporter une réponse professionnelle. Le même Chatbot doit combiner les capacités d'apprentissage et de raisonnement des grands modèles de langage avec une base de données unique comme ADB-PG qui contient des capacités de récupération vectorielle et de récupération de texte intégral (qui stocke les documents de connaissances propriétaires et les plus récents de l'entreprise et caractéristiques vectorielles) et fournir des réponses plus professionnelles et plus rapides basées sur le contenu des connaissances de la base de données lors de la réponse aux questions. 3. Grand modèle de langage LLM + ADB-PG : créez un chatbot spécifique à l'entreprise
Système de questions et réponses de connaissances locales de cas
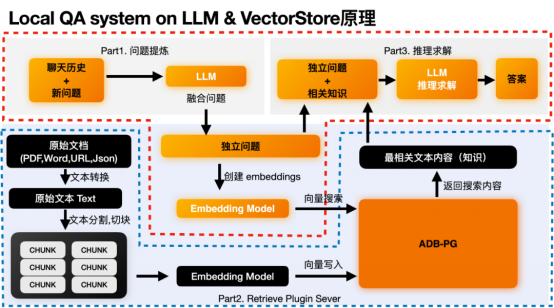
Principe de mise en œuvreLangage du système d'assurance qualité local Les capacités de raisonnement du modèle et le stockage et capacités de récupération de la base de données vectorielles. Obtenez les fragments sémantiques les plus pertinents grâce à la récupération vectorielle et utilisez-les comme base pour que de grands modèles de langage raisonnent en conjonction avec le contexte des fragments pertinents afin de tirer des conclusions correctes. Il y a deux processus principaux dans ce processus :
Traitement et stockage des données back-end processus
# 🎜🎜 #
Ce processus est principalement divisé en trois parties : 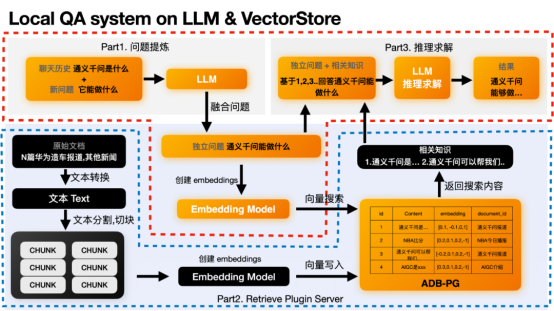
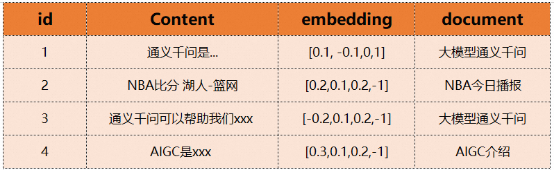

4. récupération de texte
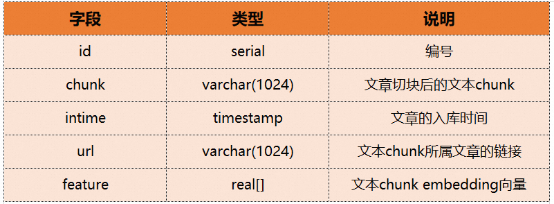




De même, si notre besoin est de trouver une certaine date au cours du mois dernier L'article source de chaque texte. Ensuite, nous pouvons effectuer une recherche directement via la recherche par fusion. Le SQL spécifique est le suivant : 🎜 Après avoir lu les exemples ci-dessus, nous constatons clairement que l'utilisation de la récupération vectorielle et de la récupération par fusion dans ADB-PG est aussi pratique que l'utilisation d'une base de données traditionnelle, sans aucun seuil d'apprentissage. Parallèlement, nous avons également réalisé de nombreuses optimisations ciblées pour la récupération vectorielle, telles que la compression de données vectorielles, la construction parallèle d'index vectoriels, la récupération parallèle multipartition vectorielle, etc., qui ne seront pas détaillées ici. 
Class
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Qu'est-ce que j2ee
Qu'est-ce que j2ee
 Quelles sont les méthodes pour se connecter au serveur vps
Quelles sont les méthodes pour se connecter au serveur vps
 Comment transformer deux pages en un seul document Word
Comment transformer deux pages en un seul document Word
 Comment créer un clone WeChat sur un téléphone mobile Huawei
Comment créer un clone WeChat sur un téléphone mobile Huawei
 Quels sont les moyens de dégager les flotteurs ?
Quels sont les moyens de dégager les flotteurs ?
 largeur de décalage
largeur de décalage
 Que dois-je faire si le disque temporaire ps est plein ?
Que dois-je faire si le disque temporaire ps est plein ?
 Tableau de mots réparti sur plusieurs pages
Tableau de mots réparti sur plusieurs pages








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



