


La « mutation » rapide des grands modèles de langage a donné à la société humaine une direction de plus en plus science-fiction. Après avoir éclairé cet arbre technologique, la réalité de "Terminator" semble se rapprocher de plus en plus de nous.
Il y a quelques jours, Microsoft vient d'annoncer un framework expérimental pouvant utiliser ChatGPT pour contrôler des robots et des drones.
Bien sûr, Google n'est pas loin derrière. Lundi, une équipe de Google et de l'Université technique de Berlin a lancé le plus grand modèle de langage visuel de l'histoire - PaLM-E. .

Adresse papier : https://arxiv.org /abs/2303.03378
En tant que modèle de langage visuel incarné (VLM) multimodal, PaLM-E peut non seulement comprendre des images, générer du langage, et peut même combiner les deux pour traiter des instructions robotiques complexes.
De plus, grâce à la combinaison du modèle de langage PaLM-540B et du modèle de transformateur visuel ViT-22B, le nombre final de paramètres de PaLM-E est aussi élevé comme 562 milliards.

PaLM-E, le nom complet est Pathways Language Model with Embodied, est un modèle de langage visuel incarné.
Sa puissance réside dans sa capacité à utiliser des données visuelles pour améliorer ses capacités de traitement du langage. Lorsque nous formons le plus grand modèle de langage visuel, que se passe-t-il lorsque vous le combinez avec un robot ? Le résultat est PaLM-E, un langage visuel généraliste incarné, à usage général, de 562 milliards de paramètres, couvrant la robotique, la vision et le langage. Introduction, PaLM-E est un LLM uniquement par décodeur, capable de générer des complétions de texte de manière autorégressive étant donné un préfixe ou une invite.
Ses données d'entraînement sont des phrases multimodales contenant une estimation visuelle et continue de l'état et un encodage de saisie de texte.

On peut dire que PaLM-E fait preuve d'une flexibilité et d'une adaptabilité sans précédent et représente un grand pas en avant, notamment dans le domaine de l'interaction homme-machine.
Plus important encore, les chercheurs ont démontré qu'en s'entraînant sur différentes combinaisons de tâches hybrides de plusieurs robots et d'un langage visuel général, il est possible de provoquer un transfert du langage visuel vers plusieurs les méthodes de prise de décision incarnée permettent aux robots d’utiliser efficacement les données lors de la planification des tâches.
De plus, PaLM-E est particulièrement remarquable en ce sens, Posséder une forte capacités de migration positives.
PaLM-E formé dans différents domaines, y compris les tâches générales de langage de vision à l'échelle d'Internet, atteint des performances considérablement améliorées par rapport aux modèles de robots effectuant des tâches uniques.
Plus le modèle de langage est grand, plus la capacité linguistique est maintenue pendant l'entraînement au langage visuel et aux tâches robotiques.
Du point de vue de l'échelle du modèle, PaLM-E avec 562 milliards de paramètres conserve presque toutes ses capacités linguistiques.
Bien qu'il ait été formé uniquement sur une seule image, PaLM-E montre des capacités exceptionnelles dans des tâches telles que le raisonnement en chaîne de pensée multimodale et le raisonnement multi-images.
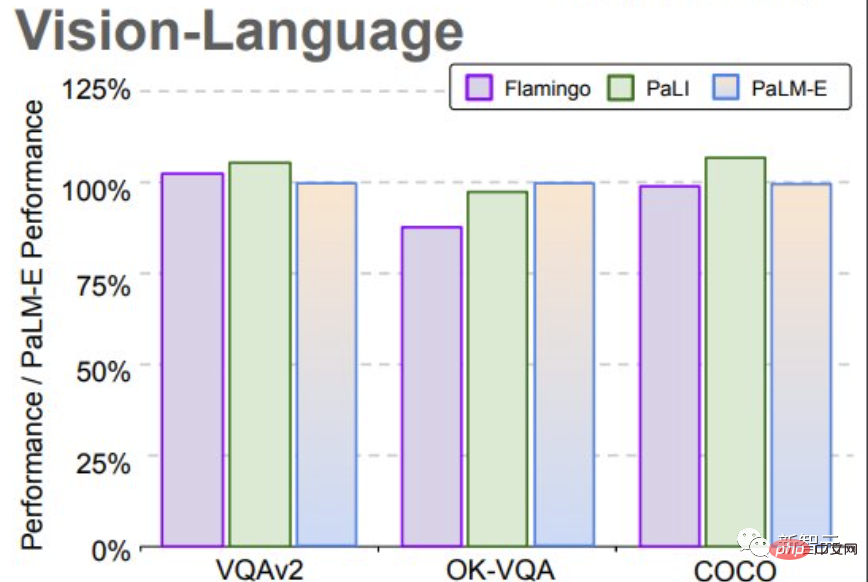
PaLM-E atteint un nouveau SOTA sur le benchmark OK-VQA.
Dans le test, les chercheurs ont montré comment utiliser PaLM-E pour effectuer des tâches de planification et de longue durée sur deux entités différentes.
Il est à noter que tous ces résultats ont été obtenus en utilisant le même modèle entraîné sur les mêmes données.
Dans le passé, les robots avaient généralement besoin d'une assistance humaine pour accomplir des tâches de longue durée. Mais désormais, PaLM-E peut le faire grâce à un apprentissage indépendant.

Par exemple, des instructions telles que « Sortez les chips du tiroir » incluent plusieurs étapes de planification et un retour visuel de la caméra du robot.
PaLM-E, qui a été formé de bout en bout, peut planifier le robot directement à partir des pixels. Le modèle étant intégré dans une boucle de contrôle, le robot est résistant aux perturbations lors de la collecte des chips.
Humain : Apportez-moi des chips.
Robot : 1. Allez dans le tiroir 2. Ouvrez le tiroir du haut 3. Ramassez les chips vertes dans le tiroir du haut 4. Placez-le sur le comptoir.

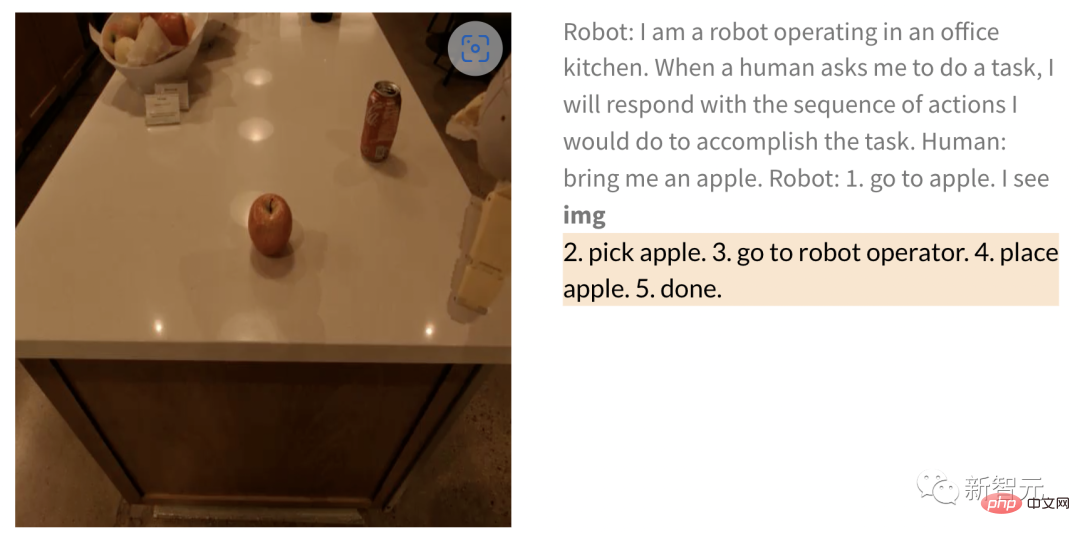
De même, lorsqu'il demande au robot de récupérer une pomme, après avoir donné l'image, le robot effectue la tâche comme suit -
Humain : apporte-moi une pomme.
Robot : 1. Marchez vers la pomme 2. Ramassez la pomme 3. Apportez-la à l'opérateur 4. Posez la pomme 5. Terminé.
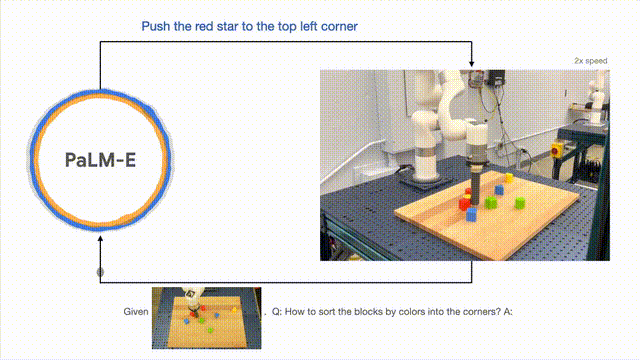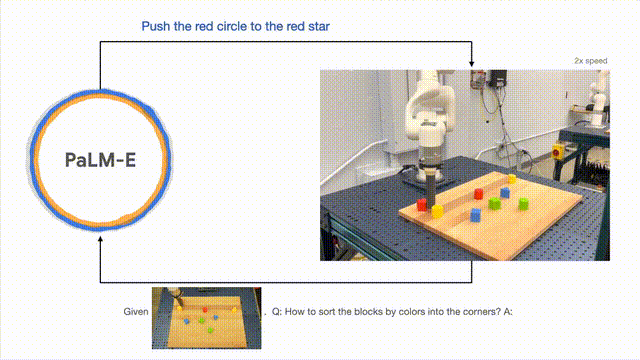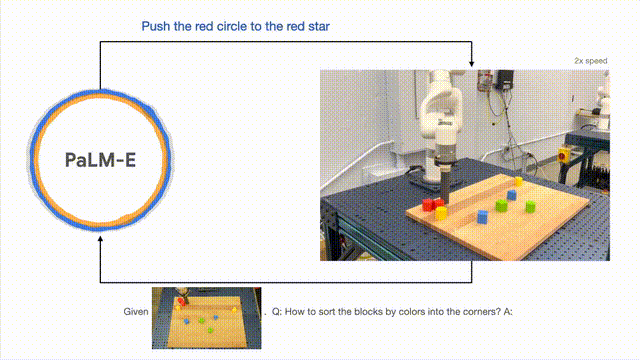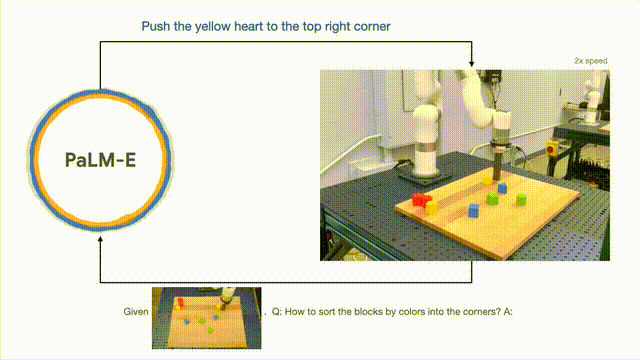
En plus d'effectuer des tâches à long terme, PaLM-E peut permettre au robot d'effectuer des tâches de planification, telles que l'organisation des blocs de construction.
Les chercheurs ont mené avec succès une planification en plusieurs étapes basée sur des entrées visuelles et verbales, combinées à un retour visuel à long terme, permettant au modèle de planifier avec succès une tâche à long terme consistant à « trier les blocs de construction en différentes catégories par couleur ». . coin".
Comme indiqué ci-dessous, en termes d'agencement et de combinaison, le robot se transforme en généraliste et trie les blocs de construction selon la couleur.
En termes de généralisation du modèle, le robot contrôlé par PaLM-E peut déplacer le bloc de construction rouge sur le côté de la tasse à café.
Il convient de mentionner que l'ensemble de données ne contient que trois démos avec des tasses à café, mais aucune d'entre elles n'inclut de blocs de construction rouges.

De même, bien que le modèle n'ait jamais vu de tortue auparavant, il peut toujours réussir à pousser le bloc vert vers la tortue

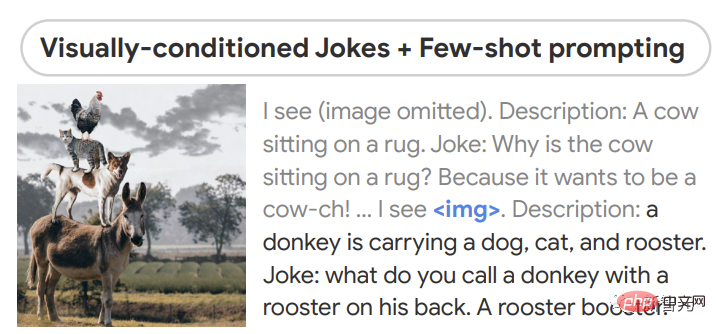
En termes d'inférence sans échantillon, PaLM - E peut raconter des blagues à partir d'images et a démontré des capacités telles que la perception, le dialogue basé sur la vision et la planification.
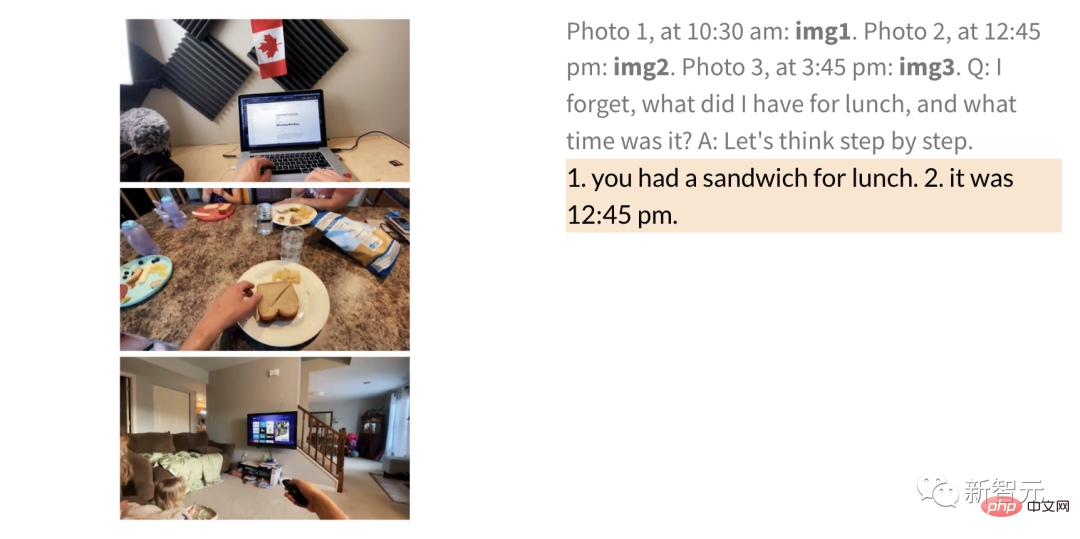
PaLM-E peut également comprendre la relation entre plusieurs images, par exemple l'endroit où se trouve l'image 1 (à gauche) dans l'image 2 (à droite).

De plus, PaLM-E peut également effectuer des opérations mathématiques à partir d'une image avec des chiffres manuscrits.
Par exemple, pour la photo manuscrite du menu du restaurant ci-dessous, combien coûtent 2 pizzas ? PaLM-E peut le calculer directement.
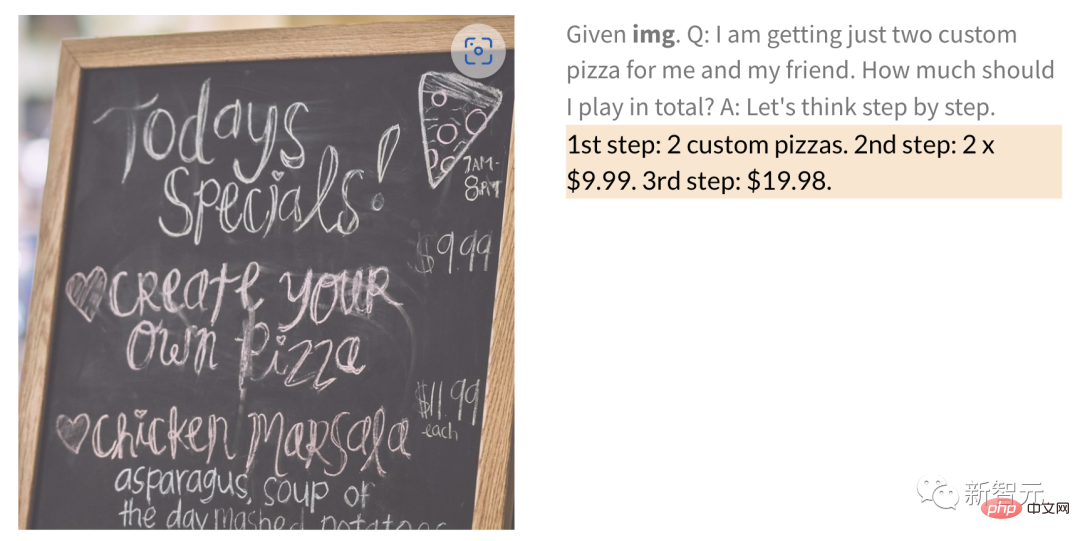
ainsi que l'assurance qualité générale, les annotations et d'autres tâches.
Enfin, les résultats de la recherche montrent également que le gel des modèles linguistiques est une voie réalisable vers des modèles multimodaux incarnés universels qui conservent pleinement leurs capacités linguistiques.
Mais en même temps, les chercheurs ont également découvert une voie alternative pour débloquer le modèle, c'est-à-dire qu'augmenter la taille du modèle de langage peut réduire considérablement les oublis catastrophiques.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



