



Concernant le gain Uplift, le problème commercial général peut être résumé comme suit: parmi les groupes délimités, les spécialistes du marketing voudront savoir, par rapport à la nouvelle action marketing T = 1 Le action marketing originale T = 0, combien de revenus moyens peut-elle générer (lift, ATE, effet de traitement moyen). Tout le monde fera attention à savoir si la nouvelle action marketing est plus efficace que l’originale.
Dans le scénario d'assurance, les actions marketing font principalement référence à la recommandation d'assurance, comme la rédaction et les produits révélés sur le module de recommandation. L'objectif est de trouver les résultats des actions marketing sous diverses actions et contraintes marketing. Le groupe qui a gagné le plus devrait procéder au ciblage d’audience.

Faites d'abord une hypothèse plus idéale et parfaite : pour chaque utilisateur i, vous pouvez savoir s'il achète l'action marketing t. Si vous l'achetez, vous pouvez penser que Di dans la formule est positif et que la valeur est relativement importante ; si vous ne l'achetez pas et êtes dégoûté des actions marketing, Di peut être relativement faible, voire négatif. De cette manière, l'effet du traitement individuel de chaque utilisateur peut être obtenu.
Concernant la division de la foule, vous pouvez voir les quatre quadrants marketing dans l'image ci-dessus. Ce qui nous préoccupe le plus, c'est certainement la foule de Persuadables dans le coin supérieur gauche. En combinaison avec la formule, la caractéristique de ce groupe de personnes est que lorsqu'il y a des actions de marketing, elles achètent beaucoup, c'est-à-dire Yi > 0, et la valeur est relativement importante. Si aucune action marketing n’est entreprise pour ce groupe de personnes, elle sera négative, ou relativement faible, égale à 0. Le Di d’un tel groupe de personnes sera relativement grand.
Regardez les personnes dans les deux autres quadrants, bien sûr, ce qui signifie que ces personnes achèteront indépendamment du marketing ou non, donc le taux de retour sur investissement marketing sur ce groupe de personnes est relativement faible. Les chiens endormis signifient que faire du marketing aura des effets négatifs. Il est préférable de ne pas faire de marketing pour ces deux groupes.

Mais il y a aussi un dilemme contrefactuel ici : Di n'est pas si parfait. Il nous est impossible de savoir si un utilisateur est intéressé par un traitement en même temps, c'est-à-dire que nous ne pouvons pas connaître la réaction d'un même utilisateur à différents traitements en même temps.
L'exemple le plus populaire est le suivant : supposons qu'il y ait un médicament après que A l'ait pris, la réaction de A au médicament sera obtenue. Mais ils ne savent pas que si A ne prend pas le médicament, parce que A a déjà pris le médicament, il s’agit en réalité d’une existence contrefactuelle.
Pour le contrefactuel, nous avons fait une estimation approximative. Dans la méthode d'estimation ITE (Individual Treatment Effect), bien qu'il ne soit pas possible de trouver un utilisateur pour expérimenter sa réponse à deux traitements, des groupes d'utilisateurs présentant les mêmes caractéristiques peuvent être trouvés pour estimer la réponse, par exemple deux personnes présentant les mêmes caractéristiques. On peut supposer que Xi Dans le même espace de fonctionnalités, ils sont à peu près équivalents à une personne.

De cette façon, l'estimation de Di est divisée en trois parties : (1)Le taux de conversion de Xi sous l'action marketing de T=1 ; (2)Le taux de conversion de Xi à T ; =0 Le taux de conversion sous l'action marketing ; (3)lift est une valeur de différence, qui calcule la différence entre deux probabilités conditionnelles. Plus la valeur lift d’un groupe d’utilisateurs est élevée, cela signifie que ce groupe de personnes est plus disposé à l’acheter. Comment augmenter la portance ? Dans la formule, le taux de conversion de Xi sous l'action marketing de T=1 est augmenté et le taux de conversion de Xi sous l'action marketing de T=0 est plus petit.

En termes de méthodes de modélisation, combinées à la formule ci-dessus, faites quelques généralisations :
#🎜 🎜#(1) Le nombre de T variables, s'il n'y a pas qu'une seule action marketing, mais n actions marketing, alors l'Uplift multi-variable est modélisé, sinon Il s’agit d’une modélisation Uplift univariée.
(2) Probabilité conditionnelle P et méthode d'estimation de lift #🎜 🎜 # : ① Grâce à la modélisation différentielle, estimez la valeur P, puis trouvez la valeur de portance. Il s'agit d'une modélisation indirecte. ② Grâce à une modélisation directe, telle qu'un modèle de conversion d'étiquettes, ou une forêt causale, telle que Tree base, LR, GBDT ou certains modèles profonds.
2. Application de la sensibilité du gain#🎜🎜 #

Tout d'abord, présentons le positionnement de l'assurance voyage sur Fliggy. L'assurance voyage est une catégorie de produits de voyage, mais elle apparaît plus souvent en lien avec les principaux produits. Par exemple, lorsque nous réservons des billets d'avion et des hôtels, l'intention d'achat principale est : les hôtels, les billets d'avion et les billets de train. À ce moment-là, l'APP vous demandera si vous souhaitez souscrire une assurance. L’assurance est donc une activité accessoire, mais elle est désormais devenue une source de revenus commerciaux très importante dans le secteur du transport et de l’hébergement.
La portée principale de cet article est la page pop-up : la page pop-up apparaîtra lorsque l'application Fliggy sera extraite en bas de la caisse. Une page. Cette page n'affichera qu'un seul type de copie créative et un seul produit d'assurance. Ceci est différent de la page de détails précédente, qui peut afficher plusieurs types de produits et de prix d'assurance. Par conséquent, cette page attirera suffisamment l'attention de l'utilisateur et pourra proposer de nouvelles promotions et même des actions marketing pour l'éducation et la formation des utilisateurs.
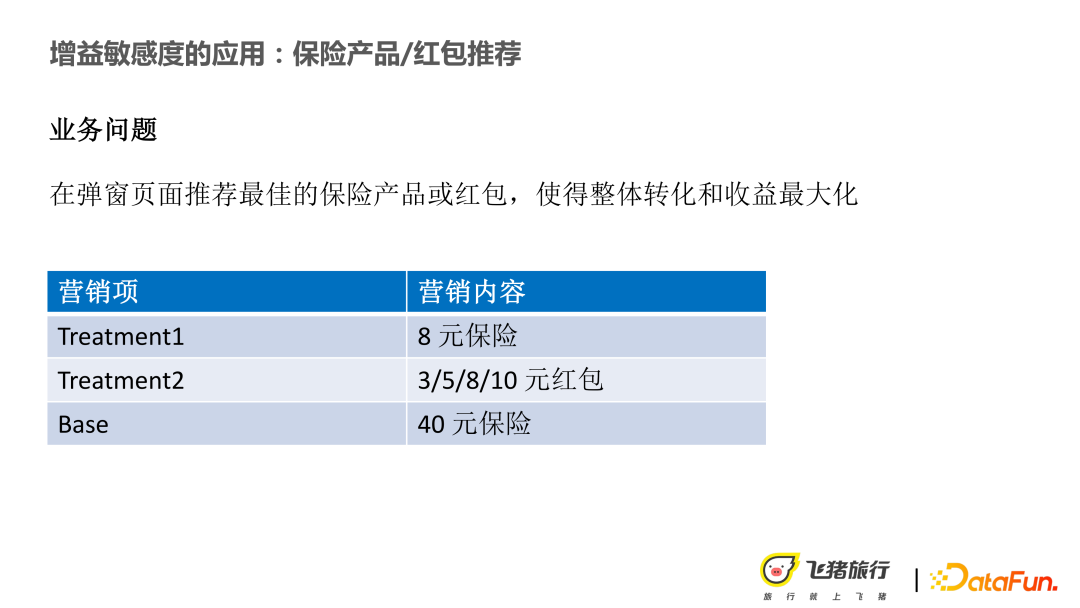 Problèmes commerciaux actuellement rencontrés Pour : Sur la page contextuelle, nous devons recommander le meilleur produit d'assurance ou l'enveloppe rouge pour maximiser la conversion ou les revenus globaux. Plus précisément, il s’agit d’atteindre un objectif commercial consistant à attirer de nouveaux clients ou à obtenir des conversions plus élevées. L’objectif des revenus de l’entreprise est d’augmenter le taux de conversion sans réduire les revenus.
Problèmes commerciaux actuellement rencontrés Pour : Sur la page contextuelle, nous devons recommander le meilleur produit d'assurance ou l'enveloppe rouge pour maximiser la conversion ou les revenus globaux. Plus précisément, il s’agit d’atteindre un objectif commercial consistant à attirer de nouveaux clients ou à obtenir des conversions plus élevées. L’objectif des revenus de l’entreprise est d’augmenter le taux de conversion sans réduire les revenus.
Sous les contraintes ci-dessus, il existe plusieurs éléments marketing : (1) Recommander aux utilisateurs une assurance d'entrée de gamme à bas prix ; (2) Un autre traitement, recommander quelques enveloppes rouges, principalement pour faire de nouvelles opérations. Et la base est le prix initial de l’assurance. Lors de la modélisation, il existe des conditions pour certaines hypothèses : Hypothèses d'indépendance conditionnelle. Désigne l'action marketing du traitement. Lors de la modélisation de la collecte par soulèvement, les échantillons obéissent à l'hypothèse d'indépendance et les différentes caractéristiques de l'utilisateur sont indépendantes les unes des autres. Par exemple, les enveloppes rouges ne peuvent pas être distribuées différemment selon l'âge. Par exemple, il devrait y avoir moins de distribution parmi les jeunes et plus de distribution parmi les personnes âgées. Cela entraînera un biais dans l’échantillon. La solution proposée consiste donc à permettre aux utilisateurs d’exposer les produits de manière aléatoire. De même, vous pouvez également calculer le score de propension pour obtenir un groupe d’utilisateurs homogène à des fins de comparaison.
Dans le plan expérimental
, expérience AB : A doit être livré selon la stratégie originale , peut-être que c'est 40 yuans pour l'assurance, ou cela peut être le prix de l'assurance par l'opération, ou le prix du modèle original. Baril B, placement d'assurance à petit prix. 
Label : Que l'utilisateur soit converti ou non.
Modèle : T/S/X-apprenant et divers modèles Meta de ce type. Structure d'échantillon : L'intérêt est de déterminer si les utilisateurs sont plus intéressés par ce type d'assurance à bas prix, et il doit y avoir suffisamment de fonctionnalités pour caractériser la sensibilité de l'utilisateur au prix. Mais en fait, comme pour les produits auxiliaires, il n’y a pas d’intention relativement forte. Par conséquent, il nous est difficile de voir quel niveau d'assurance l'utilisateur aime ou quel niveau d'assurance il achètera à partir de l'historique de navigation et des enregistrements d'achats de l'utilisateur. Nous ne pouvons examiner que les données du domaine de l'activité principale ou de certaines autres applications Fliggy consultées par les utilisateurs. Nous examinerons également la fréquence d'utilisation des enveloppes rouges des utilisateurs et la proportion de consommation d'enveloppes rouges, par exemple. envoyer des enveloppes rouges dans les premiers jours ? Ce n'est qu'à ce moment-là que la transformation a été effectuée sur Fliggy. 
Sur la base de la construction ci-dessus d'échantillons de fonctionnalités, l'importance et l'interprétabilité des fonctionnalités sont également analysées. Le modèle à base d’arbres montre qu’il est relativement sensible à certaines caractéristiques de la variable temps, de la variable prix et de la variable âge.
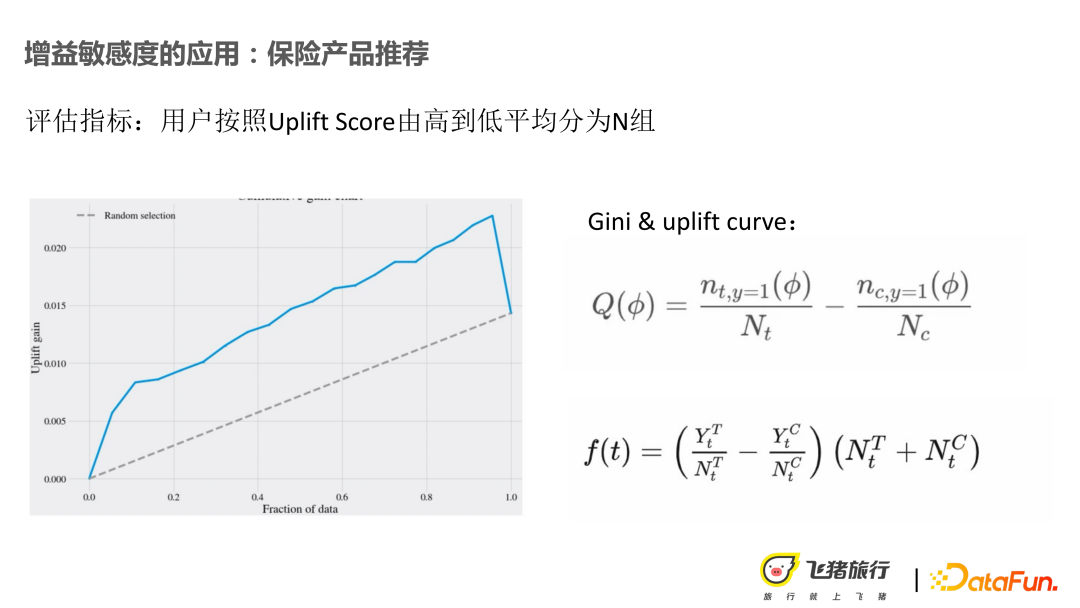
Méthodes de calcul des indicateurs d'évaluation : Gini et Gini accumulé. Divisez Uplift en n groupes et calculez un score de Gini pour chaque groupe, comme indiqué dans la première formule de la figure ci-dessus. Sous ce groupe, le taux de conversion une fois l'utilisateur mappé sur le bucket de test et le bucket de base est obtenu, et puis le Gini est calculé. Par analogie avec Uplift Gini, en calculant les points de revenu sous différents seuils, cela nous aide à déterminer un seuil.

Disponible hors ligne, le modèle le plus performant est LR+T-Learner, qui ne répond effectivement pas aux attentes initiales. Après réflexion, le problème réside peut-être dans la construction par l'utilisateur des caractéristiques de prix liées à l'assurance, qu'il n'est pas suffisant de décrire. Parce que nous avons également effectué des recherches sur les utilisateurs, telles que la personnalité de l'utilisateur et sa sensibilité à l'assurance. Certaines données de portrait d'utilisateur dans le domaine APP peuvent montrer l'intérêt de l'utilisateur pour un produit non physique. Mais au final, c'est toujours sur cette base que l'on a délimité les groupes à distribuer, et la tranche de base en ligne a augmenté de 5,8 %.

Dans la recommandation de l'enveloppe rouge, nous pouvons également émettre une assurance de 3/5/8/10 yuans sur la base de l'assurance de 40 yuans.

Nous avons un objectif commercial qui est un retour sur investissement incrémentiel. La définition de la formule est la suivante : le GMV du seau de test moins le GMV du seau de base. Le GMV incrémentiel obtenu peut-il couvrir le seau de test ? Dépenses de commercialisation. Si le retour sur investissement incrémentiel est supérieur à 1, cela signifie que le marketing ne perd pas d’argent. Donc dans ce scénario, notre exigence est de ne pas perdre d’argent. Avant d'utiliser le modèle Uplift, les étudiants en opération effectueront d'abord une vague de livraison parmi leurs groupes de semences, le retour sur investissement est compris entre 0,12 et 0,6, donc l'une de nos exigences est d'avoir un retour sur investissement plus élevé que celui-ci sans perdre d'argent.
Grâce au démantèlement des objectifs ci-dessus, le problème se transforme finalement en l'estimation du taux de conversion de l'utilisateur et l'estimation Uplift, comme le montre la formule sous la figure ci-dessus.

Enfin, après une série de changements, nous sommes revenus à la résolution de la valeur Uplift et de la probabilité de non-achat. La probabilité de non-achat fait référence au taux de conversion des utilisateurs lorsqu'aucun coupon n'est émis. Si vous souhaitez augmenter le retour sur investissement que nous venons de mentionner, cela signifie que vous devez trouver un groupe d'utilisateurs. Plus le P0 est petit, mieux c'est et plus il est élevé. la valeur Uplift, mieux c'est.
La première version du modèle est un modèle de prise de décision semi-intelligent : en fonction de la valeur Uplift calculée sous différents montants de coupon, puis en observant l'effet du traitement après sa mise en ligne, le seuil est défini. Chaque seuil défini est pour Peut couvrir les coûts.

La deuxième version est un modèle de tarification intelligent : elle s'appuie sur la solution du double problème. La contrainte est que l'émission du coupon doit être inférieure ou égale à 1, c'est-à-dire Budget. . Lambda est obtenu en le résolvant à l'aide de la méthode du double problème lagrangien. Enfin, Lambda est introduit dans la formule argmax pour le calcul, et la valeur de Xij pour chaque utilisateur peut être obtenue.

En utilisant le modèle de tarification par rapport à la livraison par enveloppe rouge dans le compartiment d'exploitation d'origine, le retour sur investissement incrémentiel peut atteindre 1,2.

La recommandation de rédaction a une idée similaire à la recommandation de produit précédente et à la recommandation d'enveloppe rouge. Nous constaterons que certains utilisateurs ont des préférences différentes pour différents styles de rédaction, nous allons donc la structurer, comme un chaleureux « avec garantie de sécurité », ou quelques avertissements sur les risques. On constatera également qu'il existe des différences relativement importantes et évidentes entre les différents groupes segmentés. Du point de vue de l'importance des caractéristiques, les phrases chaleureuses peuvent être efficaces pour les personnes nées dans les années 1980 ou pour certaines personnes plus âgées, tandis que la rédaction fondée sur la raison peut l'être. sera plus efficace, sera plus adapté aux jeunes. En termes d'importance des caractéristiques des groupes segmentés, et en même temps en essayant de personnaliser la rédaction, on constate une amélioration relative de 5 à 10 %.

Le réseau causal bayésien représente principalement la relation causale entre les transactions et la structure d'un graphe orienté à cinq anneaux. Tout d’abord, présentons brièvement pourquoi les réseaux bayésiens sont utilisés. Dans le cadre des différentes rédactions recommandées, nous souhaitons savoir pourquoi les utilisateurs sont intéressés par la rédaction, ou pourquoi ils peuvent effectuer une conversion, et quelles sont les variables cachées derrière celle-ci. Par conséquent, lors de la construction d'un réseau interprétable, les sommets sont principalement des variables observées ou des variables implicites ; les arêtes font référence aux relations causales entre deux sommets, et les relations peuvent être calculées à travers les probabilités conditionnelles entre les nœuds. Dans un réseau bayésien, la structure finale du réseau est obtenue en multipliant les valeurs de probabilité de chaque sommet dans les conditions de tous les nœuds parents.

Il existe 4 types de problèmes d'apprentissage de modèles dans la structure du réseau :
① Apprentissage structurel : basé sur des échantillons, comment apprendre un meilleur réseau bayésien, principalement basé sur des tests postérieurs, comme le montre la formule ci-dessus, si la valeur de probabilité de la structure est plus élevée, on considère que la science des réseaux est optimale.
② Après avoir obtenu la structure, comment connaître la valeur de probabilité conditionnelle du nœud dans le réseau et ses paramètres.
③ Inférence : lorsque l'événement A se produit, la probabilité que l'événement B se produise.
④ Attribution : Lorsque l'événement A se produit, quelles sont les raisons qui l'ont provoqué.

Comme mentionné ci-dessus, le scénario de recommandation d'assurance est différent de la recommandation de recherche est une activité auxiliaire, et les utilisateurs ne sont pas subjectifs, c'est-à-dire. est, avant d'arriver à ce module, que son historique de navigation dans le domaine APP n'a pas de corrélation homogène avec le type d'assurance ou de rédaction qui intéresse l'utilisateur. Dans la recherche, si vous saisissez des hôtels parent-enfant, vous saurez que les utilisateurs ont une demande pour des hôtels avec des labels parent-enfant. Dans le scénario du camp auxiliaire, un processus de raisonnement complexe est nécessaire pour savoir quel type d’action de traitement est efficace. Par exemple, grâce à l'exploitation de réseaux, on constatera que les ventes d'assurances retardées seront meilleures lorsque le temps est mauvais.

Comment modéliser et construire les nœuds et les bords du réseau dans les types suivants :
① Nœud utilisateur , l'âge et le sexe des utilisateurs Les bases l'information du portrait devient un nœud en tant que variable discrète.
② Nœud d'événement , parce que le scénario d'assurance est plus sensible aux événements que de nombreuses autres recommandations de produits, comme la météo ou les festivals, les utilisateurs peuvent être intéressés par une assurance retard, ou une assurance de propriété spécifique est plus sensible.
③ Les nœuds créatifs , tels qu'une rédaction directrice chaleureuse, une rédaction numérique dynamique, etc. auront des effets différents.
Sur la base des trois principaux types de nœuds ci-dessus, effectuez des calculs de probabilité conditionnelle pour terminer la construction du graphique.
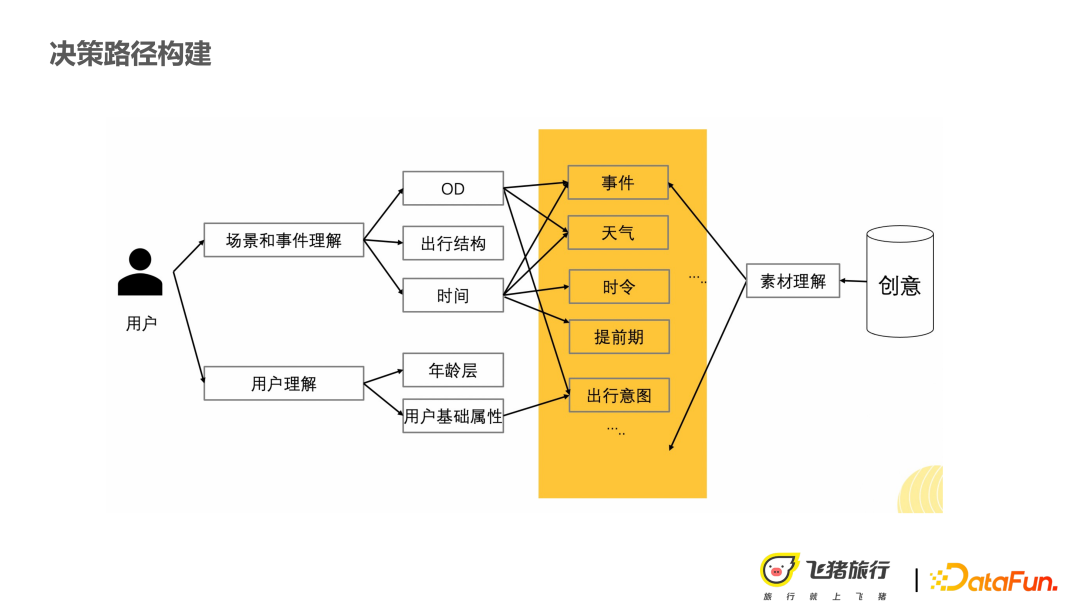
Les utilisateurs viennent de le mentionner, en développant la compréhension et la compréhension créative des scènes et des événements. Enfin, tous les types de nœuds sont unifiés dans la structure illustrée dans la figure ci-dessus.

Après avoir obtenu les nœuds, effectuez un apprentissage structurel et utilisez la fonction de notation Hockman + recherche de notes. Ce processus consiste principalement à calculer la valeur de probabilité a posteriori du réseau après avoir pris en compte les données et la structure du réseau, et à évaluer si le réseau est efficace.
Lors de l'exécution de la fonction de notation Hockman, il peut y avoir plusieurs variables, discrètes ou continues. Une fois construits, ils deviennent une variable discrète pour faciliter l’interprétation et la modélisation ultérieures. Nous supposerons que chaque variable est conforme à la distribution de Dirichlet, l'appliquerons à l'échantillon pour mettre à jour la valeur a posteriori, puis calculerons la valeur a posteriori de chaque nœud, multiplierons les probabilités entre les nœuds et obtiendrons le score de la structure. C’est relativement courant si vous êtes intéressé, vous pourrez en apprendre davantage sur cette méthode plus tard. La structure du réseau étant relativement complexe, la méthode de recherche gloutonne est utilisée dans l’ensemble du réseau. L'estimation des paramètres est relativement simple et le tableau de probabilité conditionnelle du nœud est mis à jour en fonction de l'échantillon.

Les applications interprétables, basées sur des mises à jour de structure et de paramètres, peuvent faire deux parties :
① Déduire le type de décisions que l'utilisateur peut prendre en fonction de différents types de preuves, comme les exemples mentionnés ci-dessus. Vous pouvez utiliser la pondération de vraisemblance ou la propagation des croyances en boucle, ce sont quelques-unes des méthodes les plus courantes.
② Attribution, ce qui est montré dans l'image ci-dessus est une assurance maladie. Par exemple, l'assurance accident se vend soudainement bien. Nous aimerions en connaître la raison. Est-ce parce que certaines personnes aiment l'acheter ? le pouvoir d'achat est relativement élevé, ou parce que l'utilisateur est un débutant et a rarement pris l'avion auparavant, ou que la destination de l'utilisateur a des attributs de plateau, ce qui conduit à un achat par peur.
Enfin, pour résumer, l'inférence causale joue un grand rôle dans les stratégies de foule et de recommandation des recommandations de produits d'assurance, des enveloppes rouges et du marketing de rédaction. Dans le même temps, combiné à la construction de diagrammes de cause à effet bayésiens et d'explications visuelles, il peut fournir à l'entreprise des décisions plus significatives, lui permettant de mettre continuellement à jour ses stratégies ou sa rédaction, ou d'effectuer des changements de direction. Le diagramme causal bayésien fournit également de nouvelles idées pour la sélection des fonctionnalités.
A1 : ① La vérification est là car l'effet a été amélioré sur l'AB en ligne.
② Avant d'importer le modèle causal, par exemple, la stratégie initiale dans le scénario de l'enveloppe rouge est l'estimation du taux de conversion. Si vous pouvez prédire un groupe d'utilisateurs qui ne se convertira pas à l'origine et mener des opérations marketing sur celui-ci, vous pouvez vous assurer que le coût marketing peut être contrôlé.
③ Limitations, le taux de conversion de l'utilisateur peut ne pas être élevé, ce qui signifie que même si vous lui donnez une enveloppe rouge, il ne convertira pas. Voilà donc quelques-uns des problèmes que nous avons rencontrés auparavant.
④ Après avoir importé l'inférence du modèle causal, l'amélioration la plus évidente devrait concerner la flexibilité de l'utilisateur. Après avoir utilisé la technologie d'inférence causale, nous pouvons avoir une compréhension plus claire des utilisateurs et un jugement plus clair sur les graines des groupes d'utilisateurs.
A2 : Si un grand nombre de fonctionnalités sont sélectionnées dans la première étape, l'effet peut ne pas être très bon. Lors de la sélection initiale, nous utilisons une seule variable pour voir s'il existe une corrélation particulièrement forte entre la variable et le gain, puis nous l'insérons. Bien sûr, vous pourrez voir plus tard sur le modèle d'arborescence que les caractéristiques sont notées puis filtrées, ce qui constitue la base de notre jugement.
A3 : ① Modélisation différentielle, qui conduira à une accumulation d'erreurs.
② L'apprenant T réussit principalement l'évaluation hors ligne. Nous étions assez confus à ce sujet à l'époque. En résumé, nous pensions que cela pourrait être dû au fait qu'il n'existait pas de fonctionnalité très puissante permettant de caractériser directement le gain. Les résultats obtenus ultérieurement sur certains modèles traditionnels ne sont donc pas très mauvais. Il s'agit simplement d'une évaluation du modèle complexe et du modèle simple. Le modèle simple peut être plus robuste.
③ AUUC En fait, nous l'utilisons aussi, mais ce n'est en réalité pas très différent.
④ Les variables observées peuvent faire référence à des variables observables dans les données, tandis que les variables cachées font référence à des variables cachées que nous pouvons décrire sur les données observées. Par exemple, la personnalité n’a évidemment pas été utilisée sur Internet.
A4 : Je ne l'ai pas encore essayé.
A5 : L'inférence causale était l'une de nos tâches l'année dernière, cette année, elle repose principalement sur la recommandation d'une rédaction créative.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 pr touche de raccourci
pr touche de raccourci
 Pièce de dragon d'inscription Bitcoin
Pièce de dragon d'inscription Bitcoin
 Comment ouvrir le fichier HTML WeChat
Comment ouvrir le fichier HTML WeChat
 Exigences de configuration minimales pour le système win10
Exigences de configuration minimales pour le système win10
 Comment représenter des nombres négatifs en binaire
Comment représenter des nombres négatifs en binaire
 Comment acheter du Ripple en Chine
Comment acheter du Ripple en Chine
 Comment lire des données Excel en HTML
Comment lire des données Excel en HTML
 Comment ouvrir les autorisations de portée
Comment ouvrir les autorisations de portée








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



