


Après avoir enregistré avec succès le compte, nous pouvons trouver le lien du concours de survie au naufrage du Titanic dans le lien du concours, comme indiqué ci-dessous :
Après avoir accédé à la page du concours, vous pouvez voir une brève introduction au concurrence Et le code d'autres personnes et d'autres contenus, ici nous cliquons sur Données.
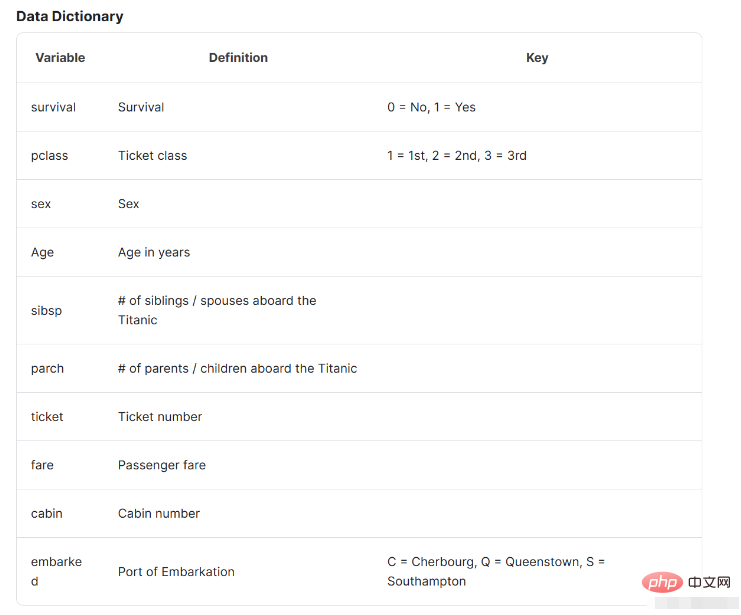
Faites attention à l'introduction des données ci-dessous. L'introduction des données ici nous aidera à comprendre la situation de base des données et ce qu'elles représentent.
Après avoir obtenu les données, nous ouvrons l'environnement de compilation et nous préparons à démarrer l'analyse des données. Dans cet article, j'utilise jupyter pour l'analyse des données. Bien sûr, vous pouvez choisir l'environnement de compilation auquel vous êtes habitué pour les travaux ultérieurs. .
Après avoir obtenu les données, nous écrivons d'abord le code pour les lire dans l'environnement de compilation. Le code est le suivant :
# 导入pandas import pandas as pd # 将训练集数据导入 data = pd.read_csv('train.csv')
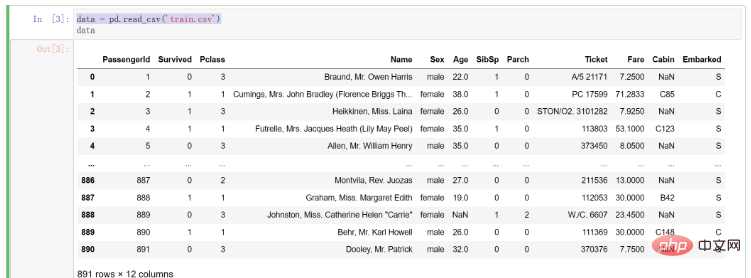
Les résultats après l'importation des données sont les suivants :
Après avoir obtenu les données, nous devons effectuer une observation préliminaire et un nettoyage des données. Nous présentons ici les Principes 4C de nettoyage des données proposés par les patrons de Kaggle, qui sont :
Correction : Comme son nom l'indique, la correction des données consiste à traiter les valeurs aberrantes dans les données. Par exemple, s’il existe plus de 100 données d’âge, il doit s’agir d’une valeur anormale. Nous vérifierons différentes données pour déceler les valeurs aberrantes afin de nous assurer qu'elles sont normales et valides. Cependant, nous devons être prudents lorsque nous modifions les données à partir des données d'origine, car la pierre angulaire de la construction d'un modèle précis sont les données, et les données déterminent la qualité du modèle
Complètement (Supplément) : Compléter les valeurs manquantes et étant donné que les valeurs aberrantes que nous avons trouvées étaient nécessaires. Bien que dans certains modèles, cela puisse nous aider automatiquement à gérer les valeurs manquantes sans traitement (comme les arbres de décision). Dans cette partie, nous choisissons généralement les valeurs manquantes avec une petite proportion de valeurs manquantes à supprimer. Pour les valeurs manquantes avec une proportion relativement importante ou une très grande proportion, nous envisagerons d'explorer une sorte de modèle dans l'original. données pour les remplir.
Création : L'ingénierie des fonctionnalités nous oblige à comprendre les fonctionnalités d'origine et à décider s'il convient d'extraire de nouvelles fonctionnalités. Par exemple, dans ce problème, nous pouvons considérer la segmentation par âge comme une nouvelle fonctionnalité. Bien entendu, le principe ici est que nous avons une compréhension approfondie du problème et que nous explorons si les fonctionnalités que nous extrayons peuvent réellement aider à la construction du modèle final. Cela nous oblige à vérifier à plusieurs reprises, à réfléchir à l'extraction de fonctionnalités et à trouver des fonctionnalités vraiment utiles pour différents problèmes.
Conversion : Lorsque nous ciblons certains formats de données, nous pouvons également avoir besoin d'effectuer une conversion de données. Ceci est bien sûr très important. Par exemple, certaines données de type chaîne doivent être converties sous forme numérique pour les représenter.
Dans cette étape, nous appellerons les fonctions de base des pandas pour faire des observations préliminaires sur les données. Nous appelons d'abord info() pour afficher le type et la situation de base des données. Le code est le suivant :
data.info()
Le résultat est le suivant :
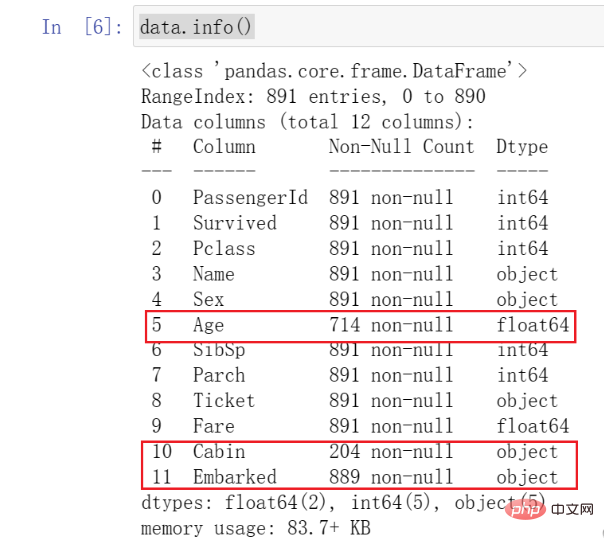
Lorsque nous appelons cette fonction, nous pouvons voir le type et la base. situation de toutes les données.
Vous devez faire attention aux données que j'ai marquées ici. Nous avons constaté que les données Âge sont beaucoup plus petites que les autres données, ce que nous appelons les valeurs manquantes. En même temps, vous pouvez constater que Cabine et Embarqué manquent également .
Ceux-ci nécessitent tous notre attention et un certain traitement à l’avenir. Par la suite, nous appelons la fonction décrire() pour observer davantage la distribution des données. Cette fonction peut nous aider à calculer la distribution et la moyenne de chaque colonne de données. Le code est le suivant :data.describe()
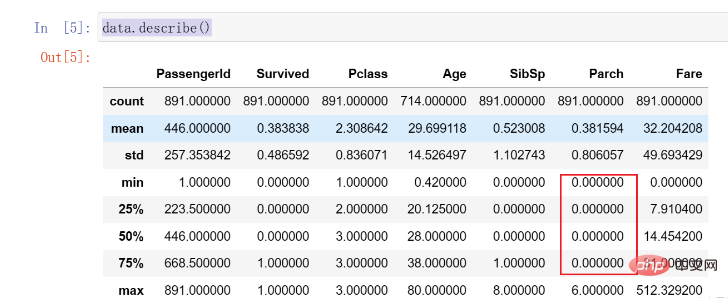
Parchdata sont 0, et il y a une distribution inégale évidente, qui devra peut-être être traitée plus tard .
Traitement des valeurs manquantes (achèvement)Dans la section précédente, nous avons constaté qu'il existe certaines conditions manquantes dans les données. Nous les visualisons d'abord, ce qui peut rendre notre observation des données plus intuitive. Ici, nous utilisons la bibliothèque Missingno pour visualiser les données manquantes, ce qui rend la visualisation des données manquantes plus intuitive.使用之前,请确保自己已经安装该库。
使用该库进行可视化的代码如下:
# 在数据中抽样100个单位 data_sample = data.sample(100) msno.matrix(data_sample)
结果如下:
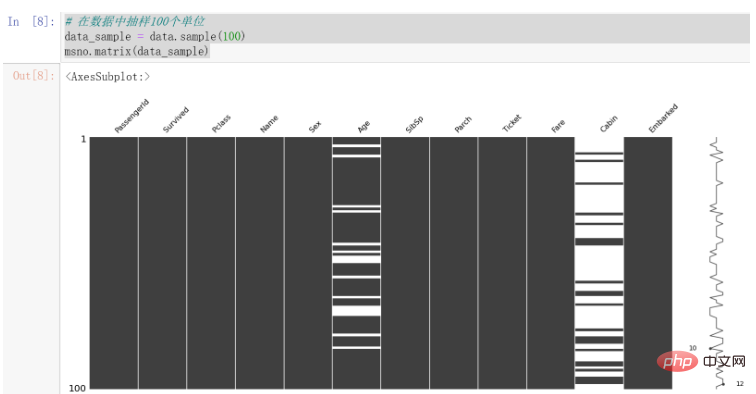
可以发现,Cabin的缺失值较为明显,Age也存在一些缺失值。
因为数据中每列代表的情况不尽相同,所以我们将针对数据进行不同的处理方法。
我们再通过代码来观察一下缺失的数据情况,代码与结果如下:
missing_data = data.isnull().sum() missing_data = missing_data [missing_data >0] missing_data
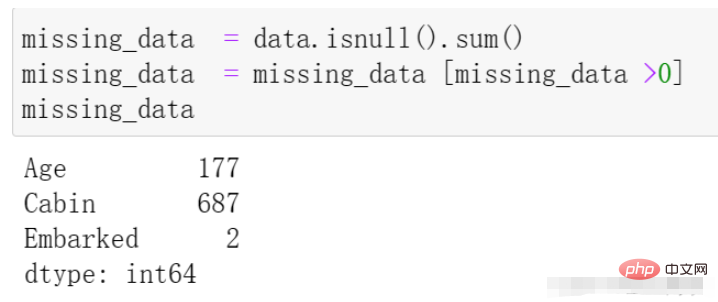
我们首先处理Embarked列,在上边的数据观察中发现其拥有两个缺失值,因为相对于全部的一千条数据来说其量级较小,所以我们在这里直接选择该列缺失的两条数据进行删除处理,代码如下:
# 在data中寻找Embarked的缺失值 找到后在原表中将其行删除 data.dropna(axis=0, how='any',subset=['Embarked'], inplace=True)
dropna 参数介绍:
axis: default 0指行,1为列
how: {‘any’, ‘all’}, default ‘any’指带缺失值的所有行;'all’指清除全是缺失值的
thresh: int,保留含有int个非空值的行
subset: 对特定的列进行缺失值删除处理
inplace: 这个很常见,True表示直接在原数据上更改
在上述观察中,我们发现Age存在一定的缺失情况,接下来我们对其进行处理。
我们由Kaggle中的数据介绍中了解到,其表示乘客的年龄,且缺失值相对来说较多,不能够直接采用删除的方式。
我们首先观察Age的分布情况,绘制年龄的直方图,代码如下:
data.hist(column='Age')
结果如下:
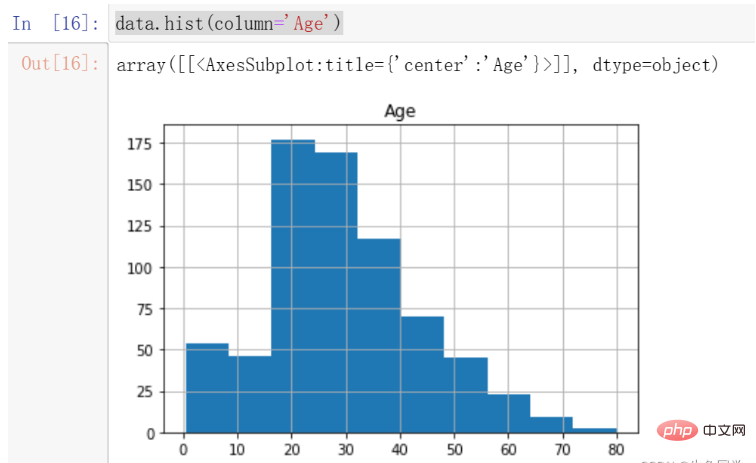
我们注意到,年龄的分布存在一定的偏态,这时候更适合采用中位数进行填充。
注意:偏态分布的大部分值都聚集在变量分布的一侧,中位数可以很好的表示中心趋势。
所以,我们对年龄的缺失值进行中位数的填充。代码如下:
data['Age'].fillna(data['Age'].median(), inplace=True)
至此,我们对于年龄的缺失值处理完毕。
我们首先看一下Cabin的数据解释:Cabin number(机舱号码)
对于该特征来说,仿佛对于最终的数据帮助不大。即使其对于最后的数据是非常重要的,由于其缺失值过多且不容易探寻其中的规律,我们还是选择对其做删除的处理。
代码如下:
# 这里我直接删除了该列 del data['Cabin']
至此,所有数据的缺失值处理完毕。
在本例中,我们能够进行检测并处理的主要是Age特征,因为我们预先知道其大概的范围。在这里我们绘制箱线图观察其数据的异常情况决定是否需要进行处理,代码如下:
data['Age'].plot.box()
结果如下:
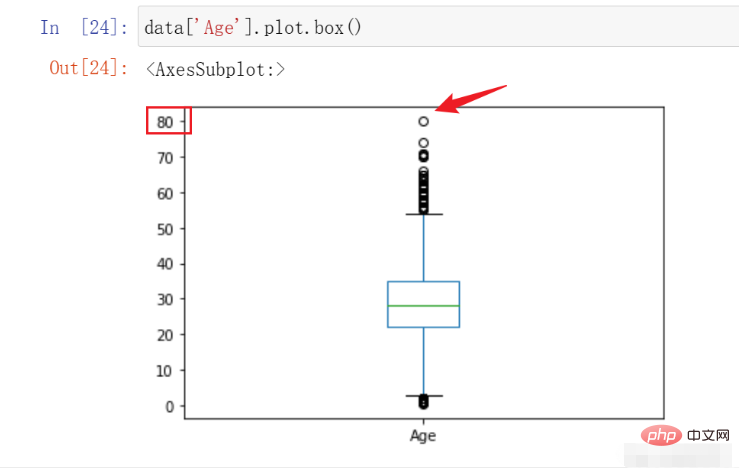
在这里,我们可以看到该数据的最高点在80,符合我们对于数据的预先认知,遂不进行处理。
在这部分中,要求我们对不同的特征有一定的了解以及认识,在这里我列出所有的特征含义。
特征名称含义survival是否存活,1表示存活,0表示没有pclass表示票的种类,分别为1,2,3等sex性别Age年龄sibsp在泰坦尼克号上的兄弟姐妹/配偶的数量parch在泰坦尼克号上的父母/子女人数ticket票号fare乘客票价cabin机舱号embarked上岸港口 ,C = Cherbourg, Q = Queenstown, S = Southampton
在这里,我们提取两个特征,分别是乘客家庭规模,是否独自一人,并对票价以及年龄进行分段构造两个新的特征。
注意:针对不同的项目采取的特征提取工作并不相同,因为这需要根据具体的业务进行分析并提取。
我们首先针对家庭规模以及是否独自一人创建新的两个特征,代码如下:
data['FamilySize'] = data['SibSp'] + data['Parch'] + 1 data['IsAlone'] = 1 data['IsAlone'].loc[data['FamilySize'] > 1] = 0
然后,我们对年龄和票价进行分段,代码如下:
data['FareBin'] = pd.qcut(data['Fare'], 4) data['AgeBin'] = pd.cut(data['Age'].astype(int), 5)
这里简单介绍一下上述两个函数的区别与作用
qcut:根据传入的数值进行等频分箱,即每个箱子中含有的数的数量是相同的。
cut:根据传入的数值进行等距离分箱,即每个箱子的间距都是相同的。
特别的,在本节中特征工程的过程要根据实际业务进行不同的特征提取,这个过程需要我们对业务有足够的理解程度。几个好的特征对后续的模型精确程度有很大的积极影响。
某些特定的格式在很多模型中其实是不适用的,在本例中经过上述处理后的数据如下所示:
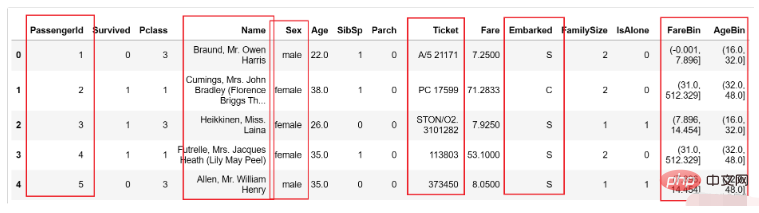
图中的性别等内容都为字符类型,这显然在模型中存在一定的不兼容情况,这就需要我们进行一定程度的格式转换。
在本部分中,我们要处理的有以下几个部分:
PassengerId:用户id的部分对后面的预测仿佛用处不大,我们对其进行删除。Name:这里的名字中有MR.MISS等信息,这可能对后续的模型有帮助,我们对其进行处理保留。Sex:需要进行编码使用,因为它是字符串类型。Ticket:仿佛用处不大,这里我们选择删除。Embarked:需要进行编码使用,因为它是字符串类型。FareBin:需要进行编码使用,因为它是一个范围。AgeBin:需要进行编码使用,因为它是一个范围。
我们首先对需要删除的两列进行删除的操作,代码如下:
del data['PassengerId'] del data['Ticket']
然后我们对Name进行处理,将其中的身份信息提取出来,代码如下:
data['Title'] = data['Name'].str.split(", ", expand=True)[1].str.split(".", expand=True)[0]结果如下:

最后,我们对需要编码的数据进行编码:
from sklearn.preprocessing import OneHotEncoder, LabelEncoder label = LabelEncoder() data['Sex_Code'] = label.fit_transform(data['Sex']) data['Embarked_Code'] = label.fit_transform(data['Embarked']) data['Title_Code'] = label.fit_transform(data['Title']) data['AgeBin_Code'] = label.fit_transform(data['AgeBin']) data['FareBin_Code'] = label.fit_transform(data['FareBin'])
编码后的结果如下:
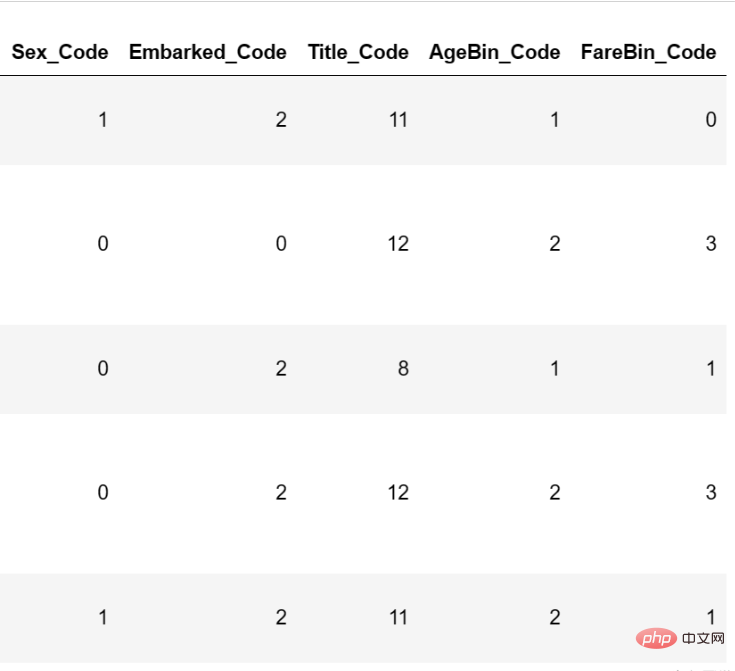
至此,数据格式转换已经完毕。
在本节中,我们将基于上述数据进行模型的构建,并且通过不同的评价指标进行构建。
在这里我将会使用基础的分类模型进行模型的构建,并挑选出初步表现最好的模型进行参数调节。代码如下:
# 处理不需要的数据列
data_x = data.copy()
del data_x['Survived']
del data_x['Name']
del data_x['Sex']
del data_x['FareBin']
del data_x['AgeBin']
del data_x['Title']
del data_x['Embarked']
# 构建y
data_y = data['Survived']
# 导入包
from sklearn import svm, tree, linear_model, neighbors, naive_bayes, ensemble, discriminant_analysis, gaussian_process
from sklearn.model_selection import cross_val_score
# 定义常用的几种分类模型
MLA = {
#随机森林
'随机森林':ensemble.RandomForestClassifier(),
#逻辑回归
'逻辑回归':linear_model.LogisticRegressionCV(max_iter=3000),
#SVM
'SVM':svm.SVC(probability=True),
#树模型
'树模型':tree.DecisionTreeClassifier(),
}
# 进行5折交叉验证并选择f1作为评价指标
for model_name in MLA:
scores = cross_val_score(MLA[model_name], X=data_x, y=data_y, verbose=0, cv = 5, scoring='f1')
print(f'{model_name}:',scores.mean())结果如下:

我们可以看到,目前随机森林的效果最好,所以我们选择随机森林进行参数调节。
在这里我们选择使用网格调参的方式进行参数调节,代码如下:
from sklearn.model_selection import GridSearchCV
n_estimators = [3,5,10,15,20,40, 55]
max_depth = [10,100,1000]
parameters = { 'n_estimators': n_estimators, 'max_depth': max_depth}
model = ensemble.RandomForestClassifier()
clf = GridSearchCV(model, parameters, cv=5)
clf = clf.fit(data_x, data_y)
clf.best_estimator_结果如下:

在这里,我们选择了几个简单的参数进行调节,可以根据自己的实际情况对不同的参数进行调节。我们再进行一次交叉验证求平均值看一下效果,结果如下:

可以看到与刚才的效果相比有一些提升。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



