


Traducteur | Li Rui
Critique | Sun Shujuan
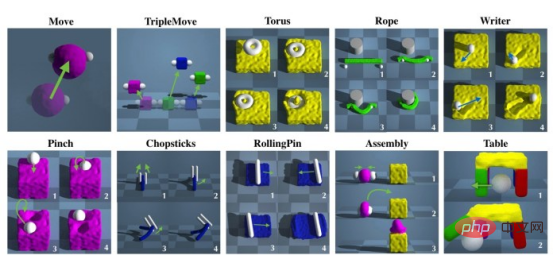
Pour les humains, le traitement d'objets déformables n'est pas beaucoup plus difficile que le traitement d'objets rigides. Les gens apprennent naturellement à les façonner, à les plier et à les manipuler de différentes manières tout en étant capables de les reconnaître.

Mais pour les systèmes de robotique et d'intelligence artificielle, manipuler des objets déformables est un défi de taille. Par exemple, un robot doit suivre une série d’étapes pour façonner la pâte en croûte à pizza. Au fur et à mesure que la pâte change de forme, elle doit être enregistrée et suivie, et en même temps, elle doit choisir les bons outils pour chaque étape du travail. Ce sont des tâches difficiles pour les systèmes d’intelligence artificielle actuels, qui sont plus stables lorsqu’ils traitent des objets rigides aux états plus prévisibles.
Maintenant, une nouvelle technique d'apprentissage profond développée par des chercheurs du MIT, de l'Université Carnegie Mellon et de l'UC San Diego promet de rendre les systèmes robotiques plus stables lors de la manipulation d'objets déformables. La technologie, appelée DiffSkill, utilise des réseaux neuronaux profonds pour acquérir des compétences simples et un module de planification pour combiner ces compétences afin de résoudre des tâches nécessitant plusieurs étapes et outils.
Si un système d'intelligence artificielle veut traiter un objet, il doit être capable de détecter et définir son état et de prédire à quoi il ressemblera dans le futur. Pour les objets rigides, il s’agit d’un problème largement résolu. Avec un bon ensemble d’exemples de formation, un réseau neuronal profond sera capable de détecter des objets rigides sous différents angles. Lorsque des objets déformables sont impliqués, leurs multiples espaces d’états deviennent encore plus complexes.
Lin Xingyu, doctorant à l'Université Carnegie Mellon et auteur principal de l'article DiffSkill, a déclaré : « Pour un objet rigide, nous pouvons utiliser six nombres pour décrire son état : trois nombres représentent ses coordonnées XYZ, et les trois autres les nombres représentent sa direction.
Cependant, les objets déformables tels que la pâte ou le tissu ont des degrés de liberté infinis, ce qui rend leur état plus difficile à décrire avec précision, et la façon dont ils se déforment est également plus difficile à utiliser que l'approche mathématique de la modélisation. . ”
Le développement de simulateurs de physique différentiable permet l’application de méthodes basées sur le gradient pour résoudre des tâches de manipulation d’objets déformables. Ceci est différent des méthodes traditionnelles d’apprentissage par renforcement, qui tentent d’apprendre la dynamique de l’environnement et des objets par de pures interactions par essais et erreurs.
DiffSkill s'inspire de PlasticineLab, un simulateur de physique différentiable et présenté lors de la conférence ICLR 2021. PlasticineLab montre que les simulateurs différenciables peuvent aider dans les tâches à court terme.
PlasticineLab est un simulateur d'objets déformables basé sur la physique différentiable. Cela fonctionne bien pour la formation de modèles basés sur le gradient
, mais les simulateurs différenciables sont toujours confrontés au problème à long terme de nécessiter plusieurs étapes et d'utiliser différents outils. Les systèmes d’intelligence artificielle basés sur des simulateurs différenciables nécessitent également une connaissance de l’état complet de la simulation et des paramètres physiques associés de l’environnement. Ceci est particulièrement limitant pour les applications du monde réel, où les agents perçoivent généralement le monde à travers des données visuelles et de détection de profondeur (RVB-D).
Lin Xingyu a déclaré : « Nous avons commencé à nous demander si nous pouvions extraire les étapes nécessaires pour accomplir une tâche en compétences et apprendre des concepts abstraits sur les compétences afin de pouvoir les relier pour résoudre des tâches plus complexes. »
DiffSkill est un cadre dans. quels agents d'intelligence artificielle apprennent des abstractions de compétences à l'aide de modèles physiques différenciables et les combinent pour accomplir des tâches opérationnelles complexes.
Ses travaux antérieurs se sont concentrés sur l'utilisation de l'apprentissage par renforcement pour manipuler des objets déformables tels que des tissus, des cordes et des liquides. Pour DiffSkill, il a choisi la manipulation de la pâte en raison des défis qu'elle présentait.
Il a déclaré : "La manipulation de la pâte est particulièrement intéressante car elle n'est pas facile à réaliser avec une pince robotisée, mais nécessite l'utilisation de différents outils en séquence, ce pour quoi les humains sont doués mais les robots sont moins courants.
Après la formation, DiffSkill." Un ensemble de tâches de manipulation de la pâte peut être réalisé avec succès en utilisant uniquement l'entrée RVB-D.
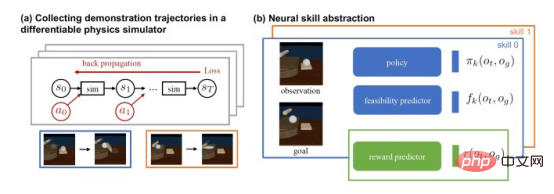
DiffSkill entraîne la faisabilité des réseaux de neurones pour prédire les états cibles à partir des états initiaux et des paramètres obtenus à partir de simulateurs de physique différentiable
DiffSkill se compose de deux éléments clés : l'un consiste à utiliser des réseaux de neurones Un « abstracteur de compétences neuronales » pour l'apprentissage de compétences individuelles, et un autre un « planificateur » pour résoudre des tâches à long terme.
DiffSkill utilise un simulateur de physique différenciable pour générer des exemples de formation pour les abstracteurs de compétences. Ces exemples montrent comment utiliser un seul outil pour atteindre des objectifs à court terme, comme utiliser un rouleau à pâtisserie pour étaler la pâte ou une spatule pour déplacer la pâte.
Ces exemples sont présentés à des abstracteurs qualifiés sous forme de vidéos RVB-D. À partir d’une observation d’image, l’abstracteur de compétences doit prédire si l’objectif souhaité est réalisable. Le modèle apprend et ajuste ses paramètres en comparant ses prédictions aux résultats réels d'un simulateur physique.
La manipulation robotisée d'objets déformables comme la pâte nécessite un raisonnement sur le long terme sur l'utilisation de différents outils. L'approche DiffSkill exploite des simulateurs différenciables pour apprendre et combiner les compétences nécessaires à ces tâches difficiles.
Pendant ce temps, DiffSkill entraîne des auto-encodeurs variationnels (VAE) pour apprendre les représentations spatiales latentes d'exemples générés par des simulateurs physiques. Les auto-encodeurs variationnels (VAE) conservent des fonctionnalités importantes et suppriment les informations non pertinentes pour la tâche. En convertissant l'espace d'image de grande dimension en espace latent, les auto-encodeurs variationnels (VAE) jouent un rôle important en permettant à DiffSkill de planifier sur des champs de vision plus longs et de prédire les résultats de l'observation des données sensorielles.
L'un des défis importants dans la formation d'un auto-encodeur variationnel (VAE) est de s'assurer qu'il apprend les fonctionnalités correctes et qu'il se généralise au monde réel. Dans le monde réel, la composition des données visuelles est différente de celle générée par un simulateur physique. Par exemple, la couleur du rouleau à pâtisserie ou de la planche à découper n'est pas pertinente pour la tâche, mais la position et l'angle du rouleau à pâtisserie et la position de la pâte le sont.
Actuellement, les chercheurs utilisent une technique appelée « randomisation de domaine », qui randomise les propriétés non pertinentes de l'environnement d'entraînement, telles que l'arrière-plan et l'éclairage, et préserve des caractéristiques importantes telles que la position et l'orientation de l'outil. Cela rend la formation des auto-encodeurs variationnels (VAE) plus stables lorsqu'ils sont appliqués au monde réel.
Lin Xingyu a déclaré : « Ce n'est pas facile de faire cela car nous devons couvrir toutes les différences possibles entre la simulation et le monde réel (appelé écart sim2real). Une meilleure façon est d'utiliser un nuage de points 3D comme représentation de la scène. Transfert plus facile de la simulation au monde réel. En fait, nous développons un projet de suivi utilisant des nuages de points comme entrée »
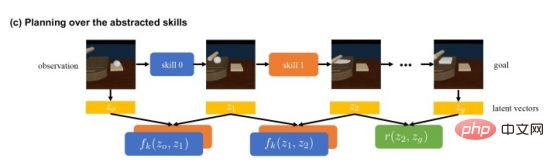
DiffSkill utilise le module de planification pour évaluer ce qui peut l'être. atteint. Différentes combinaisons et séquences de compétences
Une fois le résumé de compétences formé, DiffSkill utilise le module de planification pour résoudre des tâches à long terme. Les planificateurs doivent déterminer le nombre et la séquence de compétences requises pour passer de l'état initial à la destination.
Ce planificateur parcourt les combinaisons de compétences possibles et les résultats intermédiaires qu'elles produisent. Les auto-encodeurs variationnels sont utiles ici. Plutôt que de prédire les résultats d'images complets, DiffSkill utilise les VAE pour prédire les résultats spatiaux latents pour les étapes intermédiaires vers l'objectif final.
La combinaison de compétences d'abstraction et de représentation de l'espace latent rend le dessin de trajectoires depuis les états initiaux jusqu'aux objectifs plus efficace sur le plan informatique. En fait, les chercheurs n’ont pas eu besoin d’affiner la fonction de recherche mais ont mené une recherche exhaustive sur toutes les combinaisons.
Lin Xingyu a déclaré : « Puisque nous planifions des compétences, le travail de calcul ne sera pas trop important et le temps ne sera pas long. Cette recherche exhaustive élimine le besoin pour les planificateurs de concevoir des croquis, ce qui peut amener les concepteurs à ne pas concevoir en une manière plus générale d'envisager de nouvelles solutions, même si nous n'avons pas observé cela dans les tâches limitées que nous avons essayées. De plus, des techniques de recherche plus sophistiquées peuvent être appliquées. "
L'article DiffSkill indique : "Sur un seul GPU NVIDIA 2080Ti, chaque optimisation des ensembles de compétences peut être réalisée efficacement en 10 secondes environ »

Les chercheurs ont testé les performances de DiffSkill, en les comparant à plusieurs lignes de base qui ont été appliquées à des méthodes d'objets déformables, comprenant deux algorithmes d'apprentissage par renforcement sans modèle et un optimiseur de trajectoire utilisant uniquement des simulateurs physiques
Les modèles ont été testés sur plusieurs tâches nécessitant plusieurs étapes et outils. Dans l'une des tâches, par exemple, l'agent IA devait soulever la pâte avec une spatule, la placer sur une planche à découper, puis l'étaler avec un rouleau à pâtisserie.
Les résultats de la recherche montrent que DiffSkill est nettement meilleur que les autres technologies pour résoudre des tâches multi-outils à long terme en utilisant uniquement des informations sensorielles. Les expériences montrent qu'après avoir été bien formé, le planificateur de DiffSkill peut trouver un bon état intermédiaire entre l'état initial et l'état cible, et trouver une séquence de compétences appropriée pour résoudre la tâche.
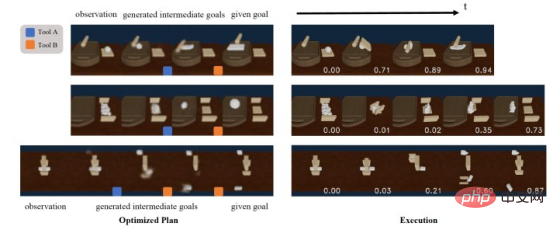
Le planificateur de DiffSkill peut prédire les étapes intermédiaires avec une grande précision
Lin Xingyu a déclaré : « L'un des points clés est qu'un ensemble de compétences peut fournir une abstraction temporelle très importante qui nous permet de raisonner sur le long terme. Cela est également similaire à la façon dont les humains gèrent différentes tâches : penser différemment. des abstractions temporelles, plutôt que de réfléchir à ce qu'il faut faire ensuite. »
Cependant, la capacité de DiffSkill est également limitée. Par exemple, les performances de DiffSkill ont considérablement diminué lors de l'exécution de l'une des tâches nécessitant une planification en trois étapes (bien qu'elles aient toujours surpassé les autres techniques). Lin Xingyu a également mentionné que dans certains cas, le prédicteur de faisabilité peut produire des faux positifs. Les chercheurs pensent que l’apprentissage de meilleurs espaces latents peut aider à résoudre ce problème.
Les chercheurs explorent également d'autres directions pour améliorer DiffSkill, notamment un algorithme de planification plus efficace qui peut être utilisé pour des tâches plus longues.
Lin Xingyu a déclaré qu'il espère qu'un jour, il pourra utiliser DiffSkill sur un vrai robot fabricant de pizza. Il a déclaré : "Nous en sommes encore loin. Divers défis sont apparus en termes de contrôle, de transfert sim2real et de sécurité. Mais nous sommes désormais plus confiants pour essayer de mener à bien certaines tâches à long terme."
Cette technique d'apprentissage profond résout l'un des défis difficiles de la robotique, par Ben Dickson
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Application de l'intelligence artificielle dans la vie
Application de l'intelligence artificielle dans la vie
 Quel est le concept de base de l'intelligence artificielle
Quel est le concept de base de l'intelligence artificielle
 Comment connecter PHP à la base de données mssql
Comment connecter PHP à la base de données mssql
 Tutoriel de création de site Web simple PHP
Tutoriel de création de site Web simple PHP
 La différence entre le Wi-Fi et le Wi-Fi
La différence entre le Wi-Fi et le Wi-Fi
 Situations courantes d'échec de l'index MySQL
Situations courantes d'échec de l'index MySQL
 Quels sont les types de données ?
Quels sont les types de données ?
 Introduction au protocole xmpp
Introduction au protocole xmpp








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



