




La numérisation des entreprises est un sujet brûlant ces dernières années. Elle fait référence à l'utilisation de technologies numériques de nouvelle génération telles que l'intelligence artificielle, le big data et le cloud computing. transformer le modèle économique des entreprises, favorisant ainsi une nouvelle croissance des activités des entreprises. La numérisation des entreprises comprend généralement la numérisation des opérations commerciales et la numérisation de la gestion de l'entreprise. Ce partage introduit principalement la numérisation au niveau de la gestion de l'entreprise.
La numérisation de l'information, en termes simples, signifie lire, écrire, stocker et transmettre des informations de manière numérique. Des anciens documents papier aux documents électroniques actuels et aux documents collaboratifs en ligne, la numérisation des informations est devenue la nouvelle norme dans les bureaux d'aujourd'hui. Actuellement, Alibaba utilise DingTalk Documents et Yuque Documents pour la collaboration commerciale, et le nombre de documents en ligne a atteint plus de 20 millions. En outre, de nombreuses entreprises disposent de leurs propres communautés de contenu internes, telles que l'intranet Alibaba Internal et External et la communauté technique ATA. Actuellement, la communauté ATA compte près de 300 000 articles techniques, qui constituent tous des actifs de contenu très précieux.
La numérisation des processus fait référence à l'utilisation de la technologie numérique pour transformer les processus de service et améliorer l'efficacité des services. Il y aura beaucoup de travail transactionnel comme l'administration interne, l'informatique, les ressources humaines, etc. Le système de gestion des processus BPMS peut standardiser les processus de travail, formuler un flux de travail basé sur des règles métier et l'exécuter automatiquement en fonction du flux de travail, ce qui peut réduire considérablement les coûts de main-d'œuvre. Le RPA est principalement utilisé pour résoudre le problème de la commutation multi-systèmes dans le processus. Parce qu'il peut simuler des opérations de saisie manuelle par clic sur l'interface système, il peut connecter diverses plates-formes système. La prochaine direction de développement de la numérisation des processus est l’intelligence des processus, réalisée grâce aux robots conversationnels et au RPA. De nos jours, les robots conversationnels basés sur des tâches peuvent aider les utilisateurs à accomplir certaines tâches simples en quelques tours de dialogue, comme demander un congé, réserver des billets, etc.
L'objectif de la digitalisation des entreprises est d'établir un nouveau modèle économique grâce à la technologie numérique. Au sein de l'entreprise, il existe en fait des middle offices d'affaires, comme la digitalisation métier du service des achats, qui fait référence à la digitalisation d'une série de processus depuis la recherche de produits, le lancement de la demande d'achat, la rédaction du contrat d'achat, le paiement, l'exécution des commandes, etc. . Un autre exemple est la numérisation commerciale du middle office juridique. En prenant comme exemple le centre de contrats, il réalise la numérisation de l'ensemble du cycle de vie du contrat, de la rédaction du contrat à la révision du contrat, en passant par la signature et l'exécution du contrat.
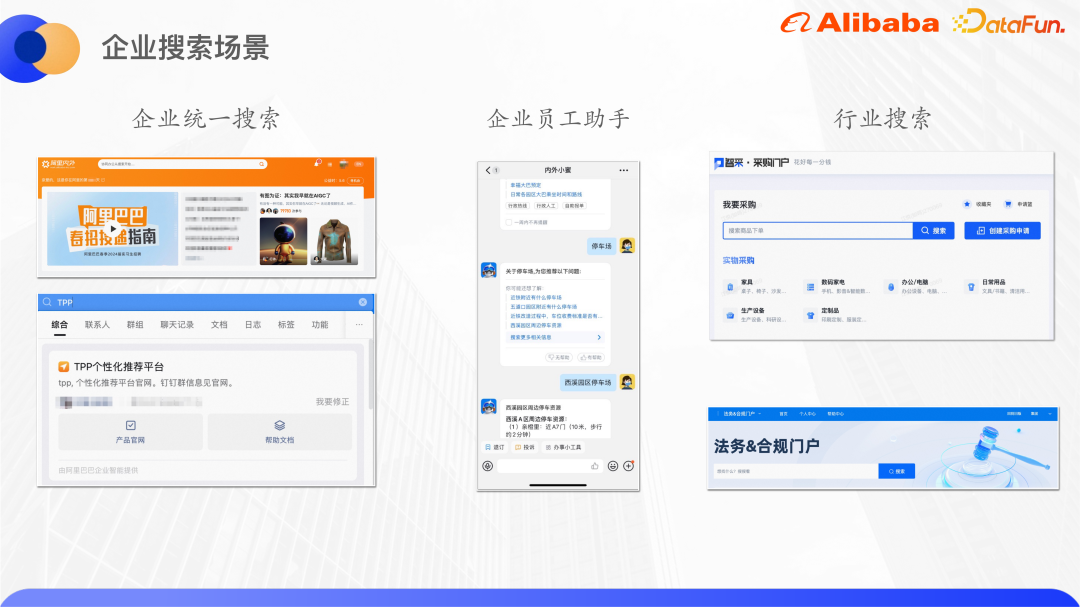
Les données et documents massifs générés par la numérisation seront dispersés dans divers systèmes d'entreprise, un moteur de recherche d'entreprise intelligent est donc nécessaire pour aider les employés à localiser rapidement les informations qu'ils recherchent. En prenant l'exemple du groupe Alibaba, les principaux scénarios de recherche d'entreprise sont les suivants :
(1) Recherche unifiée, également connue sous le nom de recherche complète, qui regroupe les informations de plusieurs sites de contenu, notamment DingTalk Documents, Yuque Documentation, ATA, etc. Les entrées de la recherche unifiée sont actuellement placées sur le réseau interne d'Alibaba Alibaba Internal et External et sur la version réservée aux employés de DingTalk. Le trafic combiné de ces deux entrées atteint environ 140 QPS, ce qui représente un trafic très élevé dans un scénario ToB.
(2) L'assistant d'employé d'entreprise fait référence à Xiaomi à l'intérieur et à l'extérieur. Il s'agit d'un robot de service intelligent pour les employés internes d'Alibaba. Il rassemble des services de questions et réponses de connaissances d'entreprise dans les domaines des ressources humaines, de l'administration, de l'informatique et d'autres domaines. ainsi que Les canaux de service rapide, y compris l'entrée DingTalk et certaines entrées plug-in, sont ouverts à un total d'environ 250 000 personnes et constituent également l'un des points de circulation du groupe.
(3) La recherche par secteur correspond à la numérisation de l'entreprise mentionnée dans le chapitre précédent. Par exemple, les achats disposent d'un portail appelé Procurement Mall. Les acheteurs peuvent effectuer une recherche dans le Procurement Mall, sélectionner des produits et soumettre des demandes d'approvisionnement, de la même manière. au commerce électronique. Recherchez sur le site Web, mais l'utilisateur est l'acheteur de l'entreprise ; l'entreprise de conformité juridique dispose également d'un portail correspondant, où les étudiants en droit peuvent rechercher des contrats et effectuer une série de tâches telles que la rédaction, l'approbation, et signature.

De manière générale, chaque système métier ou site de contenu de l'entreprise aura son propre système métier de recherche, qui doit être isolé les uns des autres. Cependant, l'isolement des sites de contenu formera le système. phénomène des îlots d’information. Par exemple, si un camarade de classe technique rencontre un problème technique, il peut d'abord se rendre sur ATA pour rechercher des articles techniques liés au problème, s'il ne le trouve pas, il recherchera ensuite un contenu similaire dans Zhibo, DingTalk Documents et Yuque Documents. , ce qui nécessitera un total de quatre ou cinq recherches. Ce comportement de recherche est sans aucun doute très inefficace. Nous espérons donc rassembler ces contenus dans une recherche d'entreprise unifiée, afin que toutes les informations pertinentes puissent être obtenues en une seule recherche.
De plus, les recherches sectorielles avec des attributs commerciaux doivent généralement être isolées les unes des autres. Par exemple, les utilisateurs du centre d'approvisionnement sont les acheteurs du groupe et les utilisateurs du centre de contrats sont les affaires juridiques du groupe. Le nombre d'utilisateurs dans ces deux scénarios de recherche est très faible, le comportement des utilisateurs sera donc relativement clairsemé et dépendra. sur l'algorithme de recommandation qui utilise données sur le comportement des utilisateurs, l'effet sera considérablement réduit. Il existe également très peu de données annotées dans les domaines des marchés publics et du droit, car cela nécessite des professionnels pour les annoter et le coût est élevé, ce qui rend difficile la collecte d'ensembles de données de haute qualité.
La dernière chose est le problème de correspondance entre la requête et le document. La longueur de la requête recherchée est essentiellement d'une douzaine de mots. Il s'agit d'un texte court, qui manque de contexte et les informations sémantiques ne sont pas assez riches. la compréhension de textes courts, il existe de nombreux travaux de recherche universitaires liés. Les éléments recherchés sont essentiellement des documents longs, avec un nombre de caractères allant de centaines à des milliers. Comprendre et représenter le contenu de documents longs est également une tâche très difficile.
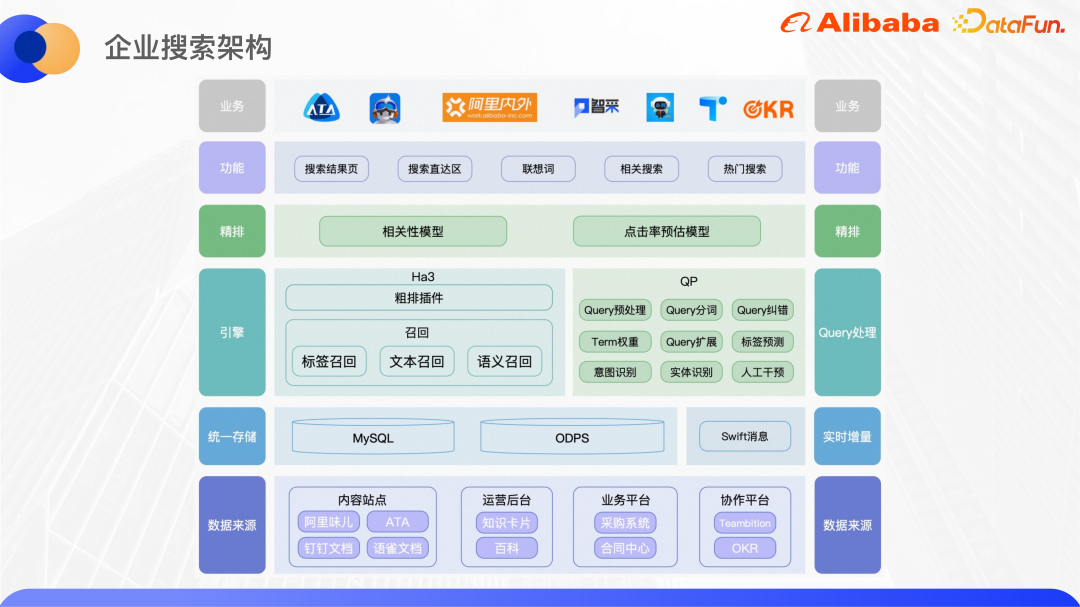
L'image ci-dessus montre l'architecture de base de notre recherche d'entreprise actuelle. Ici, nous introduisons principalement la partie recherche unifiée.
Actuellement, la recherche unifiée est connectée à plus de 40 sites de contenu, grands et petits, tels que ATA, DingTalk Documents et Yuque Documents. Le moteur Ha3 développé par Alibaba est utilisé pour le rappel et le tri approximatif. Avant le rappel, le service QP de l'algorithme est appelé pour analyser la requête de l'utilisateur et fournir la segmentation des requêtes, la correction des erreurs, la pondération des termes, l'expansion des requêtes, la reconnaissance des intentions NER, etc. Selon les résultats du QP et la logique métier, la chaîne de requête est assemblée côté moteur pour être rappelée. Le plug-in de tri approximatif basé sur Ha3 peut prendre en charge certains modèles de tri légers, tels que GBDT, etc. Dans l'étape de classement fin, des modèles plus complexes peuvent être utilisés pour le tri. Le modèle de corrélation est principalement utilisé pour garantir l'exactitude de la recherche, et le modèle d'estimation du taux de clics optimise directement le taux de clics.
En plus du tri de recherche, il intègre également d'autres fonctions périphériques de recherche, telles que la zone de recherche directe de la liste déroulante de recherche, les mots associés, les recherches associées, les recherches populaires, etc. Actuellement, les services pris en charge par la couche supérieure sont principalement la recherche unifiée au sein et à l'extérieur d'Alibaba et Alibaba DingTalk, la recherche verticale pour les achats et les affaires juridiques et la compréhension des requêtes du système ATA Teambition OKR.
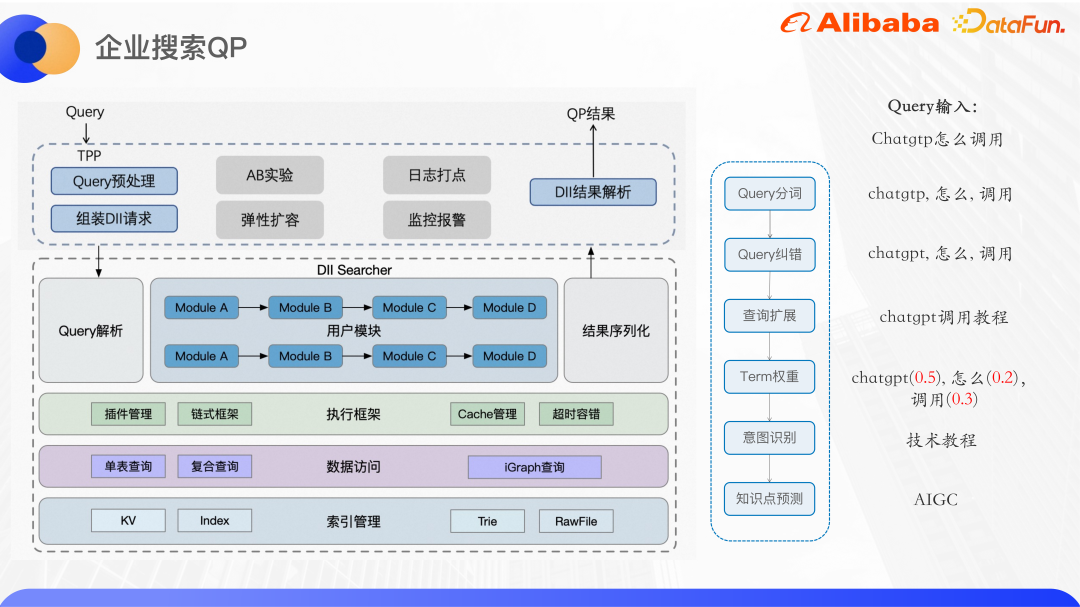
L'image ci-dessus est l'architecture générale de la recherche d'entreprise QP. Le service QP est déployé sur une plate-forme de services en ligne algorithmique appelée DII. La plate-forme DII peut prendre en charge la construction et l'interrogation de tables KV et d'index de tables d'indexation. Il s'agit d'un cadre de services en chaîne dans son ensemble, et une logique métier complexe doit être divisée en modules métier relativement indépendants et cohérents. Par exemple, le service de recherche QP à l'intérieur et à l'extérieur d'Alibaba est divisé en plusieurs modules fonctionnels tels que la segmentation des mots, la correction des erreurs, l'expansion des requêtes, la pondération des termes et la reconnaissance des intentions. L'avantage du framework en chaîne est qu'il facilite le développement collaboratif par plusieurs personnes. Chaque personne est responsable du développement de son propre module. Tant que les interfaces amont et aval sont convenues, différents services QP peuvent réutiliser le même module, ce qui réduit les coûts. code en double. De plus, une couche est intégrée au service d'algorithme sous-jacent pour fournir une interface TPP avec le monde extérieur. TPP est une plate-forme de recommandation d'algorithmes mature au sein d'Alibaba. Elle peut facilement mener des expériences AB et une expansion élastique. Le mécanisme de gestion, de surveillance et d'alarme des journaux est également très mature.
Effectuez le prétraitement des requêtes côté TPP, puis assemblez la requête DII, appelez le service d'algorithme DII, analysez le résultat après l'avoir obtenu, et enfin renvoyez-le à l'appelant.
Ensuite, nous présenterons le travail de reconnaissance d'intention de requête dans deux scénarios d'entreprise.
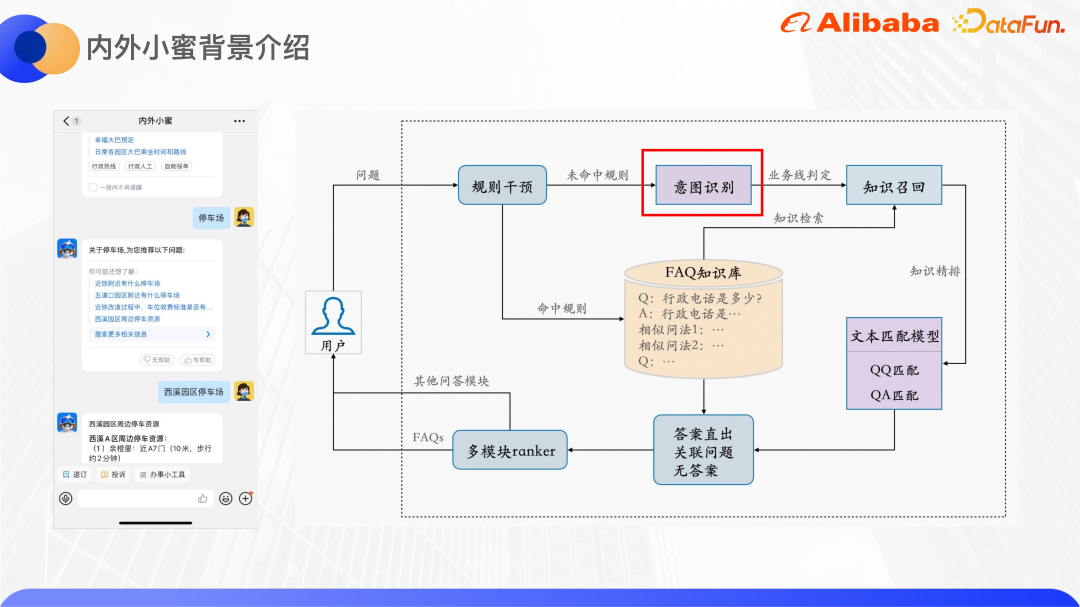
Ce qui suit se concentre sur le module de reconnaissance d'intention.
En comptant les requêtes des utilisateurs de Xiaomi au cours et à l'extérieur de l'année dernière, nous avons constaté que la plupart des mots de requête des utilisateurs sont concentrés entre 0 et 20, et plus de 80 % des mots de requête sont inférieurs à 10. Par conséquent, la reconnaissance d'intention de Xiaomi à l'intérieur et à l'extérieur est un problème de classification de textes courts. Le nombre de textes courts est très faible, donc s'il est représenté par le modèle d'espace vectoriel traditionnel, l'espace vectoriel sera clairsemé. Et d’une manière générale, les expressions textuelles courtes ne sont pas très standardisées, avec de nombreuses abréviations et termes irréguliers, il y a donc davantage de phénomènes OOV.
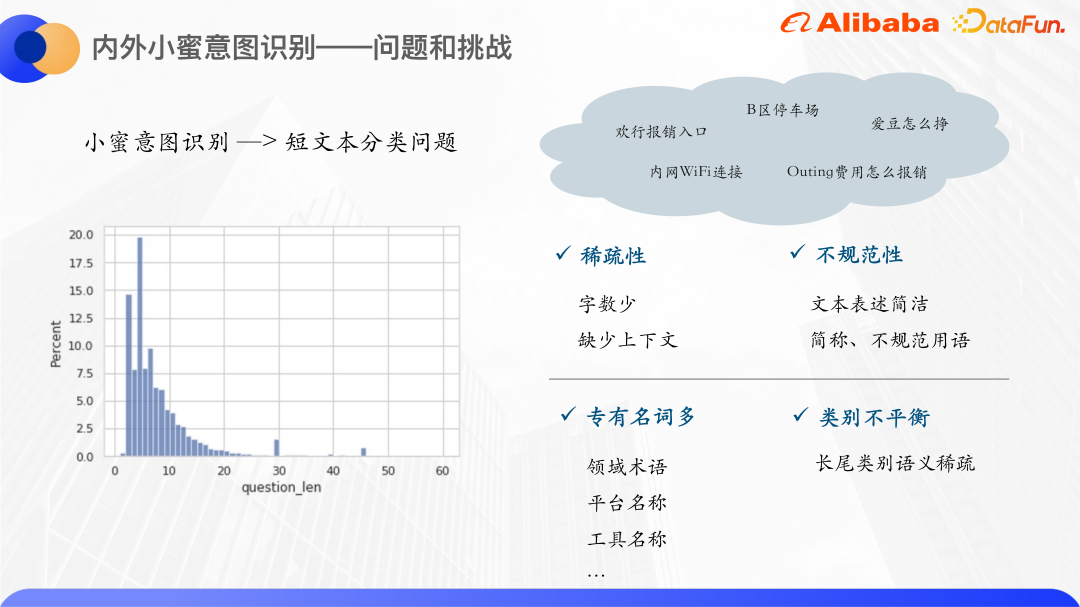
L'amélioration des connaissances générales utilisera des graphiques de connaissances open source, mais les noms propres au sein de l'entreprise ne peuvent pas trouver les entités correspondantes dans le graphique de connaissances open source, nous recherchons donc des connaissances de l'intérieur. Il arrive qu'Alibaba dispose d'une fonction de recherche de cartes de connaissances. Chaque carte de connaissances correspond à un produit intranet et est fortement liée au domaine de Xiaomi à l'intérieur et à l'extérieur. Par exemple, Huanxing et Idol peuvent trouver ici des informations pertinentes, donc d'entreprise. les cartes de connaissances sont utilisées comme sources de connaissances.
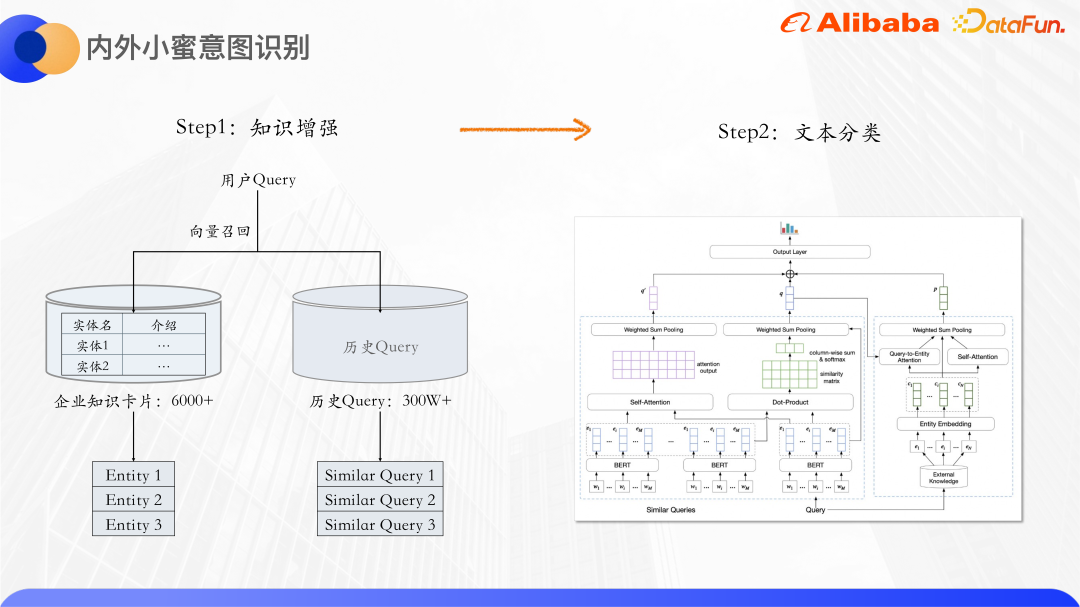
La première est l'amélioration des connaissances. Il existe plus de 6 000 cartes de connaissances d'entreprise au total. Chaque carte de connaissances aura un nom d'entité et une introduction textuelle. qui peut être rappelée en fonction de la requête de l'utilisateur. Les fiches de connaissances qui y sont liées font également appel à des requêtes historiques, car de nombreuses requêtes sont similaires, comme la connexion Wifi intranet, la connexion intranet Wifi, etc. Des requêtes similaires peuvent se compléter les informations sémantiques des autres, atténuant davantage le problème de la rareté des textes. En plus des entités de la carte de connaissances, des requêtes similaires sont rappelées et les requêtes originales sont envoyées au modèle de classification de texte pour classification.
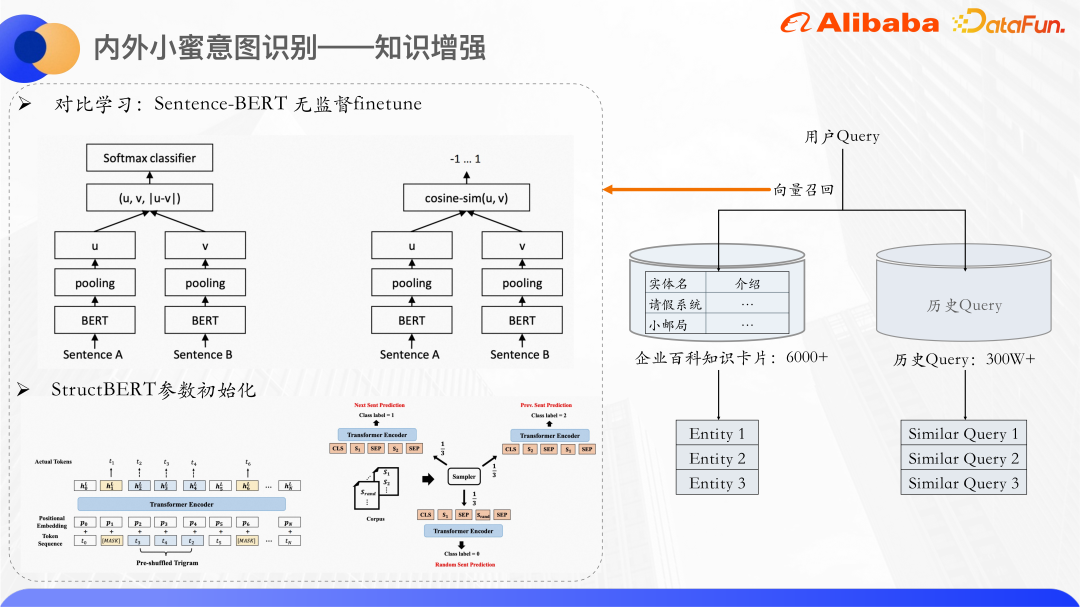
Utilisez le rappel vectoriel pour rappeler des entités et des requêtes similaires de cartes de connaissances. Utilisez Bert pour calculer la quantité concrète de la description textuelle de la requête et de la carte de connaissances respectivement. De manière générale, les vecteurs CLS de Bert ne sont pas directement utilisés comme représentations de phrases. De nombreux articles mentionnent également que l'utilisation directe des vecteurs CLS comme représentations de phrases donnera de mauvais résultats car les vecteurs produits par Bert auront des problèmes de dégradation d'expression et ne seront pas adaptés à une utilisation directe. effectue des calculs de similarité non supervisés, il utilise donc l'idée d'apprentissage contrasté pour rapprocher les échantillons similaires et répartir les échantillons différents aussi uniformément que possible.
Plus précisément, un Sentence-Bert est affiné sur l'ensemble de données, et sa structure de modèle et sa méthode de formation peuvent produire de meilleures représentations vectorielles de phrases. Il s'agit d'une structure à deux tours. Les modèles Bert des deux côtés partagent les paramètres du modèle. Les deux phrases sont respectivement entrées dans Bert. Après avoir regroupé les états cachés produits par Bert, les vecteurs de phrases des deux phrases seront obtenus. L'objectif d'optimisation ici est la perte d'apprentissage comparatif, infoNCE.
Exemple positif : Saisissez directement l'échantillon dans le modèle deux fois, mais l'abandon de ces deux fois est différent, donc les vecteurs de représentation seront légèrement différents.
Exemple négatif : Toutes les autres phrases du même lot.
Optimisez cette perte et obtenez le modèle Sentence-Bert pour prédire les vecteurs de phrases.
Nous utilisons les paramètres du modèle StructBERT pour initialiser la partie Bert ici. StructBERT est un modèle de pré-formation proposé par DAMO Academy. Sa structure de modèle est la même que celle du BERT natif. Son idée principale est d'incorporer des informations sur la structure du langage dans la tâche de pré-formation pour obtenir les vecteurs de phrases et les cartes de connaissances de la requête. Par calcul La similarité cosinusoïdale des vecteurs rappelle les k cartes de connaissances les plus similaires et les requêtes similaires.
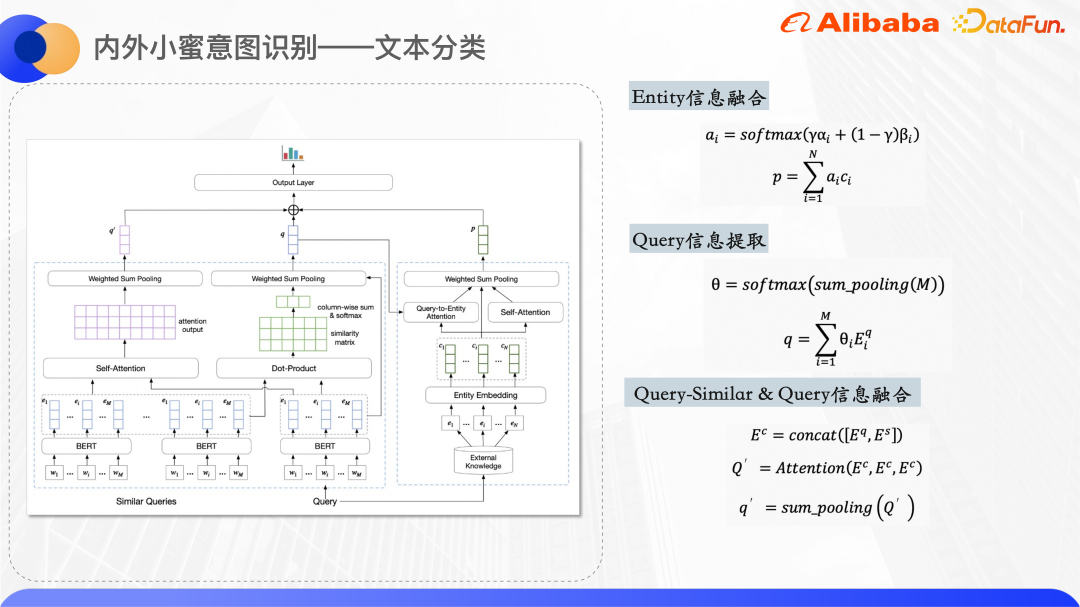
L'image ci-dessus est la structure du modèle de classification de texte. Bert est utilisé dans la couche d'encodage pour extraire la représentation de la requête originale et des vecteurs de mots de requêtes similaires maintenues par chaque entité de carte de connaissances. un ID d'entité intégré, l'intégration d'ID est initialisée de manière aléatoire.
Le côté droit du diagramme de structure du modèle permet de traiter les entités rappelées par la requête et d'obtenir une représentation vectorielle unifiée des entités. Parce que le texte court lui-même est relativement vague, les entités de la carte de connaissances rappelées auront également une certaine quantité de bruit. En utilisant deux mécanismes d'attention, le modèle peut accorder plus d'attention aux entités correctes. L’un est Query-to-Entity Attention, qui vise à amener le modèle à accorder plus d’attention aux entités liées à la requête. L'autre est l'auto-attention de l'entité elle-même, qui peut augmenter le poids des entités similaires et réduire le poids des entités bruyantes. En combinant les deux ensembles de poids d'attention, une représentation vectorielle de l'entité finale est obtenue.
Le côté gauche du diagramme de structure du modèle sert à traiter la requête d'origine et la requête similaire. Car on observe que les mots qui se chevauchent d'une requête similaire et d'une requête d'origine peuvent caractériser dans une certaine mesure le mot central de la requête, donc ici. nous calculons la relation entre chaque mot Cliquez pour obtenir la matrice de similarité et effectuons une mise en commun des sommes pour obtenir le poids de chaque mot dans la requête d'origine qui est relativement similaire à la requête. Le but est de faire en sorte que le modèle accorde plus d'attention au mot central. , puis assemblez les vecteurs de mots de la requête similaire et de la requête d'origine pour calculer les informations sémantiques fusionnées.
Enfin, les trois vecteurs ci-dessus sont assemblés et la probabilité de chaque catégorie est obtenue grâce à la prédiction de couche dense.
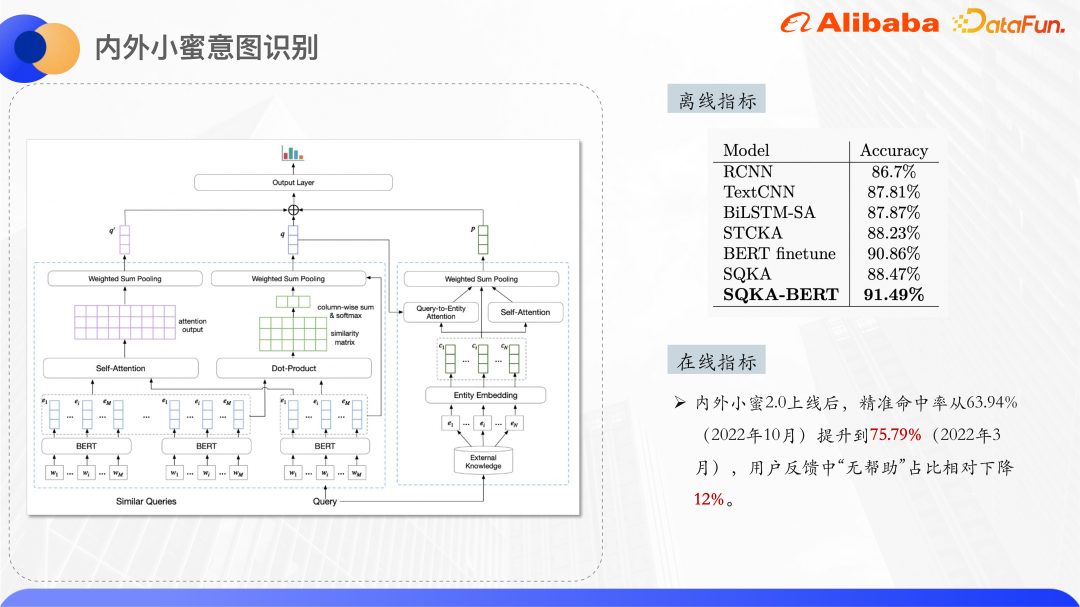
Les résultats expérimentaux ci-dessus dépassent les résultats du réglage fin BERT. Si Bert n'est pas utilisé dans la couche d'encodage, il dépasse également tous les modèles non Bert.
Prenons l'exemple du centre d'achat. Le centre d'achat a son propre système de catégories de produits, et chaque produit sera monté dans une catégorie de produits avant d'être mis sur le marché. étagères. Afin d'améliorer la précision de la recherche dans les centres commerciaux, il est nécessaire de prédire la requête pour une catégorie spécifique, puis d'ajuster les résultats du classement de recherche en fonction de cette catégorie. Vous pouvez également afficher la navigation dans les sous-catégories et les recherches associées sur l'interface en fonction de cette catégorie. les résultats de la catégorie.
La prédiction de catégorie nécessite des ensembles de données étiquetés manuellement, mais dans le domaine des achats, le coût de l'étiquetage est relativement élevé, ce problème est donc résolu du point de vue de la classification de petits échantillons.
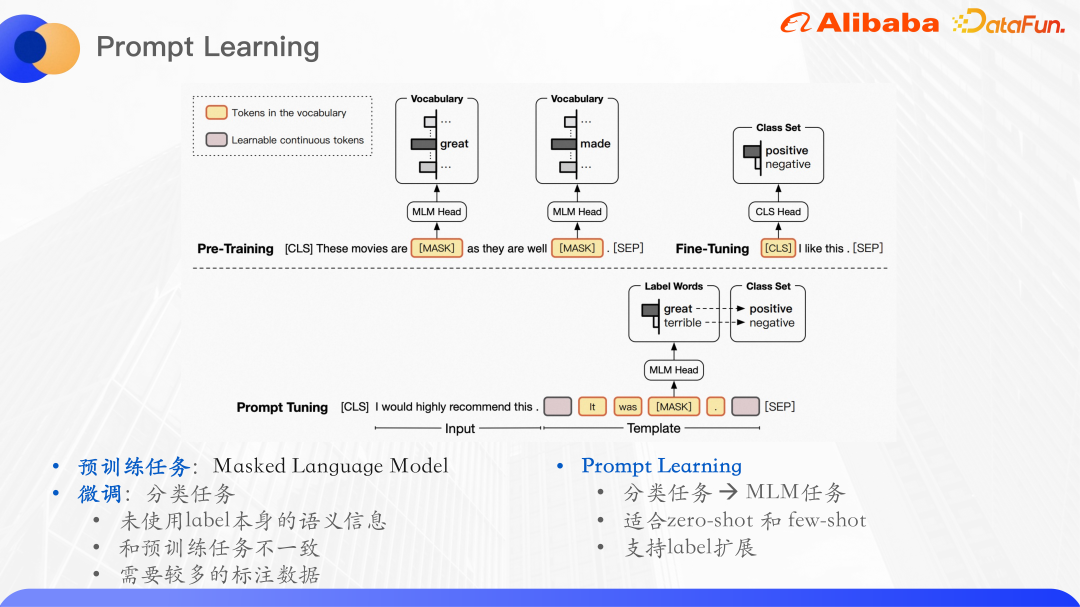
Le modèle pré-entraîné a démontré de solides capacités de compréhension du langage sur les tâches PNL. Le paradigme d'utilisation typique consiste à d'abord pré-entraîner sur un ensemble de données non étiquetées à grande échelle, puis à s'entraîner sur un. supervisé Effectuer des réglages précis sur les tâches en aval. Par exemple, la tâche de pré-entraînement de Bert est principalement un modèle de langage de masque, ce qui signifie masquer aléatoirement une partie des mots d'une phrase, la saisir dans le modèle original, puis prédire les mots dans la partie du masque pour maximiser la probabilité de les mots.
La prédiction de catégorie de requête est essentiellement une tâche de classification de texte. La tâche de classification de texte consiste à prédire l'entrée d'un certain ID d'étiquette, mais cela n'utilise pas les informations sémantiques de l'étiquette elle-même, des tâches de classification affinées. et les tâches de pré-formation. Il est incohérent et ne peut pas maximiser l'utilisation des tâches de pré-formation pour apprendre le modèle de langage, c'est pourquoi un nouveau modèle de langage de pré-formation a émergé.
Le paradigme du modèle linguistique pré-entraîné est appelé apprentissage rapide. L'invite peut être comprise comme un indice du modèle linguistique pré-entraîné pour l'aider à mieux comprendre les problèmes humains. Plus précisément, un paragraphe supplémentaire est ajouté au texte saisi. Dans ce paragraphe, les mots liés à l'étiquette seront masqués, puis le modèle sera utilisé pour prédire les mots à la position du masque, convertissant ainsi la tâche de classification en masque. Modèle de langage. Après avoir prédit le mot à la position du masque, il est souvent nécessaire de mapper le mot à l'ensemble d'étiquettes. La prédiction de catégorie pour l'approvisionnement est un problème typique de classification de petits échantillons. Plusieurs modèles sont construits pour la tâche de prédiction de catégorie, et puis le masque est abandonné. La partie est le mot qui doit être prédit.
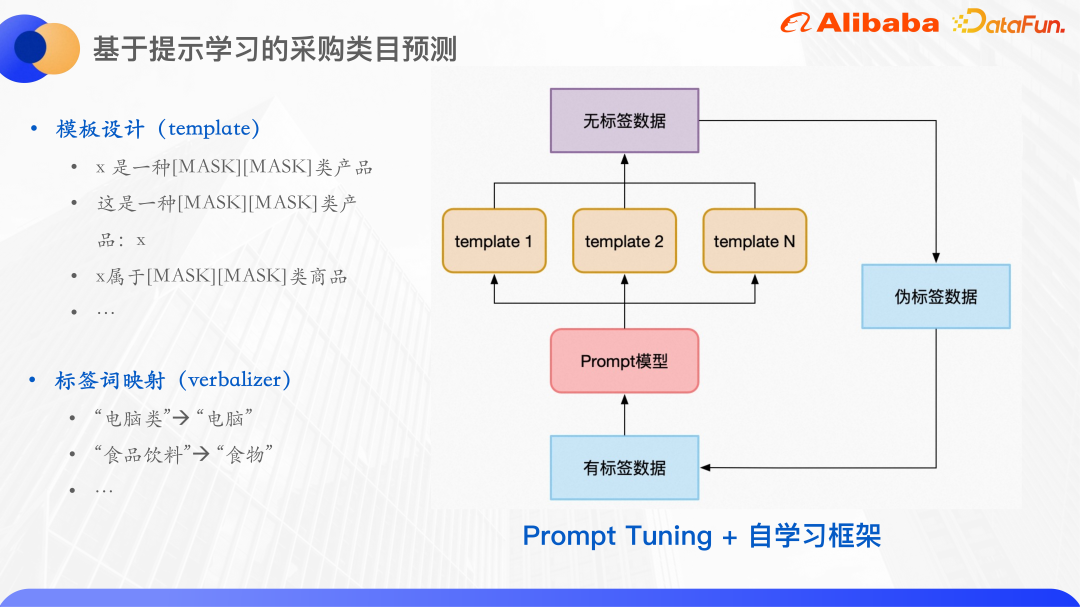
Pour le modèle, une cartographie des mots de prédiction aux mots d'étiquette est établie.
Tout d’abord, les mots prédits ne sont pas nécessairement des étiquettes. Parce que afin de faciliter la formation, le nombre de caractères de masque pour chaque échantillon est le même. Les mots d'étiquette d'origine ont 3 caractères, 4 caractères, etc. Ici, les mots de prédiction et les mots d'étiquette sont mappés et unifiés en deux caractères.
De plus, sur la base d'un apprentissage rapide, en utilisant le cadre d'auto-apprentissage, utilisez d'abord des données étiquetées pour former un modèle pour chaque modèle, puis intégrez plusieurs modèles pour prédire les données non étiquetées, entraînez-vous pour un tour et sélectionnez parmi eux des échantillons avec une grande confiance sont ajoutés à l'ensemble de formation sous forme de données de pseudo-étiquette, obtenant ainsi davantage de données étiquetées, puis entraînant une série de modèles.
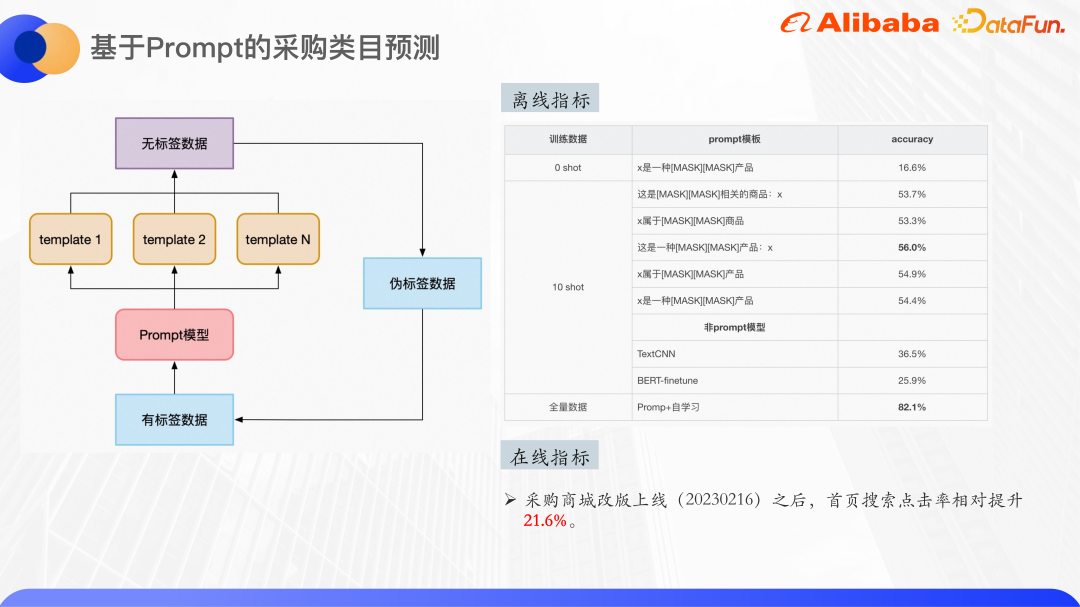
L'image ci-dessus représente quelques résultats expérimentaux. Vous pouvez voir l'effet de classification dans le scénario zéro tir. Le modèle de pré-entraînement utilise la base Bert, avec un total de 30 classes. atteint déjà une précision de 16%. En s'entraînant sur l'ensemble de données de dix prises de vue, plusieurs modèles peuvent atteindre une précision maximale de 56 %, et l'amélioration est assez évidente. On voit que le choix du modèle aura également un certain impact sur les résultats.
Le même ensemble de données de dix plans a également été testé à l'aide de TextCNN et de BERT-finetune. Les résultats étaient bien inférieurs à l'effet du réglage fin de l'apprentissage des repères, de sorte que l'apprentissage des repères est très efficace dans de petits scénarios d'échantillon.
Enfin, en utilisant la quantité totale de données, environ 4 000 échantillons d'entraînement et l'auto-apprentissage, l'effet a atteint environ 82 %. L'ajout d'un post-traitement tel que le seuil de carte en ligne peut garantir que la précision de la classification est supérieure à 90 %. 3. Réflexion sommaire Bref général compréhension du texte Les graphiques de connaissances seront utilisés pour l'amélioration des connaissances, mais en raison de la particularité des scénarios d'entreprise, les graphiques de connaissances open source sont difficiles à répondre aux besoins, c'est pourquoi les données semi-structurées au sein de l'entreprise sont utilisées pour l'amélioration des connaissances.
(2) Il existe très peu de données annotées dans certains domaines professionnels au sein de l'entreprise

Est-il donc possible de former un grand modèle pré-entraîné au niveau de l'entreprise et d'utiliser les données des domaines verticaux internes de l'entreprise sur la base de corpus communs, tels que les données d'articles ATA, les données de contrat et les données de code d'Alibaba. , etc., obtenez un grand modèle pré-entraîné, puis utilisez l'apprentissage rapide ou l'apprentissage contextuel pour unifier diverses tâches telles que la classification de texte, le NER et la correspondance de texte en une seule tâche de modèle de langage.
De plus, pour les tâches factuelles telles que l'assurance qualité des questions et réponses et la recherche, comment garantir l'exactitude des réponses sur la base des résultats du modèle de langage génératif est également une question qui doit être prise en compte.
4. Séance de questions et réponsesQ1 : Existe-t-il des documents ou des codes pertinents pour l'ensemble du modèle de reconnaissance d'intention fourni par Alibaba ?
A1 : Le modèle est auto-développé, et il n'y a pas encore de papiers ni de codes.A2 : Les requêtes et les requêtes similaires utilisent la saisie au niveau de la dimension du jeton, et les cartes de connaissances utilisent uniquement l'intégration d'ID, car compte tenu du nom de la carte de connaissances elle-même, il existe des noms de produits internes qui ne sont pas inclus dans la sémantique du texte. . Particulièrement significatif. Si ces cartes de connaissances sont décrites dans du texte, il s'agit simplement d'un texte relativement long, ce qui peut introduire trop de bruit, donc sa description textuelle n'est pas utilisée, seule l'intégration de l'ID de cette carte de connaissances est utilisée. A3 : dix courts ne représente en effet qu'environ 50 %, car le modèle pré-entraîné ne couvre pas certains corpus rares dans le domaine des achats, et utilise le modèle BERT-base avec un nombre relativement restreint de paramètres. l'effet de dix tirs n'est pas très bon, mais si la totalité des données est utilisée, la précision peut être supérieure à 80 %. A4 : Cette zone est actuellement en cours d'exploration. L'idée principale est d'utiliser des idées similaires à l'apprentissage par renforcement et d'ajouter des commentaires artificiels pour ajuster la sortie avant la génération du modèle de langage. Ajoutez un prétraitement après l'entrée, c'est-à-dire après la sortie du grand modèle. Pendant le prétraitement, vous pouvez ajouter des graphiques de connaissances ou d'autres connaissances pour garantir l'exactitude de la réponse. Q2 : Actuellement, les requêtes et les requêtes similaires utilisent une entrée au niveau du jeton. Pourquoi les informations de la carte de connaissances récupérées n'utilisent-elles pas leur caractère concret dans le modèle de classification, mais prennent uniquement en compte l'intégration de l'ID ?
Q3 : Concernant les problèmes liés à la promotion, actuellement dans le cas d'un petit échantillon, la précision n'est que de 16 %, et les dix courts n'est que de 50. Alors, comment devrait-il être pris en compte pour les applications d'entreprise ? Ou avez-vous des idées à ce sujet ?
Q4 : Est-il pratique de développer l'exactitude de la réponse du grand modèle pré-entraîné de l'entreprise qui vient d'être mentionné ? Pouvez-vous développer le contenu pertinent ?
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Qu'est-ce que la monnaie numérique
Qu'est-ce que la monnaie numérique
 Comment ouvrir les fichiers ESP
Comment ouvrir les fichiers ESP
 Comment désactiver la protection en temps réel dans le Centre de sécurité Windows
Comment désactiver la protection en temps réel dans le Centre de sécurité Windows
 Quelles sont les nouvelles fonctionnalités de Hongmeng OS 3.0 ?
Quelles sont les nouvelles fonctionnalités de Hongmeng OS 3.0 ?
 Comment débloquer un téléphone Oppo si j'ai oublié le mot de passe
Comment débloquer un téléphone Oppo si j'ai oublié le mot de passe
 Comment résoudre le problème que localhost ne peut pas être ouvert
Comment résoudre le problème que localhost ne peut pas être ouvert
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 Comment acheter et vendre du Bitcoin ? Tutoriel de trading Bitcoin
Comment acheter et vendre du Bitcoin ? Tutoriel de trading Bitcoin








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



