


Actuellement, de nombreuses applications telles que Google Actualités utilisent des algorithmes de clustering comme principale méthode de mise en œuvre. Elles peuvent utiliser de grandes quantités de données non étiquetées pour créer un clustering de sujets puissant. Cet article présente 6 types de méthodes traditionnelles, du clustering K-means le plus basique aux méthodes puissantes basées sur la densité. Elles ont chacune leurs propres domaines d'expertise et scénarios, et les idées de base ne se limitent pas nécessairement aux méthodes de clustering.

Cet article commencera par un clustering K-means simple et efficace, puis présentera le clustering par décalage moyen, le clustering basé sur la densité, le clustering utilisant le mélange gaussien et les méthodes d'espérance maximale, le clustering hiérarchique et les méthodes adaptées au groupe de données structurées. détection. Nous analyserons non seulement les concepts de base de mise en œuvre, mais donnerons également les avantages et les inconvénients de chaque algorithme pour clarifier les scénarios d'application réels.
Le clustering est une technique d'apprentissage automatique qui consiste à regrouper des points de données. Étant donné un ensemble de points de données, nous pouvons utiliser un algorithme de clustering pour classer chaque point de données dans un groupe spécifique. En théorie, les points de données appartenant au même groupe devraient avoir des propriétés et/ou des caractéristiques similaires, tandis que les points de données appartenant à des groupes différents devraient avoir des propriétés et/ou des caractéristiques très différentes. Le clustering est une méthode d'apprentissage non supervisée et une technique d'analyse de données statistiques couramment utilisée dans de nombreux domaines.
K-Means est probablement l'algorithme de clustering le plus connu. Il fait partie de nombreux cours d’introduction à la science des données et à l’apprentissage automatique. Très facile à comprendre et à implémenter dans le code ! Veuillez voir l'image ci-dessous.

K-Means Clustering
Tout d'abord, nous sélectionnons quelques classes/groupes et initialisons au hasard leurs points centraux respectifs. Afin de déterminer le nombre de classes à utiliser, il est judicieux de jeter un coup d'œil rapide aux données et d'essayer d'identifier les différents groupes. Le point central est l'emplacement de même longueur que chaque vecteur de points de données, qui est « X » dans l'image ci-dessus.
Classez chaque point en calculant la distance entre le point de données et le centre de chaque groupe, puis classez le point dans le groupe dont le centre du groupe est le plus proche.
Sur la base de ces points de classement, nous utilisons la moyenne de tous les vecteurs du groupe pour recalculer le centre du groupe.
Répétez ces étapes pendant un certain nombre d'itérations, ou jusqu'à ce que le centre du groupe change peu après chaque itération. Vous pouvez également choisir d'initialiser le centre de groupe plusieurs fois de manière aléatoire, puis de choisir l'exécution qui semble fournir les meilleurs résultats.
K-Means a l'avantage d'être rapide, puisque nous ne faisons en réalité que calculer la distance entre le point et le centre du groupe : très peu de calcul ! Il a donc une complexité linéaire O(n).
D'un autre côté, K-Means présente certains inconvénients. Tout d’abord, vous devez choisir le nombre de groupes/classes. Cela n'est pas toujours fait avec soin et, idéalement, nous souhaitons que l'algorithme de clustering nous aide à résoudre le problème du nombre de classes à classer, car son objectif est d'obtenir des informations à partir des données. K-means part également de centres de cluster sélectionnés au hasard, de sorte qu'il peut produire différents résultats de clustering dans différents algorithmes. Par conséquent, les résultats peuvent ne pas être reproductibles et manquer de cohérence. D'autres méthodes de regroupement sont plus cohérentes.
K-Medians est un autre algorithme de clustering lié aux K-Means, sauf qu'au lieu d'utiliser la moyenne, les centres de groupe sont recalculés en utilisant le vecteur médian du groupe. Cette méthode est moins sensible aux valeurs aberrantes (car la médiane est utilisée), mais est beaucoup plus lente pour les ensembles de données plus volumineux car un tri est requis à chaque itération lors du calcul du vecteur médian.
Mean Shift Clustering est un algorithme basé sur une fenêtre glissante qui tente de trouver des zones denses de points de données. Il s'agit d'un algorithme basé sur le centroïde, ce qui signifie que son objectif est de localiser le point central de chaque groupe/classe, ce qui est accompli en mettant à jour les points candidats du point central par rapport à la moyenne des points dans la fenêtre glissante. Ces fenêtres candidates sont ensuite filtrées lors d'une étape de post-traitement pour éliminer les quasi-duplications, formant ainsi l'ensemble final de points centraux et leurs groupes correspondants. Veuillez consulter la légende ci-dessous.

Regroupement à décalage moyen pour une seule fenêtre glissante
L'ensemble du processus du début à la fin pour toutes les fenêtres coulissantes est présenté ci-dessous. Chaque point noir représente le centre de gravité de la fenêtre glissante et chaque point gris représente un point de données.

L'ensemble du processus de clustering par décalage moyen
Par rapport au clustering K-means, cette méthode ne nécessite pas la sélection du nombre de clusters car le décalage moyen le découvre automatiquement. C'est un énorme avantage. Le fait que le cluster centre le cluster vers la densité de points maximale est également très satisfaisant, car il est très intuitif de comprendre et de s'adapter à la signification naturelle basée sur les données. L'inconvénient est que le choix de la taille de la fenêtre/du rayon « r » peut être sans importance.
DBSCAN est un algorithme de clustering basé sur la densité qui est similaire au décalage moyen mais présente des avantages significatifs. Découvrez un autre graphique amusant ci-dessous et commençons !

DBSCAN présente de nombreux avantages par rapport aux autres algorithmes de clustering. Premièrement, cela ne nécessite pas du tout un nombre fixe de clusters. Il identifie également les valeurs aberrantes comme du bruit, contrairement au décalage moyen, qui regroupe simplement les points de données en clusters même s'ils sont très différents. De plus, il est capable de trouver très bien des clusters de n’importe quelle taille et forme.
Le principal inconvénient de DBSCAN est qu'il ne fonctionne pas aussi bien que les autres algorithmes de clustering lorsque la densité des clusters est différente. En effet, les paramètres du seuil de distance ε et des minPoints utilisés pour identifier les points de voisinage changeront avec les clusters lorsque la densité change. Cet inconvénient se pose également dans les données de très grande dimension, car le seuil de distance ε devient là encore difficile à estimer.
Un inconvénient majeur des K-Means est sa simple utilisation des moyennes centrales de cluster. Le diagramme ci-dessous nous montre pourquoi ce n’est pas la meilleure approche. A gauche, on voit très clairement qu'il existe deux amas circulaires de rayons différents, centrés sur la même moyenne. Les K-Means ne peuvent pas gérer cette situation car les moyennes de ces clusters sont très proches. K-Means échoue également dans les cas où les clusters ne sont pas circulaires, encore une fois en raison de l'utilisation de la moyenne comme centre du cluster.

Deux cas d'échec des K-Means
Les modèles de mélange gaussien (GMM) nous offrent plus de flexibilité que les K-Means. Pour les GMM, nous supposons que les points de données sont distribués de manière gaussienne ; il s'agit d'une hypothèse moins restrictive que l'utilisation de la moyenne pour supposer qu'ils sont circulaires. De cette façon, nous disposons de deux paramètres pour décrire la forme du cluster : la moyenne et l’écart type ! En prenant la 2D comme exemple, cela signifie que les clusters peuvent prendre n'importe quel type de forme elliptique (puisque nous avons des écarts types dans les directions x et y). Par conséquent, chaque distribution gaussienne est affectée à un seul cluster.
Pour trouver les paramètres gaussiens (tels que la moyenne et l'écart type) de chaque cluster, nous utiliserons un algorithme d'optimisation appelé Expectation Maximum (EM). Regardez le diagramme ci-dessous, qui est un exemple d'ajustement gaussien à un cluster. Nous pouvons ensuite poursuivre le processus de clustering à attentes maximales à l'aide de GMM.

L'utilisation des GMM présente deux avantages clés. Premièrement, les GMM sont plus flexibles que les K-Means en termes de covariance de cluster en raison du paramètre d'écart type, les clusters peuvent prendre n'importe quelle forme elliptique au lieu d'être limités à des cercles. K-Means est en fait un cas particulier de GMM, où la covariance de chaque cluster est proche de 0 dans toutes les dimensions. Deuxièmement, comme les GMM utilisent des probabilités, il peut y avoir de nombreux clusters par point de données. Ainsi, si un point de données se trouve au milieu de deux clusters qui se chevauchent, nous pouvons définir sa classe simplement en disant que X pour cent appartient à la classe 1 et Y pour cent à la classe 2. Autrement dit, les GMM prennent en charge les qualifications hybrides.
Les algorithmes de clustering hiérarchique sont en fait divisés en deux catégories : descendant ou ascendant. Les algorithmes ascendants traitent d'abord chaque point de données comme un seul cluster, puis fusionnent (ou agrégent) deux clusters successivement jusqu'à ce que tous les clusters soient fusionnés en un seul cluster contenant tous les points de données. Par conséquent, le clustering hiérarchique ascendant est appelé clustering hiérarchique agglomératif ou HAC. Cette hiérarchie de clusters est représentée par un arbre (ou dendrogramme). La racine de l’arbre est la seule grappe qui collecte tous les échantillons, et les feuilles sont les grappes ne contenant qu’un seul échantillon. Avant d'entrer dans les étapes de l'algorithme, veuillez consulter la légende ci-dessous.

Clustering hiérarchique aggloméré
Le clustering hiérarchique ne nous oblige pas à spécifier le nombre de clusters, nous pouvons même choisir quel nombre de clusters nous convient le mieux puisque nous construisons un arbre. De plus, l’algorithme n’est pas sensible au choix de la métrique de distance ; ils fonctionnent tous aussi bien, alors que pour d’autres algorithmes de clustering, le choix de la métrique de distance est crucial. Un exemple particulièrement intéressant de méthodes de clustering hiérarchique est celui où les données sous-jacentes ont une structure hiérarchique et que vous souhaitez restaurer la hiérarchie ; Contrairement à la complexité linéaire des K-Means et du GMM, ces avantages du clustering hiérarchique se font au prix d'une efficacité moindre car il a une complexité temporelle de O(n³).
Lorsque nos données peuvent être représentées sous forme de réseau ou de graphique, nous pouvons utiliser la méthode de détection de communauté graphique pour terminer le clustering. Dans cet algorithme, une communauté de graphes est généralement définie comme un sous-ensemble de sommets plus étroitement connectés que les autres parties du réseau.
Le cas le plus intuitif est peut-être celui des réseaux sociaux. Les sommets représentent des personnes et les arêtes reliant les sommets représentent des utilisateurs amis ou fans. Cependant, pour modéliser un système sous forme de réseau, nous devons trouver un moyen de connecter efficacement les différents composants. Certaines applications innovantes de la théorie des graphes pour le clustering incluent l'extraction de caractéristiques des données d'image, l'analyse des réseaux de régulation génétique, etc.
Vous trouverez ci-dessous un diagramme simple montrant 8 sites Web récemment consultés, connectés en fonction des liens de leurs pages Wikipédia.

La couleur de ces sommets indique leur relation de groupe, et la taille est déterminée en fonction de leur centralité. Ces clusters ont également un sens dans la vie réelle, où les sommets jaunes sont généralement des sites de référence/de recherche et les sommets bleus sont tous des sites de publication en ligne (articles, tweets ou codes).
Supposons que nous ayons regroupé le réseau en groupes. Nous pouvons ensuite utiliser ce score de modularité pour évaluer la qualité du clustering. Un score plus élevé signifie que nous avons segmenté le réseau en groupes « précis », tandis qu'un score faible signifie que notre regroupement est plus proche du hasard. Comme le montre la figure ci-dessous :

La modularité peut être calculée à l'aide de la formule suivante :

où L représente le nombre d'arêtes du réseau, k_i et k_j font référence au degré de chaque sommet, qui peut être calculé en additionnant chaque ligne. Il est obtenu en additionnant les éléments de chaque colonne. Multiplier les deux et diviser par 2L représente le nombre attendu d'arêtes entre les sommets i et j lorsque le réseau est attribué aléatoirement.
Dans l'ensemble, les termes entre parenthèses représentent la différence entre la véritable structure du réseau et la structure attendue lorsqu'ils sont combinés aléatoirement. L'étude de sa valeur montre qu'elle renvoie la valeur la plus élevée lorsque A_ij = 1 et ( k_i k_j ) / 2L est petit. Cela signifie que lorsqu'il y a une arête « inattendue » entre les points fixes i et j, la valeur résultante est plus élevée.
Le dernier δc_i, c_j est la fameuse fonction Kronecker δ (fonction Kronecker-delta). Voici son explication Python :

La modularité du graphique peut être calculée à l'aide de la formule ci-dessus, et plus la modularité est élevée, meilleur est le degré de regroupement du réseau en différents groupes. Par conséquent, la meilleure façon de regrouper le réseau peut être trouvée en recherchant une modularité maximale grâce à des méthodes d’optimisation.
La combinatoire nous dit que pour un réseau avec seulement 8 sommets, il existe 4140 méthodes de clustering différentes. Un réseau de 16 sommets serait regroupé de plus de 10 milliards de façons. Les méthodes de clustering possibles d'un réseau à 32 sommets dépasseront 128 septillions (10^21) ; si votre réseau comporte 80 sommets, le nombre de méthodes de clustering possibles a dépassé le nombre de méthodes de clustering dans l'univers observable.
Nous devons donc recourir à une heuristique qui fonctionne bien pour évaluer les clusters qui donnent les scores de modularité les plus élevés, sans essayer toutes les possibilités. Il s'agit d'un algorithme appelé Fast-Greedy Modularity-Maximization, qui est quelque peu similaire à l'algorithme de clustering hiérarchique agglomératif décrit ci-dessus. C'est juste que Mod-Max ne fusionne pas des groupes en fonction de la distance, mais fusionne des groupes en fonction des changements de modularité.
Voici comment cela fonctionne :
La détection de communauté est un domaine de recherche populaire en théorie des graphes. Ses limites se reflètent principalement dans le fait qu'elle ignore certains petits clusters et n'est applicable qu'aux modèles de graphes structurés. Mais ce type d'algorithme a de très bonnes performances dans les données structurées typiques et les données de réseau réelles.
Voici les 6 principaux algorithmes de clustering que les data scientists devraient connaître ! Nous terminerons cet article en montrant des visualisations de divers algorithmes !
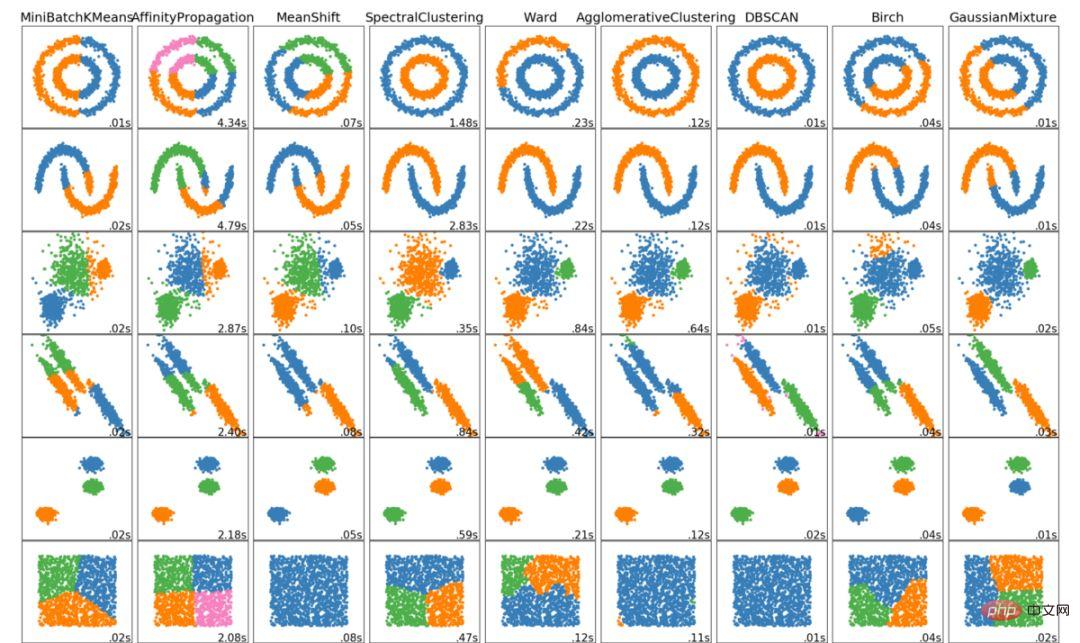
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Algorithme de remplacement de page
Algorithme de remplacement de page
 Mot de passe WiFi
Mot de passe WiFi
 Comment supprimer un fichier sous Linux
Comment supprimer un fichier sous Linux
 Comment additionner des tableaux tridimensionnels en php
Comment additionner des tableaux tridimensionnels en php
 python fusionne deux listes
python fusionne deux listes
 Raisons pour lesquelles l'écran tactile du téléphone portable échoue
Raisons pour lesquelles l'écran tactile du téléphone portable échoue
 Comment résoudre le problème selon lequel la valeur de retour scanf est ignorée
Comment résoudre le problème selon lequel la valeur de retour scanf est ignorée
 Comment télécharger et enregistrer les vidéos phares du jour
Comment télécharger et enregistrer les vidéos phares du jour








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



