


Au cours des deux dernières années, les grands modèles qui « font des miracles avec une grande puissance (puissance de calcul) » sont devenus la tendance poursuivie par la plupart des chercheurs dans le domaine de l'intelligence artificielle. Cependant, les énormes problèmes de coût de calcul et de consommation de ressources qui en découlent sont progressivement devenus évidents. Certains scientifiques ont commencé à examiner sérieusement les grands modèles et à rechercher activement des solutions. De nouvelles recherches montrent que l’obtention d’excellentes performances des modèles d’IA ne dépend pas nécessairement de la puissance de calcul et de la taille du tas.
Le deep learning est en plein essor depuis dix ans. Il faut dire que ses opportunités et ses freins ont suscité beaucoup d'attention et de discussions au cours de ces dix années de recherche et de pratique.
Parmi eux, la dimension de goulot d'étranglement la plus frappante est les caractéristiques de la boîte noire de l'apprentissage profond (manque d'interprétabilité) et les « résultats miraculeux avec beaucoup d'efforts » (les paramètres du modèle deviennent de plus en plus grands et les besoins en puissance de calcul augmentent). de plus en plus importants. Les coûts de calcul sont également de plus en plus élevés). À cela s’ajoutent des problèmes tels qu’une stabilité insuffisante du modèle et des failles de sécurité.
Essentiellement, ces problèmes sont en partie causés par la nature systémique « en boucle ouverte » des réseaux de neurones profonds. Pour briser la « malédiction » de la face B de l’apprentissage profond, il ne suffit peut-être pas simplement d’étendre l’échelle du modèle et la puissance de calcul. Il nous faut plutôt en retracer la source, à partir des principes de base des systèmes d’intelligence artificielle, et de celle-ci. une nouvelle perspective (telle que la boucle fermée) Comprendre « l'intelligence ».
Le 12 juillet, trois scientifiques chinois de renom dans le domaine de l'intelligence artificielle, Ma Yi, Cao Ying et Shen Xiangyang, ont publié conjointement un article sur arXiv, « Sur les principes de parcimonie et d'auto-cohérence pour l'émergence of Intelligence", propose un nouveau cadre pour comprendre les réseaux profonds : la transcription compressive en boucle fermée.
Ce cadre contient deux principes : la parcimonie et l'auto-cohérence, qui correspondent respectivement à « quoi apprendre » et « comment apprendre » dans le processus d'apprentissage du modèle d'IA. Ce sont les deux fondements majeurs qui. constituent l’intelligence artificielle/naturelle et ont attiré une large attention dans le domaine de la recherche sur l’intelligence artificielle au pays et à l’étranger.

Lien papier :
https://arxiv.org/pdf/2207.04630.pdf
Trois scientifiques pensent que la véritable intelligence doit avoir deux caractéristiques, l'une est l'explicabilité et l'autre l'interprétabilité. est la calculabilité.
Cependant, au cours de la dernière décennie, les progrès de l'intelligence artificielle se sont principalement appuyés sur des méthodes d'apprentissage profond qui utilisent des modèles d'entraînement par « force brute ». Dans ce cas, le modèle d'IA peut également obtenir des modules fonctionnels pour la perception. et prise de décision. Les représentations des caractéristiques apprises sont souvent implicites et difficiles à interpréter.
De plus, le fait de compter uniquement sur une grande puissance de calcul pour entraîner le modèle a également entraîné une augmentation continue de l'échelle du modèle d'IA, le coût de calcul continue d'augmenter et de nombreux problèmes sont survenus lors de l'atterrissage des applications, tels que l'effondrement neuronal conduisant à un manque de diversité dans la nature des représentations apprises, l'effondrement des modes conduisant à un manque de stabilité dans l'entraînement, une mauvaise sensibilité du modèle à l'adaptabilité et un oubli catastrophique, etc.
Trois scientifiques pensent que le problème ci-dessus se produit parce que dans les réseaux profonds actuels, la formation de modèles discriminants pour la classification et de modèles génératifs pour l'échantillonnage ou la relecture est séparée dans la plupart des cas. De tels modèles sont généralement des systèmes en boucle ouverte qui nécessitent une formation de bout en bout via une supervision ou une auto-supervision. Wiener et d’autres ont découvert depuis longtemps qu’un tel système en boucle ouverte ne peut pas corriger automatiquement les erreurs de prédiction, ni s’adapter aux changements de l’environnement.
Par conséquent, ils préconisent l'introduction d'un « feedback en boucle fermée » dans le système de contrôle afin que le système puisse apprendre à corriger les erreurs par lui-même. Dans cette étude, ils ont également découvert qu'en utilisant le modèle discriminatif et le modèle génératif pour former un système complet en boucle fermée, le système peut apprendre de manière indépendante (sans supervision externe) et est plus efficace, stable et adaptable.


Légende : De gauche à droite se trouvent Shun Xiangyang (professeur présidentiel de Hong Kong, Chine et Shenzhen, académicien étranger de la National Academy of Engineering, ancien vice-président exécutif mondial de Microsoft), Cao Ying (académicien de la National Academy of Sciences, University of California, Berkeley) Professeur à l'Université de Californie, Berkeley) et Ma Yi (Professeur à l'Université de Californie, Berkeley).
Dans cet ouvrage, trois scientifiques ont proposé deux principes de base pour expliquer la composition de l'intelligence artificielle, à savoir la simplicité et l'auto-cohérence (également appelée « auto-cohérence » "), et en prenant comme exemple la modélisation de données d'images visuelles, un cadre de transcription compressé en boucle fermée est dérivé des premiers principes de parcimonie et d'auto-cohérence.
La soi-disant simplicité est « ce qu'il faut apprendre ». Le principe de parcimonie intelligente nécessite que les systèmes obtiennent des représentations compactes et structurées de manière efficace sur le plan informatique. Autrement dit, les systèmes intelligents peuvent utiliser n’importe quel modèle structuré décrivant le monde, à condition qu’ils puissent simuler simplement et efficacement des structures utiles dans des données sensorielles réelles. Le système doit être capable d'évaluer avec précision et efficacité la qualité d'un modèle d'apprentissage à l'aide de mesures fondamentales, universelles, faciles à calculer et à optimiser.
En prenant comme exemple la modélisation de données visuelles, le principe de parcimonie tente de trouver une transformation (non linéaire) f pour atteindre les objectifs suivants :
Compression : mapper des données sensorielles de haute dimension x à une représentation z de basse dimension
Linéarisation : mappez chaque classe d'objets distribués sur la sous-variété non linéaire à un sous-espace linéaire ;
Scarification : mappez différentes classes à des sous-espaces avec une base indépendante ou maximalement incohérente.
C'est-à-dire que les données du monde réel qui peuvent être localisées sur une série de sous-variétés de faible dimension dans un espace de grande dimension sont converties en séries de sous-espaces linéaires indépendants de basse dimension. Ce modèle est appelé « représentation discriminante linéaire » (représentation discriminante linéaire, LDR), et le processus de compression est illustré dans la figure 2 :
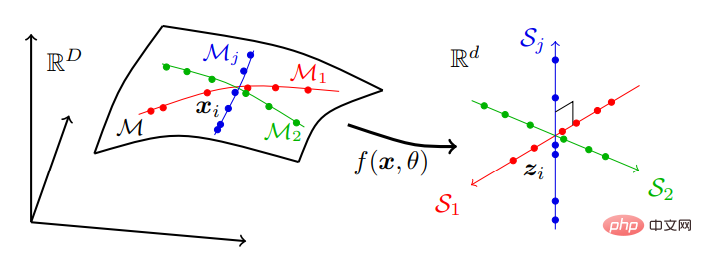
Figure 2 : Recherche d'une représentation linéaire et discriminante, qui sera généralement distribuée parmi de nombreux bas non linéaires subdivisions dimensionnelles Les données sensorielles de grande dimension sur une variété sont mappées sur un ensemble de sous-espaces linéaires indépendants ayant les mêmes dimensions que la sous-variété.
Dans la famille des modèles LDR, il existe une mesure intrinsèque de parcimonie. Autrement dit, étant donné un LDR, nous pouvons calculer le « volume » total couvert par toutes les entités sur tous les sous-espaces et la somme du « volume » couvert par les entités de chaque catégorie. Le rapport entre ces deux volumes donne alors une mesure naturelle de la qualité du modèle LDR (plus gros est souvent mieux).
Selon la théorie de l'information, le volume d'une distribution peut être mesuré par sa distorsion de débit.
Un ouvrage "ReduNet : A White-box Deep Network from the Principle of Maximizing Rate Reduction" par l'équipe de Ma Yi en 2022 montre que si vous utilisez la fonction de distorsion de débit gaussienne et choisissez un réseau profond général (tel que ResNet) pour modéliser la cartographie f(x, θ) en minimisant le taux de codage.

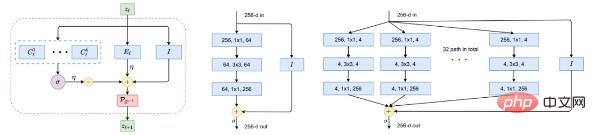
Figure 5 : Éléments constitutifs de la cartographie non linéaire f. À gauche : une couche de ReduNet, en tant qu'itération de montée de gradient projetée, consistant précisément en une expansion ou une compression d'opérateurs linéaires, un softmax non linéaire, des connexions sautées et une normalisation. Milieu et droite de la figure : une couche de ResNet et ResNeXt respectivement.
Les lecteurs avisés auront peut-être reconnu qu'un tel graphique est très similaire aux réseaux profonds populaires « éprouvés » tels que ResNet (Figure 5 au milieu), y compris les colonnes parallèles dans ResNeXt (Figure 5 à droite) et le mixage expert (MoE). .
Du point de vue du déploiement des schémas d'optimisation, cela fournit une explication puissante pour une classe de réseaux de neurones profonds. Même avant l’essor des réseaux profonds modernes, les schémas d’optimisation itératifs pour rechercher la parcimonie, tels qu’ISTA ou FISTA, étaient interprétés comme des réseaux profonds apprenables.
À travers des expériences, ils démontrent que la compression peut donner naissance à une manière constructive de dériver des réseaux de neurones profonds, y compris son architecture et ses paramètres, comme une boîte blanche entièrement interprétable : ses paires de couches favorisent des principes parcimonieux. Optimisation itérative et incrémentale des objectifs sexuels . Par conséquent, pour les réseaux profonds ainsi obtenus, les ReduNets, en commençant par les données X en entrée, les opérateurs et les paramètres de chaque couche sont construits et initialisés de manière entièrement déployée vers l'avant.
C'est très différent de la pratique populaire en matière d'apprentissage profond : commencer par un réseau construit et initialisé de manière aléatoire, puis effectuer des ajustements globaux par rétropropagation. Il est généralement admis qu’il est peu probable que le cerveau utilise la rétropropagation comme mécanisme d’apprentissage en raison de la nécessité de synapses symétriques et de formes complexes de rétroaction. Ici, l'optimisation du déroulement direct repose uniquement sur des opérations entre couches adjacentes qui peuvent être câblées et donc plus faciles à mettre en œuvre et à exploiter.
L'évolution des réseaux de neurones artificiels au cours de la dernière décennie est facile à comprendre et particulièrement utile pour expliquer une fois que l'on réalise que le rôle des réseaux profonds eux-mêmes est d'effectuer une optimisation itérative (basée sur les gradients) pour compresser, linéariser et fragmenter les données. Pourquoi seuls quelques systèmes d'IA se démarquent grâce à un processus de sélection humaine : de MLP à CNN en passant par ResNet et Transformer.
En revanche, les recherches aléatoires de structures de réseau, telles que la recherche d'architecture neuronale, ne produisent pas d'architectures de réseau capables d'effectuer efficacement des tâches générales. Ils émettent l’hypothèse que les architectures performantes deviennent de plus en plus efficaces et flexibles dans la simulation de schémas d’optimisation itératifs pour la compression des données. Cela peut être illustré par les similitudes mentionnées précédemment entre ReduNet et ResNet/ResNeXt. Bien entendu, il existe de nombreux autres exemples.
L'auto-cohérence concerne "comment apprendre", c'est-à-dire que les systèmes intelligents autonomes recherchent le modèle le plus cohérent pour observer le monde extérieur en minimisant les différences internes entre ce qui est observé et ce qui est observé. reproducteur.
Le principe de parcimonie à lui seul ne garantit pas que le modèle d'apprentissage puisse capturer toutes les informations importantes dans la perception des données du monde externe.
Par exemple, mapper chaque classe sur un vecteur unidimensionnel « one-hot » en minimisant l'entropie croisée peut être considérée comme une forme parcimonieuse. Il peut apprendre un bon classificateur, mais les caractéristiques apprises se décomposent en singletons, appelés « effondrement nerveux ». Les fonctionnalités ainsi apprises ne contiennent pas suffisamment d'informations pour régénérer les données d'origine. Même si l’on considère la classe plus générale des modèles LDR, l’objectif de réduction de vitesse à lui seul ne détermine pas automatiquement les dimensions correctes de l’espace des fonctionnalités de l’environnement. Si la dimension de l'espace des fonctionnalités est trop faible, le modèle appris sera sous-ajusté aux données ; si elle est trop élevée, le modèle peut être surajusté.
Selon eux, le but de la perception est d'apprendre tout le contenu perceptuel prévisible. Un système intelligent devrait être capable de régénérer une distribution de données observées à partir d’une représentation compressée qu’une fois générée, il ne peut pas distinguer lui-même, quels que soient ses efforts.
Le document souligne que les deux principes d'auto-cohérence et de parcimonie sont très complémentaires et doivent toujours être utilisés ensemble. L'autocohérence à elle seule ne garantit pas des gains en termes de compression ou d'efficacité.
Mathématiquement et informatiquement, ajustez toutes les données d'entraînement à l'aide d'un modèle sur-paramétré ou assurez la cohérence en établissant une cartographie un-à-un entre des domaines de mêmes dimensions, sans apprendre les intrinsèques de la distribution des données. La structure est très simple . Ce n'est que grâce à la compression que les systèmes intelligents peuvent être obligés de découvrir des structures inhérentes de basse dimension dans des données sensorielles de haute dimension, et de transformer et représenter ces structures dans l'espace des caractéristiques de la manière la plus compacte pour une utilisation future.
De plus, ce n'est que grâce à la compression que nous pouvons facilement comprendre les raisons d'un surparamétrage. Par exemple, comme DNN, qui effectue généralement une amélioration des fonctionnalités via des centaines de canaux, si son objectif pur est la compression dans un espace de fonctionnalités de grande dimension. , puis ne conduit pas à un surajustement : le boosting permet de réduire la non-linéarité des données, ce qui facilite leur compression et leur linéarisation. Le rôle des couches suivantes est d’effectuer la compression (et la linéarisation), et généralement plus il y a de couches, meilleure est la compression.
Dans le cas particulier de la compression vers une représentation structurée telle que LDR, l'article appelle un type d'encodage automatique (voir l'article original pour plus de détails) "transcription". La difficulté ici est de rendre l’objectif réalisable informatiquement et donc physiquement réalisable.
La réduction du taux ΔR donne une mesure de distance primaire sans ambiguïté entre les distributions dégénérées. Mais cela ne fonctionne que pour les sous-espaces ou les mélanges de gaussiennes, pas pour les distributions générales ! Et nous ne pouvons que nous attendre à ce que la distribution de la représentation structurée interne z soit un mélange de sous-espaces ou de gaussiennes, et non les données originales x.
Cela nous amène à une question assez profonde sur l'apprentissage des représentations « auto-cohérentes » : les systèmes autonomes ont-ils vraiment besoin de mesurer les différences dans l'espace des données afin de vérifier qu'un modèle interne du monde externe est correct ?
La réponse est non.
La clé est de réaliser que pour comparer x et x^, l'agent n'a besoin que de comparer leurs caractéristiques internes respectives z = f(x) et z^ = f(x^) via le même mappage f, de sorte que z Compact et structuré.
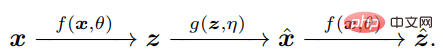
Mesurer les différences de distribution dans l'espace z est en fait bien défini et efficace : sans doute, dans l'intelligence naturelle, l'apprentissage des différences de mesure internes est la seule chose qu'un cerveau doté de systèmes autonomes indépendants peut faire.
Cela génère effectivement un système de rétroaction en « boucle fermée », l'ensemble du processus étant illustré à la figure 6.
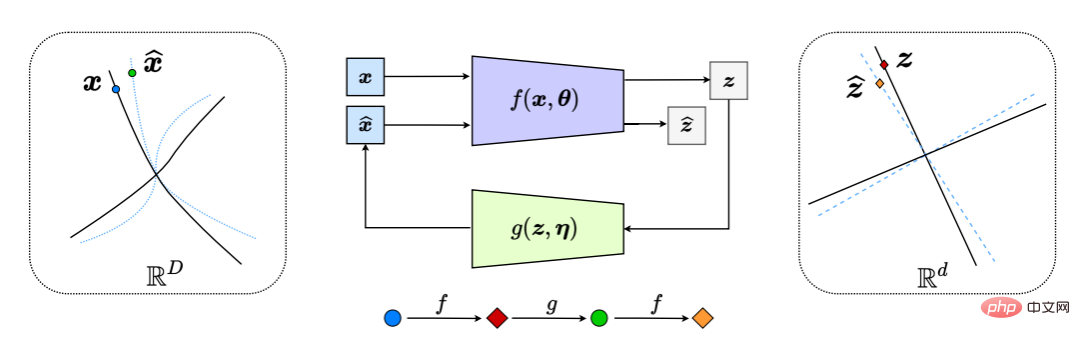
Figure 6 : Transcription compressée en boucle fermée de sous-variétés de données non linéaires en LDR (en comparant et en minimisant la différence entre z et z^ en interne). Il en résulte un jeu naturel de poursuite et de vol entre le codeur/capteur f et le décodeur/contrôleur g, tel que la distribution des données x^ décodées (ligne pointillée bleue) poursuit et correspond à la distribution des données observées x (ligne pointillée bleue). ligne continue) .
On peut interpréter la pratique populaire consistant à apprendre séparément un classificateur DNN f ou un générateur g comme l'apprentissage de la partie ouverte d'un système en boucle fermée (Figure 6). Cette approche actuellement populaire est très similaire au contrôle en boucle ouverte, que le domaine du contrôle sait depuis longtemps comme problématique et coûteux : la formation d'une telle partie nécessite une supervision de la sortie souhaitée (comme une étiquette de classe si la distribution des données, le système) ; Si les paramètres ou les tâches changent, le déploiement de tels systèmes en boucle ouverte manque intrinsèquement de stabilité, de robustesse ou d'adaptabilité. Par exemple, les réseaux de classification approfondis formés dans un environnement supervisé souffrent souvent d’oublis catastrophiques s’ils sont recyclés pour gérer de nouvelles tâches avec de nouvelles catégories de données.
En revanche, les systèmes en boucle fermée sont intrinsèquement plus stables et adaptatifs. En fait, Hinton et al. l’avaient déjà proposé en 1995. Les composants discriminatifs et génératifs doivent être combinés respectivement en tant que phases « éveil » et « sommeil » du processus d'apprentissage complet.
Cependant, boucler la boucle ne suffit pas.
Le journal préconise que tout agent intelligent a besoin d'un mécanisme de jeu interne pour pouvoir s'auto-apprendre par l'autocritique ! Ce qui suit ici est le concept du jeu comme moyen d’apprentissage universellement efficace : appliquer de manière répétée un modèle ou une stratégie actuelle contre des critiques contradictoires, améliorant ainsi continuellement le modèle ou la stratégie sur la base des commentaires reçus en boucle fermée !
Dans un tel cadre, l'encodeur f joue un double rôle : en plus d'apprendre une représentation z des données x en maximisant la réduction de débit ΔR(Z) (comme fait dans la section 2.1), il doit également servir de feedback Un « capteur » qui détecte activement la différence entre les données x et le x^ généré. Le décodeur g joue également un double rôle : c'est un contrôleur, lié à l'écart entre x et une certaine précision).
Par conséquent, le tuple de représentation optimal « parcimonieux » et « auto-cohérent » (z, f, g) peut être interprété comme le point d'équilibre du jeu à somme nulle entre f(θ) et g(η), et Non basé sur l'utilité d'une réduction combinée des tarifs :
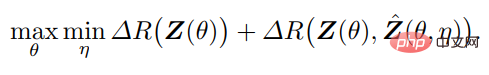
La discussion ci-dessus est la mise en œuvre des deux principes dans une situation supervisée.
Mais l'article souligne que le cadre de transcription compressé en boucle fermée qu'ils ont proposé est capable d'auto-apprentissage grâce à l'auto-surveillance et à l'autocritique !
De plus, puisque la réduction du taux a trouvé une représentation explicite (de type sous-espace) pour la structure d'apprentissage, elle facilite la conservation des connaissances passées lors de l'apprentissage de nouvelles tâches/données et peut servir de mémoire préalable qui maintient l'auto-apprentissage. cohérence .
Des études empiriques récentes montrent que cela peut produire le premier système neuronal autonome avec une mémoire fixe, capable d'apprendre progressivement de bonnes représentations LDR sans subir d'oubli catastrophique. Pour un tel système en boucle fermée, oublier (le cas échéant) est assez élégant.
De plus, la représentation apprise peut être davantage consolidée lorsque les images des anciennes catégories sont à nouveau transmises au système pour examen – une fonctionnalité très similaire à celle de la mémoire humaine. Dans un sens, cette formulation contrainte en boucle fermée garantit essentiellement que la formation de la mémoire visuelle peut être bayésienne et adaptative, en supposant que ces caractéristiques soient idéales pour le cerveau.
Comme le montre la figure 8, le codage automatique ainsi appris présente non seulement une bonne cohérence des échantillons, mais les caractéristiques apprises présentent également une structure locale claire et significative de faible dimension (mince).

Figure 8 : Gauche : Comparaison entre le x auto-encodé appris dans le cadre non supervisé de l'ensemble de données CIFAR-10 (50 000 images avec 10 classes) et le x^ décodé correspondant. À droite : t-SNE de fonctionnalités apprises non supervisées pour 10 classes, et visualisation de plusieurs quartiers et de leurs images associées. Notez la structure localement mince (presque unidimensionnelle) des entités visualisées, projetées à partir d'un espace d'entités de centaines de dimensions.
Plus surprenant encore, des structures diagonales de blocs liées aux sous-espaces ou aux fonctionnalités commencent à apparaître dans les fonctionnalités apprises pour la classe même lorsqu'aucune information de classe n'est fournie pendant la formation (Figure 9) ! Par conséquent, la structure des caractéristiques apprises est similaire aux régions sélectives de catégories observées dans le cerveau des primates.
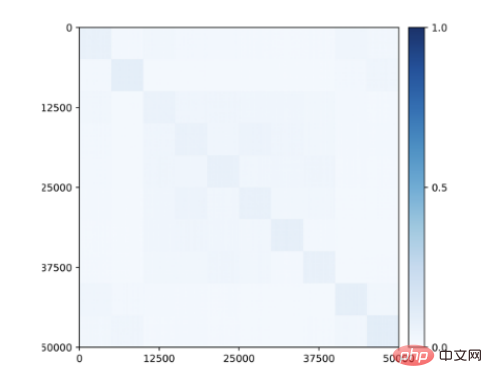
Figure 9 : Corrélation entre les fonctionnalités apprises non supervisées pour 50 000 images appartenant à 10 catégories (CIFAR-10) via transcription en boucle fermée. Des structures diagonales de blocs cohérentes avec les classes émergent sans aucune supervision.
Le résumé papier, la parcimonie et l'auto-cohérence révèlent le rôle des réseaux profonds en tant que modèles de cartographie non linéaire entre observations externes et représentations internes.
En outre, l'article souligne que les structures de compression en boucle fermée sont omniprésentes dans la nature et sont applicables à toutes les créatures intelligentes. Cela peut être observé dans le cerveau (compression des informations sensorielles), dans les circuits de la moelle épinière (compression des mouvements musculaires). et l'ADN (compression des informations sur la fonction des protéines)) et ainsi de suite, des exemples biologiques. Par conséquent, ils pensent que la transcription compressée en boucle fermée pourrait être le moteur d’apprentissage universel derrière tous les comportements intelligents. Il permet aux organismes et systèmes intelligents de découvrir et d'affiner des structures de faible dimension à partir d'entrées apparemment complexes et non organisées, et de les convertir en structures internes compactes et organisées qui peuvent être mémorisées et utilisées.
Pour illustrer la généralité de ce cadre, l'article étudie deux autres tâches : la perception 3D et la prise de décision (LeCun considère ces deux modules clés des systèmes intelligents autonomes). Cet article est organisé et présente uniquement la boucle fermée de la vision par ordinateur et de l'infographie dans la perception 3D.
Le paradigme classique de la vision 3D proposé par David Marr dans son livre influent Vision préconise une approche « diviser pour régner », divisant la tâche de perception 3D en plusieurs processus modulaires : du traitement 2D de bas niveau (par exemple, détection des bords, détection des contours esquisse), analyse 2,5D de niveau intermédiaire (par exemple, regroupement, segmentation, forme et fond) et reconstruction 3D avancée (par exemple, pose, forme) et reconnaissance (par exemple, objet), alors qu'en revanche, la boucle fermée compressée Le cadre de transcription prône la « construction conjointe » de la pensée.
La perception est une transcription compressée en boucle fermée ? Plus précisément, les représentations 3D de la forme, de l’apparence et même de la dynamique des objets dans le monde devraient être les représentations les plus compactes et structurées développées en interne par notre cerveau pour interpréter en conséquence toutes les observations visuelles perçues. Si tel est le cas, alors ces deux principes suggèrent qu’une représentation 3D compacte et structurée est le modèle interne à rechercher. Cela signifie que nous pouvons et devons unifier la vision par ordinateur et l'infographie dans un cadre informatique en boucle fermée, comme le montre la figure ci-dessous :
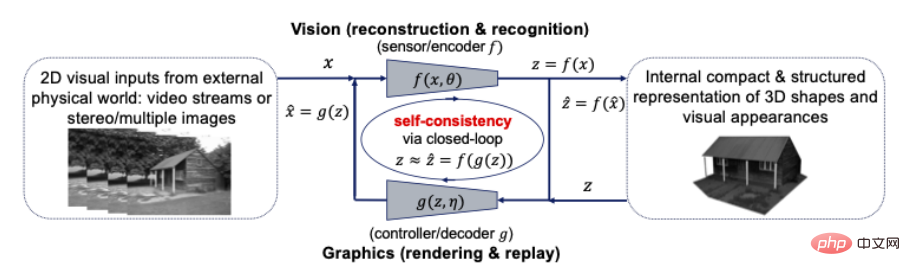
Figure 10 : Relation en boucle fermée entre la vision par ordinateur et le graphisme pour une somme compacte de visuels entrées Modèles 3D structurés
La vision par ordinateur est souvent expliquée comme le processus avancé de reconstruction et d'identification de modèles 3D internes pour toutes les entrées visuelles 2D, tandis que l'infographie représente son processus inverse de rendu et d'animation de modèles 3D internes. La combinaison de ces deux processus directement dans un système en boucle fermée peut apporter d'énormes avantages informatiques et pratiques : toutes les structures riches en géométrie, en apparence visuelle et en dynamique (telles que la parcimonie et la douceur) peuvent être utilisées ensemble dans un modèle 3D unifié, le plus compact. et cohérent avec toutes les entrées visuelles.
Les techniques de reconnaissance en vision par ordinateur peuvent aider l'infographie à créer des modèles compacts dans l'espace de forme et d'apparence et fournir de nouvelles façons de créer du contenu 3D réaliste. D'autre part, les techniques de modélisation et de simulation 3D en infographie peuvent prédire, apprendre et vérifier les propriétés et le comportement d'objets et de scènes réels analysés par des algorithmes de vision par ordinateur. La communauté visuelle et graphique pratique depuis longtemps une approche « d’analyse synthétique ».
Représentation uniforme de l'apparence et de la forme ? Le rendu basé sur l'image, dans lequel de nouvelles vues sont générées par l'apprentissage d'un ensemble d'images donné, peut être considéré comme une première tentative visant à combler le fossé entre la vision et le graphisme avec des principes parcimonieux et cohérents. En particulier, l'échantillonnage plénoptique montre que des images anti-aliasées (auto-cohérence) peuvent être obtenues avec le nombre minimum d'images requis (parcimonie).
On pourrait s'attendre à ce que les principes fondamentaux de l'intelligence aient un impact significatif sur la conception du cerveau. Les principes de parcimonie et d’autocohérence apportent un nouvel éclairage sur plusieurs observations expérimentales du système visuel des primates. Plus important encore, ils révèlent ce qu’il faut rechercher dans les expériences futures.
L'équipe des auteurs a démontré que la simple recherche de représentations internes parcimonieuses et prédictives est suffisante pour parvenir à une « auto-supervision », permettant aux structures d'apparaître automatiquement dans la représentation finale apprise grâce à une transcription compressée en boucle fermée.
Par exemple, la figure 9 montre que l'apprentissage non supervisé de la transcription de données distingue automatiquement les caractéristiques de différentes catégories, fournissant ainsi une explication des représentations sélectives de catégories observées dans le cerveau. Ces caractéristiques fournissent également une explication raisonnable aux observations généralisées de codage clairsemé et de codage sous-espace dans le cerveau des primates. En outre, outre la modélisation des données visuelles, des recherches récentes en neurosciences suggèrent que d’autres représentations structurées apparaissant dans le cerveau (telles que les « cellules de lieu ») pourraient également être le résultat d’un codage d’informations spatiales de la manière la plus compressée.
On peut dire que le principe de réduction maximale du taux de codage (MCR2) est similaire dans son esprit au « principe de minimisation de l'énergie libre » en sciences cognitives, qui tente de minimiser l'énergie bayésienne à travers le raisonnement qui fournit le cadre. Mais contrairement au concept général d’énergie libre, la réduction de taux est traitable par calcul et directement optimisable car elle peut être exprimée sous une forme fermée. De plus, l’interaction de ces deux principes suggère que l’apprentissage autonome du modèle (classe) correct devrait être réalisé par le biais d’un jeu de maximisation en boucle fermée de cette utilité, plutôt que par la seule minimisation. Par conséquent, ils pensent que le cadre de transcription compressé en boucle fermée offre une nouvelle perspective sur la manière dont l’inférence bayésienne peut être mise en œuvre dans la pratique.
Ce cadre est également considéré par eux comme illustrant l'architecture globale d'apprentissage utilisée par le cerveau, qui peut créer des segments de rétroaction en déployant des schémas d'optimisation sans avoir besoin d'apprendre de réseaux aléatoires par rétropropagation. De plus, il existe une partie générative complémentaire du cadre qui peut former un système de rétroaction en boucle fermée pour guider l'apprentissage.
Enfin, le cadre révèle le signal insaisissable « d'erreur de prédiction » recherché par de nombreux neuroscientifiques intéressés par les mécanismes cérébraux du « codage prédictif », un schéma informatique qui résonne avec la transcription compressée en boucle fermée : afin de permettre d'effectuer des calculs. Plus facile, la différence entre les observations entrantes et générées doit être mesurée au stade final de la représentation.
Les travaux de Ma Yi et al estiment que la transcription compressée en boucle fermée est plus maniable et évolutive sur le plan informatique que le cadre proposé par Hinton et al. De plus, l'apprentissage récurrent de mappages de codage/décodage non linéaires (souvent manifestés sous forme de réseaux profonds) fournit essentiellement un pont important entre les données sensorielles brutes externes non organisées (telles que la vision, l'audition, etc.) et les représentations internes compactes et structurées.
Cependant, ils ont également souligné que ces deux principes n’expliquent pas nécessairement tous les aspects de l’intelligence. Les mécanismes informatiques qui sous-tendent l’émergence et le développement d’un raisonnement sémantique, symbolique ou logique de haut niveau restent insaisissables. À ce jour, il y a un débat sur la question de savoir si cette intelligence symbolique avancée peut résulter d’un apprentissage continu ou doit être codée en dur.
Pour les trois scientifiques, les représentations internes structurées telles que les sous-espaces - correspondant chacun à une catégorie (d'objet) discrète - sont une étape intermédiaire nécessaire à l'émergence de concepts sémantiques ou symboliques de haut niveau. D'autres relations statistiques, causales ou logiques entre de tels concepts discrets abstraits peuvent être davantage simplifiées et modélisées sous forme de graphiques compacts et structurés (par exemple clairsemés), chaque nœud représentant un sous-espace/une catégorie. Les graphiques peuvent être appris grâce à un codage automatique pour garantir leur auto-cohérence.
Ils spéculent que l'émergence et le développement d'une intelligence avancée (avec des connaissances symboliques partageables) ne sont possibles qu'au-dessus de représentations compactes et structurées apprises par des agents individuels. Par conséquent, ils ont suggéré que de nouveaux principes pour l’émergence d’une intelligence avancée (si l’intelligence avancée existe) devraient être explorés par le biais d’un échange efficace d’informations ou d’un transfert de connaissances entre systèmes intelligents.
De plus, les niveaux supérieurs d'intelligence devraient avoir deux choses en commun avec les deux principes que nous proposons dans cet article :
Ce n'est qu'avec l'interprétabilité et la calculabilité que nous pourrons faire progresser l'intelligence artificielle sans compter sur les méthodes actuelles coûteuses et chronophages d'essais et erreurs, et être capables de décrire les données et les ressources informatiques minimales requises pour les réaliser. tâches, plutôt que de simplement prôner une approche de force brute selon laquelle « plus c’est gros, mieux c’est ». La sagesse ne devrait pas être l’apanage des personnes les plus ingénieuses. Avec un ensemble de principes adéquats, chacun devrait être capable de concevoir et de construire la prochaine génération de systèmes intelligents, grands ou petits, dont l’autonomie, les capacités et l’efficacité pourront en fin de compte imiter, voire même. surpassent ceux des animaux et des êtres humains.
Lien papier :
https://arxiv.org/pdf/2207.04630.pdf
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Application de l'intelligence artificielle dans la vie
Application de l'intelligence artificielle dans la vie
 Quel est le concept de base de l'intelligence artificielle
Quel est le concept de base de l'intelligence artificielle
 que signifie l'interface USB
que signifie l'interface USB
 Quel logiciel est premier
Quel logiciel est premier
 API de Google Maps
API de Google Maps
 Quatre caractéristiques majeures de la blockchain
Quatre caractéristiques majeures de la blockchain
 Comment fermer le démarrage sécurisé
Comment fermer le démarrage sécurisé
 Le rôle du masque de sous-réseau
Le rôle du masque de sous-réseau








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



