


Récemment, Huawei Lianhe Port Chinese a publié un article « Progressive-Hint Prompting Améliore le raisonnement dans les grands modèles de langage », proposant le Progressive-Hint Prompting (PHP) pour simuler le processus humain de prise de questions. Dans le cadre du framework PHP, le Large Language Model (LLM) peut utiliser les réponses de raisonnement générées au cours des dernières fois comme indices pour un raisonnement ultérieur, se rapprochant progressivement de la bonne réponse finale. Pour utiliser PHP, il vous suffit de remplir deux conditions : 1) la question peut être fusionnée avec la réponse d'inférence pour former une nouvelle question ; 2) le modèle peut gérer cette nouvelle question et donner une nouvelle réponse d'inférence.
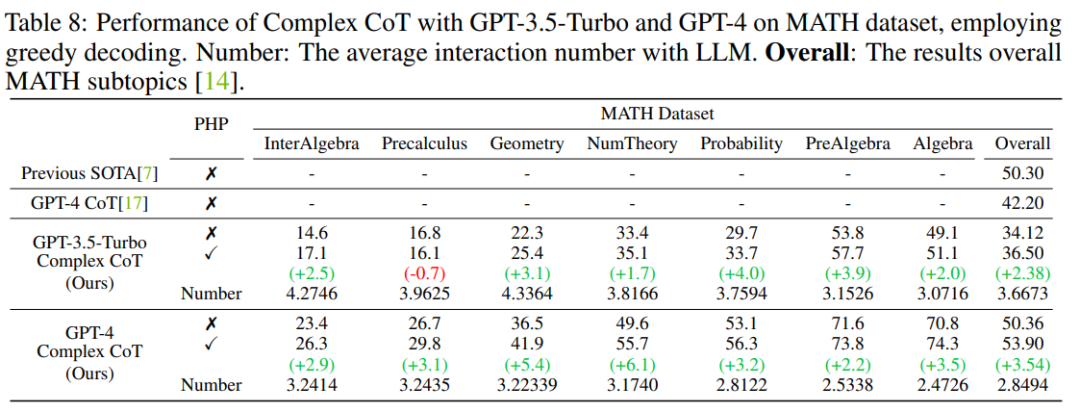
Les résultats montrent que GP-T-4+PHP obtient des résultats SOTA sur plusieurs ensembles de données, notamment SVAMP (91,9 %), AQuA (79,9 %), GSM8K (95,5 %) et MATH (53,9 %). %). Cette méthode surpasse considérablement GPT-4+CoT. Par exemple, sur l'ensemble de données de raisonnement mathématique le plus difficile, MATH, GPT-4+CoT n'est que de 42,5 %, tandis que GPT-4+PHP améliore de 6,1 % le sous-ensemble de la théorie de Nember (théorie des nombres) de l'ensemble de données MATH, augmentant ainsi le niveau de performance. global MATH à 53,9%, atteignant SOTA.

Avec le développement du LLM, certains travaux sur l'incitation ont émergé, parmi lesquels il existe deux directions principales :
Évidemment, les deux méthodes existantes n'apportent aucune modification à la question, ce qui équivaut à terminer la question une fois, sans revenir en arrière et la vérifier à nouveau avec la réponse. PHP essaie de simuler un processus de raisonnement plus humain : traitez le dernier processus de raisonnement, puis fusionnez-le dans la question d'origine et demandez à LLM de raisonner à nouveau. Lorsque les deux dernières réponses d’inférence sont cohérentes, la réponse obtenue est exacte et la réponse finale sera renvoyée. L'organigramme spécifique est le suivant :

Lorsque vous interagissez avec LLM pour la première fois, vous devez utiliser l'invite de base (invite de base), où l'invite (invite) peut être une invite standard, une invite CoT. ou Une version améliorée de celui-ci. Avec Base Prompting, vous pouvez avoir une première interaction et obtenir une réponse préliminaire. Lors des interactions ultérieures, PHP doit être utilisé jusqu'à ce que les deux réponses les plus récentes concordent.
L'invite PHP est modifiée en fonction de l'invite de base. Étant donné une invite de base, l'invite PHP correspondante peut être obtenue grâce aux principes de conception d'invite PHP formulés. Plus précisément, comme le montre la figure ci-dessous :

L'auteur espère que l'invite PHP pourra permettre aux grands modèles d'apprendre deux modes de mappage :
1) Si l'indice donné est la bonne réponse, alors le la réponse renvoyée doit toujours être la bonne réponse (en particulier "L'indice est la bonne réponse" comme indiqué dans l'image ci-dessus
2) Si l'indice donné est la mauvaise réponse, alors LLM doit utiliser le raisonnement pour sortir de l'indice ; de la mauvaise réponse et renvoie la bonne réponse (en particulier comme ci-dessus "L'indice est la réponse incorrecte" indiqué dans la figure).
Selon cette règle de conception d'invite PHP, étant donné toute invite de base existante, l'auteur peut définir l'invite PHP correspondante.
L'auteur utilise sept ensembles de données, dont AddSub, MultiArith, SingleEQ, SVAMP, GSM8K, AQuA et MATH. Dans le même temps, l'auteur a utilisé un total de quatre modèles pour vérifier ses idées, notamment text-davinci-002, text-davinci-003, GPT-3.5-Turbo et GPT-4.
Principaux résultats
PHP fonctionne mieux lorsque le modèle de langage est plus puissant et que les astuces sont plus efficaces . L'invite CoT complexe montre des améliorations significatives des performances par rapport à l'invite standard et à l'invite CoT. L'analyse montre également que le modèle de langage text-davinci-003 affiné à l'aide de l'apprentissage par renforcement fonctionne mieux que le modèle text-davinci-002 affiné à l'aide d'instructions supervisées, améliorant ainsi les performances du document. Les améliorations de performances de text-davinci-003 sont attribuées à sa capacité accrue à mieux comprendre et appliquer une invite donnée. En même temps, si vous utilisez uniquement l’invite Standard, l’amélioration apportée par PHP n’est pas évidente. Si PHP doit être efficace, il faut au moins CoT pour stimuler les capacités de raisonnement du modèle.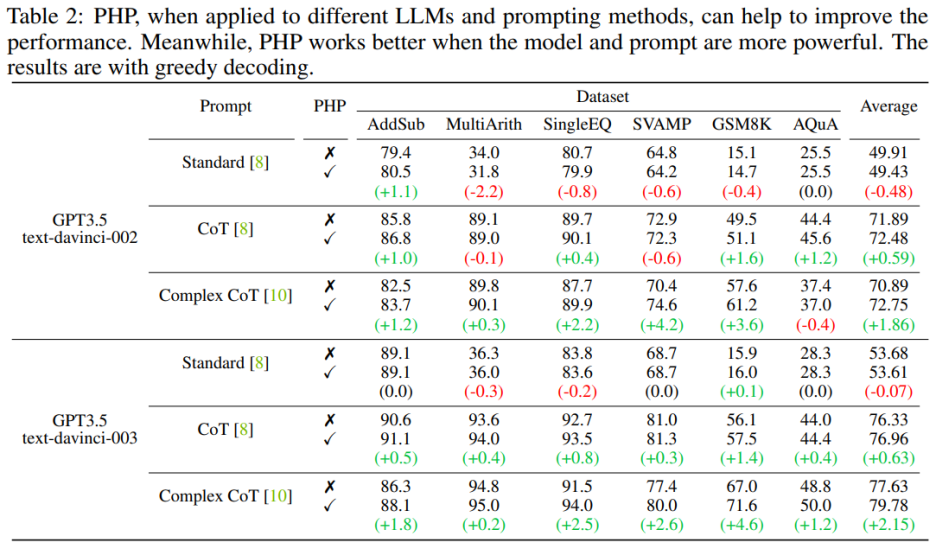
En même temps, l'auteur a également exploré la relation entre le nombre des interactions et de la relation modèle-invite. Lorsque le modèle linguistique est plus fort et les indices plus faibles, le nombre d’interactions diminue. Le nombre d'interactions fait référence au nombre de fois où l'agent interagit avec les LLM. Lorsque la première réponse est reçue, le nombre d'interactions est de 1 ; lorsque la deuxième réponse est reçue, le nombre d'interactions passe à 2. Dans la figure 2, les auteurs montrent le nombre d'interactions pour divers modèles et invites. Les résultats de recherche de l'auteur montrent que :
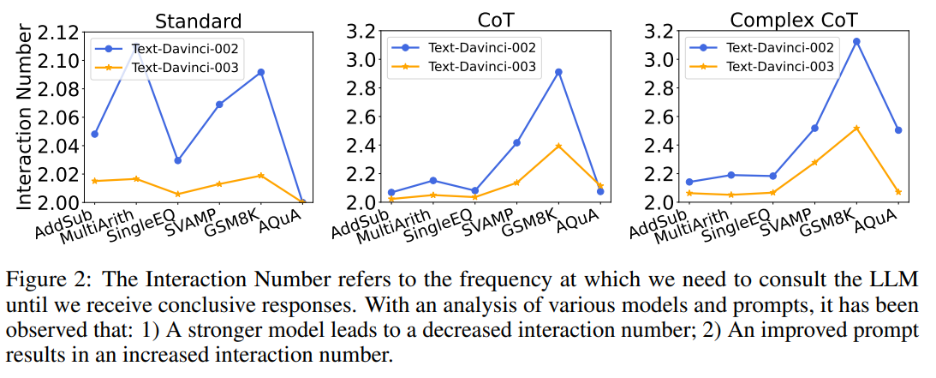
#🎜 🎜 #2) Lorsque vous utilisez le même modèle, le nombre d'interactions augmente généralement à mesure que l'invite devient plus puissante. En effet, lorsque les invites deviennent plus efficaces, les capacités de raisonnement des LLM sont mieux utilisées, ce qui leur permet d'utiliser les invites pour accéder à de mauvaises réponses, ce qui entraîne finalement un plus grand nombre d'interactions nécessaires pour atteindre la réponse finale, ce qui augmente le nombre de réponses. interactions .
Indice L'impact de la qualité
# 🎜 🎜#Pour améliorer les performances de PHP-Standard, le remplacement de Base Prompt Standard par Complex CoT ou CoT peut améliorer considérablement les performances finales. Pour PHP-Standard, les auteurs ont observé que les performances de GSM8K se sont améliorées de 16,0 % sous Base Prompt Standard à 50,2 % sous Base Prompt CoT à 60,3 % sous Base Prompt Complex CoT. À l’inverse, si vous remplacez Base Prompt Complex CoT par Standard, vous obtiendrez des performances inférieures. Par exemple, après avoir remplacé l'invite de base Complex CoT par Standard, les performances de PHP-Complex CoT ont chuté de 71,6 % à 65,5 % sur l'ensemble de données GSM8K.
Si PHP n'est pas conçu sur la base de l'invite de base correspondante, l'effet peut être encore amélioré. PHP-CoT utilisant Base Prompt Complex CoT a obtenu de meilleurs résultats que PHP-CoT utilisant CoT sur quatre des six ensembles de données. De même, PHP-Complex CoT utilisant Base Prompt CoT fonctionne mieux que PHP-Complex CoT utilisant Base Prompt Complex CoT dans quatre des six ensembles de données. L'auteur suppose que cela est dû à deux raisons : 1) sur les six ensembles de données, les performances de CoT et de Complex CoT sont similaires ; 2) parce que la réponse de base est fournie par CoT (ou Complex CoT) et que les réponses suivantes sont basé sur PHP-Complex CoT (ou PHP-CoT), qui équivaut à deux personnes travaillant ensemble pour résoudre un problème. Par conséquent, dans ce cas, les performances du système peuvent être encore améliorées. 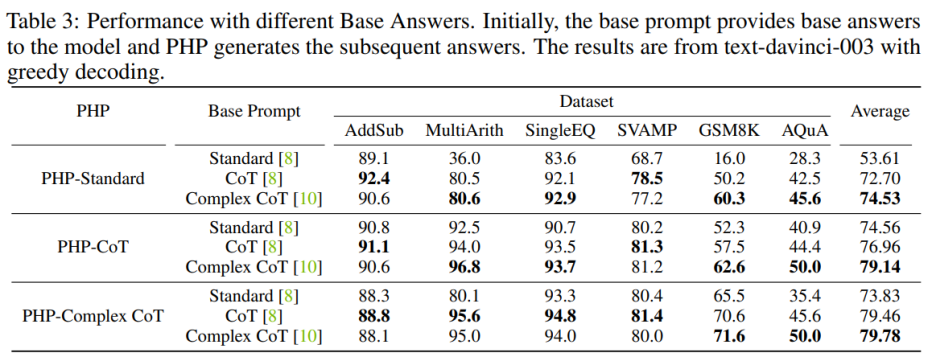
Expérience d'ablation
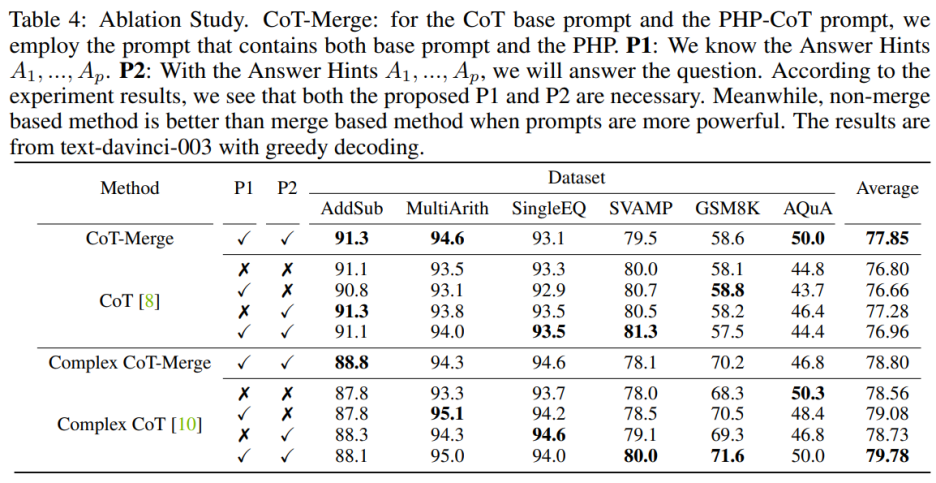
Incorporer les phrases P1 et P2 dans le modèle peut améliorer les performances de CoT sur les trois ensembles de données, mais lorsque using L'importance de ces deux phrases est particulièrement évidente lorsqu'on utilise la méthode Complex CoT. Après avoir ajouté P1 et P2, les performances de la méthode sont améliorées dans cinq des six ensembles de données. Par exemple, les performances de Complex CoT s'améliorent de 78,0 % à 80,0 % sur l'ensemble de données SVAMP et de 68,3 % à 71,6 % sur l'ensemble de données GSM8K. Cela montre que, surtout lorsque la capacité logique du modèle est plus forte, l'effet des phrases P1 et P2 est plus significatif.
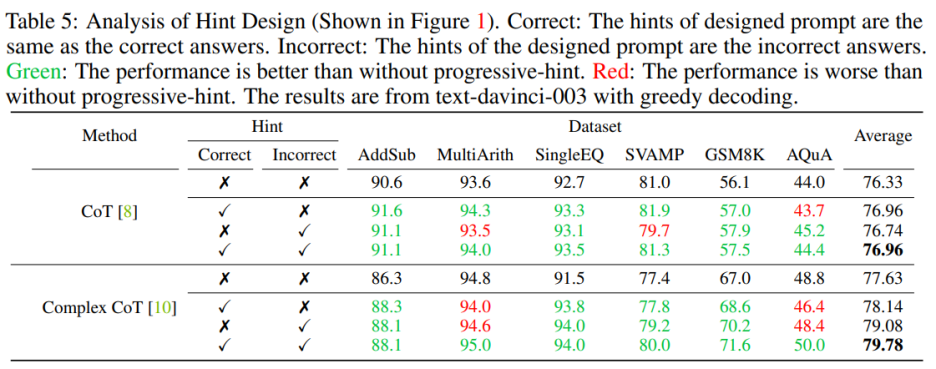
Vous devez inclure des invites correctes et incorrectes lors de leur conception. Lors de la conception d'indices contenant à la fois des indices corrects et incorrects, l'utilisation de PHP fournit de meilleurs résultats que le fait de ne pas utiliser PHP. Plus précisément, fournir l’indice correct dans l’invite facilite la génération de réponses cohérentes avec l’indice donné. Au contraire, fournir de fausses indications dans l'invite encouragera la génération d'autres réponses via l'invite donnée 🎜#
#🎜. 🎜#
#🎜 🎜# 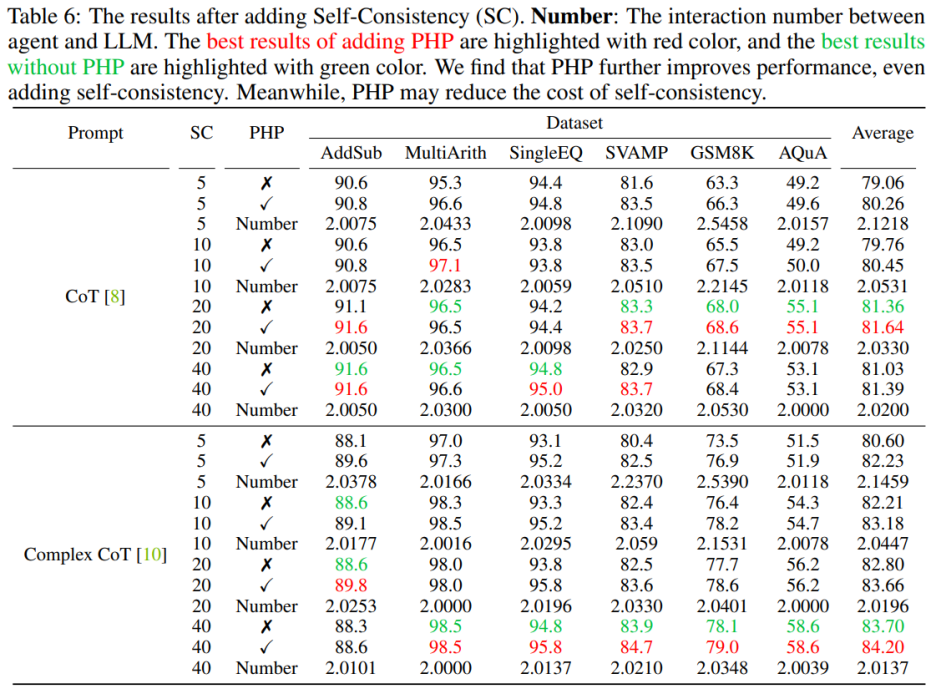 L'utilisation de PHP peut encore améliorer les performances. En utilisant un nombre similaire d'indices et d'exemples de chemins, les auteurs ont constaté que dans le tableau 6 et la figure 3, les PHP-CoT et PHP-Complex CoT proposés par les auteurs fonctionnaient toujours mieux que CoT et Complex CoT. Par exemple, CoT+SC est capable d'atteindre une précision de 96,5 % sur l'ensemble de données MultiArith avec des chemins d'échantillonnage de 10, 20 et 40. Par conséquent, on peut conclure que la meilleure performance de CoT+SC est de 96,5 % en utilisant text-davinci-003. Cependant, après la mise en œuvre de PHP, les performances sont passées à 97,1 %. De même, les auteurs ont également observé que sur l'ensemble de données SVAMP, la meilleure précision de CoT+SC était de 83,3 %, qui s'est encore améliorée à 83,7 % après la mise en œuvre de PHP. Cela montre que PHP peut éliminer les goulots d'étranglement des performances et améliorer encore les performances.
L'utilisation de PHP peut encore améliorer les performances. En utilisant un nombre similaire d'indices et d'exemples de chemins, les auteurs ont constaté que dans le tableau 6 et la figure 3, les PHP-CoT et PHP-Complex CoT proposés par les auteurs fonctionnaient toujours mieux que CoT et Complex CoT. Par exemple, CoT+SC est capable d'atteindre une précision de 96,5 % sur l'ensemble de données MultiArith avec des chemins d'échantillonnage de 10, 20 et 40. Par conséquent, on peut conclure que la meilleure performance de CoT+SC est de 96,5 % en utilisant text-davinci-003. Cependant, après la mise en œuvre de PHP, les performances sont passées à 97,1 %. De même, les auteurs ont également observé que sur l'ensemble de données SVAMP, la meilleure précision de CoT+SC était de 83,3 %, qui s'est encore améliorée à 83,7 % après la mise en œuvre de PHP. Cela montre que PHP peut éliminer les goulots d'étranglement des performances et améliorer encore les performances.
L'utilisation de PHP peut réduire le coût du SC Comme nous le savons tous, le SC implique plus de chemins de raisonnement, ce qui entraîne des coûts plus élevés. Le tableau 6 montre que PHP peut être un moyen efficace de réduire les coûts tout en conservant les gains de performances. Comme le montre la figure 3, en utilisant SC+Complex CoT, 40 exemples de chemins peuvent être utilisés pour atteindre une précision de 78,1 %, tandis que l'ajout de PHP réduit les chemins d'inférence moyens requis à 10 × 2,1531 = 21,531 chemins, et les résultats sont meilleurs et plus précis Le taux atteint 78,2%. Auteur Suite à la mise en place de travaux antérieurs, des expériences ont été menées en utilisant un modèle de génération de texte. Avec la version API de GPT-3.5-Turbo et GPT-4, les auteurs ont vérifié les performances de Complex CoT avec PHP sur les six mêmes ensembles de données. Les auteurs utilisent le décodage glouton (c'est-à-dire température = 0) et Complex CoT comme indices pour les deux modèles. 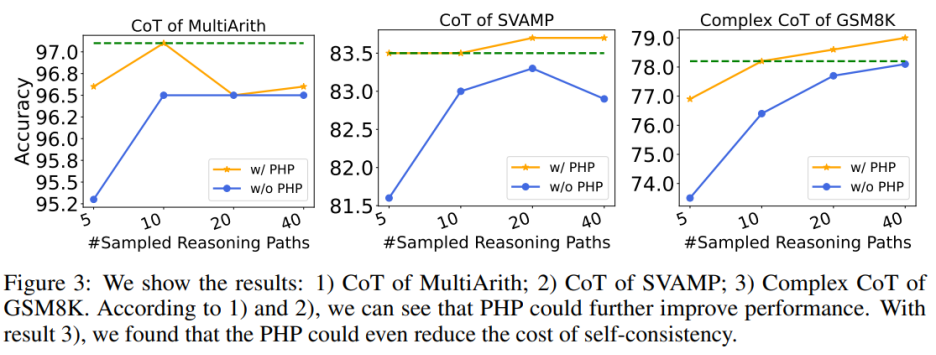
Comme le montre le tableau 7, le PHP proposé améliore les performances de 2,3% sur GSM8K et de 3,2% sur AQuA. Cependant, GPT-3.5-Turbo a montré une capacité réduite à adhérer aux signaux par rapport à text-davinci-003. Les auteurs fournissent deux exemples pour illustrer ce point : a) En cas d'indices manquants, GPT-3.5-Turbo ne peut pas répondre à la question et répond quelque chose comme "Je ne peux pas répondre à cette question car l'indice de réponse est manquant. Veuillez fournir un indice de réponse". pour continuer". En revanche, text-davinci-003 génère et remplit de manière autonome les indices de réponse manquants avant de répondre à une question ; b) lorsque plus de dix indices sont fournis, GPT-3.5-Turbo peut répondre « En raison de plusieurs réponses données, indice, je peux » Pour déterminer la bonne réponse, veuillez fournir un indice de réponse à la question.
Après avoir déployé le modèle GPT-4, les auteurs ont pu atteindre de nouvelles performances SOTA sur les benchmarks SVAMP, GSM8K, AQuA et MATH. La méthode PHP proposée par l'auteur améliore continuellement les performances de GPT-4. De plus, les auteurs ont observé que GPT-4 nécessitait moins d’interactions que le modèle GPT-3.5-Turbo, ce qui concorde avec la constatation selon laquelle le nombre d’interactions diminue lorsque le modèle est plus puissant.
Cet article présente une nouvelle méthode permettant à PHP d'interagir avec les LLM, qui présente de multiples avantages : 1) PHP implémente des tâches de raisonnement mathématique 2) PHP peut mieux profiter aux LLM en utilisant des modèles et des astuces plus puissants ; 3) PHP peut être facilement combiné avec CoT et SC, pour améliorer encore les performances.
Pour mieux améliorer la méthode PHP, les recherches futures peuvent se concentrer sur l'amélioration de la conception des invites manuelles dans la phase de question et des phrases d'invite dans la partie réponse. De plus, en plus de traiter les réponses comme des indices, de nouveaux indices peuvent être identifiés et extraits qui aident les LLM à reconsidérer le problème.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment ouvrir des fichiers HTML
Comment ouvrir des fichiers HTML
 Tutoriel d'installation du système Linux
Tutoriel d'installation du système Linux
 Analyse des perspectives de pièces ICP
Analyse des perspectives de pièces ICP
 Patch VIP Tonnerre
Patch VIP Tonnerre
 Solution de rapport d'erreur de fichier SQL d'importation Mysql
Solution de rapport d'erreur de fichier SQL d'importation Mysql
 Comment résoudre le problème de l'écran noir après avoir allumé l'ordinateur et impossible d'accéder au bureau
Comment résoudre le problème de l'écran noir après avoir allumé l'ordinateur et impossible d'accéder au bureau
 Introduction à l'utilisation de vscode
Introduction à l'utilisation de vscode
 Plateforme de change virtuelle
Plateforme de change virtuelle








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



