


Objectif de l'expérience
Soyez familier avec la structure de données de base de Python, ainsi que l'entrée et la sortie de fichiers.
Données expérimentales
Utilisez les données d'évaluation et les tâches d'évaluation de la xx conférence sur l'apprentissage automatique en XXXX. Les données comprennent des ensembles de formation et des ensembles de tests. La tâche d'évaluation consiste à prédire si la relation dans l'ensemble de test est positive ou. exemple négatif à travers les données de formation données, donnant 1 ou 0 à la fin de chaque échantillon.
Les données sont décrites comme suit : la première colonne est le type de relation, les deuxième et troisième colonnes sont les noms des personnes, la quatrième colonne est le titre et la cinquième colonne indique si la relation est un exemple positif ou négatif. . 1 est un exemple positif et 0 est un exemple négatif ; La sixième colonne représente l'ensemble d'entraînement.
| Événement | Personnage 1 | Personnage 2 | Titre | Relation (0 ou 1) | Ensemble d'entraînement |
|---|
L'ensemble de test est décrit dans la figure ci-dessous. Le format est fondamentalement similaire. à l'ensemble de formation, la seule différence est que peu importe qu'il s'agisse d'un exemple positif ou négatif dans la cinquième colonne.
| Relation | Personnage 1 | Personnage 2 | Événement |
|---|
Contenu expérimental
Traitez les données de l'ensemble d'entraînement, en ne laissant que les cinq premières colonnes, et le texte de sortie est nommé exp1_1.txt.
Catégorie 19 types de relations basées sur les données obtenues lors de la première étape. Le texte généré est stocké dans le dossier exp1_train Selon l'ordre dans lequel les catégories de relations apparaissent, les données de la première catégorie de relations sont stockées dans 1. txt. La deuxième catégorie de relation est stockée dans 2.txt jusqu'à 19.txt.
L'ensemble de test classe chaque échantillon en fonction de la catégorie de relation dans l'ordre des 19 catégories de l'ensemble de formation, c'est-à-dire que les données du même type de relation sont placées dans un fichier texte et que les fichiers de test de 19 catégories sont également généré. Le format reste le même que celui du fichier de test. Stockés dans le dossier exp1_test, les fichiers de chaque catégorie sont toujours nommés 1_test.txt, 2_test.txt... Parallèlement, la position de chaque échantillon dans le jeu de test d'origine est enregistrée, et correspond aux 19 fichiers de test un par un. Par exemple, la ligne de chaque échantillon du premier type de « rumeur de discorde » dans le texte original est enregistrée dans le fichier d'index et enregistrée dans les fichiers index1.txt, index2.txt...
Idées de résolution de problèmes
1 .La première question est de tester nos connaissances sur les opérations sur les fichiers et les listes. La principale difficulté est de lire le nouveau fichier après traitement selon les exigences, un fichier txt est généré. implémentation :
import os
# 创建一个列表用来存储新的内容
list = []
with open("task1.trainSentence.new", "r",encoding='xxx') as file_input: # 打开.new文件,xxx根据自己的编码格式填写
with open("exp1_1.txt", "w", encoding='xxx') as file_output: # 打开exp1_1.txt,xxx根据自己的编码格式填写文件如果没有就创建一个
for Line in file_input: # 遍历每一行的文件
arr = Line.split('\t') # 以\t为分隔符读取
if arr[0] not in list: # if the word is not in the list
list.append(arr[0]) # add the word to the list
file_output.write(arr[0]+"\t"+arr[1]+"\t"+arr[2]+"\t"+arr[3]+"\t"+arr[4]+"\n") # write the line to the file
file_input.close() #关闭.new文件
file_output.close() #关闭创建的txt文件2. La deuxième question examine toujours les opérations sur les fichiers. Sur la base des fichiers générés dans la question 1, les événements sont classés selon le même type d'événements. Il faut déterminer s'ils peuvent être regroupés efficacement en utilisant des conditions de boucle. Jetons un coup d'œil au code
spécifique Implémenter
import os
file_1 = open("exp1_1.txt", encoding='xxx') # 打开文件,xxx根据自己的编码格式填写
os.mkdir("exp1_train") # 创建目录
os.chdir("exp1_train") # 修改进程的工作目录(使用该目录)
a = file.readline() # 按行读取exp1_1.txt文件
arr = a.split("\t") # 按\t间隔符作为分割
b = 1 #设置分组文件的序列
file_2 = open("{}.txt".format(b), "w", encoding="xxx") # 打开文件,xxx根据自己的编码格式填写
for line in file_1: # 按行读取文件
arr_1 = line.split("\t") # 按\t间隔符作为分割
if arr[0] != arr_1[0]: # 如果读取文件的第一列内容与存入新文件的第一列类型不同
file_2.close() # 关掉该文件
b += 1 # 文件序列加一
f_2 = open("{}.txt".format(b), "w", encoding="xxx") # 创建新文件,以另一种类型分类,xxx根据自己的编码格式填写
arr = line.split("\t") # 按\t间隔符作为分割
f_2.write(arr[0]+"\t"+arr[1]+"\t"+arr[2]+"\t"+arr[3]+"t"+arr[4]+"\t""\n") # 将相同类型的文件写入
f_1.close() # 关闭题目一创建的exp1_1.txt文件
f_2.close() # 关闭创建的最后一个类型的文件3. Classer davantage les 19 catégories de l'ensemble d'entraînement en fonction de la relation entre les personnages. Nous pouvons parcourir les données à travers le dictionnaire, trouver la relation, mettre la. contenu avec la même relation dans un dossier, et créez-en un nouveau s'il est différent.
import os
with open("exp1_1.txt", encoding='xxx') as file_in1: # 打开文件,xxx根据自己的编码格式填写
i = 1 # 类型序列
arr2 = {} # 创建字典
for line in file_in1: # 按行遍历
arr3 = line[0:2] # 读取关系
if arr3 not in arr2.keys():
arr2[arr3] = i
i += 1 # 类型+1
file_in = open("task1.test.new") # 打开文件task1.test.new
os.mkdir("exp1_test") # 创建目录
os.chdir("exp1_test") # 修改进程的工作目录(使用该目录)
for line in file_in:
arr = line[0:2]
with open("{}_test.txt".format(arr2[arr]), "a", encoding='xxx') as file_out:
arr = line.split('\t')
file_out.write(line)
i = 1
file_in.seek(0)
os.mkdir("exp1_index")
os.chdir("exp1_index")
for line in file_in:
arr = line[0:2]
with open("index{}.txt".format(arr2[arr]), "a", encoding='xxx') as file_out:
arr = line.split('\t')
line = line[0:-1]
file_out.write(line + '\t' + "{}".format(i) + "\n")
i += 1Objectif de l'expérience
Soyez familier avec la structure de données de base de Python, ainsi que l'entrée et la sortie de fichiers.
Données expérimentales
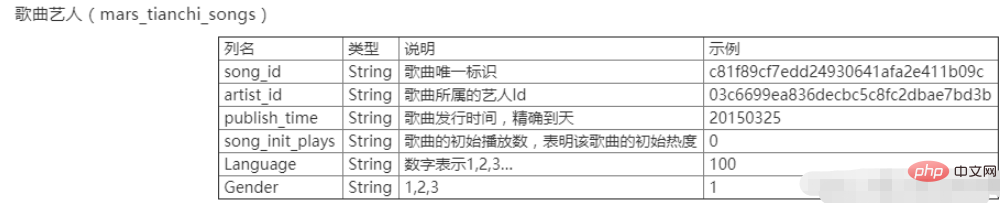
Le xx Concours Tianchi en xxxx, ce sont aussi les données du xième Big Data Challenge des universités chinoises. Les données comprennent deux tables, à savoir la table du comportement de l'utilisateur mars_tianchi_user_actions.csv et la table des artistes de la chanson mars_tianchi_songs.csv. Le concours ouvre des données échantillonnées sur les artistes de chansons, ainsi que des enregistrements de l'historique du comportement des utilisateurs liés à ces artistes dans un délai de 6 mois (20150301-20150831). Les candidats doivent prédire les données de lecture de l'artiste pour les 2 prochains mois, soit 60 jours (20150901-20151030).


Contenu expérimental
Traitez les données de l'artiste de la chanson mars_tianchi_songs et comptez le nombre d'artistes et le nombre de chansons pour chaque artiste. Le format du fichier de sortie est exp2_1.csv. La première colonne est l'identifiant de l'artiste et la deuxième colonne est le nombre de chansons de l'artiste. La dernière ligne affiche le nombre d'artistes.
Fusionnez la table de comportement de l'utilisateur et la table des artistes de la chanson en une seule grande table en utilisant la chanson song_id comme association. Les noms de chaque colonne sont les première à cinquième colonnes, qui correspondent aux noms de colonnes du tableau des comportements des utilisateurs, et les sixième à dixième colonnes sont les noms de colonnes des deuxième à sixième colonnes du tableau des artistes de la chanson. Le nom du fichier de sortie est exp2_2.csv.
Selon les statistiques des artistes, le volume de lecture de toutes les chansons de chaque artiste chaque jour, le fichier de sortie est exp2_3.csv et chaque colonne est nommée identifiant de l'artiste, date Ds et volume total de lecture de la chanson. Remarque : Seul le nombre d'écoutes de chansons est pris en compte ici, pas le nombre de téléchargements et de collections.
Idées de résolution de problèmes : (Utilisation de la bibliothèque pandas)
1.
(1) Utilisez .drop_duplicates() pour supprimer les valeurs en double
(2) Utilisez .loc[:,‘artist_id’] .value_counts() Découvrez le nombre de fois que le chanteur répète, c'est-à-dire le nombre de chansons pour chaque chanteur
(3) Utilisez .loc[:,‘songs_id’].value_counts() pour savoir si les chansons ne sont pas répétés
import pandas as pd data = pd.read_csv(r"C:\mars_tianchi_songs.csv") # 读取数据 Newdata = data.drop_duplicates(subset=['artist_id']) # 删除重复值 artist_sum = Newdata['artist_id'].count() #artistChongFu_count = data.duplicated(subset=['artist_id']).count() artistChongFu_count = data.loc[:,'artist_id'].value_counts() 重复次数,即每个歌手的歌曲数目 songChongFu_count = data.loc[:,'songs_id'].value_counts() # 没有重复(歌手) artistChongFu_count.loc['artist_sum'] = artist_sum # 没有重复(歌曲)artistChongFu_count.to_csv('exp2_1.csv') # 输出文件格式为exp2_1.csv
Utilisez merge() pour fusionner les deux tables
import pandas as pd import os data = pd.read_csv(r"C:\mars_tianchi_songs.csv") data_two = pd.read_csv(r"C:\mars_tianchi_user_actions.csv") num=pd.merge(data_two, data) num.to_csv('exp2_2.csv')
Utilisez groupby()[].sum() pour des ajouts répétés
import pandas as pd data =pd.read_csv('exp2_2.csv') DataCHongfu = data.groupby(['artist_id','Ds'])['gmt_create'].sum()#重复项相加DataCHongfu.to_csv('exp2_3.csv')
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



