


json est utilisé pour l'échange de données entre différents langages, par exemple entre C et Python, etc., qui peuvent être multilingues. Pickle ne peut être utilisé que pour l'échange de données entre python et python.
Nous appelons le processus d'objets (variables) de la mémoire vers des objets stockables ou transférables appelé sérialisation. Cela s'appelle décapage en Python et est également appelé sérialisation dans d'autres langages. le même sens. Après la sérialisation, le contenu sérialisé peut être écrit sur le disque ou transmis à d'autres machines via le réseau. À son tour, la relecture du contenu variable de l'objet sérialisé vers la mémoire est appelée désérialisation, c'est-à-dire décapage.
Si nous voulons transférer des objets entre différents langages de programmation, nous devons sérialiser l'objet dans un format standard, tel que XML, mais une meilleure façon est de le sérialiser en JSON, car JSON est représenté sous forme de chaîne et peut être dans toutes les langues. sont lus et peuvent être facilement stockés sur disque ou transférés sur le réseau. JSON est non seulement un format standard et plus rapide que XML, mais il peut également être lu directement dans les pages Web, ce qui est très pratique.
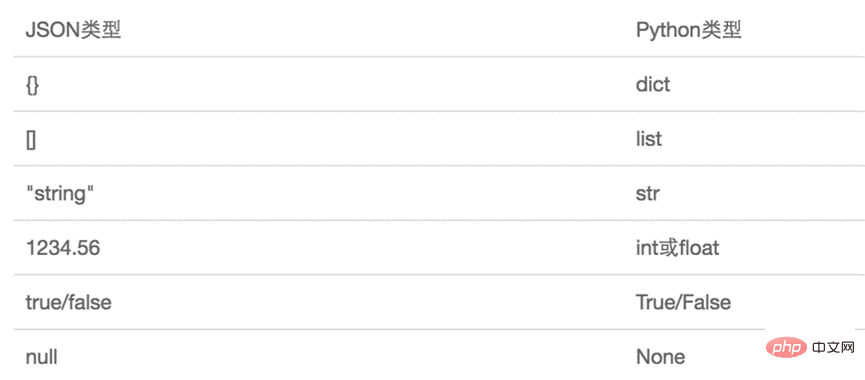
L'objet représenté par JSON est un objet de langage JavaScript standard. La correspondance entre JSON et les types de données intégrés de Python est la suivante :
Écrire et lire des données dans le fichier - dictionnaire
dic =' {‘string1':'hello'}' #写文件只能写入字符串 - 手动把字典变成字符串
f = open(‘hello', ‘w')
f.write(dic)f_read = open(‘hello', ‘r') data = f_read.read() #从文件中读出的都是字符串 data = eval(data) #提取出字符串中的字典 print(data[‘name'])
json implémente ce qui précède. fonctions - json peut être utilisé dans Il y a une différence entre la transmission de données dans n'importe quelle langue
dic = {‘string1':'hello'}
data = json.dumps(dic)
print(data)
print(type(data)) #dumps()会把我们的变量变成一个json字符串
f = open(“new_hello”, “w”)
f.write(data)chaîne json et la chaîne que nous ajoutons manuellement ’’ Elle suit la spécification de chaîne json, c'est-à-dire que la chaîne est entourée. guillemets doubles.
dumps transformera tout type de données que nous transmettons en une chaîne entre guillemets doubles
# {‘string1':'hello'} ---> “{“string1”:”hello”}”
# 8 ---> “8”
# ‘hello' ---> ““hello”” – 被json包装后的数据内部只能有双引号
#[1, 2] ---> “[1, 2]”Nous convertissons les données en une chaîne json lors du stockage ou de la transmission, qui peut être implémentée dans n'importe quelle langue
f_read = open(“new_hello”, “r”) data = json.loads(f_read.read()) #这个data直接就是字典类型 print(data) print(type(data))
json.dumps() # 把数据包装成json字符串 – 序列化 json.loads() # 从json字符串中提取出原来的数据 – 反序列化
Nous emballons une liste l = [1, 2, 3] dans une chaîne json en python et la stockons ou l'envoyons si nous utilisons l'analyse json en langage C, nous obtiendrons la valeur correspondante en langage C. La structure des données est extraite. sous forme de tableau buf[3] = {1, 2, 3}.
Cela ne signifie pas que les dumps et les chargements doivent être utilisés ensemble. Tant que la chaîne json est conforme à la spécification json, les charges peuvent être utilisées pour traiter et extraire la structure des données. Peu importe que les dumps soient utilisés ou non.
json.dump(data, f) #转换成json字符串并写入文件 #相当于 data = json.dumps(dic) + f.write(data) data = json.load(f) #先读取文件,再提取出数据 #相当于data = json.loads(f_read.read())
Exemple :
#----------------------------序列化
import json
dic={'name':'alvin','age':23,'sex':'male'}
print(type(dic))#<class 'dict'>
j=json.dumps(dic)
print(type(j))#<class 'str'>
f=open('序列化对象','w')
f.write(j) #-------------------等价于json.dump(dic,f)
f.close()#-----------------------------反序列化<br> import json f=open('序列化对象') data=json.loads(f.read())# 等价于data=json.load(f)
Remarque :
import json
#dct="{'1':111}"#json 不认单引号
#dct=str({"1":111})#报错,因为生成的数据还是单引号:{'one': 1}
dct='{"1":"111"}'
print(json.loads(dct))Peu importe la manière dont les données sont créées, tant qu'elles respectent le format json, elles peuvent être chargées en json. Il ne doit pas nécessairement s'agir de données de dump pour être chargées.
Le problème avec Pickle est le même que le problème de sérialisation spécifique à tous les autres langages de programmation, à savoir qu'il ne peut être utilisé qu'avec Python, et il est possible que différentes versions de Python soient incompatibles entre elles, Ainsi, seuls ceux qui ne sont pas importants peuvent être enregistrés avec Pickle. Cela n'a pas d'importance si les données ne peuvent pas être désérialisées avec succès.
##----------------------------序列化
import pickle
dic={'name':'alvin','age':23,'sex':'male'}
print(type(dic))#<class 'dict'>
j=pickle.dumps(dic)
print(type(j))#<class 'bytes'>
f=open('序列化对象_pickle','wb')#注意是w是写入str,wb是写入bytes,j是'bytes'
f.write(j) #-------------------等价于pickle.dump(dic,f)
f.close()#-------------------------反序列化 import pickle f=open('序列化对象_pickle','rb') data=pickle.loads(f.read())# 等价于data=pickle.load(f) print(data['age'])
L'utilisation de pickle et json est la même. Les noms scientifiques des deux sont appelés sérialisation, mais le résultat de la sérialisation json est une chaîne et le résultat de la sérialisation pickle est des octets. C'est-à-dire que la forme est différente, mais le contenu est le même. Cependant, ce qui est sérialisé par pickle est en octets, c'est-à-dire que les données à écrire dans le fichier sont en octets, donc lorsqu'il est ouvert, le fichier doit être ouvert. être ouvert sous forme de binaire wb. Le contenu écrit par pickle dans le fichier est illisible (caractères désordonnés, mais l'ordinateur peut le reconnaître), mais les données écrites par json sont lisibles. pickle prend en charge plus de types de données et pickle peut sérialiser des fonctions et des classes. Bien que json ne prenne pas en charge ces deux sérialisations, json est toujours utilisé dans la plupart des scénarios.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



