


Vous saisissez du texte et laissez l'IA générer une vidéo. Cette idée n'est apparue auparavant que dans l'imagination des gens. Aujourd'hui, avec le développement de la technologie, cette fonction a été réalisée.
Ces dernières années, l'intelligence artificielle générative a attiré une grande attention dans le domaine de la vision par ordinateur. Avec l’avènement des modèles de diffusion, la génération d’images de haute qualité à partir d’invites textuelles, c’est-à-dire la synthèse texte-image, est devenue très populaire et couronnée de succès.
Des recherches récentes ont tenté d'étendre avec succès les modèles de diffusion texte-image à la tâche de génération et d'édition texte-vidéo en les réutilisant dans le domaine vidéo. Bien que ces méthodes aient donné des résultats prometteurs, la plupart d’entre elles nécessitent une formation approfondie utilisant de grandes quantités de données étiquetées, ce qui peut s’avérer trop coûteux pour de nombreux utilisateurs.
Afin de rendre la génération vidéo moins chère, Tune-A-Video proposé par Jay Zhangjie Wu et al a introduit l'année dernière un mécanisme appliqué au modèle de diffusion stable (SD). au domaine vidéo. Une seule vidéo doit être ajustée, ce qui réduit considérablement la charge de travail de formation. Bien que cette méthode soit beaucoup plus efficace que les méthodes précédentes, elle nécessite néanmoins une optimisation. De plus, les capacités de génération de Tune-A-Video sont limitées aux applications de montage vidéo guidées par texte, et la composition de vidéos à partir de zéro reste au-delà de ses capacités.
Dans cet article, des chercheurs de Picsart AI Research (PAIR), de l'Université du Texas à Austin et d'autres institutions, en tir zéro et sans formation, dans le texte pour Une avancée dans la nouvelle problématique de la synthèse vidéo, qui consiste à générer des vidéos à partir d'invites textuelles sans aucune optimisation ni mise au point.

Voyons comment ça marche. Par exemple, un panda surfe ; un ours danse à Times Square : #Cette recherche peut aussi générer des actions basées sur des objectifs : #🎜🎜 #
De plus, il peut effectuer une détection de contour :
 Un concept clé de la méthode proposée dans cet article est la modification Des modèles texte-image pré-entraînés (par exemple Diffusion stable) l'enrichissent d'une génération cohérente dans le temps. En s'appuyant sur des modèles texte-image déjà formés, notre approche exploite leur excellente qualité de génération d'images, améliorant ainsi leur applicabilité au domaine vidéo sans nécessiter de formation supplémentaire.
Un concept clé de la méthode proposée dans cet article est la modification Des modèles texte-image pré-entraînés (par exemple Diffusion stable) l'enrichissent d'une génération cohérente dans le temps. En s'appuyant sur des modèles texte-image déjà formés, notre approche exploite leur excellente qualité de génération d'images, améliorant ainsi leur applicabilité au domaine vidéo sans nécessiter de formation supplémentaire.
Afin de renforcer la cohérence temporelle, cet article propose deux modifications innovantes : (1) D'abord enrichir l'encodage latent de l'image générée avec des informations de mouvement pour maintenir la scène globale et le temps d'arrière-plan De manière cohérente ; (2) un mécanisme d'attention inter-images est ensuite utilisé pour préserver le contexte, l'apparence et l'identité des objets de premier plan tout au long de la séquence. Les expériences montrent que ces modifications simples peuvent produire des vidéos de haute qualité et cohérentes dans le temps (illustré dans la figure 1).

Alors que d'autres personnes travaillent sur des données vidéo à grande échelle, notre approche permet d'obtenir des performances similaires et parfois meilleures (illustrés dans les figures 8, 9). La méthode décrite dans cet article ne se limite pas à la synthèse texte-vidéo, mais convient également aux vidéos conditionnelles (voir Figure 6, 5) et spécialisées. génération (voir Figure 7) et montage vidéo guidé par des instructions, qui peut être appelé Video Instruct-Pix2Pix piloté par Instruct-Pix2Pix (voir Figure 9). Dans cet article, cet article utilise la capacité de synthèse texte-image de Stable Diffusion (SD) pour gérer la tâche de texte-vidéo en zéro -situations de tir. Pour les besoins de génération de vidéo plutôt que de génération d'images, SD doit se concentrer sur le fonctionnement des séquences de code sous-jacentes. L'approche naïve consiste à échantillonner indépendamment m codes potentiels à partir d'une distribution gaussienne standard, c'est-à-dire 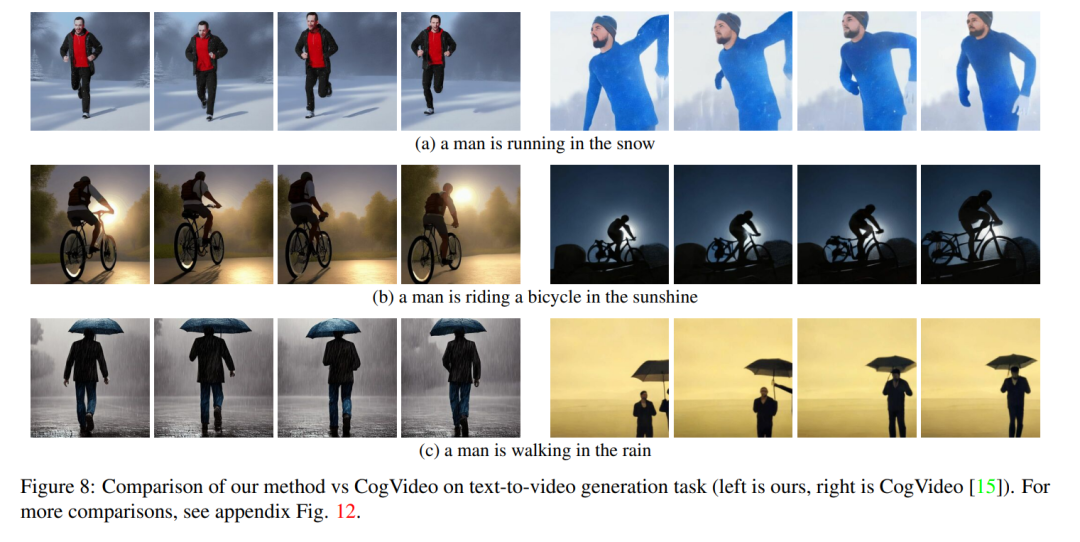



, où k = 1,…,m, sont ensuite décodés pour obtenir la séquence vidéo générée
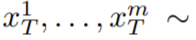 . Cependant, comme le montre la première rangée de la figure 10, cela conduit à une génération d'images complètement aléatoires, partageant uniquement la sémantique décrite par
. Cependant, comme le montre la première rangée de la figure 10, cela conduit à une génération d'images complètement aléatoires, partageant uniquement la sémantique décrite par
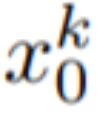
Pour résoudre ce problème, cet article propose les deux méthodes suivantes : (i) introduire une dynamique de mouvement entre les encodages latents Notez que pour simplifier la notation, cet article représente l'intégralité de la séquence de code potentielle comme : 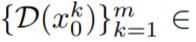
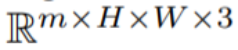
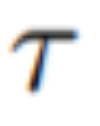
Expériences
Résultats qualitatifs 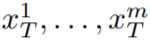
Dans le cas du texte vers vidéo, on peut observer qu'il produit des vidéos de haute qualité qui sont bien alignées avec les invites textuelles (voir Figure 3). Par exemple, un panda est amené à marcher naturellement dans la rue. De même, en utilisant des conseils de bord ou de pose supplémentaires (voir figures 5, 6 et 7), des vidéos de haute qualité correspondant à des invites et à des conseils ont été générées, montrant une bonne cohérence temporelle et une bonne préservation de l'identité.

Dans le cas de Video Instruct-Pix2Pix (voir Figure 1), la vidéo générée a une haute fidélité par rapport à la vidéo d'entrée tout en suivant strictement les instructions.
Comparaison avec la ligne de base
Cet article compare sa méthode avec deux lignes de base accessibles au public : CogVideo et Tune-A-Video. Étant donné que CogVideo est une méthode de conversion texte-vidéo, cet article la compare dans un scénario de synthèse vidéo guidée par texte brut ; en utilisant Video Instruct-Pix2Pix pour une comparaison avec Tune-A-Video.
Pour une comparaison quantitative, cet article utilise le score CLIP pour évaluer le modèle. Le score CLIP représente le degré d'alignement du texte vidéo. En obtenant aléatoirement 25 vidéos générées par CogVideo, et en synthétisant les vidéos correspondantes en utilisant les mêmes astuces selon la méthode présentée dans cet article. Les scores CLIP de notre méthode et de CogVideo sont respectivement de 31,19 et 29,63. Notre méthode est donc légèrement meilleure que CogVideo, même si cette dernière comporte 9,4 milliards de paramètres et nécessite un entraînement à grande échelle sur les vidéos.
La figure 8 montre plusieurs résultats de la méthode proposée dans cet article et fournit une comparaison qualitative avec CogVideo. Les deux méthodes montrent une bonne cohérence temporelle tout au long de la séquence, préservant l'identité de l'objet ainsi que son contexte. Notre méthode montre de meilleures capacités d’alignement texte-vidéo. Par exemple, notre méthode génère correctement une vidéo d'une personne faisant du vélo au soleil dans la figure 8 (b), tandis que CogVideo définit l'arrière-plan au clair de lune. Également sur la figure 8 (a), notre méthode montre correctement une personne courant dans la neige, alors que la neige et la personne qui court ne sont pas clairement visibles dans la vidéo générée par CogVideo.
Vidéo Les résultats qualitatifs d'Instruct-Pix2Pix et la comparaison visuelle avec Instruct-Pix2Pix par image et Tune-AVideo sont présentés dans la figure 9. Bien qu'Instruct-Pix2Pix affiche de bonnes performances d'édition par image, il manque de cohérence temporelle. Ceci est particulièrement visible dans les vidéos représentant des skieurs, où la neige et le ciel sont dessinés dans différents styles et couleurs. Ces problèmes ont été résolus à l’aide de la méthode Video Instruct-Pix2Pix, ce qui a permis d’obtenir un montage vidéo temporellement cohérent tout au long de la séquence.
Bien que Tune-A-Video crée une génération vidéo cohérente dans le temps, par rapport à l'approche de cet article, elle est moins cohérente avec les instructions, a des difficultés à créer des modifications locales et perd les détails de la séquence d'entrée. Cela devient évident en regardant le montage de la vidéo du danseur représenté sur la figure 9, à gauche. Par rapport à Tune-A-Video, notre méthode rend l'ensemble de la tenue plus lumineux tout en préservant mieux l'arrière-plan, comme le mur derrière le danseur restant presque inchangé. Tune-A-Video a peint un mur fortement déformé. De plus, notre méthode est plus fidèle aux détails d'entrée. Par exemple, par rapport à Tune-A-Video, Video Instruction-Pix2Pix dessine les danseurs en utilisant les poses fournies (Figure 9 à gauche) et affiche tous les skieurs apparaissant dans la vidéo d'entrée (. Comme le montre le dernier cadre sur le côté droit de la figure 9). Toutes les faiblesses mentionnées ci-dessus de Tune-A-Video peuvent également être observées dans les figures 23 et 24.


Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



