


J'aime beaucoup ce que certains internautes ont dit :
"Cet enfant n'est vraiment pas bon, prenons-en un autre."
Google a vraiment fait ça.
Après sept ans de développement, TensorFlow a finalement été vaincu par PyTorch de Meta, dans une certaine mesure.
Voyant que quelque chose n'allait pas, Google en a rapidement demandé un autre : "JAX", un tout nouveau framework d'apprentissage automatique.

Vous connaissez tous le récemment très populaire DALL·E Mini. Son modèle est programmé sur la base de JAX, profitant ainsi pleinement des avantages apportés par Google TPU.
En 2015, TensorFlow, le framework d'apprentissage automatique développé par Google, est sorti.
A cette époque, TensorFlow n'était qu'un petit projet de Google Brain.
Personne ne s'attendait à ce que TensorFlow devienne très populaire dès sa sortie.
De grandes entreprises comme Uber et Airbnb l'utilisent, et des agences nationales comme la NASA l'utilisent également. Et ils sont tous utilisés sur leurs projets les plus complexes.
En novembre 2020, TensorFlow avait été téléchargé 160 millions de fois.
Cependant, Google ne semble pas se soucier beaucoup des sentiments de tant d'utilisateurs.
L'interface étrange et les mises à jour fréquentes rendent TensorFlow de moins en moins convivial pour les utilisateurs et de plus en plus difficile à utiliser.
Même au sein de Google, ils sentent que ce cadre se dégrade.
En fait, il est impuissant pour Google de mettre à jour aussi fréquemment. Après tout, c'est le seul moyen de suivre l'itération rapide dans le domaine de l'apprentissage automatique.
En conséquence, de plus en plus de personnes ont rejoint le projet, provoquant une lente perte de concentration de toute l'équipe.
Et les points forts qui ont initialement fait de TensorFlow l'outil de choix ont été enfouis dans de nombreux facteurs et ne sont plus pris au sérieux.
Ce phénomène est décrit par Insider comme un « jeu du chat et de la souris ». L’entreprise est comme un chat et les nouveaux besoins qui émergent au fil des itérations constantes sont comme des souris. Les chats doivent toujours être alertes et prêts à se jeter sur les souris.

Ce dilemme est inévitable pour les entreprises qui sont les premières à pénétrer sur un certain marché.
Par exemple, en ce qui concerne les moteurs de recherche, Google n'est pas le premier. Google peut donc tirer les leçons des échecs de ses prédécesseurs (AltaVista, Yahoo, etc.) et les appliquer à son propre développement.
Malheureusement, lorsqu'il s'agit de TensorFlow, c'est Google qui est pris au piège.
C'est précisément pour les raisons ci-dessus que les développeurs qui travaillaient à l'origine pour Google ont progressivement perdu confiance en leur ancien employeur.
L'omniprésent TensorFlow dans le passé a progressivement décliné, perdant face à l'étoile montante de Meta, PyTorch.

En 2017, la version bêta de PyTorch était open source.
En 2018, le laboratoire de recherche sur l'intelligence artificielle de Facebook a publié une version complète de PyTorch.
Il convient de mentionner que PyTorch et TensorFlow sont tous deux développés sur la base de Python, tandis que Meta accorde plus d'attention au maintien de la communauté open source et investit même beaucoup de ressources.
De plus, Meta est attentif aux problèmes de Google et estime qu’il ne peut pas répéter les mêmes erreurs. Ils se concentrent sur un petit ensemble de fonctionnalités et en font le meilleur possible.
Meta ne suit pas les traces de Google. Ce framework, développé pour la première fois chez Facebook, est progressivement devenu une référence dans le secteur.
Un ingénieur de recherche dans une start-up d'apprentissage automatique a déclaré : "Nous utilisons essentiellement PyTorch. Sa communauté et son open source sont les meilleurs. Non seulement vous répondez aux questions, mais les exemples donnés sont également très pratiques."
Face à cette situation, les développeurs de Google, les experts en matériel informatique, les fournisseurs de cloud et toute personne liée au machine learning de Google ont tous dit la même chose lors d'entretiens. Ils estiment que TensorFlow a perdu le cœur des développeurs.
Après une série de luttes ouvertes et secrètes, Meta a finalement pris le dessus.
Certains experts affirment que la possibilité pour Google de continuer à diriger l'apprentissage automatique à l'avenir disparaît lentement.
PyTorch est progressivement devenu l'outil de choix des développeurs et chercheurs ordinaires.
À en juger par les données d'interaction fournies par Stack Overflow, il y a de plus en plus de questions sur PyTorch sur le forum des développeurs, tandis que les questions sur TensorFlow sont au point mort ces dernières années.
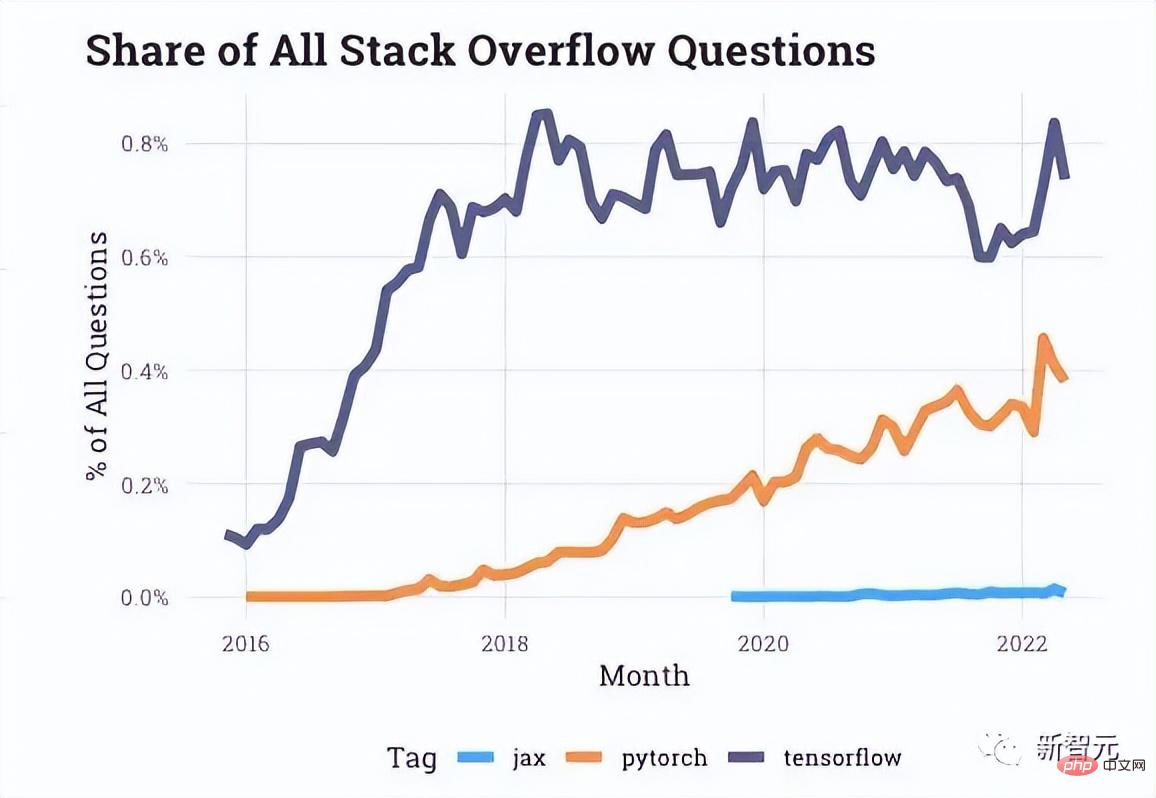
Même Uber et d'autres sociétés mentionnées au début de l'article se sont également tournées vers PyTorch.
Même chaque mise à jour ultérieure de PyTorch semble être une gifle face à TensorFlow.
Juste au moment où TensorFlow et PyTorch battaient leur plein, une « petite équipe de recherche de chevaux noirs » au sein de Google a commencé à travailler sur le développement d'un Un tout nouveau framework peut utiliser le TPU plus facilement.

En 2018, un article intitulé « Compilation de programmes d'apprentissage automatique via un traçage de haut niveau » a fait remonter le projet JAX à la surface. , Matthew James Johnson et Chris Leary.

De gauche à droite sont ces trois grands dieux
Ensuite, Adam Paszke, l'un des auteurs originaux de PyTorch, A également rejoint l'équipe JAX à temps plein début 2020.

JAX offre un moyen plus direct de traiter l'un des problèmes les plus complexes de l'apprentissage automatique : le problème de planification des processeurs multicœurs.
Selon la situation de l'application, JAX combinera automatiquement plusieurs jetons en un petit groupe, plutôt que d'en laisser un se battre seul.
L'avantage est que le plus grand nombre possible de TPU peuvent répondre en un instant, brûlant ainsi notre "univers alchimique".
Au final, par rapport au TensorFlow pléthorique, JAX a résolu un problème majeur au sein de Google : comment accéder rapidement au TPU.
Ce qui suit est une brève introduction à Autograd et XLA qui constituent JAX.
Autograd est principalement utilisé pour l'optimisation basée sur le dégradé et peut automatiquement différencier le code Python du code Numpy.
Il peut être utilisé pour gérer un sous-ensemble de Python, y compris les boucles, la récursivité et les fermetures, et il peut également effectuer des dérivées de dérivées.
De plus, Autograd prend en charge la rétropropagation des gradients, ce qui signifie qu'il peut obtenir efficacement le gradient d'une fonction à valeur scalaire par rapport à un paramètre à valeur de tableau, ainsi que la différenciation en mode direct, et les deux peuvent être combinés de quelque manière que ce soit.
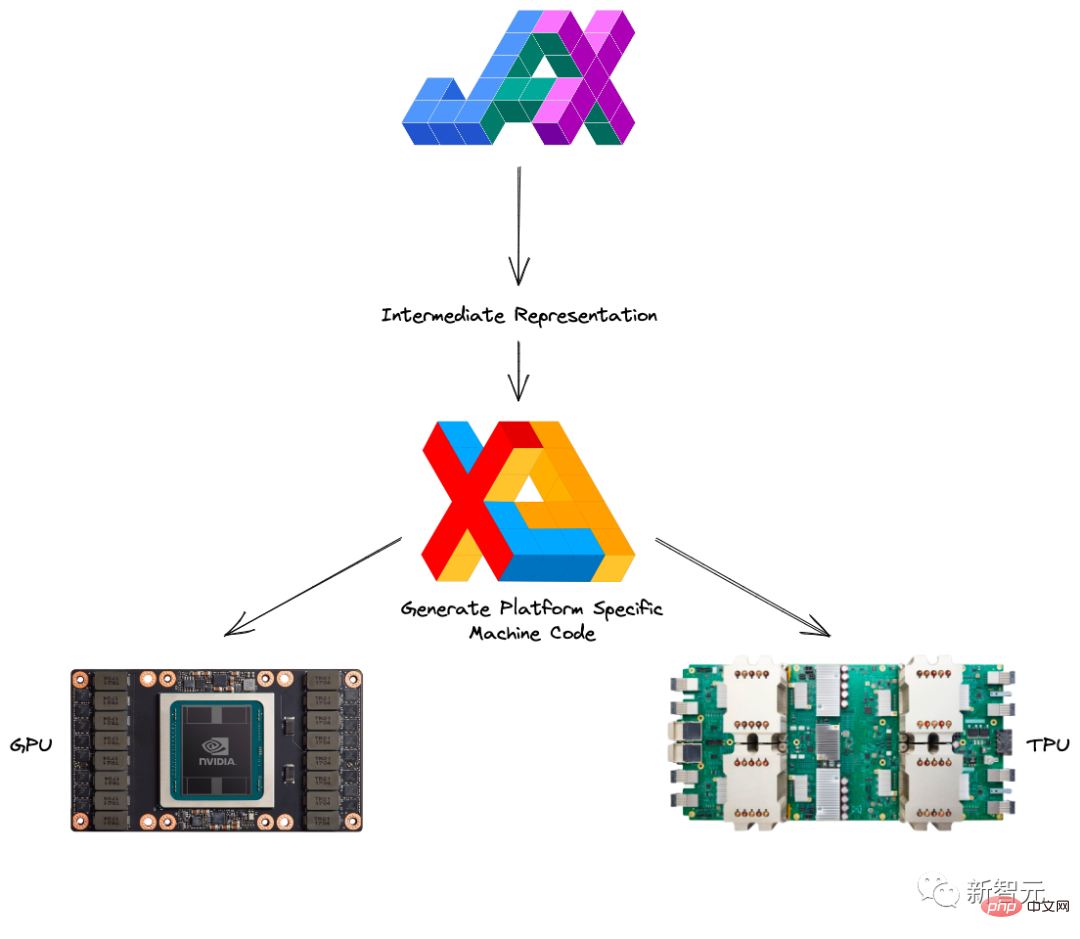
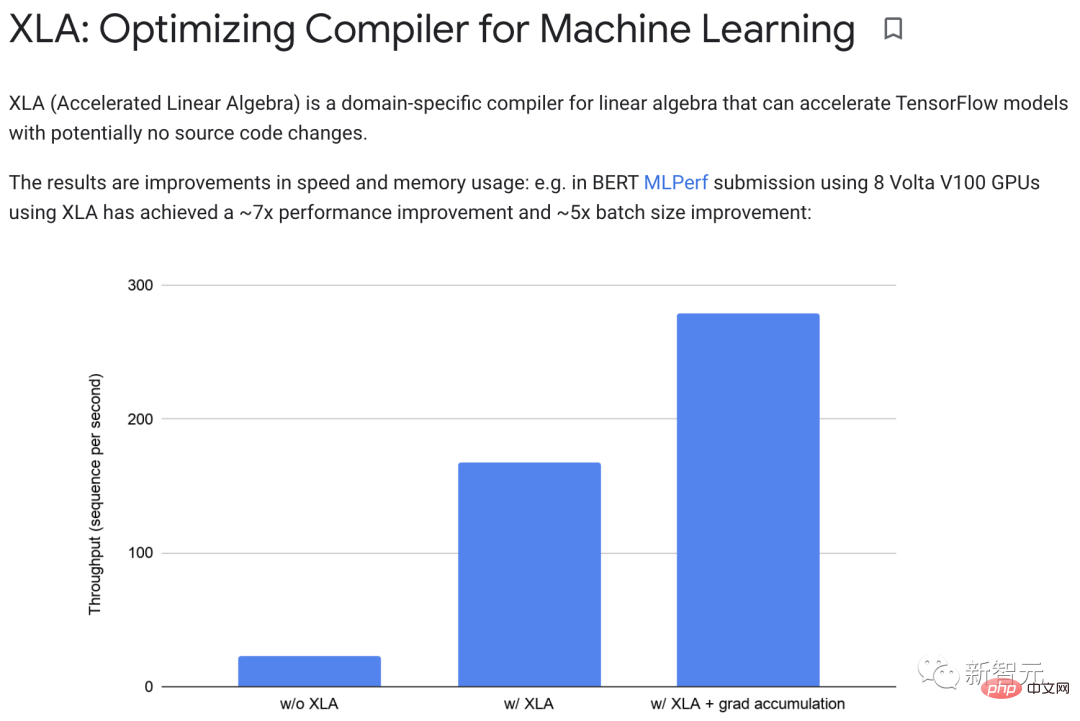
XLA (Accelerated Linear Algebra) peut accélérer les modèles TensorFlow sans changer le code source.
Lorsqu'un programme est en cours d'exécution, toutes les opérations sont effectuées individuellement par l'exécuteur. Chaque opération dispose d'une implémentation de noyau GPU précompilée sur laquelle les exécuteurs sont envoyés.
Par exemple :
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">def</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">model_fn</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">x</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">y</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">z</span>):<br><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">return</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">tf</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">reduce_sum</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">x</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">+</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">y</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">*</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">z</span>)
Lors de l'exécution sans XLA, cette partie démarre trois cœurs : un pour la multiplication, un pour l'addition et un pour l'addition.
Et XLA peut réaliser une optimisation en "fusionnant" l'addition, la multiplication et la soustraction en un seul cœur GPU.
Cette opération de fusion n'écrira pas les valeurs intermédiaires générées par la mémoire dans la mémoire y*z x+y*z, mais « diffusera » les résultats de ces calculs intermédiaires directement vers ; l'utilisateur, tout en les gardant entièrement dans le GPU.
En pratique, XLA peut améliorer les performances d'environ 7 fois et la taille des lots d'environ 5 fois.
De plus, XLA et Autograd peuvent être combinés de n'importe quelle manière, et vous pouvez même utiliser la méthode pmap pour programmer en utilisant plusieurs cœurs GPU ou TPU à la fois.
Si vous combinez JAX avec Autograd et Numpy, vous pouvez obtenir un système d'apprentissage automatique facile à programmer et hautes performances pour CPU, GPU et TPU.
Cette fois-ci, Google a évidemment retenu la leçon. En plus de déployer pleinement ses propres produits, il est également particulièrement actif dans la promotion de la construction de. l’écosystème open source.
En 2020, DeepMind est officiellement entré dans l'étreinte de JAX, ce qui a également annoncé la fin de Google lui-même. Depuis lors, diverses bibliothèques open source ont émergé sans cesse.


En regardant l'ensemble des "luttes internes", Jia Yangqing a déclaré qu'en train de critiquer TensorFlow , Le système d'IA pense que la recherche Pythonique est tout ce dont il a besoin.
Mais d'une part, Python pur ne peut pas réaliser une co-conception logicielle et matérielle efficace, d'autre part, le système distribué supérieur nécessite toujours une abstraction efficace.
Et JAX recherche un meilleur équilibre. Le pragmatisme de Google, prêt à se subvertir, mérite d'être appris.

causact L'auteur du package R et du manuel d'analyse bayésienne associé s'est dit heureux de voir Google passer de TF à JAX, une solution plus propre.

En tant que débutant, même si Jax peut apprendre des avantages de ses deux anciens prédécesseurs, PyTorch et TensorFlow , Mais parfois, commencer tard peut aussi entraîner des inconvénients.

Tout d'abord, JAX est encore trop "jeune". En tant que framework expérimental, il est loin d'atteindre les standards d'un produit Google mature.
En plus de divers bugs cachés, JAX dépend encore d'autres frameworks pour certains problèmes.
Pour le chargement et le prétraitement des données, vous devez utiliser TensorFlow ou PyTorch pour gérer la plupart des paramètres.
Évidemment, on est encore loin du cadre « one-stop » idéal.

Deuxièmement, JAX est hautement optimisé principalement pour le TPU, mais lorsqu'il s'agit de GPU et de CPU, c'est bien pire.
D'une part, le chaos organisationnel et stratégique de Google de 2018 à 2021 a entraîné un manque de fonds pour la recherche et le développement pour soutenir le GPU, et le traitement des problèmes associés n'était pas une priorité.
En même temps, ils sont probablement trop concentrés sur la création de leurs propres TPU pour obtenir une plus grande part du gâteau en matière d'accélération de l'IA. Naturellement, la coopération avec NVIDIA fait très défaut, sans parler de l'amélioration de la prise en charge des GPU. question de détail.
D'un autre côté, les propres recherches internes de Google sont sans aucun doute axées sur le TPU, ce qui fait perdre à Google une bonne boucle de rétroaction sur l'utilisation du GPU.
De plus, un temps de débogage plus long, la non-compatibilité avec Windows, le risque de ne pas suivre les effets secondaires, etc., tout cela augmente le seuil et la convivialité de Jax.
Maintenant, PyTorch a presque 6 ans, mais il n'a pas le déclin que TensorFlow a montré à l'époque.
Il semble que Jax ait encore un long chemin à parcourir s'il veut rattraper les retardataires.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



