


L'intelligence artificielle est devenue l'un des sujets les plus évoqués ces dernières années, et des services autrefois considérés comme de la pure science-fiction deviennent désormais une réalité grâce au développement des réseaux de neurones. Des agents conversationnels à la génération de contenu multimédia, l’intelligence artificielle change la façon dont nous interagissons avec la technologie. En particulier, les modèles d’apprentissage automatique (ML) ont fait des progrès significatifs dans le domaine du traitement du langage naturel (NLP). Une avancée majeure est l'introduction de « l'auto-attention » et de l'architecture Transformers pour le traitement des séquences, qui permet de résoudre plusieurs problèmes clés qui dominaient auparavant le domaine.
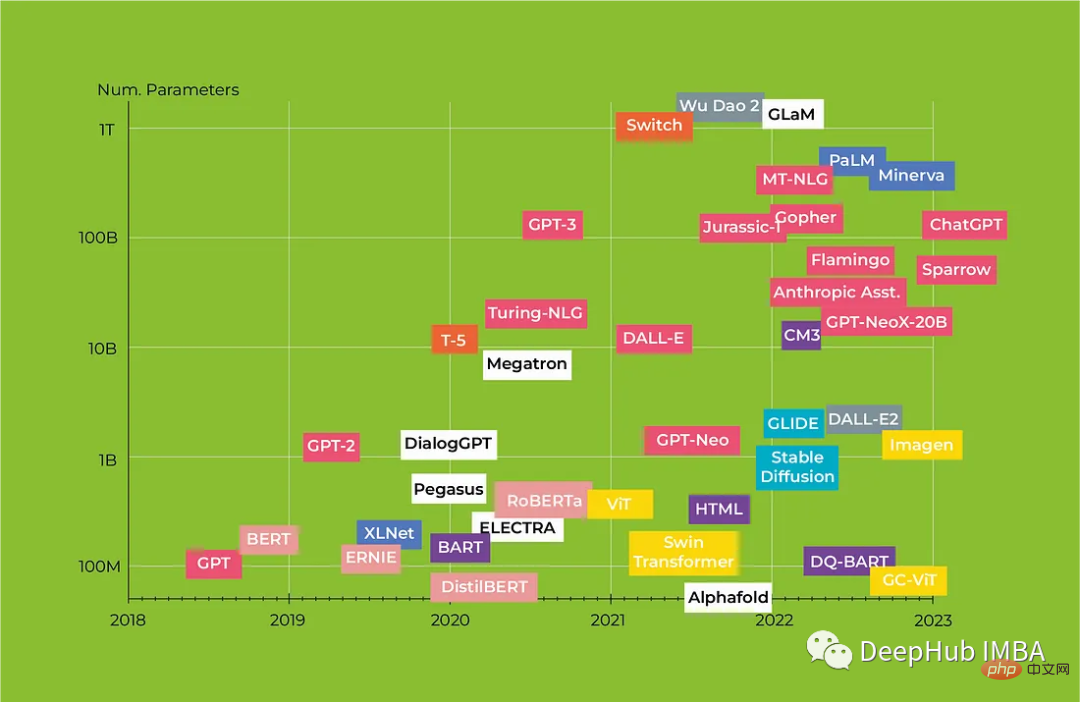
Dans cet article, nous examinerons l'architecture révolutionnaire des Transformers et comment elle change la PNL. Nous fournirons également un examen complet des modèles Transformers de BERT à Alpaca, en nous concentrant sur les principales caractéristiques de chaque modèle et. ses applications potentielles.
La première partie est un modèle basé sur l'encodeur Transformer, qui est utilisé pour la vectorisation, la classification, l'étiquetage de séquence, l'assurance qualité (question et réponse), le NER (reconnaissance d'entité nommée), etc.
Encodeur de transformateur, tokenisation de mots (vocabulaire 30K). L'intégration d'entrée se compose de trois vecteurs : un vecteur d'étiquette, un vecteur de position pouvant être entraîné et un vecteur de fragment (soit le premier texte, soit le deuxième texte). Les entrées du modèle sont l'intégration du jeton CLS, l'intégration du premier texte et l'intégration du deuxième texte.
BERT a deux tâches de formation : la modélisation du langage masqué (MLM) et la prédiction de la phrase suivante (NSP). En MLM, 15 % des tokens sont masqués, 80 % sont remplacés par des tokens MASK, 10 % sont remplacés par des tokens aléatoires et 10 % restent inchangés. Le modèle prédit les bons tokens, et la perte est calculée uniquement sur ces 15 % de tokens bloqués. Dans NSP, le modèle prédit si le deuxième texte suit le premier texte. Les prédictions sont faites sur le vecteur de sortie des jetons CLS.
Pour accélérer la formation, d'abord 90 % de la formation est effectuée sur une longueur de séquence de 128 jetons, puis les 10 % restants du temps sont consacrés à entraîner le modèle sur 512 jetons pour obtenir des intégrations de position plus efficaces.
Une version améliorée de BERT, il est uniquement formé sur MLM (car NSP est considéré comme moins utile), et la séquence de formation est plus longue (512 tokens). Grâce au masquage dynamique (différents jetons sont masqués lorsque les mêmes données sont à nouveau traitées), les hyperparamètres d'entraînement sont soigneusement choisis.
XLM a deux tâches de formation : MLM et traduction. La traduction est essentiellement la même que le MLM sur une paire de textes, mais les textes sont des traductions parallèles les uns des autres, avec des masques aléatoires et des langages de codage intégrant des segments.
4. Transformer-XL Carnegie Mellon University / 2019
Les textes longs sont divisés en segments et traités un segment à la fois. La sortie du segment précédent est mise en cache et lors du calcul de l'auto-attention dans le segment actuel, les clés et les valeurs sont calculées en fonction de la sortie du segment actuel et du segment précédent (juste concaténés ensemble). Le dégradé est également calculé uniquement dans le segment actuel.
Cette méthode ne fonctionne pas avec des positions absolues. Par conséquent, la formule de pondération d’attention est reparamétrée dans le modèle. Le vecteur de codage de position absolue est remplacé par une matrice fixe basée sur le sinus de la distance entre les positions des marqueurs et un vecteur entraînable commun à toutes les positions.
5. Université ERNIE Tsinghua, Huawei / 2019
Parce qu'il y a des problèmes dans le processus de formation BERT :
XLNet est basé sur Transformer-XL, à l'exception des tâches de modélisation de langage de remplacement (PLM), où il apprend à prédire les jetons dans des contextes courts au lieu d'utiliser directement MASK. Cela garantit que les dégradés sont calculés pour tous les marqueurs et élimine le besoin de marqueurs de masque spéciaux.
Les jetons dans le contexte sont brouillés (par exemple : le i-ème jeton peut être prédit en fonction des i-2 et i+1-ème jetons), mais leurs positions sont toujours connues. Cela n'est pas possible avec les codages de position actuels (y compris Transformer-XL). Lorsqu'il essaie de prédire la probabilité qu'un jeton fasse partie d'un contexte, le modèle ne doit pas connaître le jeton lui-même, mais doit connaître la position du jeton dans le contexte. Pour résoudre ce problème, ils ont divisé l'attention personnelle en deux flux :
Pendant le réglage fin, si vous ignorez le vecteur de requête, le modèle fonctionnera comme un Transformer-XL classique.
En pratique le modèle nécessite que le contexte soit suffisamment long pour que le modèle apprenne correctement. Il a appris sur la même quantité de données que RoBERTa avec des résultats similaires, mais en raison de la complexité de la mise en œuvre, le modèle n'est pas devenu aussi populaire que RoBERTa.
Simplifier BERT sans sacrifier la qualité:
Le modèle est formé au MLM et à la prédiction d'ordre de peine (SOP).
Une autre façon d'optimiser BERT est la distillation :
Modèle de vectorisation multilingue basé sur BERT. Il est entraîné sur MLM et TLM (20% des marqueurs sont masqués) puis affiné. Il prend en charge plus de 100 langues et contient 500 000 vocabulaires balisés.
Utiliser la méthode contradictoire générative pour accélérer la formation BERT :
Le nombre de les données de formation sont cohérentes avec RoBERTa ou XLNet sont les mêmes, et le modèle apprend plus rapidement que BERT, RoBERTa et ALBERT à un niveau de qualité similaire. Plus il est entraîné longtemps, plus il est performant.
Un autre modèle qui sépare le contenu et la position du vecteur marqueur en deux vecteurs distincts :
est utilisé
Le tokenizer utilisé est un BPE au niveau de l'octet (vocabulaire 50K) et n'utilise pas de sous-chaînes similaires telles que ("chien", "chien !", "chien".). La longueur maximale de la séquence est de 1 024. La sortie de la couche met en cache toutes les balises générées précédemment.
Pré-formation complète sur MLM (15% de tokens masqués), spans masqués par code (
Suppression des jetons
Il s'agit d'un modèle GPT-2 avec une architecture Sparse Transformer et une longueur de séquence accrue de 2048 jetons. Vous souvenez-vous encore de cette phrase : Ne demandez pas, demandez, c'est GPT3
6, mT5 Google / 2020 basé sur le modèle T5, avec une formation similaire, mais utilisant des données multilingues. Les activations ReLU ont été remplacées par GeGLU et le vocabulaire a été étendu à 250 000 jetons. 7, GLAM Google / 2021Ce modèle est conceptuellement similaire à Switch Transformer, mais se concentre davantage sur le travail en mode quelques prises plutôt que sur le réglage fin. Les modèles de différentes tailles utilisent 32 à 256 couches expertes, K=2. Utilisez le codage de position relative de Transformer-XL. Lors du traitement des jetons, moins de 10 % des paramètres réseau sont activés. 8, LaMDA Google / 2021Un modèle de type gpt. Le modèle est un modèle conversationnel pré-entraîné sur le LM causal et affiné sur les tâches de génération et discriminantes. Le modèle peut également faire des appels à des systèmes externes (recherche, traduction). 9. GPT-NeoX-20B EleutherAI / 2022Ce modèle est similaire au GPT-J et utilise également l'encodage de position de rotation. Les poids des modèles sont représentés par float16. La longueur maximale de la séquence est de 2 048. 10, BLOOM BigScience / 2022Il s'agit du plus grand modèle open source en 46 langages et 13 langages de programmation. Pour entraîner le modèle, un grand ensemble de données agrégées appelé ROOTS est utilisé, qui comprend environ 500 ensembles de données ouverts. 11, PaLM Google / 2022Il s'agit d'un grand modèle de décodeur multilingue, formé à l'aide d'Adafactor, désactivant l'abandon pendant la pré-formation et utilisant 0,1 lors du réglage fin. 12, LLaMA Meta/2023Un LM open source à grande échelle de type gpt pour la recherche scientifique, qui a été utilisé pour former plusieurs modèles d'instruction. Le modèle utilise le pré-LayerNorm, l'activation SwiGLU et l'intégration de la position RoPE. Parce qu'il est open source, c'est l'un des principaux modèles pour dépasser dans les virages. Modèles de guidage pour le texteCes captures de modèle sont utilisées pour corriger les sorties du modèle (par exemple RLHF) afin d'améliorer la qualité des réponses pendant le dialogue et la résolution de tâches. 1. InstructGPT OpenAI/2022Ce travail adapte GPT-3 pour suivre efficacement les instructions. Le modèle est affiné sur un ensemble de données composé d'indices et de réponses que les humains considèrent comme bonnes sur la base d'un ensemble de critères. Basé sur InstructGPT, OpenAI a créé un modèle que nous connaissons désormais sous le nom de ChatGPT. 2, Flan-T5 Google / 2022Modèle de guidage adapté au T5. Dans certaines tâches, le Flan-T5 11B a surpassé le PaLM 62B sans ce réglage fin. Ces modèles ont été publiés en open source. 3. Sparrow DeepMind / 2022Le modèle de base est obtenu en affinant Chinchilla sur des conversations sélectionnées de haute qualité, avec les premiers 80 % des couches gelées. Le modèle a ensuite été formé à l’aide d’une grande invite pour le guider tout au long de la conversation. Plusieurs modèles de récompense sont également formés sur Chinchilla. Le modèle peut accéder à un moteur de recherche et récupérer des extraits de 500 caractères maximum qui peuvent devenir des réponses. Lors de l'inférence, le modèle de récompense est utilisé pour classer les candidats. Les candidats sont soit générés par le modèle, soit obtenus à partir de la recherche, et le meilleur devient alors la réponse.Le modèle d'orientation de LLaMA ci-dessus. L'accent principal est mis sur le processus de création d'un ensemble de données à l'aide de GPT-3 :
Un total de 52K triples uniques ont été générés et affinés sur LLaMA 7B.
Il s'agit d'un réglage fin de LLaMA sur les données d'instruction, mais contrairement à Alpaca ci-dessus, il n'est pas seulement affiné sur GPT- 3, etc. Mise au point sur les données générées par les grands modèles. La composition de l'ensemble de données est la suivante :
4, Imagen Google / 2022
L'idée principale derrière Imagen est qu'augmenter la taille de l'encodeur de texte peut apporter plus d'avantages au modèle génératif que d'augmenter la taille du DM. CLIP a donc été remplacé par T5-XXL.
Modèles qui génèrent du texte à partir d'images
1、CoCa Google / 2022
L'image 288x288 est découpée en morceaux de 18x18 et l'encodeur la convertit en un vecteur + un vecteur de pool d'attention partagé basé sur tous ces vecteurs.
Les poids des deux pertes sont :
La similarité entre le vecteur attention pool de l'image et le vecteur tag CLS du texte de la description de l'image paire. Perte autorégressive de toute la sortie du décodeur (conditionnée à l'image).L'image est codée par ViT, le vecteur de sortie ainsi que les jetons de texte et les commandes sont introduits dans PaLM, et PaLM génère le texte de sortie.
PaLM-E est utilisé pour toutes les tâches, y compris le VQA, la détection d'objets et le fonctionnement du robot.
Il s'agit d'un modèle fermé avec peu de détails connus. Vraisemblablement, il dispose d’un décodeur avec peu d’attention et d’entrées multimodales. Il utilise un entraînement autorégressif et un réglage fin du RLHF avec des longueurs de séquence de 8K à 32K.
Il a été testé lors d'examens humains avec zéro et quelques échantillons et a atteint des niveaux semblables à ceux des humains. Il peut résoudre instantanément et étape par étape des problèmes basés sur des images (y compris des problèmes mathématiques), comprendre et interpréter des images, et analyser et générer du code. Convient également à différentes langues, y compris les langues minoritaires.
Ce qui suit est une brève conclusion. Ils peuvent être incomplets ou simplement incorrects et sont fournis à titre indicatif uniquement.
Après que les cartes graphiques automatiques ne peuvent plus être exploitées, divers modèles à grande échelle ont envahi et la base des modèles s'est élargie, mais la simple augmentation des couches et la croissance des ensembles de données ont été remplacées par diverses technologies meilleures qui permettent améliorations de la qualité (utilisation de données et d'outils externes, structures de réseau améliorées et nouvelles techniques de réglage fin). Mais un nombre croissant de travaux montrent que la qualité des données de formation est plus importante que la quantité : une sélection et une formation correctes des ensembles de données peuvent réduire le temps de formation et améliorer la qualité des résultats.
OpenAI devient désormais fermé, ils ont essayé de ne pas publier les poids de GPT-2 mais ont échoué. Mais GPT4 est une boîte noire. La tendance des derniers mois à améliorer et à optimiser le coût de réglage fin et la vitesse d'inférence des modèles open source a largement réduit la valeur des grands modèles privés, car les produits open source rattrapent également rapidement le retard. des géants en qualité , ce qui permet à nouveau de dépasser dans les virages.
Le résumé des modèles open source finaux est le suivant :
Ce qui précède est à titre de référence uniquement ;
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



