


Avec le développement du grand modèle de langage (LLM), de la diffusion (Diffusion) et d'autres technologies, la naissance de produits tels que ChatGPT et Midjourney a déclenché une nouvelle vague d'engouement pour l'IA, et l'IA générative est également devenue un sujet de grande actualité. préoccupation.
Contrairement au texte et aux images, la génération 3D est encore au stade de l'exploration technologique.
Fin 2022, Google, NVIDIA et Microsoft ont successivement lancé leurs propres travaux de génération 3D, mais la plupart d'entre eux sont basés sur l'expression implicite avancée du champ de rayonnement neuronal (NeRF) et sont incompatibles avec les logiciels 3D industriels tels que Unity. , Unreal Engine et Maya Le pipeline de rendu est incompatible.
Même s'il est converti en cartes géométriques et colorées exprimées par Mesh via des solutions traditionnelles, cela entraînera une précision insuffisante et une qualité visuelle réduite, et ne pourra pas être directement appliqué à la production cinématographique et télévisuelle et à la production de jeux.

Site Web du projet : https://sites.google.com/view/dreamface
Adresse papier : https://arxiv.org/abs/2304.03117
Démo Web : https://hyperhuman.top
HuggingFace Space : https://huggingface.co/spaces/DEEMOSTECH/ChatAvatar
Afin de résoudre ces problèmes, de Yingmo Technology et Shanghai L'équipe R&D de l'Université des Sciences et Technologies a proposé un cadre de génération 3D progressive guidé par texte.
Ce framework introduit des ensembles de données externes (y compris la géométrie et les matériaux PBR) qui sont conformes aux normes de production CG et peuvent générer directement des actifs 3D conformes à cette norme basés sur du texte. Il s'agit du premier framework à prendre en charge la 3D prête pour la production. génération d’actifs.
Pour obtenir des humains numériques 3D hyperréalistes basés sur la génération de texte, l'équipe a combiné ce cadre avec un ensemble de données humaines numériques 3D de qualité production. Ce travail a été accepté par Transactions on Graphics, la plus grande revue internationale dans le domaine de l'infographie, et sera présenté au SIGGRAPH 2023, la plus grande conférence internationale d'infographie.
DreamFace comprend principalement trois modules : la génération de géométrie, la diffusion de matériaux basée sur la physique et la génération de capacités d'animation.
Par rapport aux travaux de génération 3D précédents, les principales contributions de ce travail comprennent :
· Proposition de DreamFace, un nouveau schéma de génération qui combine des modèles de langage visuel récents avec des matériaux physiques et animables. apprentissage progressif pour séparer les capacités de géométrie, d’apparence et d’animation.
· Présente la conception de la génération d'apparences à double canal, combinant un nouveau modèle de diffusion de matériaux avec un modèle pré-entraîné, tout en effectuant une optimisation en deux étapes dans l'espace latent et l'espace image.
· Les éléments faciaux utilisant des BlendShapes ou des BlendShapes personnalisés générés sont animés et démontrent davantage l'utilisation de DreamFace pour la conception de personnages naturels.
Le module de génération de géométrie peut générer un modèle géométrique cohérent basé sur des invites de texte. Cependant, lorsqu’il s’agit de génération de visages, celle-ci peut être difficile à superviser et à faire converger.
Par conséquent, DreamFace propose un cadre de sélection basé sur CLIP (Contrastive Language-Image Pre-Training), qui sélectionne d'abord le meilleur modèle géométrique approximatif parmi des candidats échantillonnés au hasard dans l'espace des paramètres géométriques du visage, puis sculpte les détails géométriques pour créer le modèle de tête plus cohérent avec les indices textuels.
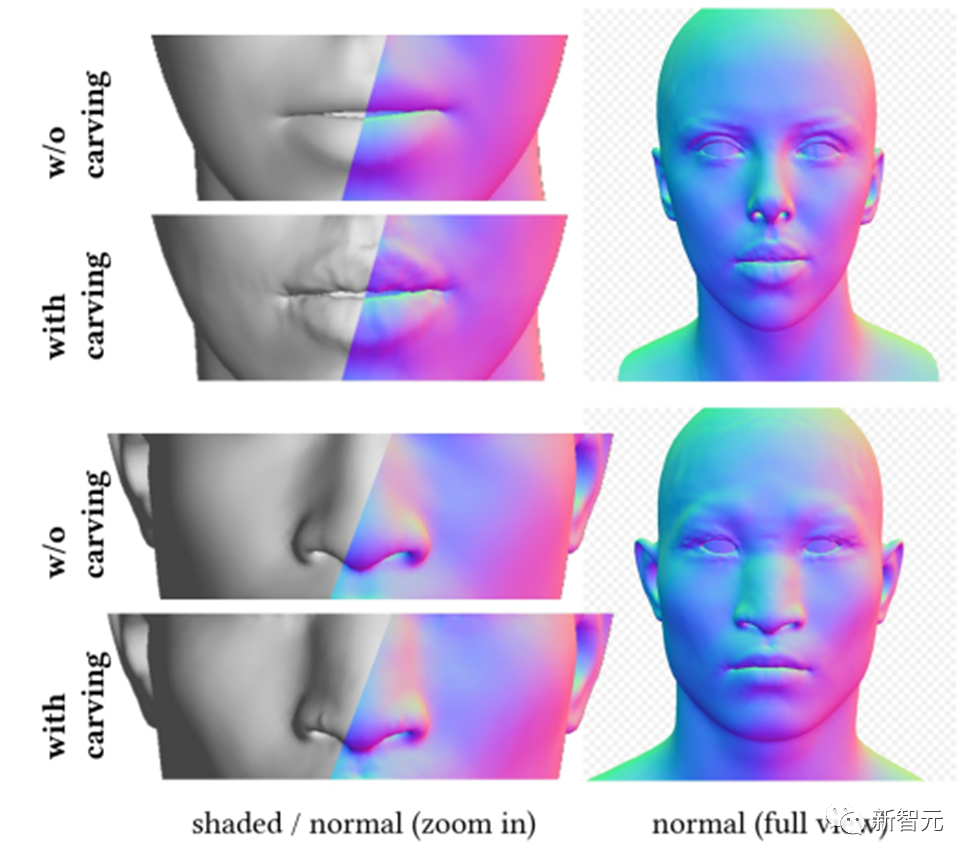
Sur la base des invites de saisie, DreamFace utilise le modèle CLIP pour sélectionner le candidat à géométrie approximative avec le score de correspondance le plus élevé. Ensuite, DreamFace utilise un modèle de diffusion implicite (LDM) pour effectuer un traitement d'échantillonnage par distillation séquentielle (SDS) sur l'image rendue sous des angles de vision et des conditions d'éclairage aléatoires.
Cela permet à DreamFace d'ajouter des détails du visage aux modèles géométriques approximatifs via le déplacement des sommets et des cartes normales détaillées, ce qui donne lieu à une géométrie très détaillée.
Semblable au modèle de tête, DreamFace effectue également des sélections de coiffures et de couleurs basées sur ce cadre.
Le module de diffusion de matériaux basé sur la physique est conçu pour prédire la cohérence avec la géométrie prédite et le texte fait allusion à la texture du visage.
Tout d'abord, DreamFace a affiné le LDM pré-entraîné sur l'ensemble de données de matériaux UV à grande échelle collectées pour obtenir deux modèles de diffusion LDM.

DreamFace utilise un protocole de formation commun pour coordonner les deux processus de diffusion, l'un est utilisé pour débruiter directement la carte de texture UV, et l'autre est utilisé pour superviser l'image rendue afin de garantir la formation correcte de la carte UV faciale et de l'image rendue cohérente avec les signaux textuels.
Afin de réduire le temps de génération, DreamFace adopte une étape de diffusion du potentiel de texture rugueuse pour fournir a priori un potentiel de génération de texture détaillée.
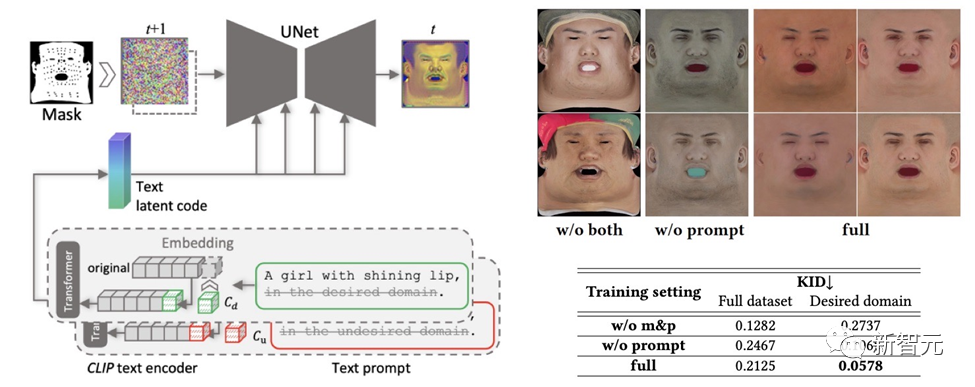
Pour garantir que la carte de texture créée ne contient pas de caractéristiques ou d'éclairage indésirables conditions, tout en maintenant la diversité, une stratégie d'apprentissage invité a été conçue.
L'équipe utilise deux méthodes pour générer des cartes diffuses de haute qualité :
(1) Réglage rapide . Contrairement aux signaux textuels spécifiques à un domaine fabriqués à la main, DreamFace combine deux signaux textuels continus spécifiques au domaine, Cd et Cu, avec les signaux textuels correspondants, qui seront optimisés lors de la formation du débruiteur U-Net pour éviter l'instabilité et l'écriture manuelle fastidieuse des invites.
(2) Masquage des zones non faciales. Le processus de débruitage LDM sera en outre contraint par des masques de zone non faciale pour garantir que la carte diffuse résultante ne contient aucun élément indésirable.
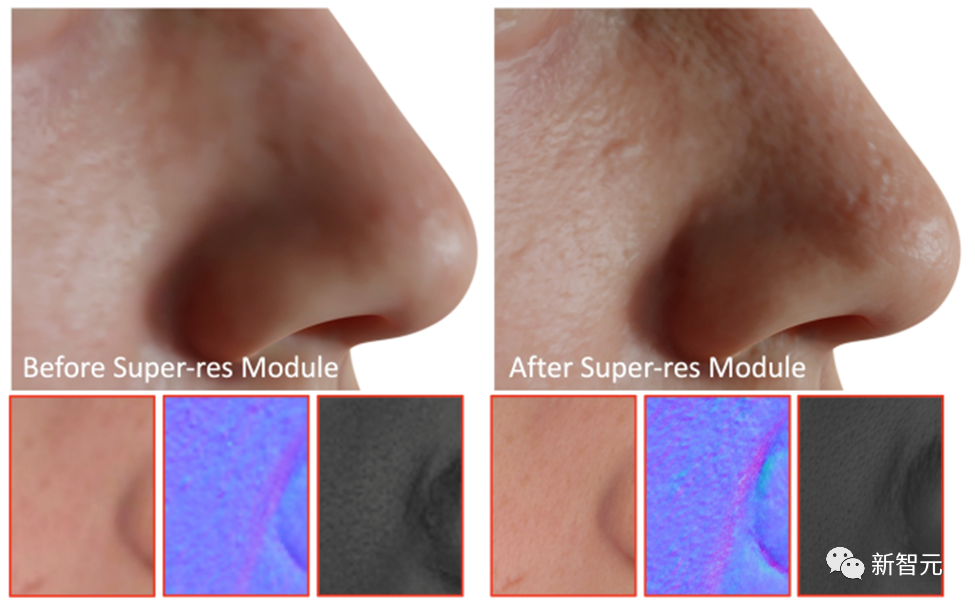
Comme dernière étape, DreamFace applique le module Super-Resolution pour générer Textures basées sur la physique 4K pour un rendu de haute qualité.

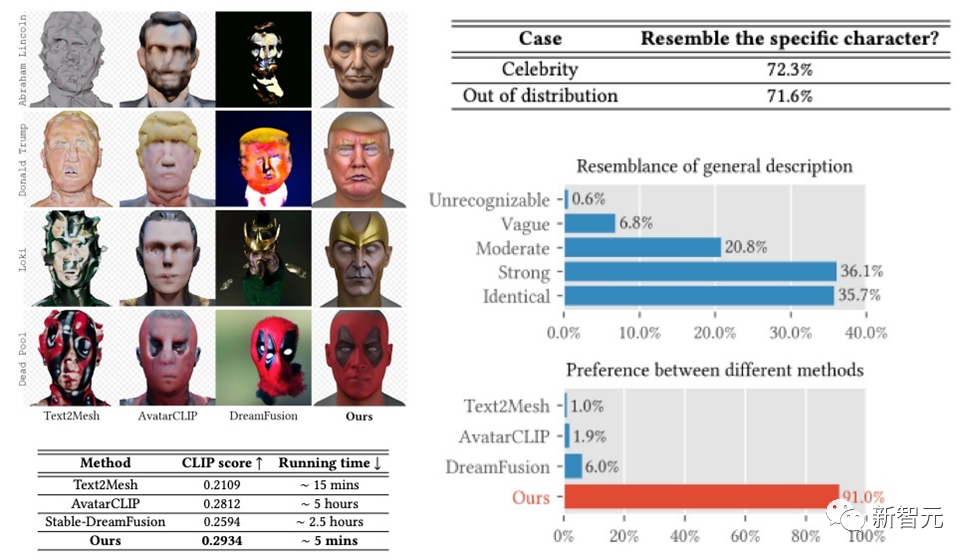
Le framework DreamFace a réalisé à la fois la génération de célébrités et la génération de personnages sur la base des descriptions. les résultats sont plutôt bons et ceux de l’étude sur les utilisateurs sont bien supérieurs à ceux des travaux antérieurs. Par rapport aux travaux antérieurs, il présente également des avantages évidents en termes de durée d'exécution.
En plus de cela, DreamFace prend également en charge l'édition de texture à l'aide de conseils et de croquis. Les effets d'édition globaux tels que le vieillissement et le maquillage peuvent être obtenus en utilisant directement des LDM et des signaux de texture affinés. En combinant davantage de masques ou de croquis, divers effets peuvent être créés, tels que des tatouages, des barbes et des taches de naissance.

#🎜🎜 #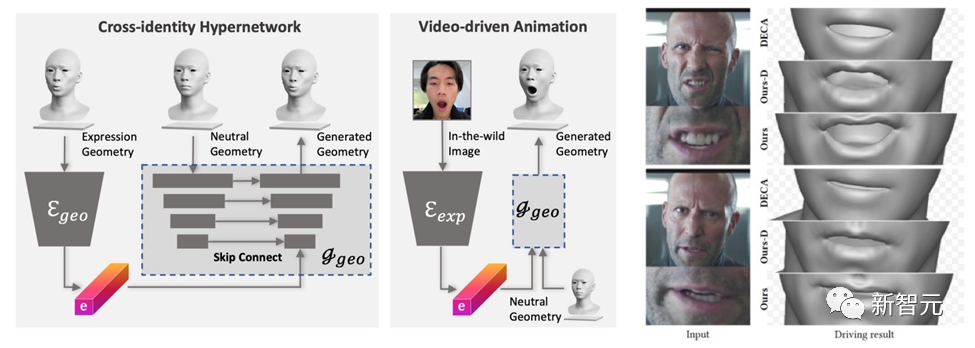
Le modèle généré par DreamFace possède des capacités d'animation. Contrairement aux méthodes basées sur BlendShapes, la méthode d'animation faciale neuronale de DreamFace produit des animations personnalisées en prédisant des déformations uniques pour animer le modèle neutre résultant.
Tout d'abord, un générateur de géométrie est formé pour apprendre l'espace latent des expressions, où le décodeur est étendu pour être conditionné sur des géométries neutres. Ensuite, l'encodeur d'expression est entraîné davantage pour extraire les caractéristiques d'expression des images RVB. Par conséquent, DreamFace est capable de générer des animations personnalisées conditionnées sur des formes géométriques neutres à l’aide d’images RVB monoculaires.
Comparé à DECA qui utilise des BlendShapes génériques pour le contrôle des expressions, le framework DreamFace fournit des détails d'expression fins et est capable de capturer des performances avec des détails fins.
Cet article présente DreamFace, un cadre de génération 3D progressive guidé par texte qui combine les derniers modèles de langage visuel, des modèles de diffusion implicites et une technologie de diffusion matérielle basée sur la physique. Les principales innovations de
DreamFace incluent la génération de géométrie, la génération de diffusion de matériaux physiques et la génération de capacités d'animation. Par rapport aux méthodes de génération 3D traditionnelles, DreamFace offre une plus grande précision, une vitesse d'exécution plus rapide et une meilleure compatibilité avec les pipelines CG.
Le cadre de génération progressive de DreamFace fournit une solution efficace pour résoudre des tâches complexes de génération 3D et devrait promouvoir davantage de recherches et de développements technologiques similaires.
De plus, la génération de diffusion de matériaux physiques et la génération de capacités d'animation favoriseront l'application de la technologie de génération 3D dans la production cinématographique et télévisuelle, le développement de jeux et d'autres industries connexes.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Solution au problème selon lequel le système Win7 ne peut pas démarrer
Solution au problème selon lequel le système Win7 ne peut pas démarrer
 utilisation du curseur Oracle
utilisation du curseur Oracle
 Que signifie la liquidation ?
Que signifie la liquidation ?
 Utilisation de la fonction GAMMAINV
Utilisation de la fonction GAMMAINV
 Quelles sont les technologies de collecte de données ?
Quelles sont les technologies de collecte de données ?
 Quels sont les logiciels bureautiques
Quels sont les logiciels bureautiques
 Pourquoi l'imprimante n'imprime-t-elle pas ?
Pourquoi l'imprimante n'imprime-t-elle pas ?
 qu'est-ce que Hadoop
qu'est-ce que Hadoop








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



