


En 2021, Microsoft, OpenAI et Github ont créé conjointement un outil utile de complétion et de suggestion de code : Copilot.
Il recommandera des lignes de code dans l'éditeur de code du développeur. Par exemple, lorsque les développeurs saisissent du code dans des environnements de développement intégrés tels que Visual Studio Code, Neovim et JetBrains IDE, il peut recommander la ligne de code suivante. De plus, Copilot peut même fournir des conseils sur des méthodes complètes et des algorithmes complexes, ainsi qu'une assistance pour le code modèle et les tests unitaires.
Plus d'un an plus tard, cet outil est devenu un "partenaire de programmation" indissociable pour de nombreux programmeurs. Andrej Karpathy, ancien directeur de l'intelligence artificielle chez Tesla, a déclaré : « Copilot a considérablement accéléré ma vitesse de programmation, et il est difficile d'imaginer comment revenir à la « programmation manuelle ». Actuellement, j'apprends encore à l'utiliser, et il a programmé près de 80 % de mes La précision du code est proche de 80 % "
En plus de nous y habituer, nous avons également quelques questions sur Copilot, comme par exemple à quoi ressemble l'invite de Copilot ? Comment appelle-t-on le modèle ? Comment son taux de réussite des recommandations est-il mesuré ? Va-t-il collecter des extraits de code utilisateur et les envoyer à son propre serveur ? Le modèle derrière Copilot est-il un grand modèle ou un petit modèle ?
Pour répondre à ces questions, un chercheur de l'Université de l'Illinois à Urbana-Champaign a procédé à une ingénierie inverse de Copilot et a blogué sur ses observations.
Andrej Karpathy a recommandé ce blog dans son tweet.
Ce qui suit est le texte original du blog.
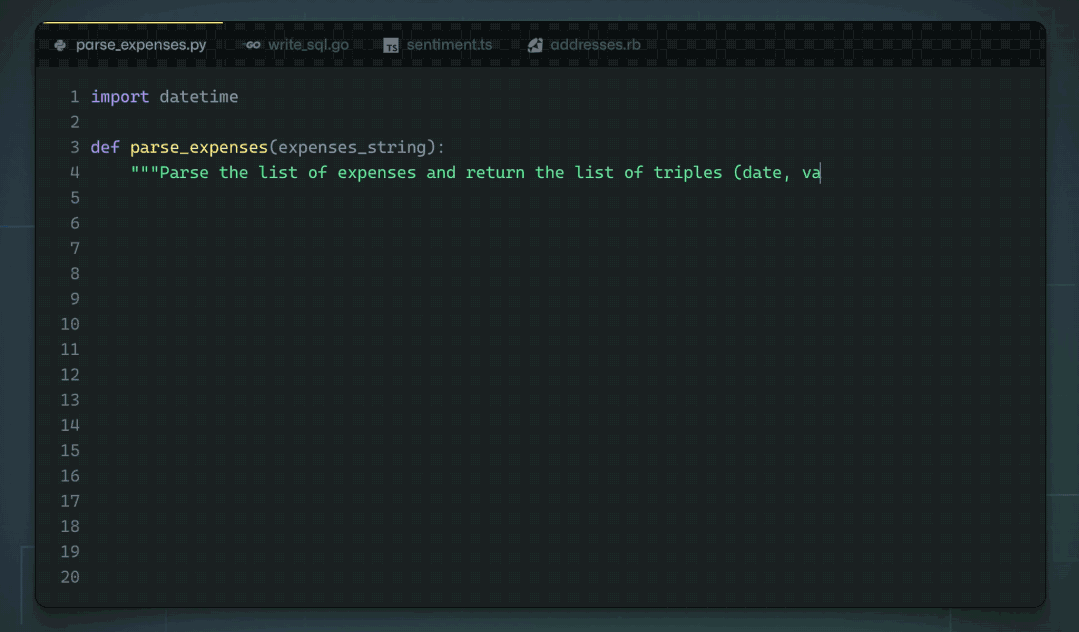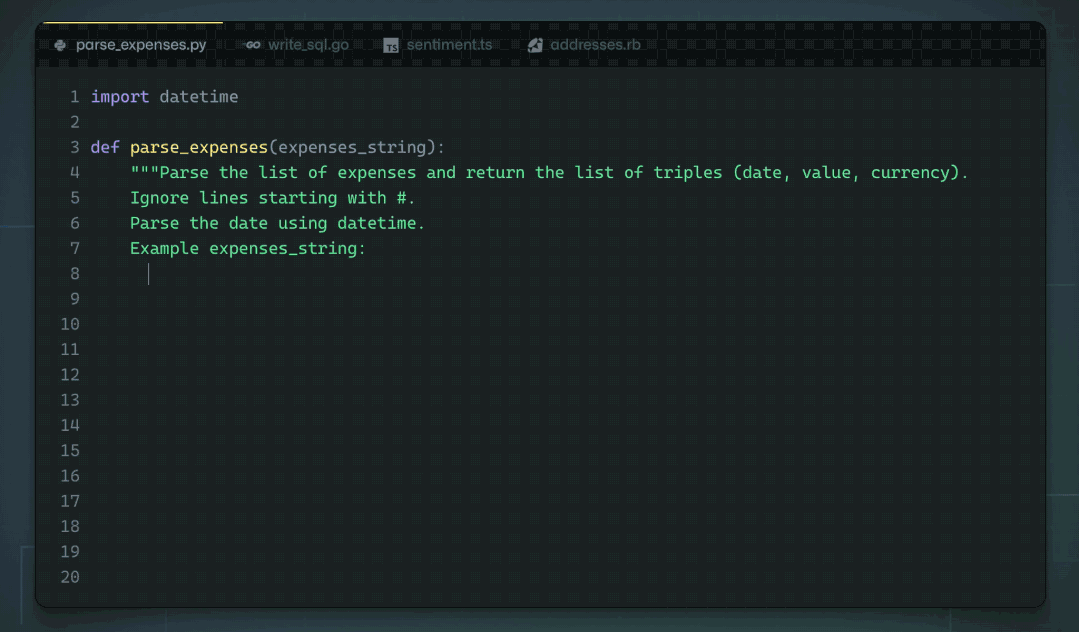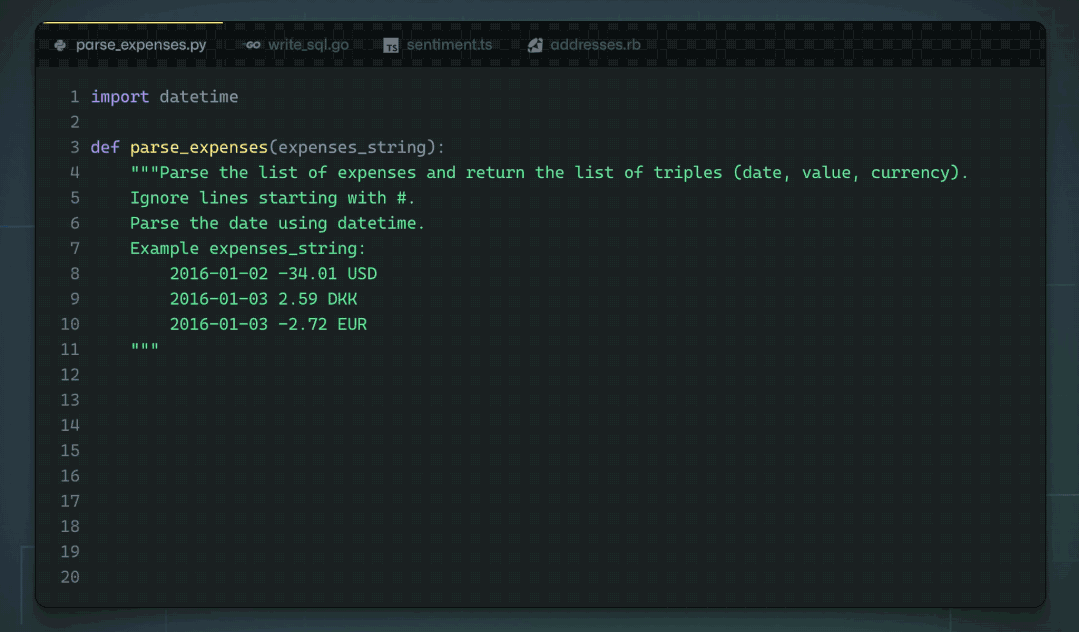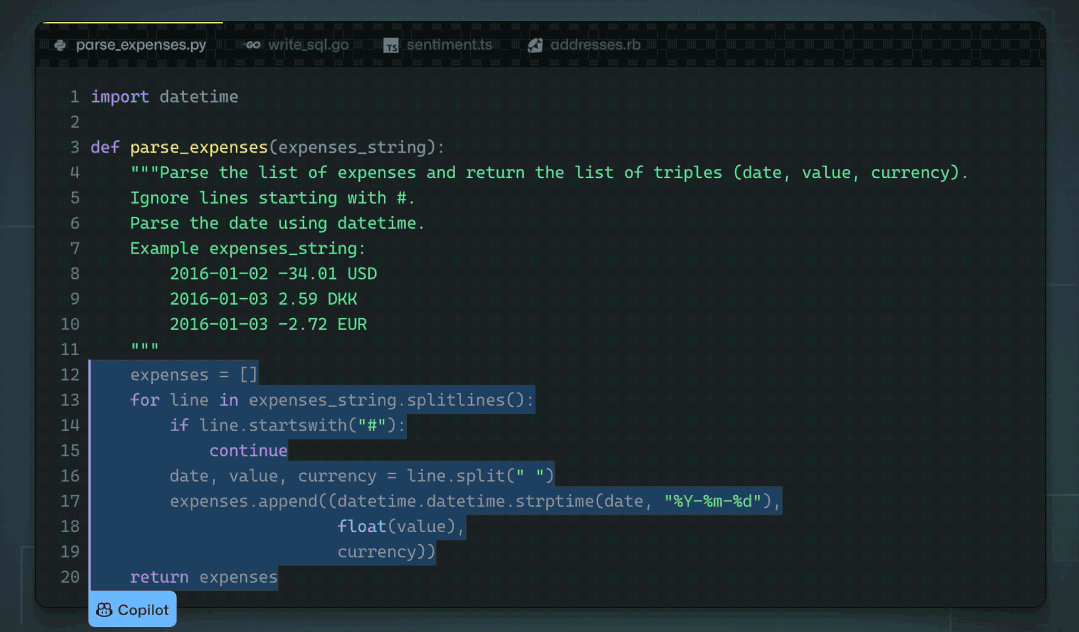
Github Copilot est très utile pour moi. Il lit souvent comme par magie dans mes pensées et fait des suggestions utiles. Ce qui m'a le plus surpris, c'est sa capacité à "deviner" correctement les fonctions/variables du code environnant (y compris le code d'autres fichiers). Cela ne se produit que lorsque l'extension Copilot envoie des informations précieuses du code environnant au modèle Codex. J'étais curieux de savoir comment cela fonctionnait, alors j'ai décidé de jeter un œil au code source.
Dans cet article, j'essaie de répondre à des questions spécifiques sur les composants internes de Copilot, tout en décrivant également quelques observations intéressantes que j'ai faites en parcourant le code.
Le code de ce projet peut être trouvé ici :
Adresse du code : https://github.com/thakkarparth007/copilot-explorer
L'article entier est structuré comme suit :

Il y a quelques mois, j'ai fait une "ingénierie inverse" très superficielle de l'extension Copilot, et depuis, j'ai envie d'approfondir. J'ai finalement réussi à le faire ces dernières semaines. Fondamentalement, en utilisant le fichier extension.js inclus avec Copilot, j'ai apporté quelques modifications manuelles mineures pour simplifier l'extraction automatique des modules, et j'ai écrit un tas de transformations AST pour "embellir" chaque module, en nommant les modules, en classant et annotant également manuellement. certaines des parties les plus intéressantes.
Vous pouvez explorer la base de code du copilote d'ingénierie inverse grâce aux outils que j'ai construits. Il n'est peut-être pas complet et raffiné, mais vous pouvez toujours l'utiliser pour explorer le code de Copilot.
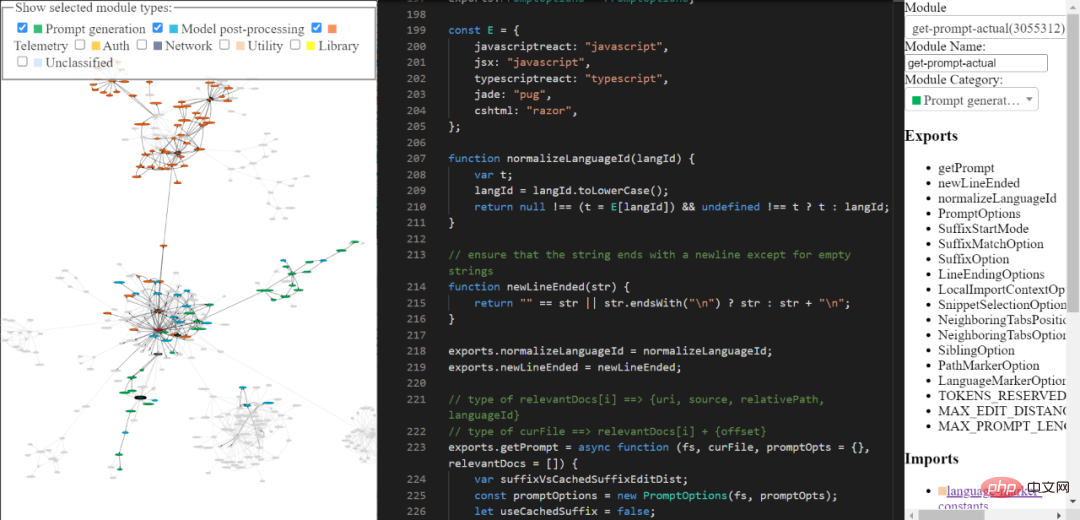
Lien de l'outil : https://thakkarparth007.github.io/copilot-explorer/
Github Copilot se compose des deux parties principales suivantes :
Maintenant que Codex a été formé sur une grande quantité de code Github public, il est logique qu'il puisse faire des suggestions utiles. Mais le Codex n'a aucun moyen de savoir quelles fonctionnalités existent dans votre projet actuel. Malgré cela, il peut toujours faire des suggestions concernant les fonctionnalités du projet.
Répondons à cette question en deux parties : regardons d'abord un exemple d'invite réel généré par copilot, puis nous verrons comment il est généré.
l'invite ressemble à
L'extension Copilot encode de nombreuses informations liées à votre projet dans l'invite. Copilot dispose d’un pipeline d’ingénierie rapide assez complexe. Voici un exemple d'invite :
{"prefix": "# Path: codeviz\app.pyn# Compare this snippet from codeviz\predictions.py:n# import jsonn# import sysn# import timen# from manifest import Manifestn# n# sys.path.append(__file__ + "/..")n# from common import module_codes, module_deps, module_categories, data_dir, cur_dirn# n# gold_annots = json.loads(open(data_dir / "gold_annotations.js").read().replace("let gold_annotations = ", ""))n# n# M = Manifest(n# client_name = "openai",n# client_connection = open(cur_dir / ".openai-api-key").read().strip(),n# cache_name = "sqlite",n# cache_connection = "codeviz_openai_cache.db",n# engine = "code-davinci-002",n# )n# n# def predict_with_retries(*args, **kwargs):n# for _ in range(5):n# try:n# return M.run(*args, **kwargs)n# except Exception as e:n# if "too many requests" in str(e).lower():n# print("Too many requests, waiting 30 seconds...")n# time.sleep(30)n# continuen# else:n# raise en# raise Exception("Too many retries")n# n# def collect_module_prediction_context(module_id):n# module_exports = module_deps[module_id]["exports"]n# module_exports = [m for m in module_exports if m != "default" and "complex-export" not in m]n# if len(module_exports) == 0:n# module_exports = ""n# else:n# module_exports = "It exports the following symbols: " + ", ".join(module_exports)n# n# # get module snippetn# module_code_snippet = module_codes[module_id]n# # snip to first 50 lines:n# module_code_snippet = module_code_snippet.split("\n")n# if len(module_code_snippet) > 50:n# module_code_snippet = "\n".join(module_code_snippet[:50]) + "\n..."n# else:n# module_code_snippet = "\n".join(module_code_snippet)n# n# return {"exports": module_exports, "snippet": module_code_snippet}n# n# #### Name prediction ####n# n# def _get_prompt_for_module_name_prediction(module_id):n# context = collect_module_prediction_context(module_id)n# module_exports = context["exports"]n# module_code_snippet = context["snippet"]n# n# prompt = f"""\n# Consider the code snippet of an unmodule named.n# nimport jsonnfrom flask import Flask, render_template, request, send_from_directorynfrom common import *nfrom predictions import predict_snippet_description, predict_module_namennapp = Flask(__name__)nn@app.route('/')ndef home():nreturn render_template('code-viz.html')nn@app.route('/data/<filename>')ndef get_data_files(filename):nreturn send_from_directory(data_dir, filename)nn@app.route('/api/describe_snippet', methods=['POST'])ndef describe_snippet():nmodule_id = request.json['module_id']nmodule_name = request.json['module_name']nsnippet = request.json['snippet']ndescription = predict_snippet_description(nmodule_id,nmodule_name,nsnippet,n)nreturn json.dumps({'description': description})nn# predict name of a module given its idn@app.route('/api/predict_module_name', methods=['POST'])ndef suggest_module_name():nmodule_id = request.json['module_id']nmodule_name = predict_module_name(module_id)n","suffix": "if __name__ == '__main__':rnapp.run(debug=True)","isFimEnabled": true,"promptElementRanges": [{ "kind": "PathMarker", "start": 0, "end": 23 },{ "kind": "SimilarFile", "start": 23, "end": 2219 },{ "kind": "BeforeCursor", "start": 2219, "end": 3142 }]}</filename>Comme vous pouvez le constater, l'invite ci-dessus comprend un préfixe et un suffixe. Copilot envoie ensuite cette invite (après un certain formatage) au modèle. Dans ce cas, comme le suffixe n'est pas vide, Copilot appellera le Codex en « mode insertion », c'est-à-dire en mode fill-in-middle (FIM).
Si vous regardez le préfixe, vous verrez qu'il contient du code provenant d'un autre fichier du projet. Voir # Comparez cet extrait de codevizpredictions.py : Comment la ligne de code et les lignes qui la suivent
invite sont-elles préparées ?
En gros, la séquence d'étapes suivante est exécutée pour générer l'invite :
De manière générale, l'invite est générée étape par étape à travers la série d'étapes suivante :
1. Point d'entrée : extraction de l'invite. se produit lorsque le document et la position du curseur spécifiés sont donnés. Le point d'entrée principal généré est extractPrompt (ctx, doc, insertPos)
2. Recherchez le chemin relatif et l'ID de langue du document à partir de VSCode. Voir : getPromptForRegularDoc (ctx, doc, insertPos)
3 Documents associés : Ensuite, interrogez les 20 fichiers les plus récemment consultés dans la même langue à partir de VSCode. Voir getPromptHelper (ctx, docText, insertOffset, docRelPath, docUri, docLangId) . Ces fichiers sont ensuite utilisés pour extraire des extraits similaires à inclure dans l'invite. Personnellement, je pense que c'est bizarre d'utiliser le même langage comme filtre puisque le développement multilingue est assez courant. Mais je suppose que cela couvre toujours la plupart des cas.
4. Configuration : Ensuite, définissez quelques options. Incluez spécifiquement :
5. Calcul du préfixe : Maintenant, créez une « Liste de souhaits d'invite » pour calculer la partie préfixe de l'invite. Ici, nous ajoutons différents « éléments » et leurs priorités. Par exemple, un élément pourrait être quelque chose comme « Comparez ce fragment de », ou le contexte d'une importation locale, ou l'ID de langue et/ou le chemin de chaque fichier. Tout cela se passe dans getPrompt (fs, curFile, promptOpts = {}, relevantDocs = []) .
6. Calcul du suffixe : L'étape précédente concerne les préfixes, mais la logique des suffixes est relativement simple : il suffit de remplir le budget du jeton avec n'importe quel suffixe disponible à partir du curseur. Il s'agit de la valeur par défaut, mais la position de départ du suffixe variera légèrement en fonction de l'option SuffixStartMode, qui est également contrôlée par le cadre d'expérimentation AB. Par exemple, si SuffixStartMode est un SiblingBlock, Copilot trouvera d'abord le frère fonctionnel le plus proche de la fonction en cours de modification et écrira le suffixe à partir de là.
Un examen plus approfondi de l'extraction de fragments
Pour moi, la partie la plus complète de la génération d'invites semble être l'extraction de fragments à partir d'autres fichiers. Il est appelé ici et défini par Neighbor-snippet-selector.getNeighbourSnippets. Selon les options, cela utilisera le "Jaccard matcher à fenêtre fixe" ou le "Jaccard Matcher basé sur l'indentation". Je ne suis pas sûr à 100%, mais il ne semble pas que Jaccard Matcher basé sur l'indentation soit réellement utilisé.
Par défaut, nous utilisons Jaccard Matcher à fenêtre fixe. Dans ce cas, le fichier donné (dont les fragments seront extraits) est découpé en fenêtres coulissantes de taille fixe. Calculez ensuite la similarité Jaccard entre chaque fenêtre et le fichier de référence (le fichier dans lequel vous tapez). Seule la fenêtre optimale est renvoyée pour chaque "fichier associé" (bien qu'il soit obligatoire de renvoyer les K premiers fragments, cela n'est jamais suivi). Par défaut, FixedWindowJaccardMatcher sera utilisé en "Mode Eager" (c'est-à-dire que la taille de la fenêtre est de 60 lignes). Cependant, ce mode est contrôlé par le framework AB Experimentation, nous pouvons donc utiliser d'autres modes.
Copilot permet la complétion via deux interfaces utilisateur : Inline/GhostText et Copilot Panel. Dans les deux cas, il existe certaines différences dans la façon dont le modèle est appelé.
Inline/GhostText
Module principal : https://thakkarparth007.github.io/copilot-explorer/codedeviz/templates/code-viz.html#m9334&pos=301:14
In Parmi eux, l'extension Copilot nécessite que le modèle fournisse très peu de suggestions (1 à 3 éléments) pour accélérer. Il met également activement en cache les résultats du modèle. De plus, il se charge d'ajuster les suggestions si l'utilisateur continue de taper. Si l'utilisateur tape très vite, il demandera également au modèle d'activer la fonction anti-rebond.
Cette interface utilisateur définit également une certaine logique pour empêcher l'envoi de demandes dans certaines circonstances. Par exemple, si le curseur de l'utilisateur est au milieu d'une ligne, la requête ne sera envoyée que si le caractère à sa droite est un espace, une accolade fermante, etc.
1. Bloquez les mauvaises demandes via un filtre contextuel
Ce qui est plus intéressant, c'est qu'après avoir généré l'invite, le module vérifie si l'invite est « assez bonne » pour appeler le modèle. Ceci est obtenu en calculant le « score de filtrage de contexte ». Ce score semble être basé sur un modèle de régression logistique simple, qui contient 11 caractéristiques telles que la langue, si la suggestion précédente a été acceptée/rejetée, la durée entre les acceptations/rejets précédents, la longueur de la dernière ligne de l'invite, la dernière personnage etc Ce poids de modèle est contenu dans le code d'extension lui-même.
Si le score est inférieur au seuil (par défaut 15% ), la demande ne sera pas effectuée. Il serait intéressant d’explorer ce modèle, j’ai observé que certains langages ont un poids plus élevé que d’autres (ex : php > js > python > rust > dart…php). Une autre observation intuitive est que si l'invite se termine par ) ou ], le score est inférieur à celui si elle se termine par ( ou [. Cela est logique, car la première est plus susceptible d'indiquer que l'opération a déjà été « faite », tandis que l'invite se termine par ce dernier indique clairement que l'utilisateur bénéficiera de la saisie semi-automatique
Copilot Panel
Module principal : https://thakkarparth007.github.io/copilot-explorer/codedeviz/templates/code-viz.html#m2990&pos =12 : 1
Logique de base 1 : https://thakkarparth007.github.io/copilot-explorer/codeviz/templates/code-viz.html#m893&pos=9:1
Logique de base 2 : https ://thakkarparth007.github.io/copilot-explorer/codedeviz/templates/code-viz.html#m2388&pos=67:1
Cette interface utilisateur demandera plus d'échantillons au modèle par rapport à l'interface utilisateur en ligne (par défaut 10) . Cette interface utilisateur ne semble pas avoir de logique de filtrage contextuel (c'est logique, vous ne voudriez pas ne pas inviter le modèle si l'utilisateur l'appelle explicitement)
Il y a deux choses principales intéressantes ici :
Avant d'afficher les suggestions (via l'une ou l'autre des interfaces utilisateur), Copilot effectue deux vérifications :
Si la sortie est en double (par exemple : foo = foo = foo = foo...), il s'agit d'un mode d'échec courant du modèle de langage, alors cette suggestion sera rejetée dans le serveur proxy Copilot ou dans le clientSi l'utilisateur a tapé. this Suggestion, cette suggestion sera également rejetée
Astuce 3 : télémétrie
Github a affirmé dans un blog précédent que 40% du code écrit par les programmeurs est écrit par Copilot (pour les langages populaires tels que Python). ). J'étais curieux de savoir comment ils mesuraient ce nombre, alors je voulais insérer quelque chose dans le code de télémétrie.
J'aimerais également savoir quelles données de télémétrie il collecte, surtout s'il collecte des extraits de code. Je m'interroge à ce sujet car même si nous pourrions facilement pointer l'extension Copilot vers le backend open source FauxPilot au lieu du backend Github, l'extension pourrait toujours envoyer des extraits de code à Github via la télémétrie, décourageant certaines personnes préoccupées par la confidentialité du code de l'utiliser. Copilote. Je me demande si c'est le cas.
Question 1 : Comment est mesuré le chiffre de 40% ?
Mesurer le taux de réussite de Copilot ne consiste pas simplement à compter le nombre d'acceptations/rejets, car les gens acceptent généralement les recommandations et apportent quelques modifications. Par conséquent, l’équipe de Github vérifie si la suggestion acceptée existe toujours dans le code. Plus précisément, ils vérifient 15 secondes, 30 secondes, 2 minutes, 5 minutes et 10 minutes après l'insertion du code suggéré.
Les recherches exactes de suggestions acceptées sont désormais trop restrictives, elles mesurent donc la distance d'édition (au niveau des caractères et des mots) entre le texte suggéré et la fenêtre autour du point d'insertion. Une suggestion est considérée comme « encore dans le code » si la distance d'édition au niveau du mot entre l'insertion et la fenêtre est inférieure à 50 % (normalisée à la taille de la suggestion).Bien sûr, tout cela ne s'applique qu'aux codes acceptés. Question 2 : Les données de télémétrie contiennent-elles des extraits de code ? Oui, inclus. 30 secondes après avoir accepté ou rejeté une suggestion, le copilote « capturera » un instantané à proximité du point d'insertion. Plus précisément, l'extension appelle le mécanisme d'extraction d'invite pour collecter une « invite hypothétique » qui peut être utilisée pour faire des suggestions à ce point d'insertion. copilot capture également « l'achèvement hypothétique » en capturant le code entre le point d'insertion et le point final « deviné ». Je ne comprends pas très bien comment il devine ce point final. Comme mentionné précédemment, cela se produit après l'acceptation ou le rejet. Je soupçonne que ces instantanés peuvent être utilisés comme données d'entraînement pour améliorer davantage le modèle. Cependant, 30 secondes semblent trop courtes pour supposer que le code s'est « installé ». Mais je suppose que, étant donné que la télémétrie contient le dépôt github correspondant au projet de l'utilisateur, même si une période de 30 secondes produit des points de données bruyants, le personnel de GitHub peut nettoyer ces données relativement bruyantes hors ligne. Bien entendu, tout cela n’est que spéculation de ma part. Notez que GitHub vous laissera choisir d'accepter ou non d'utiliser vos extraits de code pour "améliorer le produit". Si vous n'êtes pas d'accord, la télémétrie contenant ces extraits ne sera pas envoyée au serveur (du moins dans la v1). .57 J'ai vérifié Ceci est vrai dans , mais j'ai également vérifié la v1.65). Je vérifie cela en examinant le code et en enregistrant les points de données de télémétrie avant qu'ils ne soient envoyés sur le réseau. J'ai légèrement modifié le code d'extension pour activer la journalisation détaillée (impossible de trouver un paramètre configurable). J'ai découvert que ce modèle s'appelle "cushman-ml", ce qui suggère fortement que Copilot utilise peut-être un modèle de paramètres 12B au lieu d'un modèle de paramètres 175B. Pour les travailleurs de l’open source, c’est très encourageant, ce qui signifie qu’un modèle de taille modeste peut fournir d’aussi bons conseils. Bien entendu, l’énorme quantité de données détenues par Github reste inaccessible aux travailleurs open source. Dans cet article, je n'ai pas couvert le fichier worker.js qui est distribué avec l'extension. À première vue, il semble ne fournir qu’une version parallèle de la logique d’extraction rapide, mais il peut avoir plus de capacités. Adresse du fichier : https://thakkarparth007.github.io/copilot-explorer/muse/github.copilot-1.57.7193/dist/worker_expanded.js Activer la journalisation détaillée if Vous souhaitez activer la journalisation détaillée, vous pouvez le faire en modifiant le code d'extension : Si vous voulez un patch prêt à l'emploi, copiez simplement le code d'extension : https://thakkarparth007.github.io/copilot-explorer/muse/github. copilot-1.57.7193 /dist/extension.js Notez qu'il s'agit de la version 1.57.7193 Il y a des liens plus détaillés dans le texte original, les lecteurs intéressés peuvent consulter le texte original.Autres observations
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



