


À mesure que les modèles d'apprentissage automatique deviennent de plus en plus populaires pour prédire et analyser les données, l'utilisation d'algorithmes de forêt aléatoire prend de l'ampleur. Random Forest est un algorithme d'apprentissage supervisé utilisé pour les tâches de régression et de classification dans le domaine de l'apprentissage automatique. Il fonctionne en construisant un grand nombre d'arbres de décision au moment de la formation et en produisant des classes, soit le mode de la classe (classification), soit la prédiction moyenne d'un seul arbre (régression).
Dans cet article, nous verrons comment implémenter l'algorithme Random Forest à l'aide d'ensembles de données réelles en ligne. Nous fournirons également des explications détaillées du code et des descriptions de chaque étape, ainsi qu'une évaluation des performances et de la visualisation du modèle.
L'ensemble de données que nous utiliserons est le « Ensemble de données sur le cancer du sein Wisconsin (Diagnostic) » qui est accessible au public et accessible via le référentiel d'apprentissage automatique UCI. L'ensemble de données contient 569 instances avec 30 attributs et deux catégories : malignes et bénignes. Notre objectif est de classer ces instances en fonction de 30 attributs et de déterminer si elles sont bénignes ou malignes. Vous pouvez télécharger l'ensemble de données depuis https://www.kaggle.com/datasets/uciml/breast-cancer-wisconsin-data.
Tout d'abord, nous importerons les bibliothèques nécessaires :
import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
Ensuite, nous chargerons l'ensemble de données :
df = pd.read_csv(r"C:UsersUserDownloadsdatabreast_cancer_wisconsin_diagnostic_dataset.csv") df
Sortie :
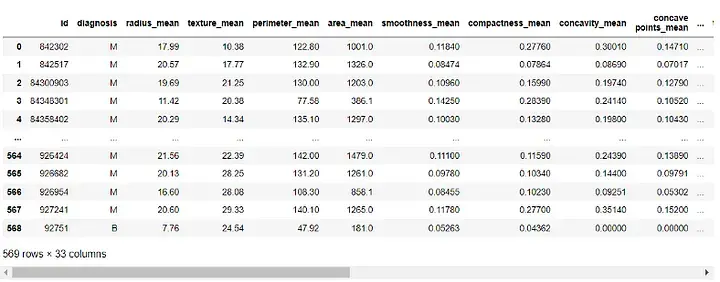
Avant de construire le modèle, nous devons prétraiter les données. Puisque les colonnes 'id' et 'Unname: 32' ne sont d'aucune utilité à notre modèle, nous allons le supprimer :
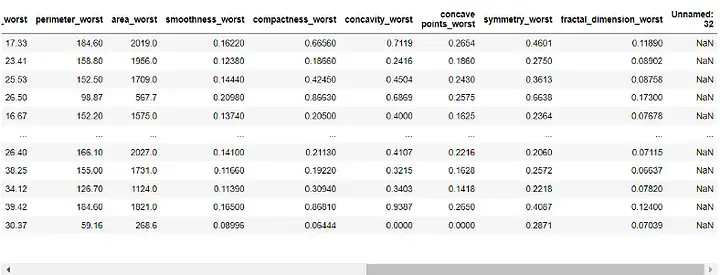
df = df.drop([ 'id' , 'Unnamed: 32' ], axis=1) df
Sortie :
Ensuite, nous mettrons le " Colonne Diagnostics" attribuée à notre variable cible et supprimée de nos fonctionnalités :
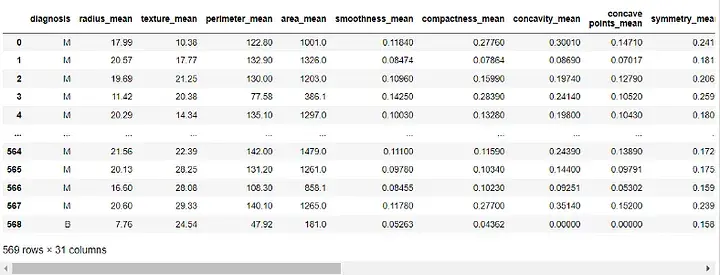
target = df['diagnosis']
features = df.drop('diagnosis', axis=1)Nous allons maintenant diviser notre ensemble de données en ensembles d'entraînement et de test. Nous utiliserons 70 % des données pour l'entraînement et 30 % pour les tests :
X_train, X_test, y_train, y_test = train_test_split(features, target, test_size=0.3, random_state=42)
Avec nos données prétraitées et divisées en ensembles d'entraînement et de test, nous pouvons maintenant construire notre modèle de forêt aléatoire :
rf = RandomForestClassifier(n_estimators=100, random_state=42) rf.fit(X_train, y_train)
Ici, nous fixons le nombre d'arbres de décision dans la forêt à 100 et définissons l'état aléatoire pour garantir la répétabilité des résultats.
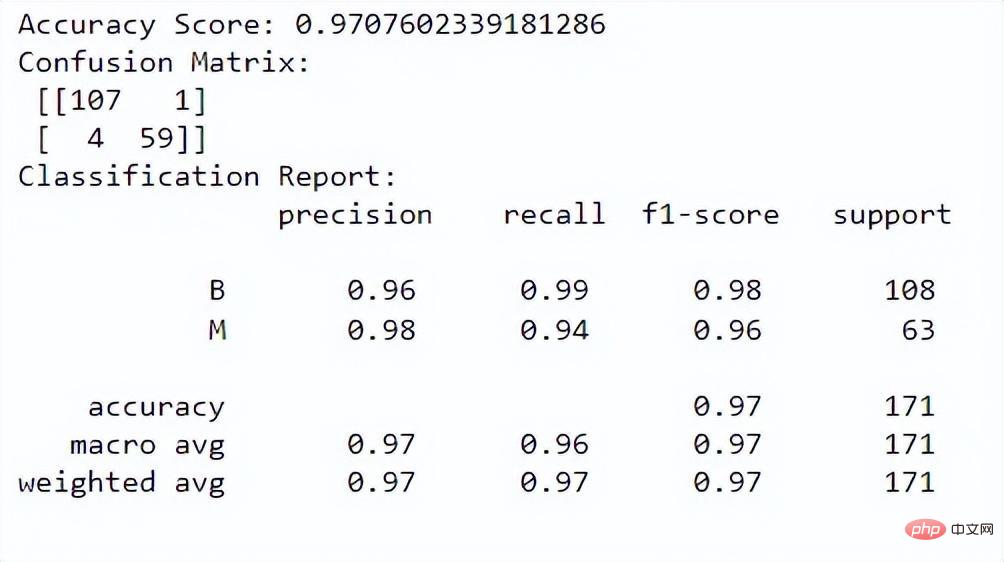
Maintenant, nous pouvons évaluer les performances du modèle. Nous utiliserons le score de précision, la matrice de confusion et le rapport de classification pour l'évaluation :y_pred = rf.predict(X_test)
# 准确度分数
print("Accuracy Score:", accuracy_score(y_test, y_pred))
# Confusion Matrix
conf_matrix = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:n", conf_matrix)
# Classification Report
class_report = classification_report(y_test, y_pred)
print("Classification Report:n", class_report)Sortie :
Le score de précision nous indique dans quelle mesure le modèle fonctionne dans la classification correcte des instances. La matrice de confusion nous permet de mieux comprendre les performances de classification de notre modèle. Le rapport de classification nous donne la précision, le rappel, le score f1 et les valeurs de support pour les deux classes.
importance = rf.feature_importances_ feat_imp = pd.Series(importance, index=features.columns) feat_imp = feat_imp.sort_values(ascending=False)
plt.figure(figsize=(12,8))
feat_imp.plot(kind='bar')
plt.ylabel('Feature Importance Score')
plt.title("Feature Importance")
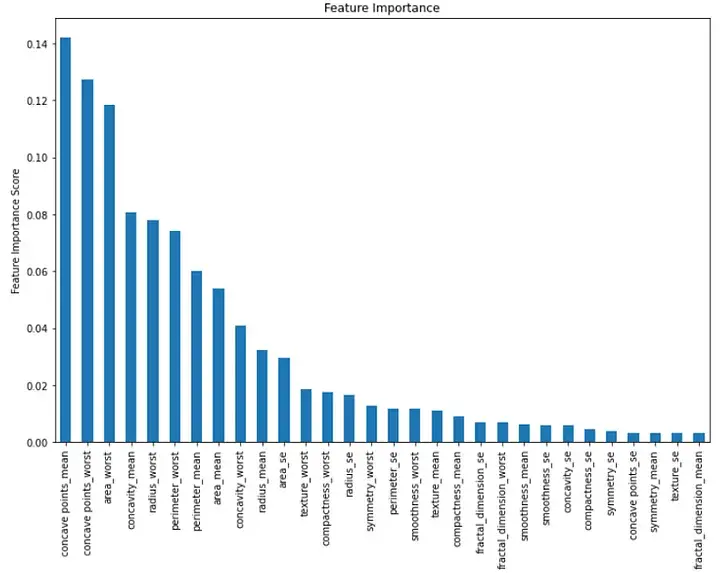
plt.show()Sortie :
Ce graphique à barres montre l'importance de chaque fonctionnalité dans l'ordre décroissant du sexe. Nous pouvons voir que les trois premières caractéristiques importantes sont « concave moyen », « pire concave » et « pire région ».
En résumé, la mise en œuvre de l'algorithme de forêt aléatoire dans l'apprentissage automatique est un outil puissant pour les tâches de classification. Nous pouvons l'utiliser pour classer les instances en fonction de plusieurs fonctionnalités et évaluer les performances de notre modèle. Dans cet article, nous utilisons un ensemble de données en ligne du monde réel et fournissons des explications détaillées du code et des descriptions de chaque étape, ainsi qu'une évaluation des performances et de la visualisation du modèle.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



